TRACER: A Semantic-Aware Framework for Fine-Grained Contamination Detection in Code LLMs
Pith reviewed 2026-06-30 15:28 UTC · model grok-4.3
The pith
TRACER detects three levels of semantic overlap in code data to identify contamination in LLMs, reaching 0.92 F1 in binary cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
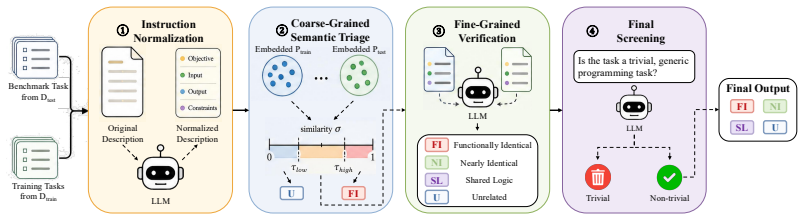
TRACER models contamination using three levels of semantic overlap—Functionally Identical, Nearly Identical, and Shared Logic—and detects them through a coarse-to-fine pipeline. The authors introduce the first benchmark spanning three widely used benchmarks and three representative post-training datasets. On this benchmark GPT-5 reaches an F1 of 0.91 in fine-grained detection; in the binary setting TRACER reaches 0.92 F1 and outperforms existing methods by 42%-217%.
What carries the argument
The coarse-to-fine pipeline that classifies input code pairs into the three semantic-overlap levels.
If this is right
- TRACER maintains strong performance when swapped across multiple LLM backbones.
- In binary detection the method exceeds prior detectors by 42 to 217 percent F1.
- Ablation results attribute gains to the combination of semantic levels and the pipeline stages.
- The same framework yields 0.91 F1 on the finer three-class task with GPT-5.
Where Pith is reading between the lines
- The three-level taxonomy could be reused as a labeling scheme for contamination audits in other programming languages.
- Integrating TRACER-style checks into dataset curation pipelines might reduce leakage before model training begins.
- If the benchmark becomes a standard, future code-LLM papers could report contamination statistics alongside accuracy numbers.
Load-bearing premise
The three semantic overlap levels together with the constructed benchmark capture the full range of real-world code contamination without systematic bias.
What would settle it
A collection of real contaminated code pairs drawn from post-training data that fall outside the three defined overlap levels or on which TRACER's F1 falls below 0.70.
Figures
read the original abstract
Data contamination is a known threat to the reliability of model evaluation. However, it remains underexplored in code large language models (LLMs), where contamination often goes beyond exact duplication. We present TRACER, a semantic-aware framework for fine-grained code contamination detection. TRACER models contamination using three levels of semantic overlap - Functionally Identical, Nearly Identical, and Shared Logic - and detects them through a coarse-to-fine pipeline. We also introduce the first benchmark for fine-grained code contamination detection, spanning three widely used benchmarks and three representative post-training datasets. TRACER achieves strong and consistent performance across multiple LLM backbones, with GPT-5 reaching an F1 score of 0.91 in fine-grained detection. In the binary setting, TRACER attains an F1 of 0.92, outperforming existing methods by 42%-217%. We further conduct ablation studies and error analysis to assess the contributions of individual components in TRACER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TRACER, a semantic-aware framework for fine-grained contamination detection in code LLMs. It defines three levels of semantic overlap (Functionally Identical, Nearly Identical, Shared Logic), uses a coarse-to-fine pipeline for detection, introduces a new benchmark constructed from three standard benchmarks and three post-training datasets, and reports F1 scores of 0.92 (binary) and 0.91 (fine-grained) on GPT-5, with outperformance of 42%-217% over baselines, plus ablations and error analysis.
Significance. If the benchmark labels prove representative, TRACER could meaningfully improve evaluation reliability for code LLMs by handling semantic rather than exact-match contamination. The introduction of the first fine-grained benchmark and the inclusion of ablation studies and error analysis are positive contributions that allow assessment of component importance.
major comments (2)
- [Benchmark construction] Benchmark construction (described in the abstract and § on benchmark): the three semantic overlap levels are applied to create labels with no reported inter-annotator agreement, no independent labeling protocol, and no comparison to externally identified contaminated pairs (e.g., GitHub fork histories or known leakage reports). This is load-bearing because all headline F1 scores and outperformance claims are measured exclusively against these author-defined labels.
- [Evaluation] Evaluation section: the binary F1 of 0.92 and fine-grained F1 of 0.91, along with the 42%-217% margins, are reported solely on the newly constructed benchmark; no results are shown on any pre-existing or independently labeled contamination detection task, leaving generalizability untested.
minor comments (1)
- [Abstract] Abstract: 'GPT-5' is referenced as a backbone; clarify whether this is a typo, a hypothetical, or a specific model variant, and ensure consistency with the experimental section.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address the two major comments point by point below, focusing on the benchmark construction and evaluation concerns.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (described in the abstract and § on benchmark): the three semantic overlap levels are applied to create labels with no reported inter-annotator agreement, no independent labeling protocol, and no comparison to externally identified contaminated pairs (e.g., GitHub fork histories or known leakage reports). This is load-bearing because all headline F1 scores and outperformance claims are measured exclusively against these author-defined labels.
Authors: The three semantic overlap levels are defined with explicit criteria in the manuscript to capture contamination beyond exact duplication. As this is the first benchmark for fine-grained code contamination detection, no prior externally labeled datasets or known leakage reports exist for these specific semantic categories. The labels were generated by systematically applying the level definitions to pairs drawn from the source benchmarks and post-training datasets. We acknowledge that inter-annotator agreement metrics and a more formalized protocol description would improve transparency; we will expand the benchmark construction section with additional details on the labeling procedure in the revision. revision: partial
-
Referee: [Evaluation] Evaluation section: the binary F1 of 0.92 and fine-grained F1 of 0.91, along with the 42%-217% margins, are reported solely on the newly constructed benchmark; no results are shown on any pre-existing or independently labeled contamination detection task, leaving generalizability untested.
Authors: No pre-existing benchmarks for fine-grained semantic contamination in code LLMs are available, which motivated the creation of this new benchmark spanning multiple standard sources. Existing binary contamination methods typically rely on exact-match or n-gram overlap rather than the semantic levels introduced here, limiting direct applicability. Performance is demonstrated consistently across three benchmarks, three post-training datasets, and multiple LLM backbones. We maintain that the current evaluation scope is appropriate given the novelty of the task; we do not plan to add results on non-existent independent fine-grained datasets. revision: no
Circularity Check
No circularity: empirical evaluation on explicitly constructed benchmark with independent definitions
full rationale
The paper defines three semantic overlap levels (Functionally Identical, Nearly Identical, Shared Logic) and constructs a benchmark from existing datasets, then reports direct F1 measurements of the TRACER pipeline on that benchmark. No equations, parameters, or claims reduce by construction to the inputs; performance numbers are measured outputs rather than renamed fits or self-referential definitions. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is self-contained as standard method-plus-benchmark introduction with ablation studies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lm-cppf: Paraphrasing- guided data augmentation for contrastive prompt-based few-shot fine-tuning
Amirhossein Abaskohi, Sascha Rothe, and Yadollah Yaghoobzadeh. Lm-cppf: Paraphrasing- guided data augmentation for contrastive prompt-based few-shot fine-tuning. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 670–681, 2023
2023
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
A systematic review on code clone detection.IEEE access, 7:86121–86144, 2019
Qurat Ul Ain, Wasi Haider Butt, Muhammad Waseem Anwar, Farooque Azam, and Bilal Maqbool. A systematic review on code clone detection.IEEE access, 7:86121–86144, 2019
2019
-
[4]
Program synthesis with large language models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 17981–17993, 2021
2021
-
[5]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondˇrej Dušek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 67–93, 2024
2024
-
[6]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[7]
Code alpaca: An instruction-following llama model for code generation
Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023
2023
-
[8]
Evaluating large language models trained on code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, et al. Evaluating large language models trained on code. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[9]
https://doi.org/10.48550/arXiv.2502.14425, http://arxiv.org/abs/2502.14425, arXiv:2502.14425 [cs]
Yuxing Cheng, Yi Chang, and Yuan Wu. A survey on data contamination for large language models.arXiv preprint arXiv:2502.14425, 2025
-
[10]
Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240): 1–113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240): 1–113, 2023
2023
-
[11]
Jasper Dekoninck, Mark Niklas Müller, Maximilian Baader, Marc Fischer, and Martin Vechev. Evading data contamination detection for language models is (too) easy.arXiv preprint arXiv:2402.02823, 2024
-
[12]
Investigating data contamination in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigating data contamination in modern benchmarks for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8706–8719, 2024
2024
-
[13]
Generalization or memorization: Data contamination and trustworthy evaluation for large language models
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li. Generalization or memorization: Data contamination and trustworthy evaluation for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 12039–12050, 2024
2024
-
[14]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
-
[15]
Does data contamination detection work (well) for llms? a survey and evaluation on detection assumptions
Yujuan Fu, Ozlem Uzuner, Meliha Yetisgen-Yildiz, and Fei Xia. Does data contamination detection work (well) for llms? a survey and evaluation on detection assumptions. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5235–5256, 2025. 10
2025
-
[16]
Scalable detection of semantic clones
Mark Gabel, Lingxiao Jiang, and Zhendong Su. Scalable detection of semantic clones. In Proceedings of the 30th international conference on Software engineering, pages 321–330, 2008
2008
-
[17]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5075–5084, 2023
2023
-
[19]
LiveCodeBench: Holistic and contamination-free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination-free evaluation of large language models for code. InInternational Confer- ence on Learning Representations (ICLR), 2025
2025
-
[20]
Deckard: Scalable and accurate tree-based detection of code clones
Lingxiao Jiang, Ghassan Misherghi, Zhendong Su, and Stephane Glondu. Deckard: Scalable and accurate tree-based detection of code clones. In29th International Conference on Software Engineering (ICSE’07), pages 96–105. IEEE, 2007
2007
-
[21]
Substring matching for clone detection and change tracking
J Howard Johnson. Substring matching for clone detection and change tracking. InICSM, volume 94, pages 120–126, 1994
1994
-
[22]
Ccfinder: A multilinguistic token- based code clone detection system for large scale source code.IEEE transactions on software engineering, 28(7):654–670, 2002
Toshihiro Kamiya, Shinji Kusumoto, and Katsuro Inoue. Ccfinder: A multilinguistic token- based code clone detection system for large scale source code.IEEE transactions on software engineering, 28(7):654–670, 2002
2002
-
[23]
Identifying similar code with program dependence graphs
Jens Krinke. Identifying similar code with program dependence graphs. InProceedings eighth working conference on reverse engineering, pages 301–309. IEEE, 2001
2001
-
[24]
Platypus: Quick, cheap, and powerful refinement of llms,
Ariel N Lee, Cole J Hunter, and Nataniel Ruiz. Platypus: Quick, cheap, and powerful refinement of llms.arXiv preprint arXiv:2308.07317, 2023
-
[25]
Cclearner: A deep learning-based clone detection approach
Liuqing Li, He Feng, Wenjie Zhuang, Na Meng, and Barbara Ryder. Cclearner: A deep learning-based clone detection approach. In2017 IEEE international conference on software maintenance and evolution (ICSME), pages 249–260. IEEE, 2017
2017
-
[26]
Cleva: Chinese language models evaluation platform
Yanyang Li, Jianqiao Zhao, Duo Zheng, Zi-Yuan Hu, Zhi Chen, Xiaohui Su, Yongfeng Huang, Shijia Huang, Dahua Lin, Michael R Lyu, et al. Cleva: Chinese language models evaluation platform. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 186–217, 2023
2023
-
[27]
Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction
Yucheng Li, Frank Guerin, and Chenghua Lin. Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18600–18607, 2024
2024
-
[28]
Pyserini: A python toolkit for reproducible information retrieval research with sparse and dense representations
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. Pyserini: A python toolkit for reproducible information retrieval research with sparse and dense representations. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pages 2356–2362, 2021
2021
-
[29]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct.arXiv preprint arXiv:2306.08568, 2023
-
[30]
The roots search tool: Data transparency for llms
Aleksandra Piktus, Christopher Akiki, Paulo Villegas, Hugo Laurençon, Gérard Dupont, Sasha Luccioni, Yacine Jernite, and Anna Rogers. The roots search tool: Data transparency for llms. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 304–314, 2023. 11
2023
-
[31]
https://doi.org/10.48550/arXiv.2403.00393
Tanmay Rajore, Nishanth Chandran, Sunayana Sitaram, Divya Gupta, Rahul Sharma, Kashish Mittal, and Manohar Swaminathan. Truce: Private benchmarking to prevent contamination and improve comparative evaluation of llms.arXiv preprint arXiv:2403.00393, 2024
-
[32]
https://doi.org/10.48550/ arXiv.2404.00699, http://arxiv.org/abs/2404.00699, arXiv:2404.00699 [cs]
Mathieu Ravaut, Bosheng Ding, Fangkai Jiao, Hailin Chen, Xingxuan Li, Ruochen Zhao, Chengwei Qin, Caiming Xiong, and Shafiq Joty. A comprehensive survey of contamination detection methods in large language models.arXiv preprint arXiv:2404.00699, 2024
-
[33]
Quantifying contamination in evaluating code generation capabilities of language models
Martin Riddell, Ansong Ni, and Arman Cohan. Quantifying contamination in evaluating code generation capabilities of language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14116–14137, 2024
2024
-
[34]
Nicad: Accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization
Chanchal K Roy and James R Cordy. Nicad: Accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization. In2008 16th iEEE international conference on program comprehension, pages 172–181. IEEE, 2008
2008
-
[35]
A survey on software clone detection research
Chanchal Kumar Roy and James R Cordy. A survey on software clone detection research. Queen’s School of computing TR, 541(115):64–68, 2007
2007
-
[36]
Sourcerercc: Scaling code clone detection to big-code
Hitesh Sajnani, Vaibhav Saini, Jeffrey Svajlenko, Chanchal K Roy, and Cristina V Lopes. Sourcerercc: Scaling code clone detection to big-code. InProceedings of the 38th international conference on software engineering, pages 1157–1168, 2016
2016
-
[37]
Detecting Pretraining Data from Large Language Models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Jianmo Ni, Gustavo Hernandez Abrego, Noah Con- stant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, et al. jina- embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173, 2024
-
[39]
Evaluating clone detection tools with bigclonebench
Jeffrey Svajlenko and Chanchal K Roy. Evaluating clone detection tools with bigclonebench. In2015 IEEE international conference on software maintenance and evolution (ICSME), pages 131–140. IEEE, 2015
2015
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Magicoder: Empow- ering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empow- ering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
-
[42]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. Livebench: A challenging, contamination-free llm benchmark.arXiv preprint arXiv:2406.19314, 4:2, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Deep learning code fragments for code clone detection
Martin White, Michele Tufano, Christopher Vendome, and Denys Poshyvanyk. Deep learning code fragments for code clone detection. InProceedings of the 31st IEEE/ACM international conference on automated software engineering, pages 87–98, 2016
2016
-
[44]
Paraphrasing with large language models
Sam Witteveen and Martin Andrews. Paraphrasing with large language models. InProceedings of the 3rd Workshop on Neural Generation and Translation, pages 215–220, 2019
2019
-
[45]
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, et al. Benchmark data contamination of large language models: A survey.arXiv preprint arXiv:2406.04244, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples.arXiv preprint arXiv:2311.04850, 2023
-
[47]
Morteza Zakeri-Nasrabadi, Saeed Parsa, Mohammad Ramezani, Chanchal Roy, and Masoud Ekhtiarzadeh. A systematic literature review on source code similarity measurement and clone detection: Techniques, applications, and challenges.Journal of Systems and Software, 204: 111796, 2023. 12
2023
-
[48]
Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. Min-k%++: Improved baseline for detecting pre-training data from large language models.arXiv preprint arXiv:2404.02936, 2024
-
[49]
Automated transplantation and differential testing for clones
Tianyi Zhang and Miryung Kim. Automated transplantation and differential testing for clones. In2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), pages 665–676. IEEE, 2017
2017
-
[50]
Yi Zhao, Jing Li, and Linyi Yang. Cap: Data contamination detection via consistency amplifica- tion.arXiv preprint arXiv:2410.15005, 2024
-
[51]
Clean–eval: Clean evaluation on contaminated large language models
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yun-Ze Song, Jiao Yueyang, Yumeng Zhang, Hanxu Hu, Yiran Wei, Rui Wang, and Hongyuan Lu. Clean–eval: Clean evaluation on contaminated large language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 835–847, 2024. A Prompts in TRACER This section presents all the prompts of TRACER. ...
2024
-
[52]
You will see two tasks: Task A and Task B
-
[53]
Read both carefully, noting their goals, inputs/outputs, and logic
-
[54]
Relationship Categories A
Choose the single most accurate relationship from the categories below. Relationship Categories A. Functionally Identical Choose this if the tasks are perfect duplicates. They accomplish the exact same goal, take the same kinds of input, and produce the same kinds of output. They are essentially two descriptions of the very same problem. Litmus Test: Coul...
-
[55]
Primitive and atomic –- performs a single, irreducible operation
-
[56]
Scalar/boolean output –- returns only a simple scalar or trivial boolean (not a composite structure)
-
[57]
Built-in equivalent –- typically maps to a single built-in or standard library function (e.g., abs(x), len(list), max(array))
-
[58]
"" brackets is a string of
Subroutine nature –- commonly used as a small sub-step inside larger algorithms. Litmus Tests (all must be satisfied for “Yes”) - Built-in mapping: Does it directly correspond to a built-in/standard library call? - Subroutine usage: Is it normally a utility step within larger problems? - Atomic simplicity: Does it avoid extra selection, indexing, or multi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.