GlossAssist -- A Tool to Simplify Corpus Creation and Study the Effect of NLP Models in Low-Resource Documentation Settings
Pith reviewed 2026-06-28 06:51 UTC · model grok-4.3
The pith
GlossAssist shows that annotator corrections can expand a mutable lexicon to improve gloss predictions without retraining the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
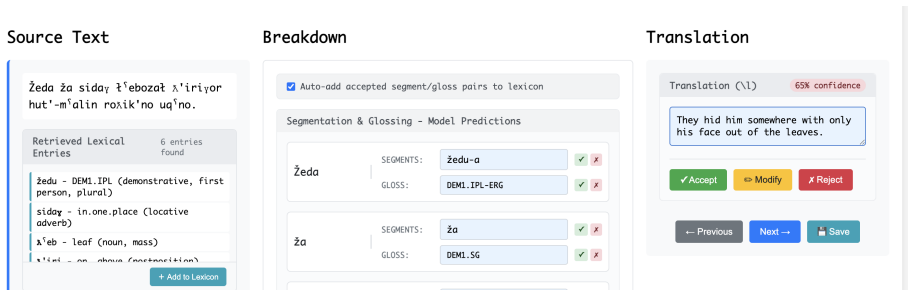
GlossAssist is built around the retrieval-based architecture of CWoMP, which grounds predictions in a mutable lexicon of learned morpheme representations. In conjunction with CWoMP, the system treats each correction by an annotator as part of an active learning setting, which expands the lexicon and improves future predictions without having to retrain the model. The paper argues that this feedback loop should be treated as a design requirement for NLP tools aimed at documentary linguists.
What carries the argument
The mutable lexicon of learned morpheme representations in the CWoMP retrieval-based architecture, which stores and expands from annotator corrections to ground and improve subsequent gloss predictions.
If this is right
- Annotators gain an interpretable path to correct predictions and have those corrections affect future outputs immediately.
- The tool becomes suitable for practical corpus creation rather than only model evaluation.
- Linguistic expertise from documentary linguists can influence system behavior without requiring machine learning retraining steps.
- Studies of NLP model effects in low-resource documentation workflows become possible through the integrated interface.
Where Pith is reading between the lines
- If lexicon updates prove stable across multiple annotators, the method could support collaborative documentation efforts on the same language.
- Analogous mutable knowledge stores might reduce retraining needs in other annotation-heavy low-resource NLP tasks such as morphological analysis.
- Measuring actual annotation time savings when using the tool versus static glossers would test real-world efficiency gains.
Load-bearing premise
Corrections made by annotators can be directly incorporated into the mutable lexicon to improve future predictions without model retraining or introducing errors from inconsistent annotations.
What would settle it
A controlled test in which linguists apply repeated corrections through the tool and subsequent gloss accuracy on held-out data shows no improvement or declines would falsify the central claim.
Figures


read the original abstract
Interlinear glossed text (IGT) is the standard format for linguistic annotation in language documentation. Producing it manually, however, is often slow and costly. Automated glossing systems have improved substantially in recent years, but adoption among field linguists remains limited. Existing tools are designed to be evaluated rather than used, offering no interpretable path for correction or the incorporation of linguistic expertise back into model behavior. We present GlossAssist, a glossing tool built around the retrieval-based architecture of CWoMP (Contrastive Word-Morpheme Pre-training), which grounds predictions in a mutable lexicon of learned morpheme representations. In conjunction with CWoMP, our system treats each correction by an annotator as part of an active learning setting, which expands the lexicon and improves future predictions without having to retrain the model. In this paper, we present our interface and argue that this feedback loop should be treated as a design requirement for NLP tools aimed at documentary linguists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GlossAssist, a glossing tool based on the CWoMP retrieval-based architecture for interlinear glossed text. It features a mutable lexicon that incorporates annotator corrections in an active learning setting to improve future predictions without retraining. The authors argue that this feedback loop should be treated as a design requirement for NLP tools aimed at documentary linguists.
Significance. If the feedback mechanism works as described, it could address key barriers to adoption of NLP tools in language documentation by enabling seamless incorporation of expert corrections. The design emphasizes usability and interpretability, which is a positive step for practical applications in low-resource settings. The paper's contribution lies in highlighting the importance of active feedback in tool design rather than in empirical results.
major comments (2)
- [Abstract] Abstract: The assertion that corrections expand the lexicon and improve predictions without retraining is load-bearing for the central claim, but the description provides no mechanism for resolving inconsistent corrections when the same morpheme receives divergent glosses from annotators. This is particularly problematic in low-resource documentation settings where such inconsistencies are routine.
- [Abstract] Abstract: No evaluation data, error rates, user studies, or baseline comparisons are supplied to support the claims of improved predictions or usability, which is necessary to substantiate the argument that the feedback loop constitutes a design requirement.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We respond to each major comment below, indicating whether revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that corrections expand the lexicon and improve predictions without retraining is load-bearing for the central claim, but the description provides no mechanism for resolving inconsistent corrections when the same morpheme receives divergent glosses from annotators. This is particularly problematic in low-resource documentation settings where such inconsistencies are routine.
Authors: We agree that explicit handling of inconsistent corrections is important for the claim. The manuscript describes the mutable lexicon as incorporating corrections via active learning to expand entries and affect retrieval, but does not detail conflict resolution for divergent glosses on the same form. We will revise to add a clear description of the mechanism (e.g., storing multiple context-sensitive entries and surfacing options to the annotator during use) to make the design fully transparent. revision: yes
-
Referee: [Abstract] Abstract: No evaluation data, error rates, user studies, or baseline comparisons are supplied to support the claims of improved predictions or usability, which is necessary to substantiate the argument that the feedback loop constitutes a design requirement.
Authors: The paper's primary contribution, as the referee notes, is the design argument and tool presentation rather than empirical results. The claim that the feedback loop improves predictions rests on the retrieval-based CWoMP architecture, where lexicon updates directly influence future outputs without retraining; this is presented as a conceptual design requirement for documentary tools. Quantitative evaluations are outside the scope of this work, which focuses on architecture and interface. revision: no
Circularity Check
Tool design paper presents no derivations or fitted predictions
full rationale
The manuscript describes an interface and a proposed feedback mechanism for expanding a mutable lexicon from annotator corrections. No equations, parameter fitting, uniqueness theorems, or derivation chains appear in the provided text. The central claim is a design recommendation rather than a result obtained from prior steps, so the architecture and feedback loop do not reduce to their own inputs by construction. Self-citation of CWoMP is present but does not carry a load-bearing derivation; the paper remains self-contained as a systems contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
Journal of Machine Learning Research , Month = dec, Numpages =
Ando, Rie Kubota and Zhang, Tong , Issn =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Rice, Enora and von der Wense, Katharina and Palmer, Alexis. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.568
-
[9]
Morris Alper and Enora Rice and Bhargav Shandilya and Alexis Palmer and Lori Levin , year=. 2603.18184 , archivePrefix=
-
[10]
Michael Ginn and Lindia Tjuatja and Enora Rice and Ali Marashian and Maria Valentini and Jasmine Xu and Graham Neubig and Alexis Palmer , year=. 2601.10925 , archivePrefix=
-
[11]
Michael Ginn and Lindia Tjuatja and Taiqi He and Enora Rice and Graham Neubig and Alexis Palmer and Lori Levin , year=. 2403.06399 , archivePrefix=
-
[12]
Findings of the SIGMORPHON 2023 Shared Task on Interlinear Glossing
Ginn, Michael and Moeller, Sarah and Palmer, Alexis and Stacey, Anna and Nicolai, Garrett and Hulden, Mans and Silfverberg, Miikka. Findings of the SIGMORPHON 2023 Shared Task on Interlinear Glossing. Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology. 2023. doi:10.18653/v1/2023.sigmorphon-1.20
-
[13]
Proceedings of the 31st International Conference on Computational Linguistics
Shandilya, Bhargav and Palmer, Alexis. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[14]
Evaluating Automation Strategies in Language Documentation
Palmer, Alexis and Moon, Taesun and Baldridge, Jason. Evaluating Automation Strategies in Language Documentation. Proceedings of the NAACL HLT 2009 Workshop on Active Learning for Natural Language Processing. 2009
2009
-
[15]
Proceedings of the Workshop on Computational Modeling of Polysynthetic Languages
Moeller, Sarah and Hulden, Mans. Proceedings of the Workshop on Computational Modeling of Polysynthetic Languages. 2018
2018
-
[16]
Girrbach, Leander. T. Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology. 2023. doi:10.18653/v1/2023.sigmorphon-1.19
-
[17]
Can we teach language models to gloss endangered languages?
Ginn, Michael and Hulden, Mans and Palmer, Alexis. Can we teach language models to gloss endangered languages?. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.337
-
[18]
Gessler, Luke. Proceedings of the Fifth Workshop on the Use of Computational Methods in the Study of Endangered Languages. 2022. doi:10.18653/v1/2022.computel-1.15
-
[19]
Moeller, Sarah and Arppe, Antti. Proceedings of the Seventh Workshop on the Use of Computational Methods in the Study of Endangered Languages. 2024. doi:10.18653/v1/2024.computel-1.5
-
[20]
2009 , institution=
Active Learning Literature Survey , author=. 2009 , institution=
2009
-
[21]
Findings of the Association for Computational Linguistics: ACL 2025
Schroeder, Hope and Roy, Deb and Kabbara, Jad. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1323
-
[22]
Proceedings of the 28th International Conference on Computational Linguistics
Zhao, Xingyuan and Ozaki, Satoru and Anastasopoulos, Antonios and Neubig, Graham and Levin, Lori. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.471
-
[23]
Proceedings of the 16th Workshop on Computational Research in Phonetics, Phonology, and Morphology
Cross-lingual morphological inflection with explicit alignment. Proceedings of the 16th Workshop on Computational Research in Phonetics, Phonology, and Morphology. 2019. doi:10.18653/v1/W19-4209
-
[24]
An Investigation of Noise in Morphological Inflection
Wiemerslage, Adam and Yang, Changbing and Nicolai, Garrett and Silfverberg, Miikka and Kann, Katharina. An Investigation of Noise in Morphological Inflection. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.207
-
[25]
Glossy Bytes: Neural Glossing using Subword Encoding
Cross, Ziggy and Yun, Michelle and Apparaju, Ananya and MacCabe, Jata and Nicolai, Garrett and Silfverberg, Miikka. Glossy Bytes: Neural Glossing using Subword Encoding. Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology. 2023. doi:10.18653/v1/2023.sigmorphon-1.24
-
[26]
Directions for Interlinear Morphemic Translations , volume =
Lehmann, Christian , year =. Directions for Interlinear Morphemic Translations , volume =. Folia Linguistica - FOLIA LINGUIST , doi =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.