PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Pith reviewed 2026-06-28 09:54 UTC · model grok-4.3
The pith
PHASER allocates replay memory equally across manipulation phases and routes around high-forgetting risks to raise success rates in continual VLA training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
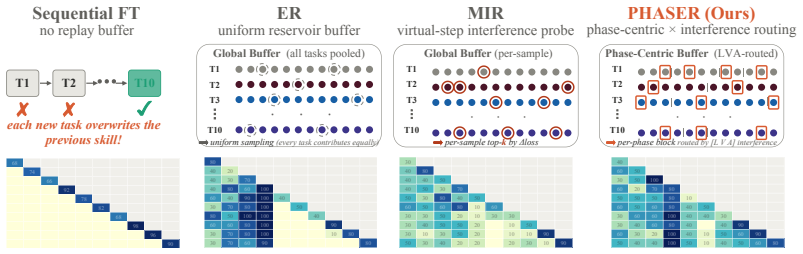
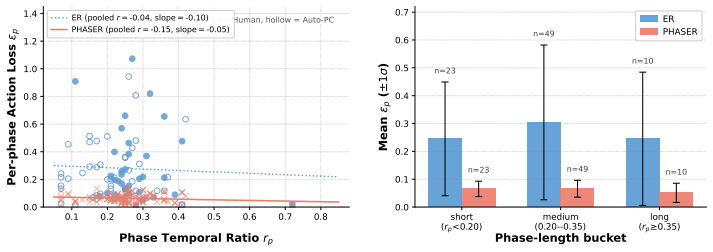
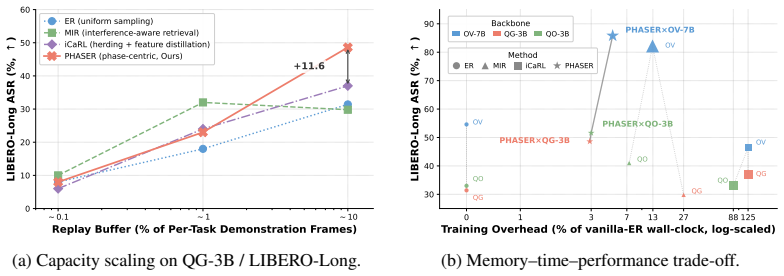
PHASER is an architecture-agnostic framework that combines phase-centric capacity allocation, multi-modal interference routing, and Auto-PC boundary detection to mitigate phase starvation and differential forgetting in experience replay for vision-language-action models, producing up to 31 percent higher average success rate than matched-budget baselines and 87.8 percent final success on the LIBERO-Goal continual-learning benchmark.
What carries the argument
Phase-centric capacity allocation that reserves equal replay slots for every sub-skill phase, paired with multi-modal interference routing that prioritizes historical phases at greatest risk of being overwritten.
If this is right
- Every sub-skill receives guaranteed replay support, so brief but necessary actions are no longer starved.
- Phases estimated to be most vulnerable to interference receive higher replay priority, preserving earlier task performance.
- Auto-PC removes manual segmentation, allowing the method to run continuously as new tasks arrive.
- The same memory budget yields higher final success across multiple VLA backbones on standard continual-learning suites.
Where Pith is reading between the lines
- The same phase-equal allocation principle could be tested on non-robotic sequential tasks that contain short critical events, such as video action recognition or autonomous driving logs.
- If boundary detection proves reliable, the framework might reduce the total replay buffer size needed to reach a target retention level.
- Combining the routing strategy with parameter-regularization methods could be examined to see whether the two forgetting mitigations add or interfere.
Load-bearing premise
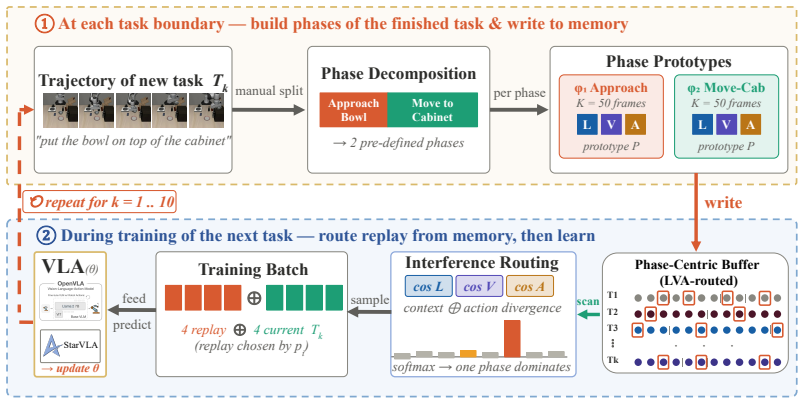
Unsupervised change-point detection on action signals plus vision-language model verification can locate the true temporal boundaries of manipulation sub-skills without human labels.
What would settle it
Measure whether success rate collapses when the same replay budget is used but the automatically detected phases are replaced by randomly chosen or uniformly spaced segments of equal length.
Figures
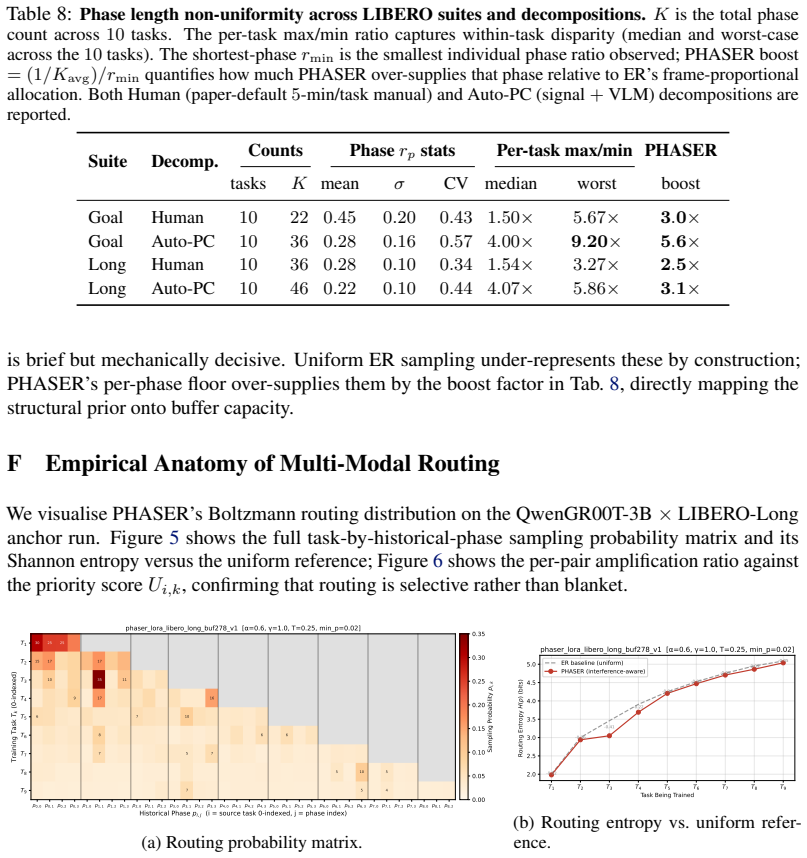
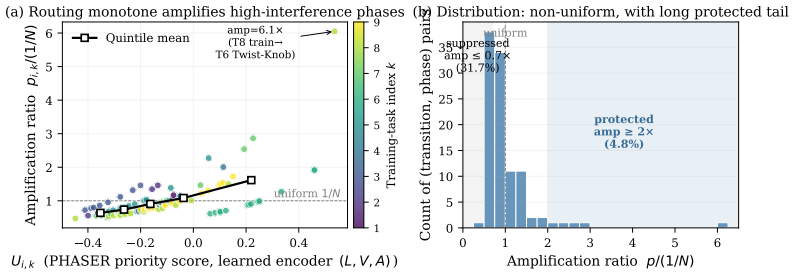
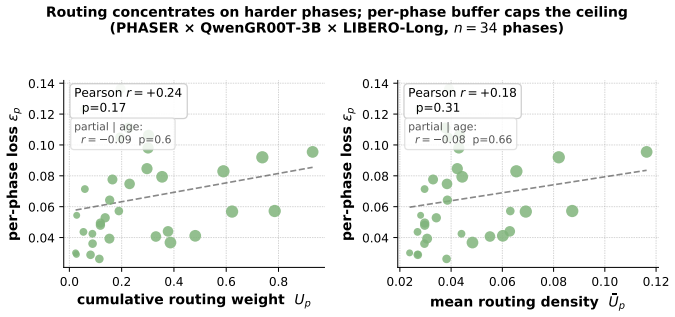
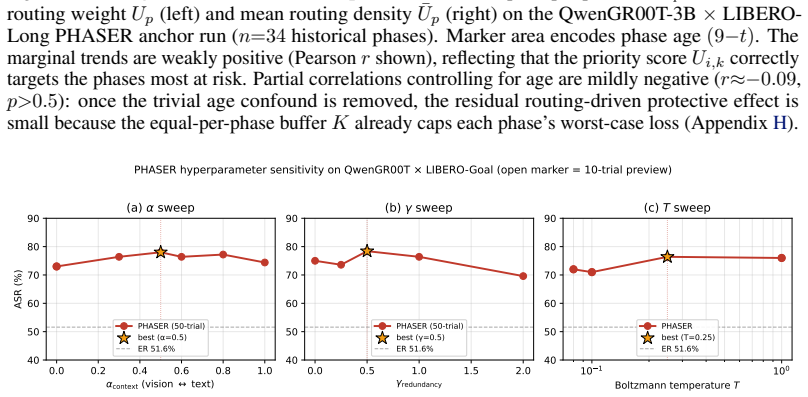
read the original abstract
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these models in open-ended environments requires continuously acquiring novel skills, a process that inevitably triggers severe catastrophic forgetting of previously learned behaviors. While experience replay (ER) serves as a standard mitigating strategy, naive uniform sampling fundamentally misaligns with the temporal characteristics of manipulation trajectories. It systematically under-samples brief but causally critical sub-skills, leading to phase starvation, and completely overlooks the varying degrees of forgetting across historical tasks. To overcome these limitations, we introduce PHASER, an architecture-agnostic continual learning framework. PHASER employs a phase-centric capacity allocation to guarantee equal memory support for all sub-skills, coupled with a multi-modal interference routing strategy that dynamically prioritizes historical phases at high risk of forgetting. Furthermore, to enable fully autonomous lifelong adaptation, we integrate Auto-PC, a lightweight pipeline combining unsupervised action-signal change-point detection with VLM-based semantic verification to extract temporal boundaries without intensive manual supervision. Evaluated across three VLA backbones on LIBERO continual learning suites, PHASER yields substantial empirical improvements, increasing Average Success Rate (ASR) by up to 31% over matched-budget ER and achieving an 87.8% final ASR on the LIBERO-Goal CL setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PHASER, an architecture-agnostic continual learning framework for Vision-Language-Action models that addresses catastrophic forgetting via phase-centric capacity allocation (to ensure equal memory support for sub-skills) and multi-modal interference routing (to prioritize high-forgetting-risk phases). It further proposes Auto-PC, an unsupervised pipeline using action-signal change-point detection plus VLM-based semantic verification to extract temporal phase boundaries without manual supervision. On LIBERO continual learning suites across three VLA backbones, it reports up to 31% ASR gains over matched-budget experience replay and a final 87.8% ASR on the LIBERO-Goal setting.
Significance. If the empirical gains are reproducible and attributable to the phase-aware mechanisms rather than implementation artifacts, the work would offer a practical advance in mitigating phase starvation during lifelong robotic adaptation. The autonomous Auto-PC component and cross-backbone evaluation are positive features for real-world deployment.
major comments (3)
- [§3.2] §3.2 (Auto-PC description): No equations, pseudocode, or parameter values are provided for the unsupervised action-signal change-point detection or the VLM verification step, so it is impossible to assess whether the extracted boundaries reliably isolate causally critical sub-skills as required for the phase-centric allocation claim.
- [Table 2] Table 2 / §5 (LIBERO results): The headline ASR improvements (up to 31% lift, 87.8% final ASR) are reported without error bars, standard deviations, or number of random seeds, leaving open whether the gains are statistically distinguishable from matched-budget ER.
- [§5.1] §5.1 (Ablations): There is no ablation that isolates Auto-PC phase extraction from the subsequent capacity allocation and interference routing; without it, the central attribution of gains to phase-centric allocation cannot be verified and could be confounded by the particular LIBERO trajectories or VLM outputs.
minor comments (1)
- [§3.3] Notation for interference scores and phase capacity parameters is introduced without explicit definitions or default values, complicating replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve technical detail, statistical reporting, and component isolation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Auto-PC description): No equations, pseudocode, or parameter values are provided for the unsupervised action-signal change-point detection or the VLM verification step, so it is impossible to assess whether the extracted boundaries reliably isolate causally critical sub-skills as required for the phase-centric allocation claim.
Authors: We agree that §3.2 lacks the necessary technical specifications. In the revised manuscript we will add the exact equations for the action-signal change-point detection (including the cost function and detection threshold), full pseudocode for the Auto-PC pipeline (change-point detection followed by VLM verification), and all hyperparameter values used on LIBERO (e.g., window size, VLM prompt template, and verification confidence threshold). revision: yes
-
Referee: [Table 2] Table 2 / §5 (LIBERO results): The headline ASR improvements (up to 31% lift, 87.8% final ASR) are reported without error bars, standard deviations, or number of random seeds, leaving open whether the gains are statistically distinguishable from matched-budget ER.
Authors: We acknowledge the absence of variability measures. Although the original experiments used multiple seeds, these statistics were not reported. We will rerun all LIBERO evaluations with 5 random seeds, update Table 2 and §5 with mean ASR ± standard deviation, and add a note on statistical distinguishability from the matched-budget ER baseline. revision: yes
-
Referee: [§5.1] §5.1 (Ablations): There is no ablation that isolates Auto-PC phase extraction from the subsequent capacity allocation and interference routing; without it, the central attribution of gains to phase-centric allocation cannot be verified and could be confounded by the particular LIBERO trajectories or VLM outputs.
Authors: We agree that an ablation isolating Auto-PC is required to support the central claim. We will add a new experiment in §5.1 comparing full PHASER against a controlled variant that uses the same capacity allocation and interference routing but replaces Auto-PC phases with either uniform segmentation or manually annotated boundaries, thereby isolating the contribution of the unsupervised phase extraction. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution with no derivation chain
full rationale
The paper presents PHASER as an architecture-agnostic continual learning framework relying on phase-centric allocation, interference routing, and Auto-PC for unsupervised phase boundary extraction. No equations, mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description. Claims rest on experimental ASR improvements (up to 31% over ER, 87.8% final ASR) across VLA backbones on LIBERO, which are externally falsifiable via replication and do not reduce to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
free parameters (2)
- phase capacity allocation parameters
- interference routing thresholds
axioms (2)
- domain assumption Manipulation trajectories contain identifiable phases whose uniform sampling leads to phase starvation.
- domain assumption VLM-based semantic verification can reliably label change points detected from action signals.
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
McCloskey and N
M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of Learning and Motivation, 24:109–165, 1989
1989
-
[5]
Rolnick, A
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne. Experience replay for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[6]
H. Liu, C. Kim, B. Liu, M. Liu, and Y . Zhu. Pretrained vision-language-action models are surprisingly resistant to forgetting in continual learning.arXiv preprint arXiv:2603.03818, 2026
arXiv 2026
- [7]
-
[8]
H. Fu, P. Sharma, E. Stengel-Eskin, G. Konidaris, N. L. Roux, M.-A. Côté, and X. Yuan. Language-guided skill learning with temporal variational inference.arXiv preprint arXiv:2402.16354, 2024
arXiv 2024
-
[9]
J. S. Smith, L. Valkov, S. Halbe, V . Gutta, R. Feris, Z. Kira, and L. Karlinsky. Adaptive memory replay for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3605–3615, 2024
2024
-
[10]
J. Deng, Z. Wang, S. Cai, A. Liu, and Y . Liang. Open-world skill discovery from unsegmented demonstrations.arXiv preprint arXiv:2503.10684, 2025
arXiv 2025
-
[11]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[12]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[13]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[14]
S. Community. Starvla: A lego-like codebase for vision-language-action model developing. arXiv preprint arXiv:2604.05014, 2026
Pith/arXiv arXiv 2026
-
[15]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[16]
Zhang, Z
Q. Zhang, Z. Liu, H. Fan, G. Liu, B. Zeng, and S. Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025. 9
2025
-
[17]
Aljundi, E
R. Aljundi, E. Belilovsky, T. Tuytelaars, L. Charlin, M. Caccia, M. Lin, and L. Page-Caccia. Online continual learning with maximal interfered retrieval.Advances in neural information processing systems, 32, 2019
2019
-
[18]
Rebuffi, A
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[19]
Lopez-Paz and M
D. Lopez-Paz and M. Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
2017
-
[20]
Y . Luo, W. Chen, T. Liang, and Z. Li. Coral: Scalable multi-task robot learning via lora experts. arXiv preprint arXiv:2603.09298, 2026
arXiv 2026
-
[21]
Z. Liu, J. Zhang, K. Asadi, Y . Liu, D. Zhao, S. Sabach, and R. Fakoor. Tail: Task-specific adapters for imitation learning with large pretrained models. InInternational Conference on Learning Representations, volume 2024, pages 16330–16353, 2024
2024
-
[22]
R. Romer, Y . Zhang, and A. P. Schoellig. Clare: Continual learning for vla models via autonomous adapter routing and expansion.arXiv preprint arXiv:2601.09512, 2026
Pith/arXiv arXiv 2026
-
[23]
Y . Wu, G. Wang, Z. Yang, et al. Stellar vla: Continually evolving skill knowledge in vision language action model.arXiv preprint arXiv:2511.18085, 2025
Pith/arXiv arXiv 2025
-
[24]
J. Hu, J. Shim, C. Tang, et al. Simple recipe works: Vision-language-action models are natural continual learners with reinforcement learning.arXiv preprint arXiv:2603.11653, 2026
Pith/arXiv arXiv 2026
-
[25]
W. Wan, Y . Zhu, R. Shah, and Y . Zhu. Lotus: Continual imitation learning for robot manipulation through unsupervised skill discovery. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 537–544. IEEE, 2024
2024
-
[26]
Zheng, J.-F
Z. Zheng, J.-F. Cai, X.-M. Wu, Y .-L. Wei, Y .-M. Tang, A. Wu, and W.-S. Zheng. imanip: Skill- incremental learning for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13890–13900, 2025
2025
-
[27]
A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajber, A. Alemi, and R. Zhao. On tiny episodic memories in continual learning.arXiv preprint arXiv:1902.10486, 2019
Pith/arXiv arXiv 1902
-
[28]
Aljundi, M
R. Aljundi, M. Lin, B. Goujaud, and Y . Bengio. Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[29]
O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
Pith/arXiv arXiv 2017
-
[30]
W. Guo, Z. Chen, S. Wang, J. He, Y . Xu, J. Ye, Y . Sun, and H. Xiong. Logic-in-frames: Dynamic keyframe search via visual semantic-logical verification for long video understanding.Advances in Neural Information Processing Systems, 38:124389–124422, 2026
2026
-
[31]
S. Wang, W. Guo, Z. Chen, Y . Xu, X. Hu, and H. Xiong. Less is more: Token-efficient video-qa via adaptive frame-pruning and semantic graph integration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9856–9866, 2026
2026
-
[32]
S. Wang, W. Guo, Z. Chen, X. Hu, and H. Xiong. Where to focus: Query-modulated multimodal keyframe selection for long video understanding.arXiv preprint arXiv:2604.17422, 2026
Pith/arXiv arXiv 2026
-
[33]
zero-forward-cost
X. Tang, J. Qiu, L. Xie, Y . Tian, J. Jiao, and Q. Ye. Adaptive keyframe sampling for long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025. 10 A Implementation Details Training Infrastructure.All experiments are conducted on NVIDIA A800-SXM4-80GB GPUs with 2-GPU data parallelism via PyT...
2025
-
[34]
For every taskT k, the bucket associated with phase index0is left empty (capacity0)
-
[35]
For a baseline of K=278 and |ϕk|=4 this yields 370 frames for 3 siblings, exactly preserving the1112-frame per-task total
The released allocation K is redistributed uniformly across the task’s remaining|ϕk|−1 phases: each surviving phase is allotted ⌊K· |ϕ k|/(|ϕk|−1)⌋ frames, with any single-frame remainder absorbed by the first sibling. For a baseline of K=278 and |ϕk|=4 this yields 370 frames for 3 siblings, exactly preserving the1112-frame per-task total
-
[36]
approach
The Boltzmann routing distribution is left untouched. Empty buckets are automatically filtered out by PHASER’s existing _PhaseStore.active_phase_ids mask, so no other code path requires modification and the routing temperature, prototypes, and per-step replay path remain bit-equivalent to baseline. A 5-step smoke validation confirms the invariant: after t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.