AgentAtlas: Beyond Outcome Leaderboards for LLM Agents
Pith reviewed 2026-05-21 06:31 UTC · model grok-4.3
The pith
Explicit control labels in prompts are essential for high-performing LLM agent evaluations
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
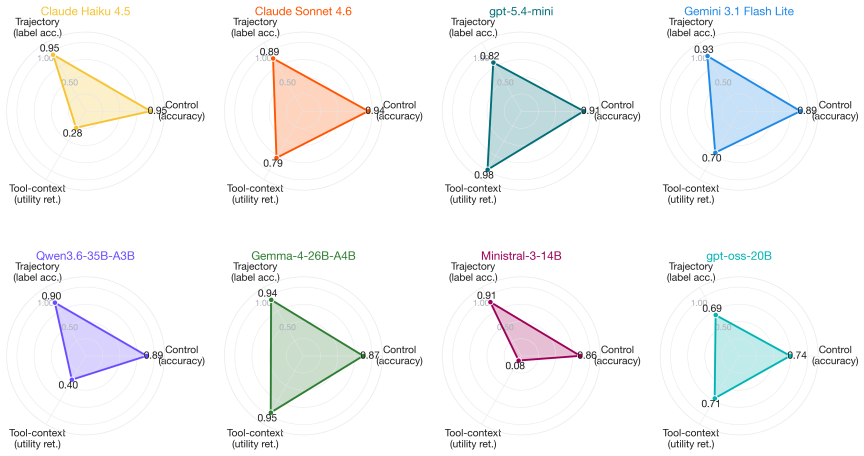
The paper claims that agent evaluations must move beyond single accuracy columns by using a six-state control taxonomy and a nine-category trajectory-failure taxonomy, and that a taxonomy-aware versus taxonomy-blind test reveals how much of measured performance comes from prompt supervision rather than intrinsic capability.
What carries the argument
The taxonomy-aware versus taxonomy-blind methodology that measures the contribution of explicit label menus to trajectory accuracy.
If this is right
- Trajectory accuracy depends on the presence of explicit decision and failure labels.
- No single model leads across control accuracy, diagnosis quality, and tool-context retention.
- Existing agent benchmarks cover only a subset of the six behavioral axes identified.
- Performance floors appear independent of model family when supervision is minimized.
Where Pith is reading between the lines
- Developers could use these taxonomies to create more robust training objectives for agents.
- The methodology might help identify which benchmarks are most informative for real-world deployment.
- Uniform performance without labels points to shared architectural limits in current LLMs for autonomous operation.
Load-bearing premise
The six-state control taxonomy and nine-category failure taxonomy are complete and non-overlapping enough to classify behaviors across the fifteen benchmarks without major gaps.
What would settle it
Testing the eight models on new agent tasks outside the original fifteen benchmarks and checking whether accuracy still drops uniformly into the 0.54-0.62 range without labels.
Figures



read the original abstract
Large language model agents now act on codebases, browsers, operating systems, calendars, files, and tool ecosystems, but the benchmarks used to evaluate them are fragmented: each emphasizes a different unit of measurement (final task success, tool-call validity, repeated-pass consistency, trajectory safety, or attack robustness). A line of 2024-2025 work has converged on the diagnosis that a single accuracy column is no longer the right unit of comparison for deployable agents. AgentAtlas extends this line of work with four components: (i) a six-state control-decision taxonomy (Act / Ask / Refuse / Stop / Confirm / Recover); (ii) a nine-category trajectory-failure taxonomy with two orthogonal hierarchical labels (primary_error_source, impact); (iii) a taxonomy-aware vs. taxonomy-blind methodology that measures how much of a model's apparent capability comes from the supervision in the prompt; and (iv) a benchmark-coverage audit mapping fifteen agent benchmarks against six behavioral axes. To demonstrate the methodology we run a small fixed eight-model set (1,342 generated items, four frontier closed and four open-weight) under both prompt modes. Removing the explicit label menu drops every model's trajectory accuracy by 14-40 pp to a tight 0.54-0.62 floor regardless of family, and no single model wins on all three of control accuracy, trajectory diagnosis, and tool-context utility retention. We treat the synthetic run as a measurement-protocol demonstration, not a benchmark release.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AgentAtlas as a framework extending 2024-2025 work on LLM agent evaluation beyond single accuracy metrics. It introduces a six-state control-decision taxonomy (Act/Ask/Refuse/Stop/Confirm/Recover) and a nine-category trajectory-failure taxonomy (with primary_error_source and impact labels), a taxonomy-aware versus taxonomy-blind prompting methodology to isolate the effect of explicit supervision, and a benchmark-coverage audit across fifteen agent benchmarks. In a demonstration run on a fixed set of eight models (four closed, four open-weight) producing 1,342 items, removing the explicit label menu from prompts drops trajectory accuracy by 14-40 pp to a 0.54-0.62 floor independent of model family, with no model dominating all three reported metrics (control accuracy, trajectory diagnosis, tool-context utility retention). The synthetic run is positioned as a measurement-protocol demonstration rather than a benchmark release.
Significance. If the taxonomies are shown to be robust, the work usefully demonstrates that much of current agent performance on benchmarks may derive from prompt supervision rather than intrinsic capability, producing a surprisingly tight performance floor once that supervision is removed. The taxonomy-aware/blind contrast and the coverage audit provide concrete tools for more diagnostic evaluation. The explicit framing as a protocol demonstration rather than leaderboard is a strength that keeps the scope proportionate.
major comments (2)
- [Taxonomy definitions and demonstration setup] The central claim of a model-family-independent accuracy floor (0.54-0.62) and the comparative statement that no model wins on all three metrics rest on reliable assignment of the 1,342 trajectories to the six control states and nine failure categories. The manuscript provides no inter-annotator agreement, coverage audit, or expert validation that the taxonomies are exhaustive and disjoint across the fifteen benchmarks (see the demonstration setup and taxonomy definitions). Without these, both the reported drop magnitudes and the cross-family invariance remain sensitive to label choice.
- [Benchmark-coverage audit] The benchmark-coverage audit is described as mapping fifteen benchmarks against six behavioral axes, yet no quantitative summary (e.g., coverage percentages or gaps per axis) is supplied. This weakens the claim that the chosen taxonomies are broadly applicable for diagnosis.
minor comments (2)
- [Abstract] The abstract states the run is a 'demonstration' but could more explicitly note that the 1,342 items and eight-model set are not intended as a released benchmark or leaderboard.
- [Taxonomy definitions] Notation for the two orthogonal hierarchical labels (primary_error_source, impact) in the nine-category taxonomy would benefit from an explicit example table showing how a single trajectory receives both labels.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our manuscript. We address each of the major comments below and have made revisions to the manuscript where appropriate to strengthen the presentation of our taxonomies and audit.
read point-by-point responses
-
Referee: [Taxonomy definitions and demonstration setup] The central claim of a model-family-independent accuracy floor (0.54-0.62) and the comparative statement that no model wins on all three metrics rest on reliable assignment of the 1,342 trajectories to the six control states and nine failure categories. The manuscript provides no inter-annotator agreement, coverage audit, or expert validation that the taxonomies are exhaustive and disjoint across the fifteen benchmarks (see the demonstration setup and taxonomy definitions). Without these, both the reported drop magnitudes and the cross-family invariance remain sensitive to label choice.
Authors: We agree that formal validation metrics such as inter-annotator agreement would enhance the reliability of the reported results. The trajectories were annotated by the authors using the provided taxonomy definitions, with iterative refinement to ensure consistency. However, we recognize this as a limitation of the current demonstration. We have revised the manuscript to include a detailed description of the annotation process in the demonstration setup section and added a note on the potential sensitivity to labeling choices. Additionally, we plan to incorporate a small IAA study in future extensions of this work. revision: partial
-
Referee: [Benchmark-coverage audit] The benchmark-coverage audit is described as mapping fifteen benchmarks against six behavioral axes, yet no quantitative summary (e.g., coverage percentages or gaps per axis) is supplied. This weakens the claim that the chosen taxonomies are broadly applicable for diagnosis.
Authors: We thank the referee for pointing out this omission. The benchmark-coverage audit was performed by systematically reviewing each of the fifteen benchmarks against the six behavioral axes defined in the taxonomy. We have now added a quantitative summary in the form of a table showing coverage percentages for each axis across the benchmarks, along with identified gaps. This revision provides concrete evidence supporting the applicability of the taxonomies. revision: yes
Circularity Check
No circularity: empirical results from prompt variants on newly introduced taxonomies
full rationale
The paper introduces the six-state control-decision taxonomy and nine-category failure taxonomy as new constructs rather than deriving them from prior equations or self-referential definitions. The central findings (14-40 pp accuracy drop to a 0.54-0.62 floor, and lack of a single dominating model) are obtained by directly running the eight models on 1,342 items under two explicit prompt conditions (taxonomy-aware with label menu vs. taxonomy-blind). No fitted parameters, predictions that reduce to inputs by construction, or load-bearing self-citations appear in the derivation chain. The benchmark-coverage audit and methodology are presented as measurement protocols applied to the generated trajectories, not as outputs forced by the inputs. This is a standard empirical demonstration with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The six-state control-decision taxonomy and nine-category failure taxonomy together capture the relevant behavioral distinctions for agent evaluation.
invented entities (1)
-
Taxonomy-aware versus taxonomy-blind prompt methodology
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agentdojo leaderboard. Online leaderboard. Snapshot 2025-02-24. Anthropic. 2024a. Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku. Technical announcement. Claude computer-use industry con- text. Anthropic. 2024b. Introducing the model context pro- tocol. Technical announcement. MCP ecosystem motivation. Ask or Assume team
work page 2025
-
[2]
Ask or assume? uncertainty-aware clarification-seeking in coding agents. arXiv preprint 2603.26233. Uncertainty- aware multi-agent scaffold lifts SWE-bench Verified resolution from 61.2% to 69.4% via selective asking. Barke et al
-
[3]
Why Do Multi-Agent LLM Systems Fail?
Why do multi-agent llm sys- tems fail? arXiv preprint 2503.13657. 14-mode fail- ure taxonomy for multi-agent systems, 1,600 human- annotated traces, kappa=0.88. Debenedetti et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gaia leaderboard. On- line leaderboard. Snapshot 2026-05-11. Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu
work page 2026
-
[5]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Webvoyager: Building an end-to- end web agent with large multimodal models. arXiv preprint 2401.13919. WebV oyager end-to-end web agent benchmark. Shashank Kapoor, Benedikt Stroebl, Zachary Kirgis, Nikhil Patel, Jonathan Brand, Peter Henderson, Percy Liang, Rishi Bommasani, Dawn Song, Weijia Su, Arvind Narayanan, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Holistic agent leaderboard: The missing infrastructure for ai agent evaluation. arXiv preprint 2510.11977. HAL: mod- els x scaffolds x benchmarks audit with 21,730 roll- outs on 9 systems x 9 benchmarks. Shashank Kapoor, Benedikt Stroebl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan
-
[7]
Siegel, Nitya Nadgir, and Arvind Narayanan
Ai agents that matter. arXiv preprint 2407.01502. Methodology fix separating developer vs. practitioner evaluation and advocating cost reporting alongside accuracy. Li et al
-
[8]
NeurIPS / arXiv preprint 2401.13178
Agentboard: An analytical evaluation board of multi-turn llm agents. NeurIPS / arXiv preprint 2401.13178. AgentBoard analytical framework for multi-turn LLM agent evaluation. MCPTox authors
-
[9]
OSWorld-Human: Benchmarking the Efficiency of Computer-Use Agents
Osworld-human: Bench- marking the efficiency of computer-use agents. arXiv preprint 2506.16042. Efficiency re-analysis of OSWorld: 42.5% standard vs. 17.4% strict step- efficiency metric; per-application latency breakdown. OSWorld team
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Osworld leaderboard. Online leaderboard. Snapshot 2026-04-20. SWE-bench team / OpenAI collaboration
work page 2026
-
[11]
tau-bench sierra leaderboard. Online leaderboard. Snapshot 2026-05-11. web-arena-x
work page 2026
-
[12]
Webarena leaderboard. Online leaderboard. Snapshot 2026-05-11. Xie et al
work page 2026
-
[13]
Survey on Evaluation of LLM-based Agents
Survey on evaluation of llm- based agents. arXiv preprint 2503.16416. Descrip- tive survey mapping existing units of comparison for LLM-based agent evaluation. Yoran et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Agent-as-a-judge: Evaluate agents with agents. arXiv preprint 2410.10934. Agent-as-a-Judge evalu- ation framework using agents to evaluate agents. 10 A Benchmark Coverage Audit — Rubric and Matrix We score each of the 15 audited benchmarks on a 0/1/2 scale across six evaluation axes. The ag- gregated bar chart is Fig. 3 in §6; the underlying per-benchmark...
-
[15]
Trajectory diagnosisreaches 2 only in the three dedicated trajectory works (AgentRx, ATBench, AgentProcessBench).Memory & statehas just one strong benchmark (ToolSandbox).Efficiency hasnobenchmark scoring 2 across the audit — exactly the gap §4.3 (and the OSWorld-Human la- tency analysis in Fig. D.2) is designed to surface. A.1 Compact benchmark reference...
work page 2024
-
[16]
open models are safer under blind mode
Web assistant 1 1 1 0 0 1 Realistic web tasks but limited safety/refusal/recovery taxonomy. Table A.1: Per-benchmark coverage matrix. Columns are the six axes from §4 + §6; cell values are 0/1/2 per the rubric above. The right column is the primary gap each benchmark leaves uncovered. index. Across all eight evaluators we observe exact- step accuracy of 0...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.