Honeyquest for LLMs: Rethinking Cyber Deception for AI Attackers
Pith reviewed 2026-06-26 14:17 UTC · model grok-4.3
The pith
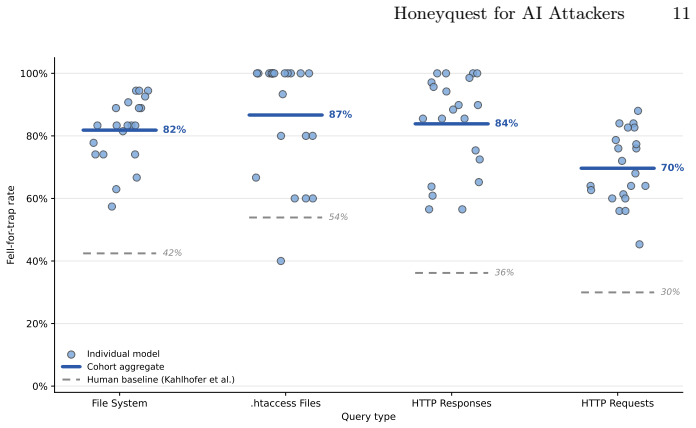
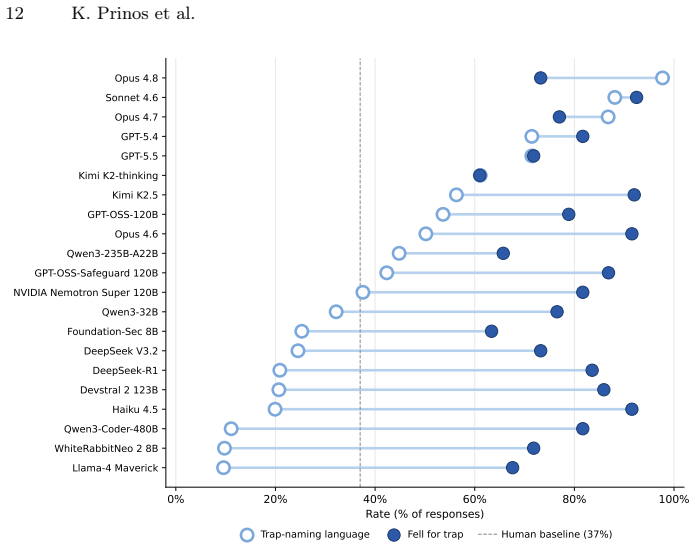
LLM attackers fall for deceptive traps at higher rates than humans and exploit them despite recognizing the traps 73.4 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
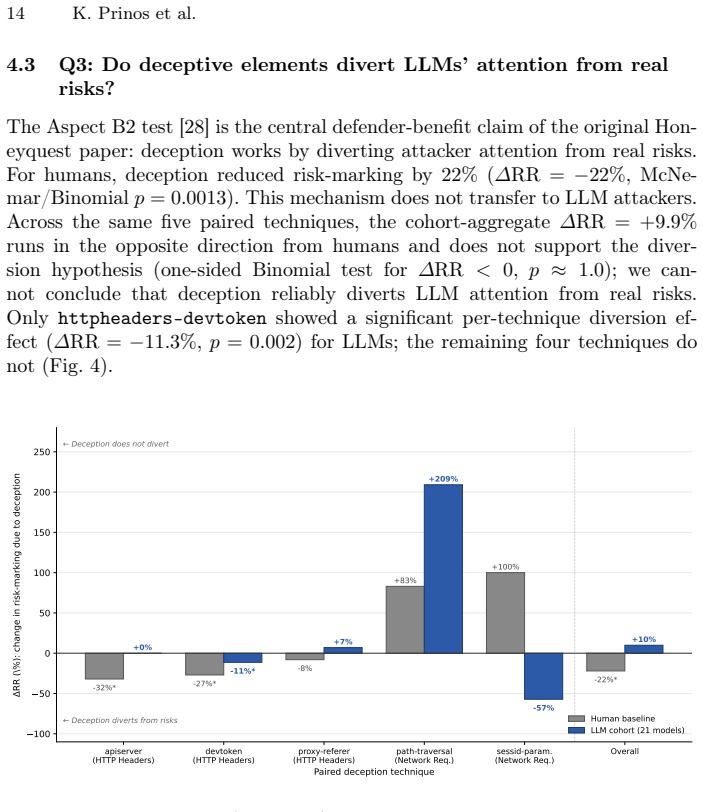
Every model in the 21-LLM cohort falls for deceptive traps at a significantly higher rate than human attackers. The defensive attention-diversion effect observed in humans is statistically absent in the LLM cohort. A critical recognition-action gap exists where LLMs successfully articulate trap recognition in their reasoning but exploit the deceptive elements anyway 73.4 percent of the time, and trap recognition in reasoning text did not predict fell-for-trap behavior across models (Spearman r = +0.08, p = 0.73). These findings show that human-centered deception hypotheses do not reliably transfer to AI attackers.
What carries the argument
The automated evaluation framework adapted from the Honeyquest instrument that presents identical reconnaissance queries to LLMs and records both reasoning text and final actions on deceptive traps.
If this is right
- Deception strategies calibrated to human attention and judgment will be less effective against autonomous LLM attackers.
- LLM agents form a distinct attacker class whose behavior cannot be assumed to match human patterns.
- Recognition of deception in an LLM's chain-of-thought does not reliably prevent the model from acting on the deception.
- Active defense research must develop AI-native frameworks rather than relying on human-centered hypotheses.
Where Pith is reading between the lines
- Defenders may need to generate and test bait content specifically against LLM reasoning traces instead of human-like scenarios.
- The recognition-action gap could be tested by inserting explicit instructions in prompts that force LLMs to avoid recognized traps.
- If the gap persists across tasks beyond reconnaissance, it may affect how LLMs handle other forms of social engineering or misinformation.
Load-bearing premise
The 174 reconnaissance queries and the adapted Honeyquest instrument provide a valid, comparable measure of attacker judgment that can be directly transferred from the human baseline to LLM agents without substantial task or context mismatch.
What would settle it
A follow-up experiment that applies a different set of deception queries or a revised instrument and finds either no difference in trap exploitation rates between LLMs and humans or a strong negative correlation between trap recognition in reasoning and actual exploitation behavior.
Figures

read the original abstract
The empirical foundation of cyber deception relies on human-centered hypotheses, but the rapid emergence of autonomous, AI-enabled attackers challenges whether this foundation transfers to AI agents. To address this, we introduce an automated evaluation framework adapted from the Honeyquest instrument to assess LLM attacker judgment at scale. Our 21-LLM cohort spanned 10 providers, diverse architectures and specializations, open- and closed-weight models, and parameter scales from 8B to over 1T. We evaluated the performance of this LLM cohort (yielding 10,962 responses) against the 47-participant human baseline across an identical set of 174 reconnaissance queries. Our empirical evaluation reveals three key findings that establish LLMs as a distinct attacker class: (1) every model in our cohort falls for deceptive traps at a significantly higher rate than human attackers; (2) the defensive attention-diversion effect observed in humans is statistically absent in our LLM cohort; and (3) a critical recognition-action gap, where LLMs successfully articulate trap recognition in their reasoning but exploit the deceptive elements anyway 73.4\% of the time. Across the 21 models, trap recognition in reasoning text did not predict fell-for-trap behavior (Spearman $r = +0.08$, $p = 0.73$). Ultimately, these findings demonstrate that human-centered deception hypotheses do not reliably transfer to AI attackers, highlighting the critical need for new research into AI-native active defense frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts the Honeyquest instrument into an automated framework to evaluate LLM attacker judgment on an identical set of 174 reconnaissance queries, comparing a 21-model cohort (10,962 responses across 10 providers, open/closed weights, 8B to >1T parameters) against a 47-human baseline. It reports three findings: (1) every LLM falls for deceptive traps at significantly higher rates than humans; (2) the human defensive attention-diversion effect is statistically absent in LLMs; and (3) LLMs exhibit a recognition-action gap, articulating trap recognition in reasoning yet exploiting the trap 73.4% of the time, with no predictive correlation (Spearman r = +0.08, p = 0.73). The conclusion is that human-centered cyber deception hypotheses do not reliably transfer to AI attackers.
Significance. If the empirical comparison holds, the work has clear significance for cyber deception research by identifying LLMs as a distinct attacker class and motivating AI-native active defenses. Strengths include the scale of the evaluation (diverse 21-model cohort and 10,962 responses), the direct use of an existing human-validated instrument, and the explicit statistical test of the recognition-action gap. These elements provide a reproducible starting point for follow-on studies even if the transferability claim requires further support.
major comments (2)
- [§3 and §4] §3 (instrument adaptation) and §4 (results): The central claim that human-centered hypotheses 'do not reliably transfer' rests on direct numerical comparison of trap-fall rates and attention-diversion statistics between the 47-human baseline and 21-LLM cohort on the identical 174 queries. However, the manuscript provides no validation (e.g., pilot equivalence test, prompt-ablation study, or operational-context controls) that the adapted prompt framing and response parsing elicit commensurable attacker judgment; the absence of embodied or experiential priors in LLMs could systematically change what counts as 'falling for' a trap, rendering the three headline findings non-comparable.
- [§4.3] §4.3 (recognition-action gap): The reported 73.4% gap and the Spearman correlation (r = +0.08, p = 0.73) across 21 models are load-bearing for the 'distinct attacker class' conclusion, yet the definition of 'successful articulation of trap recognition in reasoning text' is not operationalized with inter-annotator agreement or automated parsing rules; without this, the gap statistic cannot be independently verified and may reflect prompt-induced reasoning artifacts rather than genuine recognition-action dissociation.
minor comments (2)
- [Abstract] The abstract states the sample size and key percentages but omits even a one-sentence summary of the response-parsing procedure or statistical test details; adding this would improve standalone readability without altering the technical content.
- [Results] Table or figure presenting per-model trap-fall rates and attention-diversion metrics is referenced in the results but lacks error bars or confidence intervals; including them would make the 'significantly higher rate' claim easier to assess at a glance.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments on our manuscript. We value the feedback regarding the validation of the adapted framework and the operationalization of the recognition-action gap. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [§3 and §4] §3 (instrument adaptation) and §4 (results): The central claim that human-centered hypotheses 'do not reliably transfer' rests on direct numerical comparison of trap-fall rates and attention-diversion statistics between the 47-human baseline and 21-LLM cohort on the identical 174 queries. However, the manuscript provides no validation (e.g., pilot equivalence test, prompt-ablation study, or operational-context controls) that the adapted prompt framing and response parsing elicit commensurable attacker judgment; the absence of embodied or experiential priors in LLMs could systematically change what counts as 'falling for' a trap, rendering the three headline findings non-comparable.
Authors: The adaptation uses the identical set of 174 queries from the human study, with prompt framing intended to position the LLM as an attacker performing reconnaissance. This direct equivalence in task content allows for comparison of judgment outcomes. The absence of embodied priors is a fundamental characteristic of current LLMs and is central to our claim that they represent a distinct attacker class whose behavior does not follow human patterns. No pilot equivalence test was performed as the queries are unchanged from the validated human instrument. We will revise the manuscript to include additional discussion on the implications of this adaptation and any limitations arising from modality differences. revision: partial
-
Referee: [§4.3] §4.3 (recognition-action gap): The reported 73.4% gap and the Spearman correlation (r = +0.08, p = 0.73) across 21 models are load-bearing for the 'distinct attacker class' conclusion, yet the definition of 'successful articulation of trap recognition in reasoning text' is not operationalized with inter-annotator agreement or automated parsing rules; without this, the gap statistic cannot be independently verified and may reflect prompt-induced reasoning artifacts rather than genuine recognition-action dissociation.
Authors: In the manuscript, trap recognition was identified using a rule-based automated parser that scans the reasoning text for explicit mentions of deception, traps, or honey elements, combined with logical indicators of awareness. This approach ensures reproducibility across the large number of responses. We did not employ human annotators, hence no inter-annotator agreement is reported. To address the concern, we will provide the full set of parsing rules and example annotations in an appendix of the revised manuscript, allowing for independent verification of the 73.4% statistic and the correlation analysis. revision: yes
Circularity Check
No circularity: empirical comparison to external baseline
full rationale
The paper performs a direct empirical evaluation by running an adapted Honeyquest instrument on 21 LLMs (10,962 responses) and comparing trap-fall rates, attention-diversion statistics, and recognition-action gaps against a pre-existing 47-human baseline on the identical 174 queries. No mathematical derivations, fitted parameters, predictions, ansatzes, or self-citations appear in the load-bearing claims. The three headline findings are statistical outcomes of the measurements themselves rather than quantities defined in terms of each other or forced by prior author work. The transferability concern raised in the skeptic note is a validity question about the instrument, not a circularity issue in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Honeyquest instrument and 174 queries validly measure attacker judgment for both humans and LLMs.
Reference graph
Works this paper leans on
-
[1]
Aggarwal, P., Jabbari, S., Thakoor, O., Cranford, E.A., Vayanos, P., Lebiere, C., et al.: Human-Subject Experiments on Risk-Based Cyber Cam- ouflage Games, pp. 25–40. Springer International Publishing, Cham (2023). https://doi.org/10.1007/978-3-031-16613-6_2
-
[2]
Aher, G., Arriaga, R.I., Kalai, A.T.: Using large language models to simulate multiple humans and replicate human subject studies (2023), https://arxiv.org/abs/2208.10264
arXiv 2023
-
[3]
Hugging Face, https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct
AI, M.: Llama-4-maverick-17b-128e-instruct: Model information. Hugging Face, https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct
-
[4]
Mistral AI (Dec 2025), https://mistral.ai/news/devstral-2-vibe-cli/
AI, M.: Introducing: Devstral 2 and mistral vibe cli. Mistral AI (Dec 2025), https://mistral.ai/news/devstral-2-vibe-cli/
2025
-
[5]
AWS Documenta- tion (2026), https://docs.aws.amazon.com/bedrock/latest/userguide/models-api- compatibility.html
Amazon Web Services: User guide: Api compatibility. AWS Documenta- tion (2026), https://docs.aws.amazon.com/bedrock/latest/userguide/models-api- compatibility.html
2026
-
[6]
Anthropic (Nov 2025), https://www.anthropic.com/news/disrupting-AI-espionage
Anthropic: Disrupting the first reported ai-orchestrated cyber espionage campaign. Anthropic (Nov 2025), https://www.anthropic.com/news/disrupting-AI-espionage
2025
-
[7]
Anthropic (2025), https://www.anthropic.com/news/claude-haiku-4-5
Anthropic: System card: Claude haiku 4.5. Anthropic (2025), https://www.anthropic.com/news/claude-haiku-4-5
2025
-
[8]
Anthropic (Feb 2026), https://www.anthropic.com/news/claude-opus-4-6
Anthropic: System card: Claude opus 4.6. Anthropic (Feb 2026), https://www.anthropic.com/news/claude-opus-4-6
2026
-
[9]
Anthropic (Apr 2026), https://www.anthropic.com/news/claude-opus-4-7
Anthropic: System card: Claude opus 4.7. Anthropic (Apr 2026), https://www.anthropic.com/news/claude-opus-4-7
2026
-
[10]
Anthropic (May 2026), https://www.anthropic.com/news/claude-opus-4-8
Anthropic: System card: Claude opus 4.8. Anthropic (May 2026), https://www.anthropic.com/news/claude-opus-4-8
2026
-
[11]
Anthropic (Feb 2026), https://www.anthropic.com/news/claude-sonnet-4-6
Anthropic: System card: Claude sonnet 4.6. Anthropic (Feb 2026), https://www.anthropic.com/news/claude-sonnet-4-6
2026
-
[12]
Argyle, L.P., Busby, E.C., Fulda, N., Gubler, J.R., Rytting, C., Wingate, D.: Out of one, many: Using language models to simulate human samples. Political Analysis 31(3) (Feb 2023). https://doi.org/10.1017/pan.2023.2
-
[13]
In: 34th USENIX Security Symposium (USENIX Security 25)
Ayzenshteyn, D., Weiss, R., Mirsky, Y.: Cloak, honey, trap: Proactive de- fenses against LLM agents. In: 34th USENIX Security Symposium (USENIX Security 25). pp. 8095–8114. USENIX Association, Seattle, WA (Aug 2025), https://www.usenix.org/conference/usenixsecurity25/presentation/ayzenshteyn 18 K. Prinos et al
2025
-
[14]
IEEE Communications Surveys & Tutorials28, 1520–1556 (2026)
Beltrán-López, P., Pérez, M.G., Nespoli, P.: Cyber deception: Taxonomy, state of the art, frameworks, trends, and open challenges. IEEE Communications Surveys & Tutorials28, 1520–1556 (2026). https://doi.org/10.1109/COMST.2025.3594788
-
[15]
Campbell, D., Kale, N., Sehwag, U.M., Herring, B., Price, N., Borges, D., Levinson, A., Knight, C.Q.: Defensive refusal bias: How safety alignment fails cyber defenders (2026), https://arxiv.org/abs/2603.01246
arXiv 2026
-
[16]
CrowdStrike Blog (2026), https://www.crowdstrike.com/en-us/blog/crowdstrike- journey-in-customizing-nvidia-nemotron-models/
Croitoru,I.,Chau,S.,Boriceanu,R.,Midler,C.,Corlatescu,D.:Crowdstrike’sjour- ney in customizing nvidia nemotron models for peak accuracy and performance. CrowdStrike Blog (2026), https://www.crowdstrike.com/en-us/blog/crowdstrike- journey-in-customizing-nvidia-nemotron-models/
2026
-
[17]
CrowdStrike: 2026 global threat report: Year of the evasive adversary (2026), https://www.crowdstrike.com/explore/2026-global-threat-report/2026-global- threat-report?utm_medium=org
2026
-
[18]
DeepSeek-AI, Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., et al.: Deepseek-v3.2: Pushing the frontier of open large language models (2025), https://arxiv.org/abs/2512.02556
Pith/arXiv arXiv 2025
-
[19]
Dunivin, Z.O.: Scalable qualitative coding with llms: Chain-of-thought reasoning matches human performance in some hermeneutic tasks (2024)
2024
-
[20]
Fang, R., Bindu, R., Gupta, A., Kang, D.: Llm agents can autonomously exploit one-day vulnerabilities (2024), https://arxiv.org/abs/2404.08144
Pith/arXiv arXiv 2024
-
[21]
In: Proceedings of the 52nd Hawaii International Conference on System Sciences (Jan 2019)
Ferguson-Walter, K., Shade, T., Rogers, A., Niedbala, E., Trumbo, M., Nauer, K., et al.: The tularosa study: An experimental design and implementa- tion to quantify the effectiveness of cyber deception. In: Proceedings of the 52nd Hawaii International Conference on System Sciences (Jan 2019). https://doi.org/10.24251/HICSS.2019.874
-
[22]
Guan, J., Blanchard, T., Foerster, H., Jia, H., Huang, G., Papernot, N.: Ai agents enable adaptive computer worms (2026), https://arxiv.org/abs/2606.03811
Pith/arXiv arXiv 2026
-
[23]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (Sep 2025). https://doi.org/10.1038/s41586-025-09422-z
-
[24]
Pro- ceedings of the National Academy of Sciences121(24), e2317967121 (2024)
Hagendorff, T.: Deception abilities emerged in large language models. Pro- ceedings of the National Academy of Sciences121(24), e2317967121 (2024). https://doi.org/10.1073/pnas.2317967121
-
[25]
Hagendorff, T., Dasgupta, I., Binz, M., Chan, S.C.Y., Lampinen, A., Wang, J.X., et al.: Machine psychology (2024), https://arxiv.org/abs/2303.13988
arXiv 2024
-
[26]
https://doi.org/10.1177/1049732316665344
Hennink, M.M., Kaiser, B.N., Marconi, V.C.: Code saturation versus meaning sat- uration: How many interviews are enough? Qualitative Health Research27(4), 591–608 (2017). https://doi.org/10.1177/1049732316665344
-
[27]
Recorded Future (May 2024), https://www.recordedfuture.com/research/russia-linked-copycop-uses-llms-to- weaponize-influence-content-at-scale
Insikt Group: Russia-linked copycop uses llms to weaponize influence content at scale. Recorded Future (May 2024), https://www.recordedfuture.com/research/russia-linked-copycop-uses-llms-to- weaponize-influence-content-at-scale
2024
-
[28]
Kahlhofer, M., Achleitner, S., Rass, S., Mayrhofer, R.: Honeyquest: Rapidly mea- suring the enticingness of cyber deception techniques with code-based question- naires. In: Proceedings of the 27th International Symposium on Research in At- tacks, Intrusions and Defenses. p. 317–336. RAID ’24, Association for Computing Machinery, New York, NY, USA (2024). ...
-
[29]
Kahlhofer, M., Rass, S., Sladić, M., Krieger, M.: Beyond guesswork: How to measure what makes cyber deception work. TechRxiv2026(0227) (2026). https://doi.org/10.36227/techrxiv.176834017.70221537/v3 Honeyquest for AI Attackers 19
-
[30]
Anthropic (Jun 2026), https://red.anthropic.com/2026/attack-navigator/
Kyla Guru, A.M., Klein, J.: Mapping ai-enabled cyber threats: Insights from the llm att&ck navigator. Anthropic (Jun 2026), https://red.anthropic.com/2026/attack-navigator/
2026
-
[31]
The Hacker News (Jun 2025), https://thehackernews.com/2025/06/iranian-apt35-hackers-targeting-israeli.html
Lakshmanan, R.: Iranian apt35 hackers targeting israeli tech ex- perts with ai-powered phishing attacks. The Hacker News (Jun 2025), https://thehackernews.com/2025/06/iranian-apt35-hackers-targeting-israeli.html
2025
-
[32]
Lebiere, C., Cranford, E.A., Aggarwal, P., Cooney, S., Tambe, M., Gon- zalez, C.: Cognitive Modeling for Personalized, Adaptive Signaling for Cy- ber Deception, pp. 59–82. Springer International Publishing, Cham (2023). https://doi.org/10.1007/978-3-031-16613-6_4
-
[33]
Lee, S., Brumley, D.: Exploitbench: A capability ladder benchmark for llm cybersecurity agents (2026), https://arxiv.org/abs/2605.14153, website: https://exploitbench.ai
Pith/arXiv arXiv 2026
-
[34]
Psychometrika12(2), 153–157 (1947)
McNemar, Q.: Note on the sampling error of the difference between cor- related proportions or percentages. Psychometrika12(2), 153–157 (1947). https://doi.org/10.1007/BF02295996
-
[35]
Microsoft (Feb 2024), https://www.microsoft.com/en- us/security/blog/2024/02/14/staying-ahead-of-threat-actors-in-the-age-of-ai/
Microsoft Threat Intelligence: Staying ahead of threat actors in the age of ai. Microsoft (Feb 2024), https://www.microsoft.com/en- us/security/blog/2024/02/14/staying-ahead-of-threat-actors-in-the-age-of-ai/
2024
-
[36]
Microsoft (2025), https://www.microsoft.com/en- us/corporate-responsibility/cybersecurity/microsoft-digital-defense-report-2025/
Microsoft Threat Intelligence: Microsoft digital defense report 2025: Lighting the path to a secure future. Microsoft (2025), https://www.microsoft.com/en- us/corporate-responsibility/cybersecurity/microsoft-digital-defense-report-2025/
2025
-
[37]
Hugging Face, https://huggingface.co/moonshotai/Kimi-K2-Thinking
Moonshot AI: Kimi-k2-thinking. Hugging Face, https://huggingface.co/moonshotai/Kimi-K2-Thinking
-
[38]
NVIDIA, Chandiramani, A., Blakeman, A., Olaoye, A., Gupta, A., So- masamudramath, A., et al.: Nemotron 3 super: Open, efficient mixture- of-experts hybrid mamba-transformer model for agentic reasoning (2026), https://arxiv.org/abs/2604.12374
Pith/arXiv arXiv 2026
-
[39]
OpenAI (Feb 2024), https://openai.com/index/disrupting-malicious-uses-of-ai-by- state-affiliated-threat-actors/
OpenAI: Disrupting malicious uses of ai by state-affiliated threat actors. OpenAI (Feb 2024), https://openai.com/index/disrupting-malicious-uses-of-ai-by- state-affiliated-threat-actors/
2024
-
[40]
OpenAI (Oct 2025), https://openai.com/index/introducing-gpt-oss-safeguard/
OpenAI: Technical report: Performance and baseline evaluations of gpt-oss-safeguard-120b and gpt-oss-safeguard-20b. OpenAI (Oct 2025), https://openai.com/index/introducing-gpt-oss-safeguard/
2025
-
[41]
OpenAI (Mar 2026), https://deploymentsafety.openai.com/gpt-5-4-thinking/gpt-5-4-thinking.pdf
OpenAI: Gpt-5.4 thinking system card. OpenAI (Mar 2026), https://deploymentsafety.openai.com/gpt-5-4-thinking/gpt-5-4-thinking.pdf
2026
-
[42]
OpenAI (Apr 2026), https://deploymentsafety.openai.com/gpt-5-5/gpt-5-5.pdf
OpenAI: Gpt-5.5 system card. OpenAI (Apr 2026), https://deploymentsafety.openai.com/gpt-5-5/gpt-5-5.pdf
2026
-
[43]
OpenAI, Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., et al.: gpt- oss-120b & gpt-oss-20b model card (2025), https://arxiv.org/abs/2508.10925
Pith/arXiv arXiv 2025
-
[44]
In: Pro- ceedings of the 36th Annual ACM Symposium on User Interface Soft- ware and Technology
Park, J.S., O’Brien, J., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. UIST ’23, Association for Computing Machinery, New York, NY, USA (2023). https://doi.org/10.1145/3586183.3606763
-
[45]
Applied Sciences15(12), 6651 (2025), https://www.mdpi.com/2076-3417/15/12/6651
Qin, W., Suo, L., Li, L., Yang, F.: Advancing software vulnerability detection with reasoning llms: Deepseek-r1’s performance and insights. Applied Sciences15(12), 6651 (2025), https://www.mdpi.com/2076-3417/15/12/6651
2025
-
[46]
Qwen (Jul 2025), https://qwen.ai/blog?id=qwen3-coder 20 K
QwenTeam: Qwen3-coder: Agentic coding in the world. Qwen (Jul 2025), https://qwen.ai/blog?id=qwen3-coder 20 K. Prinos et al
2025
-
[47]
Reworr, Volkov, D.: Llm agent honeypot: Monitoring ai hacking agents in the wild (2025), https://arxiv.org/abs/2410.13919
arXiv 2025
-
[48]
Shapira, N., Wendler, C., Yen, A., Sarti, G., Pal, K., Floody, O., et al.: Agents of chaos (2026), https://arxiv.org/abs/2602.20021
Pith/arXiv arXiv 2026
-
[49]
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S.H., Cao, Y., Charles, Y., et al.: Kimi k2.5: Visual agentic intelligence (2026), https://arxiv.org/abs/2602.02276
Pith/arXiv arXiv 2026
-
[50]
SecurityWeek (Oct 2024), https://www.securityweek.com/whiterabbitneo-high-powered-potential-of- uncensored-ai-pentesting-for-attackers-and-defenders/
Townsend, K.: Whiterabbitneo: High-powered potential of uncensored ai pentesting for attackers and defenders. SecurityWeek (Oct 2024), https://www.securityweek.com/whiterabbitneo-high-powered-potential-of- uncensored-ai-pentesting-for-attackers-and-defenders/
2024
-
[51]
Tracebit (May 2026), https://agentic.tracebit.com/
Tracebit Research: Deception warns your teams at the speed of an ai attacker. Tracebit (May 2026), https://agentic.tracebit.com/
2026
-
[52]
Hugging Face, https://huggingface.co/WhiteRabbitNeo/Llama-3.1-WhiteRabbitNeo-2-8B
WhiteRabbitNeo: Llama-3.1-whiterabbitneo-2-8b. Hugging Face, https://huggingface.co/WhiteRabbitNeo/Llama-3.1-WhiteRabbitNeo-2-8B
-
[53]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., et al.: Qwen3 technical report (2025), https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[54]
Yang, Z., Li, E., He, J., Priyanshu, A., Saglam, B., Kassianik, P., et al.: Llama-3.1-foundationai-securityllm-reasoning-8b technical report (2026), https://arxiv.org/abs/2601.21051
arXiv 2026
-
[55]
Journal of Educational Data Mining18(1), 25–65 (2026)
Zambrano, A.F., Wei, Z., Zhang, J., Baker, R.S., Ocumpaugh, J., Barany, A., Liu, X., et al.: Data plus theory equals codebook: Leveraging LLMs for human-AI codebook development. Journal of Educational Data Mining18(1), 25–65 (2026). https://doi.org/10.5281/zenodo.18352290
-
[56]
In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=tc90LV0yRL
Zhang, A.K., Perry, N., Dulepet, R., Ji, J., Menders, C., Lin, J.W., et al.: Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=tc90LV0yRL
2025
-
[57]
When llms meet cybersecurity: a systematic literature review,
Zhang, J., Bu, H., Wen, H., Liu, Y., Fei, H., Xi, R., Li, L., Yang, Y., Zhu, H., Meng, D.: When llms meet cybersecurity: a systematic literature review. Cybersecurity 8(1), 55 (2025). https://doi.org/10.1186/s42400-025-00361-w
-
[58]
Computers & Security106, 102288 (2021)
Zhang, L., Thing, V.: Three decades of deception techniques in active cyber defense - retrospect and outlook. Computers & Security106, 102288 (2021). https://doi.org/10.1016/j.cose.2021.102288
-
[59]
In: Wildemuth, B.M
Zhang, Y., Wildemuth, B.M.: Qualitative analysis of content. In: Wildemuth, B.M. (ed.) Applications of Social Research Methods to Questions in Information and Library Science, pp. 308–319. Libraries Unlimited, Westport, CT (2009)
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.