Mastermind: Strategy-grounded Learning for Repository-Scale Vulnerability Reproduction
Pith reviewed 2026-07-03 13:59 UTC · model grok-4.3
The pith
A trainable planner learns reusable strategies to improve frozen LLM executors on repository-scale vulnerability reproduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
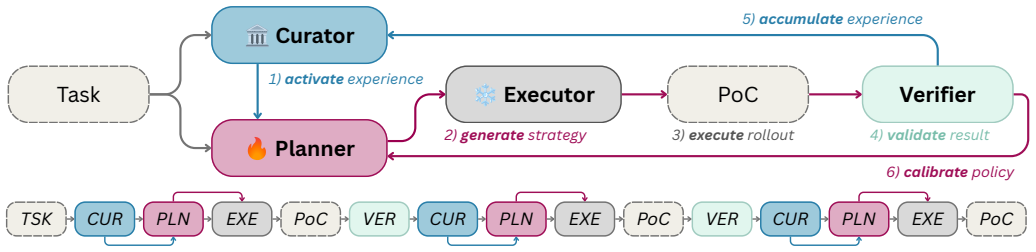
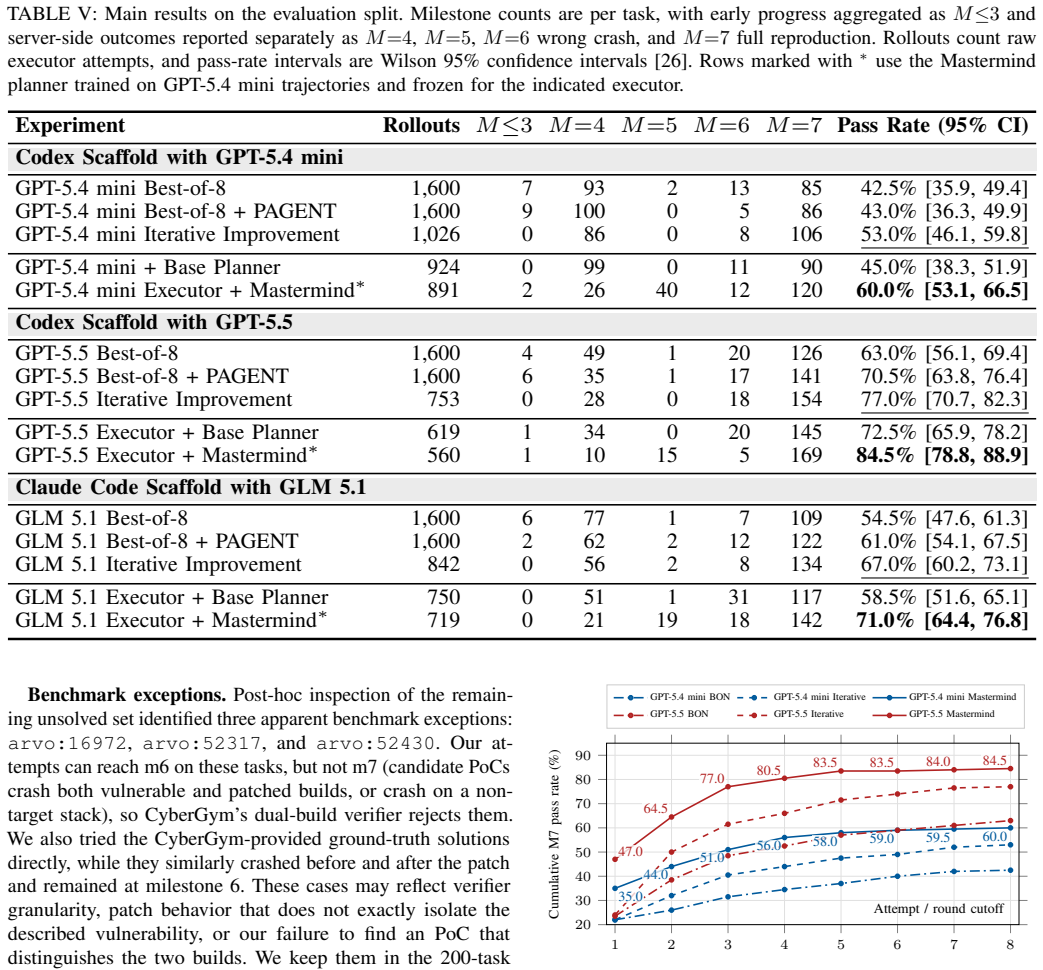
Mastermind separates transferable strategy learning from task-specific experience in a dual-loop framework. A planner learns reusable vulnerability-reproduction strategies through SFT and milestone-based GRPO, while an experience loop maintains task-local strategy records that guide subsequent attempts. The planner is trained independently of the executor, allowing strategy learning to improve multiple frozen executors without modifying their action-generation capability. On CyberGym with 260 training and 200 held-out tasks, the planner lifts GPT-5.5 to an 84.5 percent pass rate and improves GPT-5.4 mini and GLM~5.1 from 45.0 percent and 58.5 percent to 60.0 percent and 71.0 percent.
What carries the argument
The dual-loop framework with a trainable planner that learns reusable strategies via SFT and milestone-based GRPO, kept separate from a frozen executor.
If this is right
- Strategies learned by the planner transfer across different frozen executors without any change to their action-generation process.
- The planner improves performance on held-out tasks from 60 percent to 84.5 percent with GPT-5.5 and produces similar lifts on GPT-5.4 mini and GLM~5.1.
- Task-local strategy records maintained by the experience loop guide later attempts on the same task.
- Learning compact strategies outperforms open-book PoC context, best-of-8 sampling, and iterative improvement.
Where Pith is reading between the lines
- The same separation of strategy from execution could be tested on other repository-scale tasks such as bug localization or patch generation.
- If the learned strategies remain effective when the planner is applied to executors from completely different model families, it would strengthen the case for strategy sharing across organizations.
- Storing and retrieving compact strategies might reduce the number of expensive executor calls needed per task once a planner has been trained.
Load-bearing premise
Vulnerability-reproduction strategies are compact, concrete, and stable enough to be learned once by a planner and then reused across many tasks and executors without the planner needing to see the executor's internal action-generation process.
What would settle it
Train the planner using only one executor family and test whether the resulting strategies still raise success rates when applied to an entirely different, unseen executor family on the same held-out tasks.
Figures

read the original abstract
Repository-level vulnerability reproduction is a demanding software engineering (SE) task: an agent must inspect a codebase, infer the input grammar that reaches a vulnerable path, construct a proof-of-conceptv(PoC), and verify that the crash disappears on the patched build. Recent LLM agents can often execute these steps when the approach is correct, yet they still fail by choosing the wrong strategy. This paper argues that strategy, rather than the full action trajectory, is the right learning unit for such SE agents: it is compact enough to optimize, concrete enough to guide execution, and stable enough to store and reuse across attempts. We present Mastermind, a dual-loop framework that separates transferable strategy learning from task-specific experience. A trainable planner learns reusable vulnerability-reproduction strategies through SFT and milestone-based GRPO, while an experience loop maintains task-local strategy records that guide subsequent attempts. The planner is trained independently of the executor, allowing strategy learning to improve multiple frozen executors without modifying their action-generation capability. We evaluate Mastermind on CyberGym using 260 training tasks and 200 held-out evaluation tasks. With GPT-5.5 as the frozen executor, Mastermind achieves an 84.5% pass rate, outperforming open-book PoC context (60.0%), Best-of-8 sampling (63.0%), and iterative improvement (77.0%). The same planner also improves GPT-5.4 mini and GLM~5.1 from 45.0% and 58.5% to 60.0% and 71.0%. These results demonstrate that learning high-level strategies is an effective and transferable mechanism for improving repository-scale SE agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mastermind, a dual-loop framework for repository-scale vulnerability reproduction that separates a trainable planner learning reusable strategies via supervised fine-tuning (SFT) and milestone-based GRPO from a task-local experience loop. The planner is trained independently on 260 tasks from CyberGym and evaluated on 200 held-out tasks, demonstrating improved pass rates when guiding frozen executors such as GPT-5.5 (84.5% pass rate, outperforming baselines like iterative improvement at 77.0%), and also boosting performance on GPT-5.4 mini and GLM~5.1.
Significance. If the results hold, this work provides evidence that high-level strategy learning can be an effective mechanism for improving LLM-based agents in complex software engineering tasks like vulnerability reproduction. The independent training of the planner and its application to multiple executors without modifying their internals is a notable strength, suggesting a path toward more modular and transferable agent designs. The use of held-out tasks supports the claim of reusability.
major comments (2)
- [Evaluation] Evaluation section: The abstract and evaluation report concrete pass-rate improvements (e.g., 84.5% vs. 77.0%) but supply no information on data splits beyond the 260/200 division, statistical significance, error bars, or implementation details of milestone-based GRPO, which is load-bearing for verifying that the gains are not artifacts of evaluation choices.
- [Method] Method section: The central transferability claim relies on the assumption that strategies are stable and executor-independent, yet the manuscript provides no representation details for learned strategies, no cross-executor consistency checks, and no ablation studies isolating the planner's contribution from the experience loop; this directly impacts the interpretation of the reported lifts on secondary models.
minor comments (1)
- [Abstract] Abstract: The phrase 'proof-of-conceptv(PoC)' appears to contain a typo and should be 'proof-of-concept (PoC)'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The abstract and evaluation report concrete pass-rate improvements (e.g., 84.5% vs. 77.0%) but supply no information on data splits beyond the 260/200 division, statistical significance, error bars, or implementation details of milestone-based GRPO, which is load-bearing for verifying that the gains are not artifacts of evaluation choices.
Authors: We agree that the evaluation section would benefit from greater transparency. The 260/200 division (planner training on 260 tasks, held-out evaluation on 200) is the core split used throughout, as stated in Section 4. We will add error bars computed over multiple random seeds, report statistical significance via appropriate tests for the reported pass rates, and expand the description of milestone-based GRPO (including reward structure, milestone extraction, and hyperparameters) in the revised manuscript. revision: yes
-
Referee: [Method] Method section: The central transferability claim relies on the assumption that strategies are stable and executor-independent, yet the manuscript provides no representation details for learned strategies, no cross-executor consistency checks, and no ablation studies isolating the planner's contribution from the experience loop; this directly impacts the interpretation of the reported lifts on secondary models.
Authors: The transferability claim is supported by training the planner once on the 260 tasks and then applying the identical planner to multiple frozen executors (GPT-5.5, GPT-5.4 mini, GLM~5.1) without any executor modification, as described in Sections 3 and 5. We acknowledge that explicit representation details, cross-executor consistency metrics, and ablations separating the planner from the experience loop are not currently present. We will add these elements—strategy representation as milestone sequences, consistency checks across executors, and targeted ablations—in the revised version. revision: yes
Circularity Check
No circularity; results from held-out evaluation with no fitting reductions
full rationale
The paper reports empirical pass rates from a planner trained on 260 tasks and evaluated on 200 held-out tasks, with improvements shown across multiple frozen executors. No equations, fitting procedures, or self-citations are described that would reduce the reported metrics to quantities defined by the same data or inputs by construction. The derivation chain consists of standard SFT/GRPO training followed by independent evaluation, making the central claims self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vulnerability-reproduction strategies are compact enough to optimize, concrete enough to guide execution, and stable enough to store and reuse across attempts.
Reference graph
Works this paper leans on
-
[1]
An overview of vulnerability assessment and penetration testing techniques,
S. Shah and B. M. Mehtre, “An overview of vulnerability assessment and penetration testing techniques,”Journal of Computer Virology and Hacking Techniques, vol. 11, no. 1, pp. 27–49, 2015
2015
-
[2]
Large language model for vulnerability detection and repair: Literature review and the road ahead,
X. Zhou, S. Cao, X. Sun, and D. Lo, “Large language model for vulnerability detection and repair: Literature review and the road ahead,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 1–31, 2025
2025
-
[3]
Towards robust and secure embodied ai: A survey on vulnerabilities and attacks,
W. Xing, M. Li, M. Li, and M. Han, “Towards robust and secure embodied ai: A survey on vulnerabilities and attacks,”ACM Computing Surveys, vol. 58, no. 12, pp. 1–36, 2026
2026
-
[4]
CyberGym: Evaluating AI agents’ real-world cybersecu- rity capabilities at scale,
Z. Wang, T. Shi, J. He, M. Cai, J. Zhang, and D. Song, “CyberGym: Evaluating AI agents’ real-world cybersecu- rity capabilities at scale,” inInternational Conference on Learning Representations, 2026
2026
-
[5]
MPO: Boosting LLM agents with meta plan optimization,
W. Xiong, Y . Song, Q. Dong, B. Zhao, F. Song, X. Wang, and S. Li, “MPO: Boosting LLM agents with meta plan optimization,” inFindings of the Association for Computational Linguistics: EMNLP, 2025
2025
-
[6]
P. Authors, “PilotRL: Training language model agents via global planning-guided progressive reinforcement learning,”arXiv preprint arXiv:2508.00344, 2025
-
[7]
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Plan-and-Act Authors, “Plan-and-act: Improving plan- ning of agents for long-horizon tasks,”arXiv preprint arXiv:2503.09572, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
CoDA: A context-decoupled hierarchi- cal agent with reinforcement learning,
CoDA Authors, “CoDA: A context-decoupled hierarchi- cal agent with reinforcement learning,”arXiv preprint arXiv:2512.12716, 2025
-
[9]
Expanding LLM agent bound- aries with strategy-guided exploration,
A. Szotet al., “Expanding LLM agent bound- aries with strategy-guided exploration,”arXiv preprint arXiv:2603.02045, 2026
-
[10]
A-MEM: Agentic Memory for LLM Agents
A-Mem Authors, “A-Mem: Agentic memory for LLM agents,” inAdvances in Neural Information Processing Systems, 2025, arXiv:2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
AlphaEvolve: A coding agent for scientific and algorithmic discovery,
Google DeepMind, “AlphaEvolve: A coding agent for scientific and algorithmic discovery,”Google DeepMind Technical Report, 2025
2025
-
[12]
Tree search for LLM agent rein- forcement learning,
Tree-GRPO Authors, “Tree search for LLM agent rein- forcement learning,”International Conference on Learn- ing Representations, 2026, arXiv:2509.21240
-
[13]
Turn-PPO: Turn-level advantage estimation with PPO for improved multi-turn RL in agentic LLMs,
Turn-PPO Authors, “Turn-PPO: Turn-level advantage estimation with PPO for improved multi-turn RL in agentic LLMs,”arXiv preprint arXiv:2512.17008, 2025
-
[14]
Beyond ten turns: Unlocking long- horizon agentic search with large-scale asynchronous RL,
ASearcher Authors, “Beyond ten turns: Unlocking long- horizon agentic search with large-scale asynchronous RL,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[15]
Program Analysis Guided LLM Agent for Proof-of-Concept Generation
PAGENT Authors, “PAGENT: Program-analysis-guided LLM agent for proof-of-concept generation,”arXiv preprint arXiv:2604.07624, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Illuminating search spaces by mapping elites
J.-B. Mouret and J. Clune, “Illuminating search spaces by mapping elites,”arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Quality-diversity optimization: A novel branch of stochastic optimization,
K. Chatzilygeroudis, A. Cully, V . Vassiliades, and J.- B. Mouret, “Quality-diversity optimization: A novel branch of stochastic optimization,” inBlack Box Optimiza- tion, Machine Learning, and No-Free Lunch Theorems. Springer, 2021, pp. 109–135
2021
-
[19]
ARVO: Atlas of Reproducible Vulnerabilities for Open-Source Software
X. Mei, P. Zhang, P. Jadhav, Z. Zhao, I. Bojanova, M. Payer, T. Zhou, C. Giuffrida, M. Neugschwandtner, and A. Narayanan, “ARVO: Atlas of reproducible vul- nerabilities for open source software,”arXiv preprint arXiv:2408.02153, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
OSS-Fuzz - Google’s continuous fuzzing service for open source software,
K. Serebryany, “OSS-Fuzz - Google’s continuous fuzzing service for open source software,” in26th USENIX Security Symposium (USENIX Security 17), 2017
2017
-
[21]
Qwen3.6-35B-A3B,
Qwen Team, “Qwen3.6-35B-A3B,” https://huggingface. co/Qwen/Qwen3.6-35B-A3B, 2026, accessed: 2026-06- 30
2026
-
[22]
Tinker: A training API for researchers and developers,
Thinking Machines Lab, “Tinker: A training API for researchers and developers,” https://tinker-docs. thinkingmachines.ai/tinker/, 2026, accessed: 2026-06-28
2026
-
[23]
Codex: Ai coding partner from OpenAI,
OpenAI, “Codex: Ai coding partner from OpenAI,” https: //openai.com/codex/, 2026, accessed: 2026-06-30
2026
-
[24]
ChatGPT plans and pricing,
——, “ChatGPT plans and pricing,” https://chatgpt.com/ pricing/, 2026, accessed: 2026-06-30
2026
-
[25]
Zhipu AI open platform documentation,
Zhipu AI, “Zhipu AI open platform documentation,” https://docs.bigmodel.cn/cn/guide/start/introduction, 2026, accessed: 2026-06-30
2026
-
[26]
Probable inference, the law of succes- sion, and statistical inference,
E. B. Wilson, “Probable inference, the law of succes- sion, and statistical inference,”Journal of the American Statistical Association, vol. 22, no. 158, pp. 209–212, 1927
1927
-
[27]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V . Le, C. Ré, and A. Mirhoseini, “Large language monkeys: Scaling inference compute with repeated sampling,”arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Language agent tree search unifies reasoning, acting, and planning in language models,
A. Zhou, K. Yan, M. Shlapentokh-Rothman, H. Wang, and Y .-X. Wang, “Language agent tree search unifies reasoning, acting, and planning in language models,” in International Conference on Machine Learning, 2024
2024
-
[29]
Reflexion: Language agents with verbal rein- forcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal rein- forcement learning,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Available: https://arxiv.org/abs/2408.08926
A. K. Yang, L. Jiang, D. Y . Zhu, C. de Fontnouvelle, A. Ngo, S. Ye, N. Muennighoff, D. Boneh, J. Mitchell, D. E. Ho, P. Liang, and N. Li, “CYBENCH: A framework for evaluating cybersecurity capabilities and risks of language model agents,”arXiv preprint arXiv:2408.08926, 2024. 11
-
[32]
NYU CTF dataset: A scalable open-source benchmark dataset for evaluating LLMs in offensive security,
M. Shao, S. Jancheska, M. Udeshi, B. Dolan-Gavitt, H. Xi, K. Milner, B. Chen, M. Bhatt, A. Alarif, and Y . Zeng, “NYU CTF dataset: A scalable open-source benchmark dataset for evaluating LLMs in offensive security,”arXiv preprint arXiv:2406.05590, 2024
-
[33]
InterCode: Standardizing and benchmarking interactive coding with execution feedback,
J. Yang, A. Prabhakar, K. Narasimhan, and S. Yao, “InterCode: Standardizing and benchmarking interactive coding with execution feedback,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[34]
arXiv preprint arXiv:2409.16165 , year=
T. Abramovich, M. Udeshi, M. Shao, K. Lieret, H. Xi, K. Milner, S. Jancheska, J. Yang, C. E. Jimenez, F. Khor- rami, P. Krishnamurthy, B. Dolan-Gavitt, M. Shafique, K. Narasimhan, R. Karri, and O. Press, “EnIGMA: Enhanced interactive generative model agent for CTF challenges,”arXiv preprint arXiv:2409.16165, 2025
-
[35]
CTFAgent: An LLM-powered agent for CTF challenge solving,
Y . Zou, J. Liu, and W. Fan, “CTFAgent: An LLM-powered agent for CTF challenge solving,”Journal of Information Security and Applications, vol. 96, p. 104305, 2025
2025
-
[36]
Cybersecurity AI: The world’s top AI agent for security capture-the-flag (CTF),
V . Mayoral-Vilches, L. J. Navarrete-Lozano, F. Balassone, M. Sanz-Gomez, C. R. J. Veas Chavez, M. del Mundo de Torres, and V . Turiel, “Cybersecurity AI: The world’s top AI agent for security capture-the-flag (CTF),”arXiv preprint arXiv:2512.02654, 2025
-
[37]
PentestAgent: Incorporating LLM agents to automated penetration testing,
X. Shen, L. Wang, Z. Li, Y . Chen, W. Zhao, D. Sun, J. Wang, and W. Ruan, “PentestAgent: Incorporating LLM agents to automated penetration testing,” inACM Asia Conference on Computer and Communications Security, 2025
2025
-
[38]
Cyber-zero: Training cybersecurity agents without run- time,
T. Y . Zhuo, D. Wang, H. Ding, V . Kumar, and Z. Wang, “Cyber-zero: Training cybersecurity agents without run- time,” inInternational Conference on Learning Represen- tations, 2026. 12
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.