ModuLoop : Low-Level Code Generation using Modular Synthesizer and Closed-Loop Debugger for Robotic Control
Pith reviewed 2026-06-28 10:09 UTC · model grok-4.3
The pith
A pre-trained LLM generates and refines low-level robotic control code using modular planning and closed-loop debugging without task-specific fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
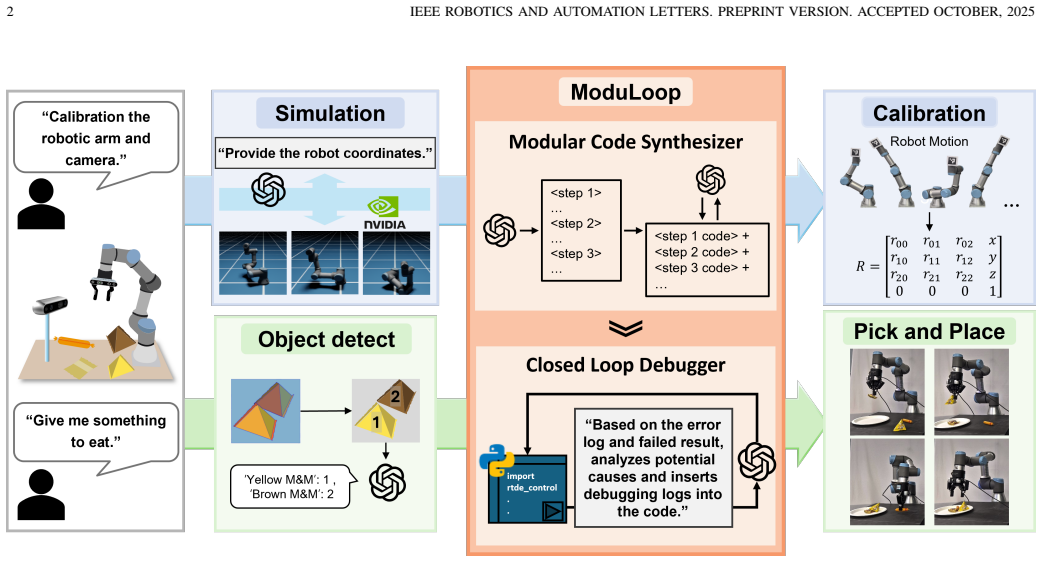
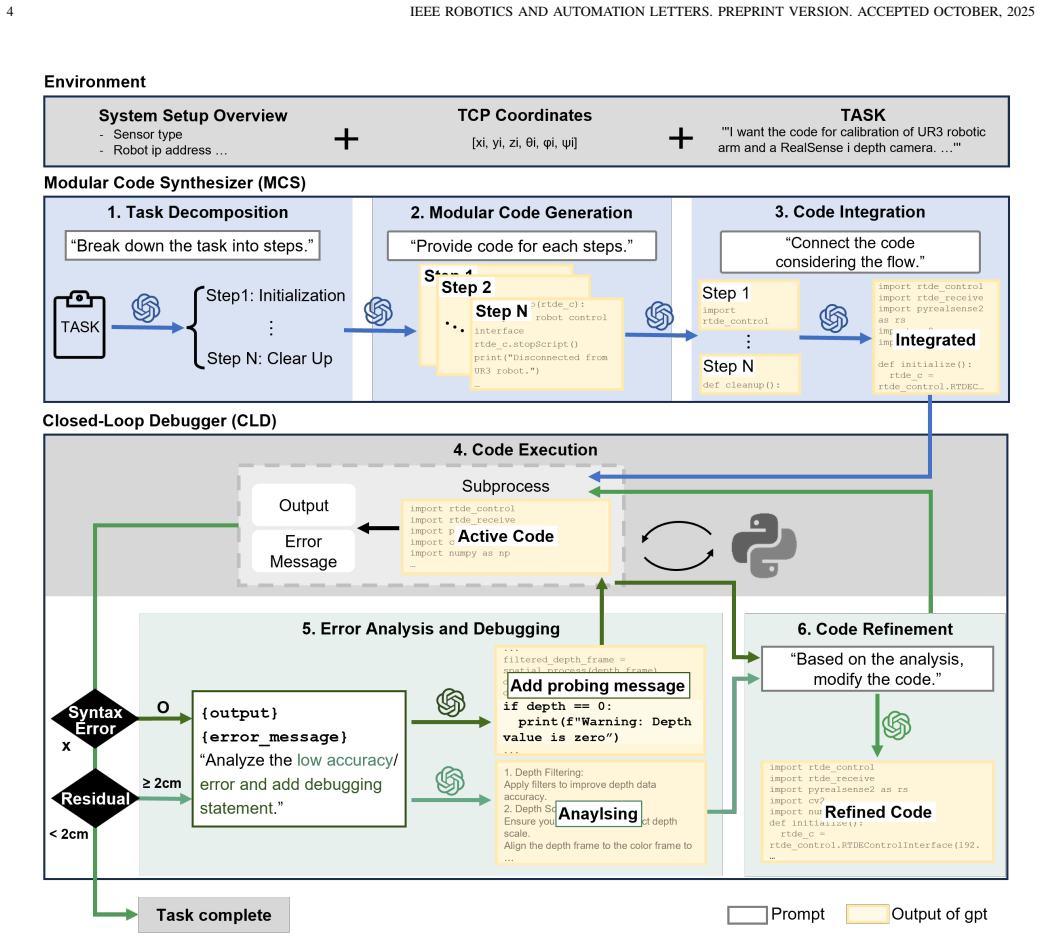
The Closed-Loop Modular Code Synthesizer enables a pre-trained LLM to perform modular code planning and generation for low-level robotic control, then iteratively execute the generated code while inserting debugging probes to observe behavior, systematically debug, and refine the program until it produces executable control code that succeeds on physical hardware for camera calibration and subsequent pick-and-place tasks.
What carries the argument
The closed-loop structure that inserts debugging probes during code execution to enable systematic debugging and iterative refinement by the LLM.
If this is right
- The same modular planning and closed-loop refinement process can be applied to additional low-level robotic tasks beyond calibration and pick-and-place.
- High execution accuracy on hardware demonstrates that LLM-generated code can meet the precision demands of real-world robotic manipulation.
- The framework achieves substantial autonomy, reducing reliance on human-written baselines for each new task.
- Because no task-specific fine-tuning is required, the method scales to new robotic setups by changing only the modular prompts and hardware feedback.
Where Pith is reading between the lines
- The same probe-insertion and refinement loop might transfer to other domains that need precise code generation from feedback, such as embedded controller tuning.
- If the assumption holds, non-experts could direct robots through natural-language task descriptions alone.
- Extending the framework to incorporate additional sensor streams beyond the tested RGB-D and arm encoders would test its generality on more complex environments.
Load-bearing premise
A pre-trained LLM given only modular prompts and execution feedback can reliably produce and refine low-level control code that succeeds on physical hardware without task-specific fine-tuning or human-written baselines.
What would settle it
The generated code repeatedly fails to meet the required calibration precision or pick-and-place success rate on the physical robot after several refinement cycles driven by the debugging feedback.
Figures





read the original abstract
Large Language Models (LLMs) have demonstrated impressive performance across various domains, including code generation and problem solving. However, their application in robotic control, particularly in low-level tasks that require precise manipulation, real-time feedback, and environment-dependent execution, remains limited. To address this challenge, we propose the Closed-Loop Modular Code Synthesizer framework. This framework leverages a pre-trained LLM without any task-specific fine-tuning to perform modular code planning and generation, and iteratively executes the generated code while inserting debugging probes to observe its behavior. This closed-loop structure facilitates systematic debugging and refinement, ultimately producing executable control programs. We apply the proposed framework to the calibration of an RGB-D camera and a robotic arm, validating its effectiveness in real-world settings. Furthermore, through a subsequent pick-and-place task, we demonstrate not only the accuracy of the calibration but also the potential extensibility of the framework. Across both tasks, the framework achieved high execution accuracy and autonomy, illustrating the practicality and scalability of LLM-based robotic control using our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Closed-Loop Modular Code Synthesizer (ModuLoop) framework, which uses a pre-trained LLM (without task-specific fine-tuning) to perform modular code planning and generation for low-level robotic control. The framework iteratively executes generated code while inserting debugging probes for observation and refinement. It is validated on RGB-D camera calibration and a follow-on pick-and-place task, with the claim that it achieves high execution accuracy and autonomy in real-world hardware settings, illustrating practicality and scalability of LLM-based robotic control.
Significance. If the empirical claims hold with supporting data, the work would demonstrate a viable path for autonomous generation and debugging of low-level robotic code using off-the-shelf LLMs, potentially reducing the need for manual programming or fine-tuning in manipulation tasks that require real-time feedback and environment interaction.
major comments (1)
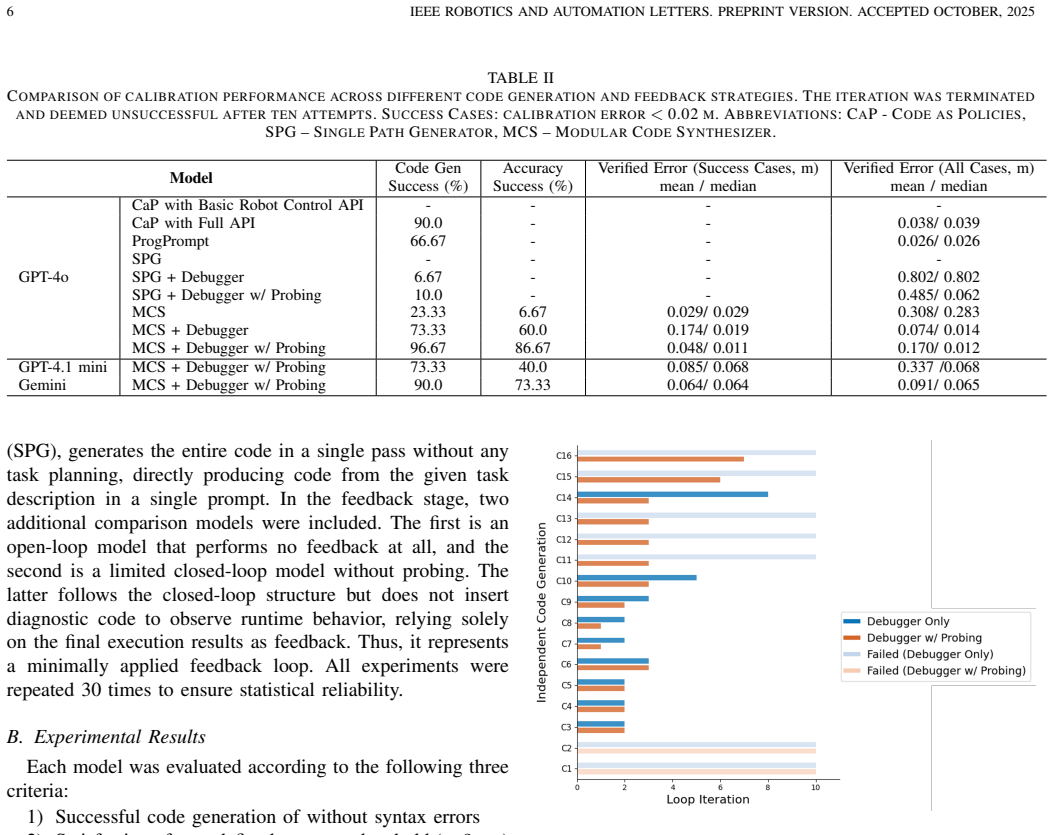
- [Abstract] Abstract: the assertion that 'Across both tasks, the framework achieved high execution accuracy and autonomy' is unsupported by any quantitative metrics, success rates, error measurements, baseline comparisons, or failure cases. This is load-bearing for the central claim of practicality and scalability, as the abstract supplies no data with which to evaluate the weakest assumption that a pre-trained LLM plus modular prompts and execution feedback can reliably produce executable hardware code.
minor comments (1)
- [Abstract] Abstract: the framework is referred to as both 'Closed-Loop Modular Code Synthesizer framework' and 'our framework' before the title's acronym ModuLoop is introduced; consistent early use of the acronym would aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful review and the identification of a clear weakness in the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Across both tasks, the framework achieved high execution accuracy and autonomy' is unsupported by any quantitative metrics, success rates, error measurements, baseline comparisons, or failure cases. This is load-bearing for the central claim of practicality and scalability, as the abstract supplies no data with which to evaluate the weakest assumption that a pre-trained LLM plus modular prompts and execution feedback can reliably produce executable hardware code.
Authors: We agree that the current abstract statement is unsupported by numbers and therefore weakens the central claim. The full manuscript reports concrete experimental outcomes (success rates, calibration errors, and task completion statistics) in the results sections; these were omitted from the abstract. We will revise the abstract to include the specific quantitative metrics, success rates, and any available baseline or failure-case information so that the claim is directly supported by data. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a framework proposal for LLM-driven modular code synthesis and closed-loop debugging in robotic tasks, validated empirically on camera calibration and pick-and-place experiments. No mathematical derivations, equations, fitted parameters, or self-referential predictions are present in the abstract or described structure. All load-bearing claims rest on experimental execution accuracy rather than any reduction to inputs by construction, self-citation chains, or ansatz smuggling. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI, “Gpt-4o,” https://openai.com/index/gpt-4o, 2024, accessed: 2024-04-10
2024
-
[2]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Trans. Softw. Eng. Methodol., Jul. 2025
2025
-
[3]
Language models are few-shot learners,
T. Brownet al., “Language models are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[4]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovichet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 06–09 Nov 2023, pp. 2165–2183
2023
-
[5]
Code as policies: Language model programs for embodied control,
J. Lianget al., “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500
2023
-
[6]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohanet al., “Do as i can, not as i say: Grounding language in robotic affordances,” inConference on robot learning. PMLR, 2023, pp. 287–318
2023
-
[7]
Progprompt: Generating situated robot task plans using large language models,
I. Singhet al., “Progprompt: Generating situated robot task plans using large language models,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 11 523–11 530
2023
-
[8]
V oxposer: Composable 3d value maps for robotic manipulation with language models,
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxposer: Composable 3d value maps for robotic manipulation with language models,” in7th Annual Conference on Robot Learning, 2023
2023
-
[9]
PaLM-E: An Embodied Multimodal Language Model
D. Driesset al., “Palm-e: An embodied multimodal language model,” CoRR, vol. abs/2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohanet al., “Rt-1: Robotics transformer for real-world control at scale,” inRobotics: Science and Systems (RSS), 2023
2023
-
[11]
Robotgpt: Robot manipulation learning from chatgpt,
Y . Jinet al., “Robotgpt: Robot manipulation learning from chatgpt,” IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2543–2550, 2024
2024
-
[12]
Roboscript: Code generation for free-form manipulation tasks across real and simulation,
J. Chenet al., “Roboscript: Code generation for free-form manipulation tasks across real and simulation,”CoRR, vol. abs/2402.14623, 2024
-
[13]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fanget al., “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics (T-RO), 2023
2023
-
[14]
Evaluating Large Language Models Trained on Code
M. Chenet al., “Evaluating large language models trained on code,” CoRR, vol. abs/2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Autogen: Enabling next-gen LLM applications via multi- agent conversations,
Q. Wuet al., “Autogen: Enabling next-gen LLM applications via multi- agent conversations,” inFirst Conference on Language Modeling, 2024
2024
-
[16]
Reflex- ion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: Language agents with verbal reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
2023
-
[17]
arXiv preprint arXiv:2410.15154 , year =
Y . Liet al., “Mccoder: Streamlining motion control with llm-assisted code generation and rigorous verification,”CoRR, vol. abs/2410.15154, 2024
-
[18]
Hand-eye calibration,
R. Horaud and F. Dornaika, “Hand-eye calibration,”The international journal of robotics research, vol. 14, no. 3, pp. 195–210, 1995
1995
-
[19]
Marker data enhancement for markerless motion capture,
A. Falisse, S. D. Uhlrich, A. S. Chaudhari, J. L. Hicks, and S. L. Delp, “Marker data enhancement for markerless motion capture,”IEEE Transactions on Biomedical Engineering, 2025
2025
-
[20]
Kalib: Markerless hand-eye calibration with keypoint tracking,
T. Tang, M. Liu, W. Xu, and C. Lu, “Kalib: Markerless hand-eye calibration with keypoint tracking,”arXiv preprint arXiv:2408.10562, 2024
-
[21]
Automatic robot hand-eye calibration enabled by learning-based 3d vision,
L. Li, X. Yang, R. Wang, and X. Zhang, “Automatic robot hand-eye calibration enabled by learning-based 3d vision,”Journal of Intelligent & Robotic Systems, vol. 110, no. 3, p. 130, 2024
2024
-
[22]
Isaac Sim,
NVIDIA, “Isaac Sim,” https://developer.nvidia.com/isaac-sim, 2021, ac- cessed: 2025-04-30
2021
-
[23]
Segment anything,
A. Kirillovet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.