Memory Makes the Difference: Evaluating How Different Memory Roles Shape Conversational Agents
Pith reviewed 2026-06-25 21:25 UTC · model grok-4.3
The pith
Memories classified by functional role produce distinct effects on conversational agent responses, with clarifying types raising accuracy and irrelevant ones lowering relevance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
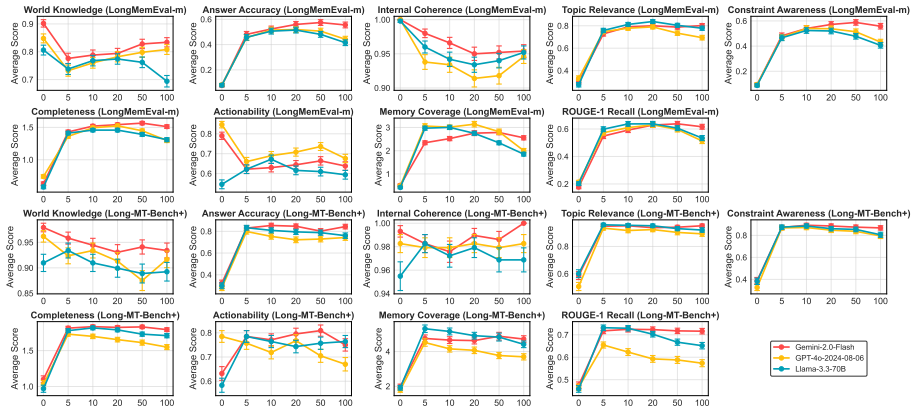
The central claim is that memories with different roles shape agent responses in differentiated ways under varying conversational contexts. Clarifying memory improves factual accuracy and constraint awareness, producing responses that are more correct and personalized. Irrelevant memory reduces topic relevance and degrades constraint awareness. These patterns appear consistently when memories are classified by role and responses are assessed through a user-centric framework on long-term datasets with frontier LLMs.
What carries the argument
A fine-grained taxonomy classifying retrieved memories into functional role types, paired with a user-centric evaluation framework that simulates user perspectives to measure response behaviors.
If this is right
- Prioritizing clarifying memories during retrieval can raise factual accuracy and constraint adherence in generated responses.
- Excluding or down-weighting irrelevant memories can preserve topic relevance and constraint awareness.
- Explicit role classification enables more targeted memory use than uniform retrieval.
- User-centric evaluation surfaces response differences that reference-based metrics miss.
- Role-aware memory handling offers a path to more personalized outputs across frontier models.
Where Pith is reading between the lines
- Retrieval pipelines could incorporate lightweight role classifiers at query time to filter or weight memories dynamically.
- The taxonomy might apply to non-conversational retrieval settings such as long-document question answering.
- Models could be fine-tuned to internalize role distinctions rather than relying on external classification.
- Extending the simulation framework with actual user interaction logs would test whether the observed effects hold in live settings.
Load-bearing premise
The user-centric evaluation framework that simulates user perspectives accurately measures how different memory roles influence response behaviors under varying conversational contexts.
What would settle it
Re-running the same memory-role classifications on the same datasets but scoring responses with direct human ratings or standard reference-based metrics yields no statistically significant quality differences traceable to memory role.
Figures


















read the original abstract
Prior research on memory mechanism in RAG-based conversational system has emphasized how memory is stored and retrieved. However, far less is known about how memories with different functional roles influence response quality. Specifically, how they shape an agent's responses under varying conversational contexts and whether they lead to substantively different response behaviors. Existing evaluations in conversational system are also largely reference-based, insufficiently capturing the nuances in responses that may address users' preferences differently. In this work, we probe the impact of different memory types in shaping agents' responses. We present a fine-grained taxonomy of conversational memory, classify retrieved memories into different role types, and design a user-centric evaluation framework that simulates user perspectives. Through comparative experiments on long-term datasets and frontier LLMs, our analysis reveal many differentiated effects of memories: e.g., clarifying memory improves responses' factual accuracy and constraint awareness, making them more correct and personalized; irrelevant memory reduces topic relevance and degrades constraint awareness. Despite the power of frontier LLMs, these findings shed light on how different memory types can be leveraged to produce more personalized responses and inspire further research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that different functional roles of memory in RAG-based conversational agents produce differentiated effects on response quality. It introduces a fine-grained taxonomy of conversational memory roles, classifies retrieved memories accordingly, and evaluates them via a user-centric framework that simulates user perspectives with LLM judges. Experiments on long-term datasets with frontier LLMs reportedly show that clarifying memory improves factual accuracy and constraint awareness (yielding more correct and personalized responses), while irrelevant memory reduces topic relevance and degrades constraint awareness.
Significance. If the differentiated effects hold under validated measurement, the work would usefully shift focus from storage/retrieval mechanics to functional memory roles, offering concrete guidance for memory filtering in personalized conversational systems. The empirical comparative design on real datasets is a positive feature.
major comments (3)
- [Evaluation Framework] Evaluation Framework section: the central claims rest on LLM-simulated user judgments, yet no correlation with human raters, inter-judge agreement statistics, or ablation of the simulation prompt is reported. This leaves open whether observed differences (e.g., clarifying vs. irrelevant memory effects) reflect genuine user-perceived changes or judge artifacts.
- [Memory Classification] Memory Classification subsection: the method for assigning memories to the fine-grained taxonomy roles is not described (no automated classifier details, human annotation protocol, or agreement metrics), which is load-bearing because all subsequent comparative results depend on the correctness of these role labels.
- [Results] Results section: the abstract and experiments mention differentiated effects but provide no statistical controls, dataset statistics, error analysis, or baseline comparisons that would allow assessment of whether the reported improvements are robust or confounded by prompt length or retrieval volume.
minor comments (2)
- [Abstract] The abstract states that existing evaluations are 'largely reference-based' but does not cite specific prior work; adding 2-3 representative references would clarify the gap.
- [Taxonomy] Notation for memory role categories (e.g., 'clarifying memory') should be defined once in a table or dedicated subsection rather than introduced inline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and will revise the manuscript to improve clarity and rigor where the concerns are valid.
read point-by-point responses
-
Referee: [Evaluation Framework] Evaluation Framework section: the central claims rest on LLM-simulated user judgments, yet no correlation with human raters, inter-judge agreement statistics, or ablation of the simulation prompt is reported. This leaves open whether observed differences (e.g., clarifying vs. irrelevant memory effects) reflect genuine user-perceived changes or judge artifacts.
Authors: We agree that additional validation of the LLM judge would strengthen the evaluation framework. The current manuscript does not include human correlation studies, inter-judge agreement, or prompt ablations. In revision we will add inter-judge agreement statistics and a prompt ablation study. A full-scale human correlation experiment is resource-intensive and may only be partially feasible; we will report what is achievable. revision: partial
-
Referee: [Memory Classification] Memory Classification subsection: the method for assigning memories to the fine-grained taxonomy roles is not described (no automated classifier details, human annotation protocol, or agreement metrics), which is load-bearing because all subsequent comparative results depend on the correctness of these role labels.
Authors: The referee is correct that the classification procedure is under-specified. We will expand the Memory Classification subsection with full details of the automated classifier (including model, prompting, and any post-processing), the human annotation protocol used for validation, and agreement metrics. revision: yes
-
Referee: [Results] Results section: the abstract and experiments mention differentiated effects but provide no statistical controls, dataset statistics, error analysis, or baseline comparisons that would allow assessment of whether the reported improvements are robust or confounded by prompt length or retrieval volume.
Authors: We acknowledge the need for more rigorous statistical presentation. The revised Results section will include dataset statistics, error analysis, baseline comparisons, and explicit controls for prompt length and retrieval volume, along with statistical significance testing of the reported effects. revision: yes
Circularity Check
Empirical evaluation study with no derivation chain or self-referential reductions
full rationale
The paper describes a taxonomy of memory roles, classification of retrieved memories, and a user-centric evaluation framework tested via comparative experiments on external long-term datasets and frontier LLMs. No equations, fitted parameters, predictions of derived quantities, or self-citation chains appear in the provided text. All claims rest on direct experimental comparisons rather than any reduction to inputs by construction, so the analysis is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memories retrieved in RAG systems can be reliably classified into distinct functional role types that causally influence response properties.
invented entities (1)
-
Fine-grained taxonomy of conversational memory roles (e.g., clarifying memory, irrelevant memory)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Benchmarking large language models in retrieval-augmented generation. InProceedings of the Thirty-Eighth AAAI Conference on Artificial In- telligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. AAAI Press. Nuo Chen, Hongguang Li, Jianhui Chan...
Pith/arXiv arXiv 2025
-
[2]
InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 719–729
The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 719–729. Google DeepMind. 2024. Introducing gemini 2.0: our new ai model for the agentic era. Blog post. https: //blog.google/technology/google-deepmind/ google-gemini-ai-updat...
2024
-
[3]
Association for Computational Linguistics
Can LLM be a personalized judge? InFind- ings of the Association for Computational Linguistics: EMNLP 2024, pages 10126–10141. Association for Computational Linguistics. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of...
Pith/arXiv arXiv 2024
-
[4]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Association for Computational Linguistics. Kaushal Kumar Maurya, Kv Aditya Srivatsa, Kseniia Petukhova, and Ekaterina Kochmar. 2025. Unify- ing AI tutor evalua...
Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2310.08560
Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560. Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao
-
[6]
InThe Thir- teenth International Conference on Learning Repre- sentations
Secom: On memory construction and retrieval for personalized conversational agents. InThe Thir- teenth International Conference on Learning Repre- sentations. Filip Radlinski and Nick Craswell. 2017. A theoretical framework for conversational search. InProceedings of the 2017 conference on conference human infor- mation interaction and retrieval, pages 11...
Pith/arXiv arXiv 2017
-
[7]
prompt–test–refine
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memorybank: Enhancing large language models with long-term memory.Proceed- ings of the AAAI Conference on Artificial Intelligence, 38(17):19724–19731. Appendix A Pr...
2024
-
[8]
A response that does not mention world knowledge is not considered inaccurate
World knowledge accuracy - How accurate are the factual statements in the response with respect to general facts and world knowledge. A response that does not mention world knowledge is not considered inaccurate
-
[9]
Answer accuracy - How accurate is the response with respect to the answer provided in the gold response
-
[10]
You should givebinary scoresfor each aspect where 1 means accurate or consistent and 0 means not, and the explanation for the score
Internal consistency - How logically consistent is the response internally. You should givebinary scoresfor each aspect where 1 means accurate or consistent and 0 means not, and the explanation for the score. ###User’s query### {question} ###Chatbot’s response### {agent response} ###Gold answer### {gold answer} You should output only three lines. The firs...
-
[11]
Topical relevance - How directly does the response address the query?
-
[12]
Constraint relevance - How well does the response meet all implicit or explicit constraints and conditions stated or implied by the user’s intent and prior conversation? You should givebinary scoresfor each aspect where 1 means relevant and 0 means not relevant, and the explanation for the score. ###User’s query### {question} ###User’s intent### (optional...
-
[13]
A user’s query to a chatbot
-
[14]
The user’s intent behind the query
-
[15]
The chatbot’s response
-
[16]
Your task is to identify all pieces of information in the chatbot’s response that are recalled from the prior conversation history but were *not* restated in the current user query
The prior conversation history between the user and the chatbot. Your task is to identify all pieces of information in the chatbot’s response that are recalled from the prior conversation history but were *not* restated in the current user query. - Count each such recalled item. - Consider paraphrases or indirect references as recalls. - Ignore generic pl...
-
[17]
Completeness - How well does the response cover all sub-questions or necessary information relevant to the query and intent?
-
[18]
Response is completely generic or contradicts the context
Actionability - How well does the response provide concrete details or clear guidance? Particularly, for aspect Completeness, this is a more detailed scale: Score 0 (Absent): No sign the response noticed the user’s motivations, constraints, or intents. Response is completely generic or contradicts the context. Score 1 (Partial): The response realizes some...
2024
-
[19]
Bakery & Co: A great place to relax and enjoy a cup of coffee and a pastry. 3. Raa Cha Suki & BBQ: If you’re looking for something spicy and delicious, this Thai restaurant is a great option. 4. Sumoboo: This Japanese shaved ice dessert place features a wide variety of flavors, toppings, and combinations. 5. Holycow! Steakhouse by Chef Afit: This steakhou...
-
[20]
Take a cooking class: Bandung is famous for its cuisine, and you can take a cooking class to learn how to make traditional Indonesian dishes such as nasi goreng, sate, and rendang. 6. Visit the Saung Angklung Udjo: This is a cultural center that features traditional music and dance performances with the angklung, a traditional Indonesian instrument made f...
-
[21]
Rumah Mode: This popular factory outlet is famous for its Balinese-inspired architecture and stylish clothing and accessories. 7. Kartika Sari: This bakery is famous for its chocolate brownies and other Indonesian snacks, making it a great place to pick up some tasty treats to take home. Irrelevant Table 10: A judgment case for GPT-5-reasoning to determin...
-
[22]
Doc Martin
Escape Rooms - Orlando has several escape rooms that offer immersive and challenging puzzle-solving experiences. 2. Cirque du Soleil - Watch a mesmerizing acrobatic and theatrical performance by the world-famous Cirque du Soleil, which often performs in Orlando. 3. Airboat Tours - Take an airboat tour through the Florida Everglades and see alligators, bir...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.