Reasoning with Sampling: Cutting at Decision Points
Pith reviewed 2026-06-29 08:14 UTC · model grok-4.3
The pith
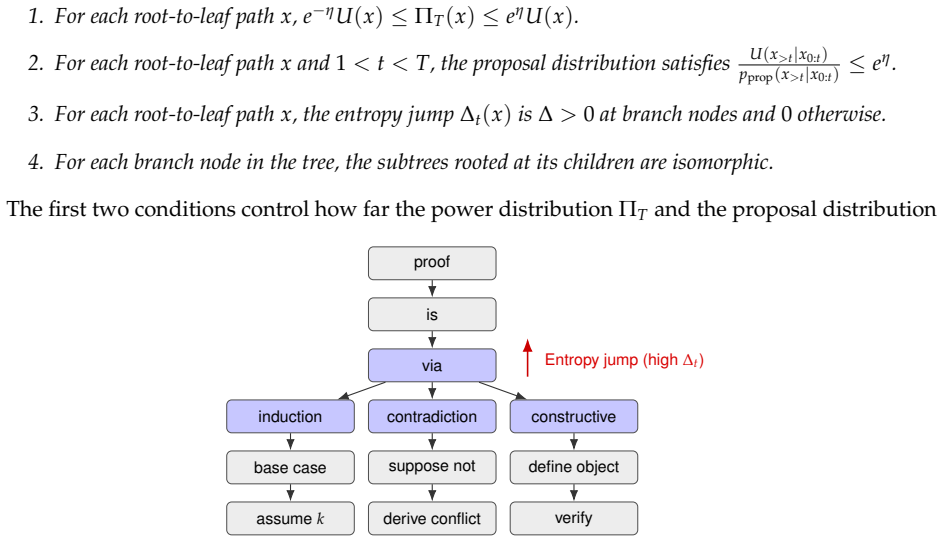
Entropy jumps let samplers cut reasoning traces at decision points, scaling mixing time to the number of decisions instead of tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
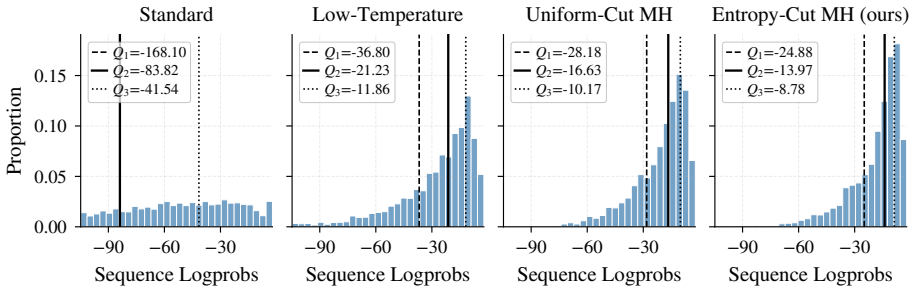
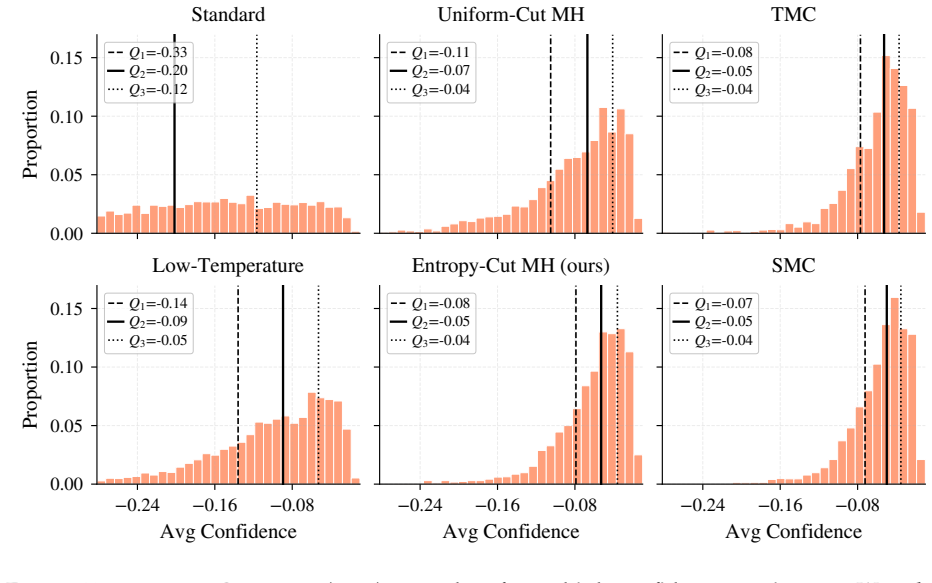
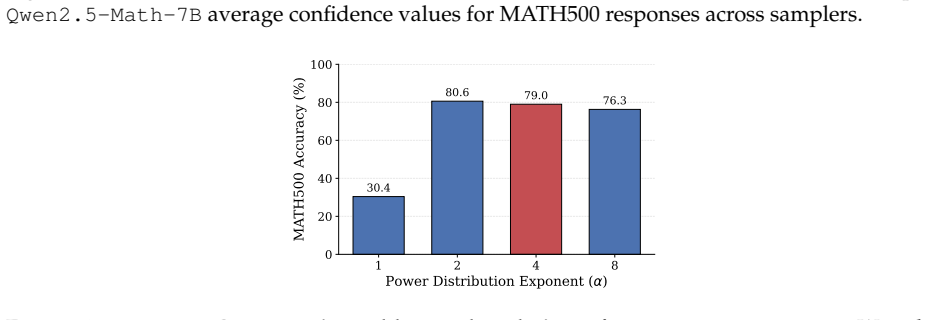
The central claim is that entropy jumps in the base model's next-token predictions identify consequential decision points, so that an Entropy-Cut Metropolis-Hastings sampler mixes to the target power distribution in time proportional to the number of such points; this produces better reasoning performance than uniform random cuts or trained models on the listed benchmarks.
What carries the argument
Entropy-Cut Metropolis-Hastings algorithm that proposes cut positions according to jumps in the base model's next-token entropy and resamples the suffix from those positions.
If this is right
- Mixing time scales with the number of decisions rather than the number of tokens.
- The sampler revisits and revises high-impact choices more often than local details.
- Performance improves consistently over both uniform-cut sampling and RL-trained models on MATH500, HumanEval, GPQA Diamond, and AIME26.
Where Pith is reading between the lines
- If entropy reliably flags decisions, models could be encouraged during pretraining to produce sharper entropy signals at those points.
- The same cut-selection idea might apply to other sampling problems where a small number of choices dominate the output distribution.
- Human studies that label decision points could be used to test or refine the entropy proxy on new domains.
Load-bearing premise
Jumps in the base model's next-token entropy reliably mark the consequential decision points in a reasoning trace rather than incidental local variations.
What would settle it
An experiment in which uniform random cuts achieve the same benchmark scores as entropy-selected cuts, or in which human-labeled decision points show no correlation with entropy jumps.
Figures





read the original abstract
Frontier reasoning models are produced by posttraining base language models with reinforcement learning. Recent work has challenged this by showing that sampling from a sharpened version of the base model's distribution, a so-called power distribution, elicits comparable reasoning without additional training, curated datasets, or verifiers. However, making this method practical requires efficiently sampling from the power distribution. A sampler needs to "mix" to the power distribution, which necessitates moving between modes of the target distribution; intuitively, e.g., trying different reasoning strategies. The samplers proposed in prior works repeatedly select a "cut" position in the current reasoning trace uniformly at random and resample the suffix from that position onward. However, reasoning traces typically contain a few consequential decisions (e.g., the choice of proof strategy or algorithm), and we observe that a uniformly chosen cut tends to rewrite local details rather than revisit decision points. We introduce an algorithm (Entropy-Cut Metropolis-Hastings) that uses the base model's next-token entropy as a proxy to identify key decision points and resample from those positions. We empirically verify that entropy jumps are a useful proxy for decision points and, in a stylized model of reasoning, prove that our method's mixing time scales with the number of decisions in a trace rather than with the number of tokens, which can be much larger. Across MATH500, HumanEval, GPQA Diamond, and AIME26, our method consistently improves over baselines and RL-trained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Entropy-Cut Metropolis-Hastings, which selects cut positions for suffix resampling using jumps in the base model's next-token entropy as a proxy for decision points, enables efficient sampling from the power distribution. In a stylized model it proves that mixing time scales with the number of decisions rather than tokens; empirically it reports consistent gains over uniform-cut baselines and RL-trained models on MATH500, HumanEval, GPQA Diamond, and AIME26.
Significance. If the mixing-time result and the validity of the entropy proxy hold, the work supplies a training-free, parameter-free route to strong reasoning performance that directly challenges the necessity of RL post-training. The explicit scaling proof and the multi-benchmark comparison are concrete strengths that would be of broad interest if substantiated.
major comments (2)
- [Stylized model section (proof of mixing time)] The stylized-model proof that mixing time scales with the number of decisions (rather than tokens) is load-bearing for the efficiency claim, yet the manuscript supplies no definition of the model, no statement of its assumptions, and no derivation steps. Without these, it is impossible to verify whether the claimed O(#decisions) bound actually follows or whether it relies on the very entropy-decision coincidence that the skeptic questions.
- [Empirical verification of entropy proxy] The central modeling assumption—that entropy jumps reliably mark consequential branch points whose resampling mixes distinct reasoning modes—is required for both the theoretical scaling and the empirical gains. The abstract asserts empirical verification of the proxy, but the manuscript provides no quantitative analysis showing that high-entropy positions correspond to strategy-level changes rather than local syntactic variation; this gap directly affects whether the sampler outperforms uniform-cut baselines on the target distribution.
minor comments (2)
- [Experimental results] The abstract and results sections should report the precise number of samples, temperature settings, and statistical significance tests used for the benchmark comparisons.
- [Method description] Notation for the power distribution and the Metropolis-Hastings acceptance ratio should be introduced explicitly with equations rather than left implicit.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive comments. We will revise the manuscript to address the concerns regarding the stylized model and the empirical verification of the entropy proxy, as detailed in our point-by-point responses below.
read point-by-point responses
-
Referee: [Stylized model section (proof of mixing time)] The stylized-model proof that mixing time scales with the number of decisions (rather than tokens) is load-bearing for the efficiency claim, yet the manuscript supplies no definition of the model, no statement of its assumptions, and no derivation steps. Without these, it is impossible to verify whether the claimed O(#decisions) bound actually follows or whether it relies on the very entropy-decision coincidence that the skeptic questions.
Authors: We agree that the current presentation of the stylized model lacks sufficient detail for independent verification. In the revised version, we will provide a complete definition of the stylized model, explicitly state all assumptions, and include full derivation steps for the mixing time result. This will demonstrate that the O(#decisions) scaling derives from the structure of decision points in the model and does not presuppose the entropy proxy. revision: yes
-
Referee: [Empirical verification of entropy proxy] The central modeling assumption—that entropy jumps reliably mark consequential branch points whose resampling mixes distinct reasoning modes—is required for both the theoretical scaling and the empirical gains. The abstract asserts empirical verification of the proxy, but the manuscript provides no quantitative analysis showing that high-entropy positions correspond to strategy-level changes rather than local syntactic variation; this gap directly affects whether the sampler outperforms uniform-cut baselines on the target distribution.
Authors: We acknowledge the need for more rigorous quantitative validation of the entropy proxy. While the manuscript includes some empirical verification, we will enhance this section in the revision by adding quantitative analyses, such as correlations between entropy jumps and annotated strategy changes, or comparisons of resampling outcomes at high- vs. low-entropy positions, to better distinguish strategy-level decisions from syntactic variations. revision: yes
Circularity Check
No circularity: derivation and claims are self-contained
full rationale
The paper introduces Entropy-Cut MH by using next-token entropy as a proxy for decision points, proves an O(#decisions) mixing-time bound in an explicit stylized model, and reports benchmark gains on MATH500/HumanEval/GPQA/AIME26. No equations, fitted parameters, or self-citations are shown that would make any claimed prediction or scaling result equivalent to its own inputs by construction; the entropy-proxy assumption is stated as such rather than derived from the target distribution, and the empirical results are measured against external baselines and RL models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-token entropy serves as a useful proxy for consequential decision points in reasoning traces
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
arXiv: 2209.02001. URL: https://arxiv.org/abs/2209.02001 (cit. on p. 5). [CBIL+23] Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating Large Language Model Decoding with Speculative Sampling. 2023. arXiv: 2302.01318 [cs.CL]. URL: https://arxiv.org/abs/2302.01318 (cit. on p. 18). [CBSP+25] ...
-
[2]
Fast Inference from Transformers via Speculative Decoding
OpenReview.net, 2024. URL: https://openreview.net/forum?id=v8L0pN6EOi (cit. on p. 27). [LKC25] Marvin Li, Aayush Karan, and Sitan Chen. Blink of an Eye: A Simple Theory for Feature Local- ization in Generative Models. 2025. arXiv: 2502.00921. URL: https://arxiv.org/abs/ 2502.00921 (cit. on pp. 4, 19). [LKM23] Yaniv Leviathan, Matan Kalman, and Yossi Matia...
-
[3]
Spurious Rewards: Rethinking Training Signals in RLVR
arXiv: 2506.10947 [cs.AI] (cit. on pp. 1, 4). [WYGZ+25] Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Lea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.