GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
Pith reviewed 2026-05-21 16:59 UTC · model grok-4.3
The pith
Embedding linguistic features into 3D Gaussian primitives aligns text with driving scenes for unified understanding and generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
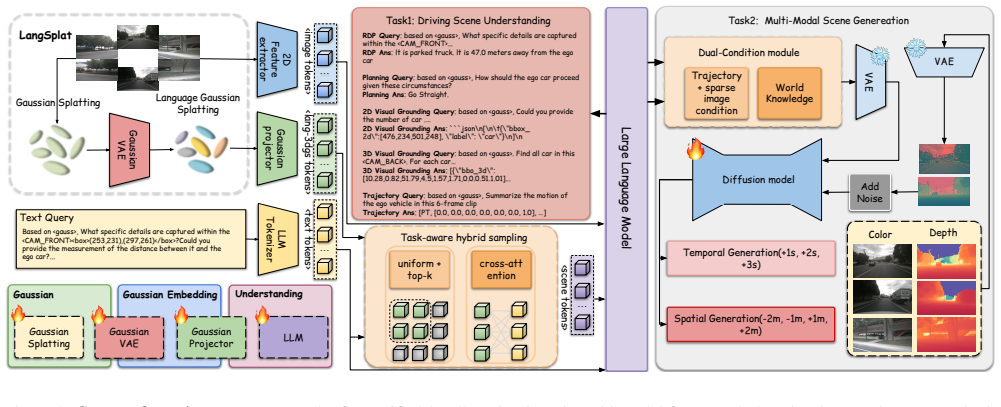
Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment, while enabling both 3D scene understanding and multi-modal scene generation. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process.
What carries the argument
3D Gaussian primitives with embedded rich linguistic features for early modality alignment, combined with task-aware language-guided sampling to produce compact tokens for LLM input.
If this is right
- Textual information aligns early with the underlying 3D scene structure.
- Redundant Gaussians are removed while preserving spatial details for LLM processing.
- High-level language conditions and low-level image conditions jointly guide multi-modal generation.
- The unified framework supports both interpretation and content creation from driving scenes.
Where Pith is reading between the lines
- The compact 3D tokens could support real-time inference in resource-constrained vehicle systems.
- Early text-scene alignment might improve handling of natural language queries about occluded or distant objects.
- The representation could transfer to non-driving domains requiring joint 3D and linguistic reasoning such as robotics navigation.
Load-bearing premise
That embedding linguistic features into each 3D Gaussian primitive produces accurate early modality alignment and that the task-aware language-guided sampling removes redundancy without losing critical 3D spatial details needed for LLM input.
What would settle it
An experiment showing that models without per-primitive linguistic embedding or without language-guided sampling achieve equal or better performance on scene understanding queries and generation metrics would falsify the necessity of the proposed alignment and sampling steps.
Figures







read the original abstract
Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GaussianDWM, a unified driving world model based on 3D Gaussian scene representations. It enables both 3D scene understanding and multi-modal generation by directly embedding rich linguistic features into each Gaussian primitive to achieve early modality alignment, introduces a task-aware language-guided sampling strategy to produce compact 3D tokens for LLM input, and uses a dual-condition generation model that combines high-level language conditions with low-level image conditions. Comprehensive experiments on the nuScenes and NuInteract datasets are reported to achieve state-of-the-art performance.
Significance. If the alignment and performance claims are substantiated, the work offers a promising direction for unified 3D Gaussian frameworks in autonomous driving that integrate geometric representation with language for both reasoning and generation tasks, potentially improving contextual enrichment over point-cloud or BEV approaches.
major comments (1)
- The central claim of early modality alignment via embedding linguistic features into Gaussian primitives (Abstract and Method section) lacks any described joint optimization objective, such as a contrastive, reconstruction, or attention-based loss, that couples language embeddings to the Gaussian parameters (mean, covariance, opacity, spherical harmonics) during 3D scene optimization. Without back-propagation through such an objective, the language features may remain loosely attached post-hoc, undermining the asserted early fusion and the downstream utility for accurate LLM-based scene understanding.
minor comments (2)
- Abstract: the state-of-the-art performance claim on nuScenes and NuInteract is asserted without any quantitative metrics, ablation results, or error analysis; a brief summary of key numbers should be added for immediate verifiability.
- Ensure all implementation details for the language embedding projection, sampling strategy hyperparameters, and dual-condition generation architecture are fully specified in the Experiments section to support reproducibility.
Circularity Check
No circularity: novel framework construction without reductive derivations
full rationale
The paper presents a new unified DWM framework using 3D Gaussian primitives with embedded linguistic features for early modality alignment, plus task-aware sampling and dual-condition generation. No equations, parameter fits, or derivations appear in the provided text that reduce the alignment claim or generation process to self-definitions, fitted inputs renamed as predictions, or self-citation chains. The approach is described as a direct embedding and novel strategy without invoking prior author work as a uniqueness theorem or smuggling ansatzes. Validation on nuScenes and NuInteract is external to any internal reduction, confirming the derivation chain is self-contained as a standard proposal of new components.
Axiom & Free-Parameter Ledger
invented entities (1)
-
3D Gaussian primitives with embedded linguistic features
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt 3D Gaussians as the scene representation... augmented with a language embedding fi... from CLIP features
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Appearance Decomposition Gaussian Splatting for Multi-Traversal Reconstruction
ADM-GS decomposes static background appearance into traversal-invariant material and traversal-dependent illumination via a frequency-separated neural light field, yielding +0.98 dB PSNR gains and better cross-travers...
-
LLM-Augmented Traffic Signal Control with LSTM-Based Traffic State Prediction and Safety-Constrained Decision Support
An LLM-augmented framework combining LSTM traffic prediction, structured LLM reasoning, and safety-constrained filtering improves simulated traffic efficiency under dynamic conditions with zero safety violations.
-
DINO-VO: Learning Where to Focus for Enhanced State Estimation
DINO-VO achieves state-of-the-art monocular visual odometry accuracy and generalization by training a differentiable patch selector together with multi-task features and inverse-depth bundle adjustment.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 5, 6, 9
work page 2020
-
[4]
Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering.arXiv preprint arXiv:2311.18561, 2023. 2, 6, 8
-
[5]
Yi Chen, Tianchen Deng, Wentao Zhao, Xiaoning Wang, Wenqian Xi, Weidong Chen, and Jingchuan Wang. Sn-lidar: Semantic neural fields for novel space-time view lidar syn- thesis.arXiv preprint arXiv:2504.08361, 2025. 2
-
[6]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[7]
Omnire: Omni urban scene reconstruction
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Go- jcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 6, 8
work page 2025
-
[8]
Tianchen Deng, Siyang Liu, Xuan Wang, Yejia Liu, Danwei Wang, and Weidong Chen. Prosgnerf: Progressive dynamic neural scene graph with frequency modulated auto-encoder in urban scenes.arXiv preprint arXiv:2312.09076, 2023. 2
-
[9]
Plgslam: Progressive neural scene represenation with local to global bundle adjustment
Tianchen Deng, Guole Shen, Tong Qin, Jianyu Wang, Wen- tao Zhao, Jingchuan Wang, Danwei Wang, and Weidong Chen. Plgslam: Progressive neural scene represenation with local to global bundle adjustment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19657–19666, 2024. 2
work page 2024
-
[10]
Tianchen Deng, Yue Pan, Shenghai Yuan, Dong Li, Chen Wang, Mingrui Li, Long Chen, Lihua Xie, Danwei Wang, Jingchuan Wang, Javier Civera, Hesheng Wang, and Wei- dong Chen. What is the best 3d scene representation for robotics? from geometric to foundation models.arXiv preprint arXiv:2512.03422, 2025. 3
-
[11]
Tianchen Deng, Guole Shen, Xun Chen, Shenghai Yuan, Hongming Shen, Guohao Peng, Zhenyu Wu, Jingchuan Wang, Lihua Xie, Danwei Wang, Hesheng Wang, and Wei- dong Chen. Mcn-slam: Multi-agent collaborative neural slam with hybrid implicit neural scene representation.arXiv preprint arXiv:2506.18678, 2025. 2
-
[12]
Mne-slam: Multi-agent neural slam for mobile robots
Tianchen Deng, Guole Shen, Chen Xun, Shenghai Yuan, Tongxin Jin, Hongming Shen, Yanbo Wang, Jingchuan Wang, Hesheng Wang, Danwei Wang, et al. Mne-slam: Multi-agent neural slam for mobile robots. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1485–1494, 2025. 2
work page 2025
-
[13]
Tianchen Deng, Yanbo Wang, Hongle Xie, Hesheng Wang, Rui Guo, Jingchuan Wang, Danwei Wang, and Weidong Chen. Neslam: Neural implicit mapping and self-supervised feature tracking with depth completion and denoising.IEEE Transactions on Automation Science and Engineering, 22: 12309–12321, 2025. 2
work page 2025
-
[14]
Tianchen Deng, Wenhua Wu, Junjie He, Yue Pan, Xirui Jiang, Shenghai Yuan, Danwei Wang, Hesheng Wang, and Weidong Chen. Vpgs-slam: V oxel-based progressive 3d gaussian slam in large-scale scenes.arXiv preprint arXiv:2505.18992, 2025. 2
-
[15]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[16]
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601, 2023. 3, 6
-
[17]
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yi- hang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024. 2
work page 2024
-
[18]
Mocount: Motion-based repetitive ac- tion counting
Ruocheng Gu, Sen Jia, Yule Ma, Jinqin Zhong, Jenq-Neng Hwang, and Lei Li. Mocount: Motion-based repetitive ac- tion counting. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9026–9034, 2025. 2
work page 2025
-
[19]
Dist-4d: Disentangled spa- tiotemporal diffusion with metric depth for 4d driving scene generation
Jiazhe Guo, Yikang Ding, Xiwu Chen, Shuo Chen, Bohan Li, Yingshuang Zou, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, Zhiheng Li, and Hao Zhao. Dist-4d: Disentangled spa- tiotemporal diffusion with metric depth for 4d driving scene generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), page 27231–27241,
-
[20]
Dist-4d: Disentangled spatiotemporal diffusion with metric depth for 4d driving scene generation
Jiazhe Guo, Yikang Ding, Xiwu Chen, Shuo Chen, Bohan Li, Yingshuang Zou, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, Zhiheng Li, et al. Dist-4d: Disentangled spatiotemporal diffusion with metric depth for 4d driving scene generation. arXiv preprint arXiv:2503.15208, 2025. 2, 6
-
[21]
Anna-Maria Halacheva, Jan-Nico Zaech, Xi Wang, Danda Pani Paudel, and Luc Van Gool. Gaussianvlm: Scene-centric 3d vision-language models using language- aligned gaussian splats for embodied reasoning and beyond. arXiv preprint arXiv:2507.00886, 2025. 3
-
[22]
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: In- jecting the 3d world into large language models.Advances 17 in Neural Information Processing Systems, 36:20482–20494,
-
[24]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[26]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3, 9
work page 2023
-
[27]
3d and 4d world modeling: A survey
Lingdong Kong, Wesley Yang, Jianbiao Mei, Youquan Liu, Ao Liang, Dekai Zhu, Dongyue Lu, Wei Yin, Xiaotao Hu, Mingkai Jia, et al. 3d and 4d world modeling: A survey. arXiv preprint arXiv:2509.07996, 2025. 2
-
[28]
Uniscene: Unified occupancy-centric driving scene generation
Bohan Li, Jiazhe Guo, Hongsi Liu, Yingshuang Zou, Yikang Ding, Xiwu Chen, Hu Zhu, Feiyang Tan, Chi Zhang, Tiancai Wang, et al. Uniscene: Unified occupancy-centric driving scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11971–11981, 2025. 3
work page 2025
-
[29]
Human motion instruction tuning
Lei Li, Sen Jia, Jianhao Wang, Zhongyu Jiang, Feng Zhou, Ju Dai, Tianfang Zhang, Zongkai Wu, and Jenq-Neng Hwang. Human motion instruction tuning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17582–17591, 2025. 2
work page 2025
-
[30]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong- hao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024. 5
work page 2024
-
[31]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 5
work page 2004
-
[32]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 5, 11, 12
work page 2024
-
[33]
Petr: Position embedding transformation for multi-view 3d object detection
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transformation for multi-view 3d object detection. InEuropean conference on computer vi- sion, pages 531–548. Springer, 2022. 5
work page 2022
-
[34]
Dreamdrive: Generative 4d scene modeling from street view images
Jiageng Mao, Boyi Li, Boris Ivanovic, Yuxiao Chen, Yan Wang, Yurong You, Chaowei Xiao, Danfei Xu, Marco Pavone, and Yue Wang. Dreamdrive: Generative 4d scene modeling from street view images. In2025 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 367–374. IEEE, 2025. 3
work page 2025
-
[35]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2, 3
work page 2021
-
[36]
Neural scene graphs for dynamic scenes
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2856–2865, 2021. 2
work page 2021
-
[37]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[38]
A lesson in splats: Teacher-guided diffusion for 3d gaussian splats generation with 2d supervision
Chensheng Peng, Ido Sobol, Masayoshi Tomizuka, Kurt Keutzer, Chenfeng Xu, and Or Litany. A lesson in splats: Teacher-guided diffusion for 3d gaussian splats generation with 2d supervision. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 28707– 28717, 2025. 2
work page 2025
-
[39]
Chensheng Peng, Chengwei Zhang, Yixiao Wang, Chenfeng Xu, Yichen Xie, Wenzhao Zheng, Kurt Keutzer, Masayoshi Tomizuka, and Wei Zhan. Desire-gs: 4d street gaussians for static-dynamic decomposition and surface reconstruction for urban driving scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6782–6791...
work page 2025
-
[40]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 3, 9
work page 2024
-
[41]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 3
work page 2024
-
[42]
Qijian Tian, Xin Tan, Yuan Xie, and Lizhuang Ma. Driv- ingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 7374–7382, 2025. 2
work page 2025
-
[43]
Suds: Scalable urban dynamic scenes
Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. Suds: Scalable urban dynamic scenes. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12375–12385, 2023. 2
work page 2023
-
[44]
Cider: Consensus-based image description evalua- tion
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalua- tion. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 5
work page 2015
-
[45]
Freevs: Generative view synthesis on free driv- ing trajectory
Qitai Wang, Lue Fan, Yuqi Wang, Yuntao Chen, and Zhaox- iang Zhang. Freevs: Generative view synthesis on free driv- ing trajectory. InProceedings of the International Confer- ence on Learning Representations (ICLR), 2025. 6
work page 2025
-
[46]
Omnidrive: A holistic vision-language dataset for au- tonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Al- 18 varez. Omnidrive: A holistic vision-language dataset for au- tonomous driving with counterfactual reasoning. InProceed- ings of the Computer Vision and Pattern Recognition Confer- ence, pages 22442–22452, 2025. 11, 12
work page 2025
-
[47]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14749–14759, 2024. 2
work page 2024
-
[48]
Yanbo Wang, Zipeng Fang, Lei Zhao, and Weidong Chen. Learning to tune like an expert: Interpretable and scene- aware navigation via mllm reasoning and cvae-based adapta- tion.arXiv preprint arXiv:2507.11001, 2025. 3
-
[49]
Yue Wen, Liang Song, Yijia Liu, Siting Zhu, Yanzi Miao, Lijun Han, and Hesheng Wang. Freedriverf: Monocu- lar rgb dynamic nerf without poses for autonomous driving via point-level dynamic-static decoupling.arXiv preprint arXiv:2505.09406, 2025. 2
-
[50]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InEu- ropean Conference on Computer Vision, pages 399–417. Springer, 2024. 5
work page 2024
-
[51]
Cape: Camera view position embedding for multi-view 3d object detection
Kaixin Xiong, Shi Gong, Xiaoqing Ye, Xiao Tan, Ji Wan, Errui Ding, Jingdong Wang, and Xiang Bai. Cape: Camera view position embedding for multi-view 3d object detection. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 21570–21579, 2023. 5
work page 2023
-
[52]
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Let- ters, 2024. 3
work page 2024
-
[53]
Drivingsphere: Building a high-fidelity 4d world for closed- loop simulation
Tianyi Yan, Dongming Wu, Wencheng Han, Junpeng Jiang, Xia Zhou, Kun Zhan, Cheng-zhong Xu, and Jianbing Shen. Drivingsphere: Building a high-fidelity 4d world for closed- loop simulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27531–27541, 2025. 2
work page 2025
-
[54]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024. 2, 6, 8
work page 2024
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Se- ung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision.arXiv preprint arXiv:2311.02077, 2023. 2, 6
-
[57]
Jiawei Yang, Jiahui Huang, Yuxiao Chen, Yan Wang, Boyi Li, Yurong You, Apoorva Sharma, Maximilian Igl, Peter Karkus, Danfei Xu, et al. Storm: Spatio-temporal re- construction model for large-scale outdoor scenes.arXiv preprint arXiv:2501.00602, 2024. 2
-
[58]
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction, November 2023
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction.arXiv preprint arXiv:2309.13101, 2023. 8
-
[59]
Visual point cloud forecasting enables scalable autonomous driving
Zetong Yang, Li Chen, Yanan Sun, and Hongyang Li. Visual point cloud forecasting enables scalable autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14673–14684, 2024. 2
work page 2024
-
[60]
Drivedreamer-2: Llm-enhanced world models for diverse driving video generation
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video generation. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 10412–10420, 2025. 2
work page 2025
-
[61]
Zongchuang Zhao, Haoyu Fu, Dingkang Liang, Xin Zhou, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Extending large vision-language model for diverse interactive tasks in autonomous driving.arXiv preprint arXiv:2505.08725, 2025. 3, 5, 6
-
[62]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Drivinggaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21634–21643, 2024. 2
work page 2024
-
[64]
Hermes: A unified self-driving world model for simultaneous 3d scene understanding and generation
Xin Zhou, Dingkang Liang, Sifan Tu, Xiwu Chen, Yikang Ding, Dingyuan Zhang, Feiyang Tan, Hengshuang Zhao, and Xiang Bai. Hermes: A unified self-driving world model for simultaneous 3d scene understanding and generation.arXiv preprint arXiv:2501.14729, 2025. 2, 3, 11, 12
-
[65]
Yingshuang Zou, Yikang Ding, Chuanrui Zhang, Jiazhe Guo, Bohan Li, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, and Haoqian Wang. Mudg: Taming multi-modal diffusion with gaussian splatting for urban scene reconstruction.arXiv preprint arXiv:2503.10604, 2025. 2 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.