CNnotator: LLM-Guided Memory Safety Annotation Synthesis
Pith reviewed 2026-06-26 11:19 UTC · model grok-4.3
The pith
Large language models can synthesize CN annotations to represent memory usage in C programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
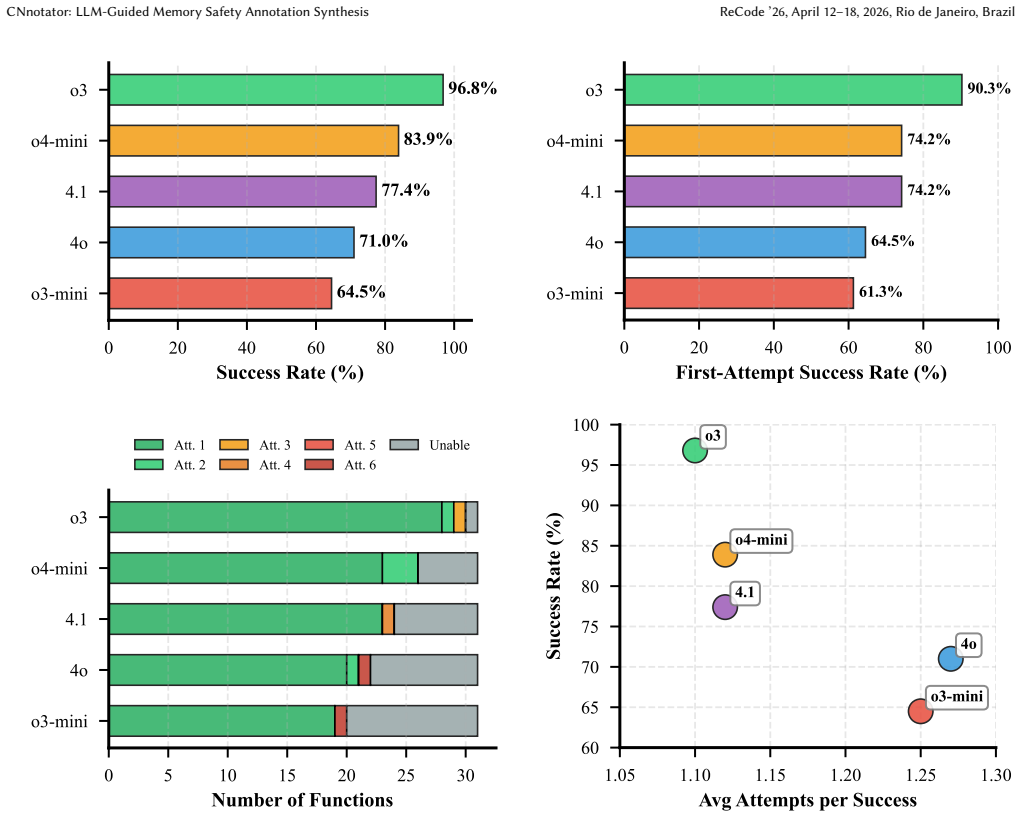
CNnotator shows that LLMs can generate CN specifications that capture memory usage patterns in small-to-medium C programs. The system works by having the model propose annotations and then validating them through CN's hybrid testing and verification capabilities. Reported outcomes include 90 percent first-attempt success and 97 percent overall success for one model, together with 65 percent first-attempt success for another model. The authors conclude that this level of performance makes AI-assisted annotation practical for real-world C codebases.
What carries the argument
CNnotator, the LLM-guided loop that generates candidate CN memory annotations and validates them by running CN tests.
If this is right
- Memory usage in existing C code can be documented without exhaustive manual reverse-engineering.
- CN verification becomes applicable to more programs because the annotation step is automated.
- Memory safety errors can be located earlier in the development or maintenance process.
- Efforts to migrate C systems to memory-safe languages gain an initial explicit model of resource behavior.
Where Pith is reading between the lines
- The same generate-and-test loop could be applied to other specification languages that describe resource usage.
- Annotations produced this way might serve as starting points for stronger formal proofs once testing succeeds.
- For very large codebases the method would likely need to be combined with modular decomposition so that LLMs receive manageable fragments.
Load-bearing premise
The small-to-medium programs chosen for testing are representative of memory usage patterns in larger, real-world C codebases, and successful passage of CN tests confirms that the generated annotations are correct and useful in practice.
What would settle it
A realistic C codebase where repeated LLM attempts produce no set of CN annotations that both pass CN testing and prevent actual memory errors during execution.
Figures

read the original abstract
Memory safety errors account for a large proportion of security bugs in systems written in C; modern languages such as Java and Rust prevent such bugs because they are memory-safe by design. To migrate systems to safer languages or identify memory errors, we must first determine how legacy code manipulates memory. This information is only represented implicitly in such code. In many cases, memory usage patterns are merely tedious for humans to figure out, rather than truly difficult. In this work, we ask if large language models (LLMs) can perform this task by having them synthesize annotations representing memory usage as specifications in CN, a hybrid testing/verification tool. Our tool, CNnotator, uses LLMs to automatically generate and test CN specifications. We find that current models are able to generate CN specifications for small-to-medium C programs, with the OpenAI o3 reasoning model achieving a 90% success rate on first attempts and 97% overall success, while the chat model GPT-4o correctly annotates 65% of first attempts. These results suggest AI-assisted annotation is becoming practical for real-world C codebases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CNnotator, a tool that uses LLMs to automatically generate and test CN specifications for memory-safety properties in C programs. It claims that current models can perform this task on small-to-medium C programs, with the o3 reasoning model achieving 90% success on first attempts and 97% overall, and GPT-4o achieving 65% on first attempts. The work positions this as evidence that AI-assisted annotation is becoming practical for real-world C codebases.
Significance. If the empirical results hold under stronger evaluation, the work would show that LLMs can automate inference of implicit memory-usage patterns that are tedious but not fundamentally difficult, offering a practical aid for verification or language migration of legacy C code. The direct measurement of LLM performance on a concrete annotation task (rather than a fitted or self-referential metric) is a strength.
major comments (2)
- [Evaluation] Evaluation section: The reported success rates (o3: 90% first-attempt / 97% overall; GPT-4o: 65% first-attempt) are presented without any information on the number of programs, selection criteria, size/complexity distribution, or failure-mode breakdown. This information is load-bearing for the central claim that the models succeed on representative small-to-medium C programs.
- [Validation] Validation subsection: The paper treats passage of the CN test suites as confirmation that generated annotations are correct, yet provides no description of how the test inputs were chosen, whether they exercise aliasing or pointer-arithmetic cases, or any argument that the suites constitute a sound oracle. If the tests are derived from the same examples used in prompting or lack coverage, the success percentages do not establish soundness.
minor comments (1)
- [Abstract] Abstract: The phrase 'small-to-medium C programs' is used without a concrete definition (e.g., LOC ranges or cyclomatic complexity), making it difficult to interpret the scope of the reported results.
Simulated Author's Rebuttal
Thank you for the constructive review. The comments correctly identify gaps in the level of detail provided for the evaluation and validation. We will revise the manuscript to supply the missing information and strengthen the presentation of our experimental setup.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported success rates (o3: 90% first-attempt / 97% overall; GPT-4o: 65% first-attempt) are presented without any information on the number of programs, selection criteria, size/complexity distribution, or failure-mode breakdown. This information is load-bearing for the central claim that the models succeed on representative small-to-medium C programs.
Authors: We agree that the Evaluation section requires additional context to support the central claim. The current manuscript reports aggregate success rates but does not characterize the benchmark in detail. In the revised version we will add a dedicated subsection (or expanded table) that reports: the exact number of programs evaluated, the selection criteria and sources, the distribution of program sizes and complexity metrics (e.g., lines of code, number of allocations and pointers), and a categorized breakdown of observed failure modes. These additions will make the applicability to small-to-medium C programs explicit and reproducible. revision: yes
-
Referee: [Validation] Validation subsection: The paper treats passage of the CN test suites as confirmation that generated annotations are correct, yet provides no description of how the test inputs were chosen, whether they exercise aliasing or pointer-arithmetic cases, or any argument that the suites constitute a sound oracle. If the tests are derived from the same examples used in prompting or lack coverage, the success percentages do not establish soundness.
Authors: We acknowledge the need for a clearer justification of the validation oracle. The revised Validation subsection will describe the process used to construct the test inputs, explicitly note whether they cover aliasing, pointer arithmetic, and other relevant cases, and provide an argument for why the suites constitute a reasonable (if not exhaustive) oracle for the memory-safety properties expressed in CN. We will also clarify the relationship between the test cases and any examples appearing in prompts, and we will discuss the inherent limitations of test-based validation. revision: yes
Circularity Check
No circularity: direct empirical measurement of LLM annotation success
full rationale
The paper reports measured success rates (o3 at 90%/97%, GPT-4o at 65%) from an experimental pipeline that prompts LLMs to produce CN annotations and then runs them through the CN testing harness on a set of C programs. No equations, fitted parameters, or derivations are present; the results are raw counts of annotations that pass the provided test suites. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear. The evaluation chain is self-contained and externally falsifiable via the same LLM+CN procedure on new programs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zain K. Aamer and Benjamin C. Pierce. 2025. Bennet: Randomized Specification Testing for Heap-Manipulating Programs.Proceedings of the ACM on Program- ming Languages9, OOPSLA2 (2025), 3924–3953. doi:10.1145/3764115
-
[2]
Anthropic. 2025. Claude Code: An Agentic CLI Coding Assistant. Anthropic. https://claude.ai/code Accessed 2025
2025
-
[3]
Rini Banerjee, Kayvan Memarian, Dhruv Makwana, Christopher Pulte, Neel Krishnaswami, and Peter Sewell. 2025. Fulminate: Testing CN Separation-Logic Specifications in C.Proceedings of the ACM on Programming Languages9, POPL, Article 43 (2025), 33 pages. doi:10.1145/3704879
-
[4]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, and Azalia Mirhoseini. 2024. Large Language Monkeys: Scal- ing Inference Compute with Repeated Sampling. arXiv:2407.21787 [cs.LG] https://arxiv.org/abs/2407.21787
Pith/arXiv arXiv 2024
-
[5]
Twain Byrnes. 2025. Escaping Isla Nublar: Coming Around to LLMs for Formal Methods. Galois Blog. https://www.galois.com/articles/escaping-isla-nublar- coming-around-to-llms-for-formal-methods Published August 18, 2025
2025
-
[6]
Harrison Chase. 2022. LangChain. GitHub repository. https://github.com/ langchain-ai/langchain Accessed 2025
2022
-
[7]
Chromium Security Team. 2025. Memory Safety. Chromium Project Documenta- tion. https://www.chromium.org/Home/chromium-security/memory-safety/ Accessed 2025
2025
-
[8]
Citrus Contributors. 2017. Citrus: C to Rust Converter. GitLab repository. https: //gitlab.com/citrus-rs/citrus Accessed 2025
2017
-
[9]
DARPA Information Innovation Office. 2024. TRACTOR: Translating All C to Rust. DARPA Program Information. https://www.darpa.mil/program/translating- all-c-to-rust Accessed 2025
2024
-
[10]
Chongzhou Fang, Ning Miao, Shaurya Srivastav, Jialin Liu, Ruoyu Zhang, Ruijie Fang, Asmita, Ryan Tsang, Najmeh Nazari, Han Wang, and Houman Homayoun
-
[11]
InProceedings of the 33rd USENIX Security Symposium (USENIX Security 24)
Large Language Models for Code Analysis: Do LLMs Really Do Their Job?. InProceedings of the 33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, Philadelphia, PA, 829–846. https://www.usenix.org/ conference/usenixsecurity24/presentation/fang
-
[12]
Immunant and Galois. 2024. C2Rust: Migrate C Code to Rust. GitHub repository. https://github.com/immunant/c2rust Accessed 2025
2024
-
[13]
Anirudh Khatry, Robert Zhang, Jia Pan, Ziteng Wang, Qiaochu Chen, Greg Durrett, and Isil Dillig. 2025. CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation. arXiv:2504.15254 [cs.SE] https://arxiv.org/abs/ 2504.15254
arXiv 2025
-
[14]
Anirudh Khatry, Robert Zhang, Jia Pan, Ziteng Wang, Qiaochu Chen, Greg Durrett, and Isil Dillig. 2025. CRUST-Bench Project Website. Project Website. https://crust-bench.github.io Accessed 2025
2025
-
[15]
Florent Kirchner, Nikolai Kosmatov, Virgile Prevosto, Julien Signoles, and Boris Yakobowski. 2015. Frama-C: A Software Analysis Perspective.Formal Aspects of Computing27, 3 (2015), 573–609. doi:10.1007/s00165-014-0326-7
-
[16]
LangChain Inc. 2024. LangGraph: Build Resilient Language Agents as Graphs. GitHub repository. https://github.com/langchain-ai/langgraph Accessed 2025
2024
-
[17]
Wei Ma, Shangqing Liu, Zhihao Lin, Wenhan Wang, Qiang Hu, Ye Liu, Cen Zhang, Liming Nie, Li Li, and Yang Liu. 2024. LMs: Understanding Code Syntax and Semantics for Code Analysis. arXiv:2305.12138 [cs.SE] https://arxiv.org/abs/ 2305.12138
Pith/arXiv arXiv 2024
-
[18]
Vikram Nitin, Rahul Krishna, Luiz Lemos do Valle, and Baishakhi Ray. 2025. C2SaferRust: Transforming C Projects into Safer Rust with NeuroSymbolic Tech- niques. arXiv:2501.14257 [cs.SE] https://arxiv.org/abs/2501.14257
arXiv 2025
-
[19]
Makwana, Thomas Sewell, Kayvan Memarian, Peter Sewell, and Neel Krishnaswami
Christopher Pulte, Dhruv C. Makwana, Thomas Sewell, Kayvan Memarian, Peter Sewell, and Neel Krishnaswami. 2023. CN: Verifying Systems C Code with Separation-Logic Refinement Types.Proceedings of the ACM on Programming Languages7, POPL (2023), 191–220. doi:10.1145/3571194
-
[20]
Pierce, Cole Schlesinger, Jessica Shi, and Elizabeth Austell
Christopher Pulte, Benjamin C. Pierce, Cole Schlesinger, Jessica Shi, and Elizabeth Austell. 2025. CN Tutorial. Online tutorial. https://rems-project.github.io/cn- tutorial/ Accessed 2025
2025
-
[21]
John C. Reynolds. 2002. Separation Logic: A Logic for Shared Mutable Data Struc- tures. InProceedings of the 17th Annual IEEE Symposium on Logic in Computer Sci- ence (LICS). IEEE, Copenhagen, Denmark, 55–74. doi:10.1109/LICS.2002.1029817
-
[22]
Jamey Sharp. 2016. Corrode: C to Rust Translator. GitHub repository. https: //github.com/jameysharp/corrode Accessed 2025
2016
-
[23]
Tree-sitter Contributors. 2024. Tree-sitter: An Incremental Parsing System for Programming Tools. GitHub repository. https://github.com/tree-sitter/tree-sitter Accessed 2025
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.