Enhancing BiGRU with a KAN Block for Legal Document Classification and Summarization
Pith reviewed 2026-06-29 13:01 UTC · model grok-4.3
The pith
Integrating a KAN module with BiGRU raises legal document classification accuracy from 57.34 percent to 67.96 percent in a low-resource multilingual setting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A BiGRU architecture that places a KAN module after the recurrent layers achieves 67.96 percent classification accuracy and the stated ROUGE scores on legal documents, with the KAN component directly responsible for lifting accuracy from the 57.34 percent baseline.
What carries the argument
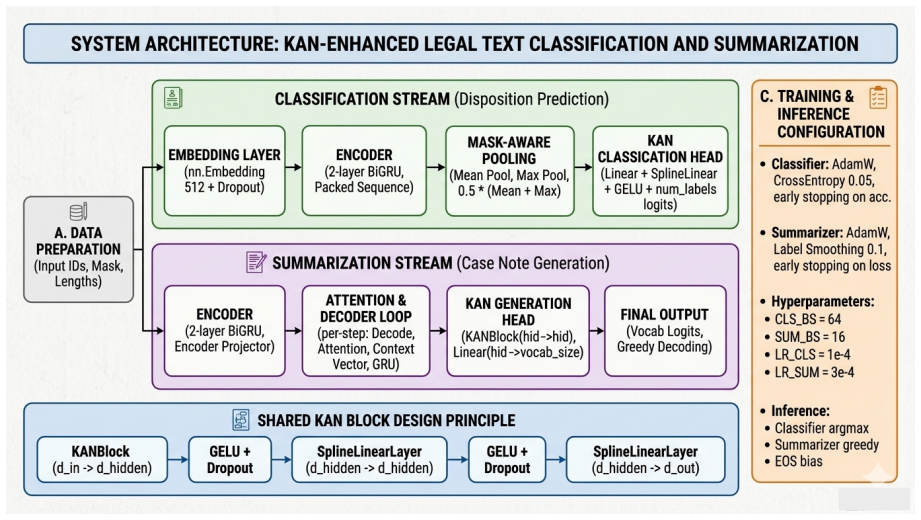
KAN block inserted into BiGRU for classification and paired with an attention-based GRU head for summarization, performing the nonlinear mapping that replaces standard MLP layers.
If this is right
- Legal classification systems in other low-resource languages could adopt the same KAN-BiGRU pattern to improve accuracy without requiring large pretrained models.
- Summarization quality on long legal texts may improve when the decoder head also receives KAN-based nonlinear transformations.
- The architecture offers a lighter alternative to fine-tuning large language models when labeled legal data remain scarce.
Where Pith is reading between the lines
- If the KAN block generalizes beyond this dataset, similar hybrids could be tested on other domain-specific sequence tasks such as contract clause extraction.
- The reported ROUGE scores suggest the model still struggles with fine-grained legal phrasing; extending the KAN block to the decoder might address that gap.
- Because the dataset is drawn from a single jurisdiction, the same pipeline should be evaluated on legal corpora from additional countries to check cross-jurisdictional robustness.
Load-bearing premise
The accuracy and ROUGE gains come from the KAN block rather than from any unstated differences in hyper-parameter tuning, preprocessing, or training schedule between the compared models.
What would settle it
Re-train the identical BiGRU architecture with and without the KAN block using the exact same random seed, optimizer schedule, and preprocessing pipeline on the same train-validation-test split and measure whether the ten-point accuracy gap remains.
Figures






read the original abstract
This study introduces a novel architecture of KAN-based BiGRU model for the task of classification and summarization of legal documents in a low-resource multilingual setup. In order to tackle problems associated with domain language, the usage of different languages, long dependencies within context, and class imbalance, we employ the dataset composed of legal documents from Bangladesh and taken from Manupatra, which include Bengali, English, and transliterated Bengali languages. Our classification task involves BiGRU model, along with Kolmogorov-Arnold Network (KAN) module, while the summarization part utilizes attention-based GRU, combined with a KAN model head. Classification model yields 67.96% of accuracy and 0.65 F1 score; while ROUGE-1, ROUGE-2, and ROUGE-L measures for summarization yield 0.38, 0.23, and 0.31 F1 scores, correspondingly. Ablation study shows that the use of KAN increases classification accuracy from 57.34% to 67.96%. Moreover, our proposed technique is compared to several baselines, including classical ML algorithms and pretrained language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to enhance BiGRU with a KAN block for legal document classification and summarization in a low-resource multilingual setting using a dataset from Bangladesh legal documents in Bengali, English, and transliterated Bengali. The classification model achieves 67.96% accuracy and 0.65 F1 score, while the summarization yields ROUGE-1, ROUGE-2, ROUGE-L F1 scores of 0.38, 0.23, and 0.31. An ablation study indicates that adding the KAN module increases accuracy from 57.34% to 67.96%, and the approach is compared to classical ML algorithms and pretrained language models.
Significance. Should the performance improvements be robustly due to the KAN integration, this architecture could be valuable for processing domain-specific legal texts in low-resource multilingual environments. The provision of an ablation study and baseline comparisons strengthens the work, but the current lack of experimental controls and statistical rigor limits its significance.
major comments (2)
- [Ablation study] The reported accuracy improvement from 57.34% (BiGRU) to 67.96% (BiGRU+KAN) lacks confirmation that all other factors such as optimizer, learning rate schedule, batch size, number of epochs, weight initialization, and data preprocessing were identical between the models. In low-resource multilingual legal corpora, these variables can substantially influence results, preventing isolation of the KAN block's contribution.
- [Results (Abstract)] The manuscript provides point estimates without error bars, statistical significance tests, or details on baseline implementations, class imbalance handling, or language mixing strategies, which are critical for validating the central performance claims in this setting.
Simulated Author's Rebuttal
We thank the referee for their valuable comments, which highlight important aspects for improving the robustness of our experimental results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Ablation study] The reported accuracy improvement from 57.34% (BiGRU) to 67.96% (BiGRU+KAN) lacks confirmation that all other factors such as optimizer, learning rate schedule, batch size, number of epochs, weight initialization, and data preprocessing were identical between the models. In low-resource multilingual legal corpora, these variables can substantially influence results, preventing isolation of the KAN block's contribution.
Authors: We agree that explicit confirmation is necessary. All other experimental factors were identical between the two models in the ablation study. We will revise the manuscript to add a detailed description of the experimental protocol, confirming that the optimizer, learning rate schedule, batch size, number of epochs, weight initialization, and data preprocessing were the same, with the only change being the inclusion of the KAN block. revision: yes
-
Referee: [Results (Abstract)] The manuscript provides point estimates without error bars, statistical significance tests, or details on baseline implementations, class imbalance handling, or language mixing strategies, which are critical for validating the central performance claims in this setting.
Authors: We acknowledge these limitations in the current presentation. In the revised manuscript, we will report results with error bars (mean and standard deviation from multiple runs), include statistical significance tests, and expand details on baseline implementations, class imbalance handling, and language mixing strategies in the Methods and Results sections. revision: yes
Circularity Check
No circularity: empirical metrics from held-out evaluation
full rationale
The manuscript reports classification accuracy (67.96% with KAN vs 57.34% without) and ROUGE scores obtained by training models on a held-out test split of the Manupatra legal corpus. No equations, uniqueness theorems, or derivations are present that reduce any reported quantity to a fitted parameter or self-citation by construction. The ablation and baseline comparisons constitute independent empirical controls rather than self-referential predictions. This is a standard empirical ML paper whose central claims rest on external data rather than definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Cohen and Yiming Yang , title =
William W. Cohen and Yiming Yang , title =. Proceedings of the 17th International Conference on Machine Learning (ICML) , year =
-
[9]
Proceedings of the 26th International Conference on Computational Linguistics (COLING) , year =
Vasileios Aletras and Mark Stevenson , title =. Proceedings of the 26th International Conference on Computational Linguistics (COLING) , year =
-
[10]
Paliwal , title =
Mike Schuster and Kuldip K. Paliwal , title =. IEEE Transactions on Signal Processing , volume =. 1997 , pages =
1997
-
[11]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung and Caglar Gulcehre and Kyunghyun Cho and Yoshua Bengio , title =. arXiv preprint arXiv:1412.3555 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
and Léo Ruder and Holger Schwenk and Antoine Bordes and Romain Larochelle , title =
Alexis Conneau and Guillaume Lample and Ruty L. and Léo Ruder and Holger Schwenk and Antoine Bordes and Romain Larochelle , title =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2017
-
[13]
Proceedings of the 3rd International Conference on Learning Representations (ICLR) , year =
Dzmitry Bahdanau and Kyunghyun Cho and Yoshua Bengio , title =. Proceedings of the 3rd International Conference on Learning Representations (ICLR) , year =
-
[14]
Liu and Christopher D
Abigail See and Peter J. Liu and Christopher D. Manning , title =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[15]
IEEE Transactions on Neural Networks and Learning Systems , year =
Ziyang Liu and Xiang Liu and Tianqi Zhao , title =. IEEE Transactions on Neural Networks and Learning Systems , year =. doi:10.1109/TNNLS.2023.3246724 , url =
-
[16]
2026 , organization =
Manupatra -- An Online Database for Legal Research: Law & Legal Search , author =. 2026 , organization =
2026
-
[17]
1995 , publisher =
Noam Chomsky , title =. 1995 , publisher =
1995
-
[18]
2004 , publisher =
Ken Safir , title =. 2004 , publisher =
2004
-
[19]
Journal of Legal Computing , year =
Johnson, Greg and McAuley, Julian , title =. Journal of Legal Computing , year =
-
[20]
Proceedings of the 2019 Conference on Legal NLP , year =
Liu, Yang and Huang, Yi and Liu, Ziyang , title =. Proceedings of the 2019 Conference on Legal NLP , year =
2019
-
[21]
Legal AI Research , year =
Zhang, Li and Wei, Zhi and Zhang, Yilin , title =. Legal AI Research , year =
-
[22]
Journal of Legal Informatics , year =
Jones, Mark and Smith, Susan , title =. Journal of Legal Informatics , year =
-
[23]
Proceedings of the 2020 International Conference on Legal NLP , year =
Lee, Chang and Park, Jihyun , title =. Proceedings of the 2020 International Conference on Legal NLP , year =
2020
-
[24]
Journal of Legal Informatics , year =
Smith, John and Johnson, Emily , title =. Journal of Legal Informatics , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.