Depth2Pose: A Pose-Based Benchmark for Monocular Depth Estimation without Ground-Truth Depth
Pith reviewed 2026-05-20 06:37 UTC · model grok-4.3
The pith
Monocular depth quality can be measured by how well it supports relative camera pose estimation in depth-aware solvers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining depth predictions with feature correspondences in depth-aware geometric solvers, relative camera pose estimation accuracy serves as a task-driven proxy for depth quality. This formulation enables evaluation of monocular depth estimators without requiring ground-truth depth and extends to challenging scenes outside common training distributions where dense depth labels are difficult to obtain.
What carries the argument
Depth-aware geometric solvers that integrate predicted depth maps with 2D feature correspondences to recover relative camera poses.
Load-bearing premise
Improvements in depth prediction quality will produce measurable improvements in relative pose estimation accuracy within the chosen depth-aware solvers across the evaluated scenes.
What would settle it
A depth estimator with better standard depth error metrics that yields worse relative pose accuracy than a weaker estimator when both are used in the same depth-aware solvers on D2P scenes.
Figures



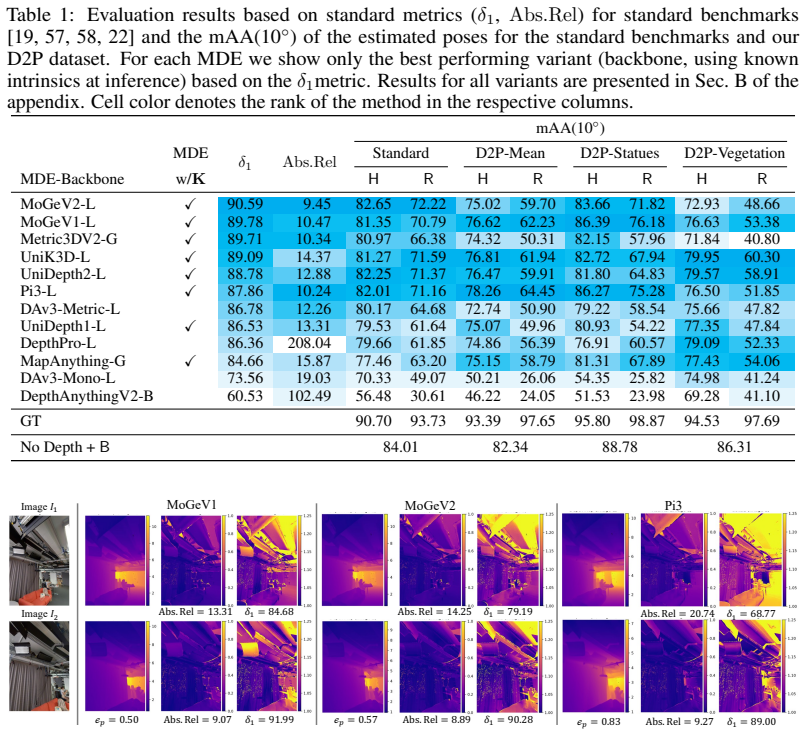

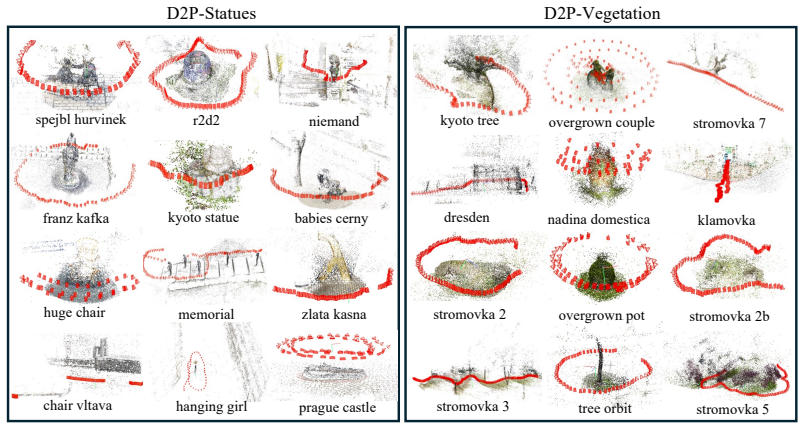




read the original abstract
Monocular depth estimation has improved significantly in recent years, driven by increasingly powerful models and large-scale training data. Predicted depth is increasingly used as an input signal for downstream tasks such as Structure-from-Motion (SfM), visual localization, and SLAM. However, monocular depth estimators (MDEs) are still primarily evaluated in terms of depth accuracy. Standard metrics aggregate errors globally and may not reflect the usefulness of depth for downstream geometric tasks. We therefore propose Depth2Pose, a framework for evaluating MDEs in the context of downstream tasks. By combining depth predictions with feature correspondences in depth-aware geometric solvers, we use relative camera pose estimation accuracy as a task-driven proxy for depth quality. Traditional benchmarks require dense ground truth in the form of per-pixel depth, which is expensive to obtain. In contrast, our formulation requires only camera poses, which can be estimated efficiently, e.g., using Structure-from-Motion pipelines. As a result, our framework can be applied to scenes where ground-truth depth is difficult to obtain, for example due to large scene scale or heavy occlusions (e.g., vegetated environments). Leveraging this, we introduce the D2P dataset, which contains challenging scenes outside the distribution of commonly used training data. We show that methods performing well under standard depth error metrics on existing benchmarks also perform well under our pose-based metric when evaluated on the same datasets, but do not necessarily generalize to our more challenging dataset. Finally, we provide a simple and extensible evaluation framework. The dataset and code are available at kocurvik.github.io/depth2pose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Depth2Pose, a framework for evaluating monocular depth estimators (MDEs) via relative camera pose estimation accuracy as a task-driven proxy for depth quality. Predicted depths are combined with 2D feature correspondences and fed into depth-aware geometric solvers; the resulting pose error serves as the metric. This avoids the need for per-pixel ground-truth depth. The authors release the D2P dataset of challenging scenes outside common training distributions and report that methods strong on standard depth benchmarks remain strong under the pose proxy on those benchmarks but do not necessarily generalize to D2P.
Significance. If the proxy relationship is empirically validated, the work enables evaluation of depth models in large-scale or heavily occluded scenes where dense GT depth is impractical to acquire. The public release of the D2P dataset and evaluation code is a concrete strength that supports reproducibility and downstream research in SfM, localization, and SLAM.
major comments (2)
- [Experiments / Results] The central proxy claim—that pose error faithfully tracks depth quality—requires a sensitivity or ablation study that perturbs depth while holding correspondences fixed and measures the resulting change in solver output. No such study is reported; the agreement shown on existing benchmarks therefore remains correlational rather than causal.
- [Method] The manuscript does not specify which depth-aware solvers are used (e.g., depth-weighted essential matrix, PnP variants) nor how depth enters the optimization (scale only, weighted residuals, etc.). Without these details it is impossible to assess whether the solvers are robust to moderate depth noise, undermining the load-bearing assumption that depth errors propagate measurably into pose error.
minor comments (2)
- [Figures / Tables] Figure captions and table headers should explicitly state the number of scenes, correspondences, and solver variants used so that the reported pose errors can be interpreted in context.
- [Discussion] A short discussion of failure cases (e.g., when correspondences dominate or when depth is used only for scale) would clarify the operating regime of the proxy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects that will improve the clarity and empirical support of the Depth2Pose framework. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments / Results] The central proxy claim—that pose error faithfully tracks depth quality—requires a sensitivity or ablation study that perturbs depth while holding correspondences fixed and measures the resulting change in solver output. No such study is reported; the agreement shown on existing benchmarks therefore remains correlational rather than causal.
Authors: We agree that an explicit sensitivity analysis would strengthen the causal interpretation of the proxy. In the revised manuscript we will add a controlled ablation in which we inject increasing levels of Gaussian noise into the predicted depth maps while keeping the 2D correspondences fixed, then record the resulting change in relative-pose error. This experiment will be reported alongside the existing benchmark comparisons and will directly quantify how depth perturbations propagate into solver output. revision: yes
-
Referee: [Method] The manuscript does not specify which depth-aware solvers are used (e.g., depth-weighted essential matrix, PnP variants) nor how depth enters the optimization (scale only, weighted residuals, etc.). Without these details it is impossible to assess whether the solvers are robust to moderate depth noise, undermining the load-bearing assumption that depth errors propagate measurably into pose error.
Authors: We acknowledge the lack of implementation detail. The revised Method section will explicitly state that we employ a depth-weighted essential-matrix solver (based on the formulation of Sweeney et al.) in which predicted depths are used both to scale the translation component and to weight the epipolar residuals inside a RANSAC loop. We will also describe the exact residual weighting scheme and provide pseudocode. These additions will allow readers to evaluate robustness to depth noise directly. revision: yes
Circularity Check
No significant circularity; proxy metric is a methodological proposal validated externally
full rationale
The paper proposes Depth2Pose as a new evaluation framework that substitutes relative pose accuracy (obtained by inserting predicted depths into existing depth-aware solvers) for direct depth error. This choice is presented as a task-driven proxy rather than derived from any equation or self-referential definition. The abstract and description explicitly state that the approach is validated by observing agreement with standard depth metrics on existing benchmarks, and the only required external input is camera poses obtainable via independent SfM pipelines. No fitted parameters are renamed as predictions, no self-citation chain is load-bearing for the central claim, and no ansatz or uniqueness theorem is smuggled in. The derivation chain is therefore self-contained against external geometric solvers and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reliable feature correspondences can be extracted from image pairs
- domain assumption Depth-aware geometric solvers translate depth quality into measurable pose accuracy differences
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By combining depth predictions with feature correspondences in depth-aware geometric solvers, we use relative camera pose estimation accuracy as a task-driven proxy for depth quality.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We validate our framework on several established benchmarks and show that pose-based evaluation correlates strongly with standard depth metrics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Depth-guided sparse structure-from-motion for movies and tv shows,
S. Liu, X. Nie, and R. Hamid, “Depth-guided sparse structure-from-motion for movies and tv shows,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15980–15989, 2022
work page 2022
-
[2]
Mp-sfm: Monocular surface priors for robust structure-from-motion,
Z. Pataki, P.-E. Sarlin, J. L. Schönberger, and M. Pollefeys, “Mp-sfm: Monocular surface priors for robust structure-from-motion,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 21891–21901, 2025
work page 2025
-
[3]
Marginalized bundle adjust- ment: Multi-view camera pose from monocular depth estimates,
S. Zhu, A. Abdelkader, M. J. Matthews, X. Liu, and W.-S. Chu, “Marginalized bundle adjust- ment: Multi-view camera pose from monocular depth estimates,” inInternational Conference on 3D Vision (3DV), 2026
work page 2026
-
[4]
Map-free visual relocalization: Metric pose relative to a single image,
E. Arnold, J. Wynn, S. Vicente, G. Garcia-Hernando, A. Monszpart, V . Prisacariu, D. Tur- mukhambetov, and E. Brachmann, “Map-free visual relocalization: Metric pose relative to a single image,” inEuropean Conference on Computer Vision, pp. 690–708, Springer, 2022
work page 2022
-
[5]
E. Brachmann, J. Wynn, S. Chen, T. Cavallari, A. Monszpart, D. Turmukhambetov, and V . A. Prisacariu, “Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer,” inEuropean Conference on Computer Vision, pp. 421–440, Springer, 2024
work page 2024
-
[6]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017
work page 2017
-
[7]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras,
Z. Teed and J. Deng, “Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras,” Advances in neural information processing systems, vol. 34, pp. 16558–16569, 2021
work page 2021
-
[8]
Nicer-slam: Neural implicit scene encoding for rgb slam,
Z. Zhu, S. Peng, V . Larsson, Z. Cui, M. R. Oswald, A. Geiger, and M. Pollefeys, “Nicer-slam: Neural implicit scene encoding for rgb slam,” in2024 International Conference on 3D Vision (3DV), pp. 42–52, IEEE, 2024
work page 2024
-
[9]
M. Li, Z. Zhu, M. Pollefeys, and D. Barath, “Droid-slam in the wild,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[10]
Como: Compact mapping and odometry,
E. Dexheimer and A. J. Davison, “Como: Compact mapping and odometry,” inEuropean Conference on Computer Vision, pp. 349–365, Springer, 2024
work page 2024
-
[11]
Neural 3d scene recon- struction with the manhattan-world assumption,
H. Guo, S. Peng, H. Lin, Q. Wang, G. Zhang, H. Bao, and X. Zhou, “Neural 3d scene recon- struction with the manhattan-world assumption,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5511–5520, 2022
work page 2022
-
[12]
Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction,
Z. Yu, S. Peng, M. Niemeyer, T. Sattler, and A. Geiger, “Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction,”Advances in neural information processing systems, vol. 35, pp. 25018–25032, 2022
work page 2022
-
[13]
Fast monocular scene re- construction with global-sparse local-dense grids,
W. Dong, C. Choy, C. Loop, O. Litany, Y . Zhu, and A. Anandkumar, “Fast monocular scene re- construction with global-sparse local-dense grids,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4263–4272, 2023
work page 2023
-
[14]
L. Han, X. Zhang, H. Song, K. Shi, Y .-S. Liu, and Z. Han, “Sparserecon: Neural implicit surface reconstruction from sparse views with feature and depth consistencies,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 28514–28524, 2025
work page 2025
-
[15]
Depth map prediction from a single image using a multi-scale deep network,
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,”Advances in neural information processing systems, vol. 27, 2014. 10
work page 2014
-
[16]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”The international journal of robotics research, vol. 32, no. 11, pp. 1231–1237, 2013
work page 2013
-
[17]
Indoor segmentation and support inference from rgbd images,
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from rgbd images,” inEuropean conference on computer vision, pp. 746–760, Springer, 2012
work page 2012
-
[18]
Scannet: Richly- annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly- annotated 3d reconstructions of indoor scenes,” inProc. Computer Vision and Pattern Recogni- tion (CVPR), IEEE, 2017
work page 2017
-
[19]
A multi-view stereo benchmark with high-resolution images and multi-camera videos,
T. Schops, J. L. Schonberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger, “A multi-view stereo benchmark with high-resolution images and multi-camera videos,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3260– 3269, 2017
work page 2017
-
[20]
Diode: A dense indoor and outdoor depth dataset,
I. Vasiljevic, N. Kolkin, S. Zhang, R. Luo, H. Wang, F. Z. Dai, A. F. Daniele, M. Mostajabi, S. Basart, M. R. Walter,et al., “Diode: A dense indoor and outdoor depth dataset,”arXiv preprint arXiv:1908.00463, 2019
-
[21]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine,et al., “Scalability in perception for autonomous driving: Waymo open dataset,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2446– 2454, 2020
work page 2020
-
[22]
A naturalistic open source movie for optical flow evaluation,
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black, “A naturalistic open source movie for optical flow evaluation,” inEuropean conference on computer vision, pp. 611–625, Springer, 2012
work page 2012
-
[23]
Megadepth: Learning single-view depth prediction from internet photos,
Z. Li and N. Snavely, “Megadepth: Learning single-view depth prediction from internet photos,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2041– 2050, 2018
work page 2041
-
[24]
Megascenes: Scene-level view synthesis at scale,
J. Tung, G. Chou, R. Cai, G. Yang, K. Zhang, G. Wetzstein, B. Hariharan, and N. Snavely, “Megascenes: Scene-level view synthesis at scale,” inEuropean Conference on computer vision, pp. 197–214, Springer, 2024
work page 2024
-
[25]
Long-tail Internet photo reconstruction
Y . Li, Y . Xiangli, H. Averbuch-Elor, N. Snavely, and R. Cai, “Long-tail internet photo recon- struction,”arXiv preprint arXiv:2604.22714, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Blendedmvs: A large-scale dataset for generalized multi-view stereo networks,
Y . Yao, Z. Luo, S. Li, J. Zhang, Y . Ren, L. Zhou, T. Fang, and L. Quan, “Blendedmvs: A large-scale dataset for generalized multi-view stereo networks,” inComputer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[27]
S. R. Richter, Z. Hayder, and V . Koltun, “Playing for benchmarks,” inIEEE International Conference on Computer Vision, ICCV 2017, V enice, Italy, October 22-29, 2017, 2017
work page 2017
-
[28]
Reposed: Ef- ficient relative pose estimation with known depth information,
Y . Ding, V . Kocur, V . Vávra, Z. B. Haladová, J. Yang, T. Sattler, and Z. Kukelova, “Reposed: Ef- ficient relative pose estimation with known depth information,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14876–14886, 2025
work page 2025
-
[29]
Deeper depth prediction with fully convolutional residual networks,
I. Laina, C. Rupprecht, V . Belagiannis, F. Tombari, and N. Navab, “Deeper depth prediction with fully convolutional residual networks,” in2016 F ourth international conference on 3D vision (3DV), pp. 239–248, IEEE, 2016
work page 2016
-
[30]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” in Proceedings of the IEEE/CVF international conference on computer vision, pp. 12179–12188, 2021
work page 2021
-
[31]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer,
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun, “Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 3, pp. 1623–1637, 2020
work page 2020
-
[32]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
S. F. Bhat, R. Birkl, D. Wofk, P. Wonka, and M. Müller, “Zoedepth: Zero-shot transfer by combining relative and metric depth,”arXiv preprint arXiv:2302.12288, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Towards zero-shot scale-aware monocular depth estimation,
V . Guizilini, I. Vasiljevic, D. Chen, R. Ambrus, , and A. Gaidon, “Towards zero-shot scale-aware monocular depth estimation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9233–9243, 2023
work page 2023
-
[34]
Metric3d: Towards zero-shot metric 3d prediction from a single image,
W. Yin, C. Zhang, H. Chen, Z. Cai, G. Yu, K. Wang, X. Chen, and C. Shen, “Metric3d: Towards zero-shot metric 3d prediction from a single image,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 9043–9053, 2023
work page 2023
-
[35]
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang, “Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5261–5271, 2025
work page 2025
-
[36]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,”arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” Advances in Neural Information Processing Systems, vol. 37, pp. 21875–21911, 2024
work page 2024
-
[38]
Unidepthv2: Universal monocular metric depth estimation made simpler,
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. Van Gool, “Unidepthv2: Universal monocular metric depth estimation made simpler,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[39]
Unsupervised cnn for single view depth estimation: Geometry to the rescue,
R. Garg, V . K. Bg, G. Carneiro, and I. Reid, “Unsupervised cnn for single view depth estimation: Geometry to the rescue,” inEuropean conference on computer vision, pp. 740–756, Springer, 2016
work page 2016
-
[40]
Digging into self-supervised monocular depth estimation,
C. Godard, O. Mac Aodha, M. Firman, and G. J. Brostow, “Digging into self-supervised monocular depth estimation,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 3828–3838, 2019
work page 2019
-
[41]
The temporal opportunist: Self-supervised multi-frame monocular depth,
J. Watson, O. Mac Aodha, V . Prisacariu, G. Brostow, and M. Firman, “The temporal opportunist: Self-supervised multi-frame monocular depth,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1164–1174, 2021
work page 2021
-
[42]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10371–10381, 2024
work page 2024
-
[43]
Survey on monocular metric depth estimation,
J. Zhang, Y . Wu, and H. Jiang, “Survey on monocular metric depth estimation,”Computers, vol. 14, no. 11, p. 502, 2025
work page 2025
-
[44]
G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez, “The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 3234–3243, 2016
work page 2016
-
[45]
Y . Cabon, N. Murray, and M. Humenberger, “Virtual kitti 2,”arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[46]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind, “Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 10912–10922, 2021
work page 2021
-
[47]
Training an open-vocabulary monocular 3d detection model without 3d data,
R. Huang, H. Zheng, Y . Wang, Z. Xia, M. Pavone, and G. Huang, “Training an open-vocabulary monocular 3d detection model without 3d data,”Advances in Neural Information Processing Systems, vol. 37, pp. 72145–72169, 2024
work page 2024
-
[48]
Monosowa: Scalable monocular 3d object detector without human annotations,
J. Skvrna and L. Neumann, “Monosowa: Scalable monocular 3d object detector without human annotations,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7613–7623, 2025. 12
work page 2025
-
[49]
Plot: Pseudo-labeling via video object tracking for scalable monocular 3d object detection,
S. Lee, S. Aung, J. Choi, S. Kim, I.-J. Kim, and J. Cho, “Plot: Pseudo-labeling via video object tracking for scalable monocular 3d object detection,”arXiv preprint arXiv:2507.02393, 2025
-
[50]
Relative pose solvers using monocular depth,
D. Barath and C. Sweeney, “Relative pose solvers using monocular depth,” in2022 26th International Conference on Pattern Recognition (ICPR), pp. 4037–4043, IEEE, 2022
work page 2022
-
[51]
Fast relative pose estimation using relative depth,
J. Astermark, Y . Ding, V . Larsson, and A. Heyden, “Fast relative pose estimation using relative depth,” in2024 International Conference on 3D Vision (3DV), pp. 873–881, IEEE, 2024
work page 2024
-
[52]
Fundamental matrix estimation using relative depths,
Y . Ding, V . Vávra, S. Bhayani, Q. Wu, J. Yang, and Z. Kukelova, “Fundamental matrix estimation using relative depths,” inEuropean Conference on Computer Vision, pp. 142–159, Springer, 2024
work page 2024
-
[53]
Relative pose estimation through affine corrections of monocular depth priors,
Y . Yu, S. Liu, R. Pautrat, M. Pollefeys, and V . Larsson, “Relative pose estimation through affine corrections of monocular depth priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 16706–16716, 2025
work page 2025
-
[54]
R. Hartley and A. Zisserman,Multiple View Geometry in Computer Vision. Cambridge Univer- sity Press, 2 ed., 2004
work page 2004
-
[55]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
Neural 3d reconstruction in the wild,
J. Sun, X. Chen, Q. Wang, Z. Li, H. Averbuch-Elor, X. Zhou, and N. Snavely, “Neural 3d reconstruction in the wild,” inACM SIGGRAPH 2022 conference proceedings, pp. 1–9, 2022
work page 2022
-
[57]
Lamar: Benchmarking localization and mapping for augmented reality,
P.-E. Sarlin, M. Dusmanu, J. L. Schönberger, P. Speciale, L. Gruber, V . Larsson, O. Miksik, and M. Pollefeys, “Lamar: Benchmarking localization and mapping for augmented reality,” in European Conference on Computer Vision, pp. 686–704, Springer, 2022
work page 2022
-
[58]
Scannet++: A high-fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high-fidelity dataset of 3d indoor scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12–22, 2023
work page 2023
-
[59]
T. Wu, J. Zhang, X. Fu, Y . Wang, J. Ren, L. Pan, W. Wu, L. Yang, J. Wang, C. Qian,et al., “Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 803–814, 2023
work page 2023
-
[60]
Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos,
H. Xia, Y . Fu, S. Liu, and X. Wang, “Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22378–22389, 2024
work page 2024
-
[61]
Image matching across wide baselines: From paper to practice,
Y . Jin, D. Mishkin, A. Mishchuk, J. Matas, P. Fua, K. M. Yi, and E. Trulls, “Image matching across wide baselines: From paper to practice,”International Journal of Computer Vision, vol. 129, no. 2, pp. 517–547, 2021
work page 2021
-
[62]
Structure-from-motion revisited,
J. L. Schönberger and J.-M. Frahm, “Structure-from-motion revisited,” inComputer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[63]
LoMa: Local Feature Matching Revisited
D. Nordström, J. Edstedt, G. Bökman, J. Astermark, A. Heyden, V . Larsson, M. Waden- bäck, M. Felsberg, and F. Kahl, “Loma: Local feature matching revisited,”arXiv preprint arXiv:2604.04931, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
Superpoint: Self-supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self-supervised interest point detection and description,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 224–236, 2018
work page 2018
-
[65]
Lightglue: Local feature matching at light speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “Lightglue: Local feature matching at light speed,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 17627– 17638, 2023
work page 2023
-
[66]
PoseLib - Minimal Solvers for Camera Pose Estimation,
V . Larsson and contributors, “PoseLib - Minimal Solvers for Camera Pose Estimation,” 2020. 13
work page 2020
-
[67]
Fixing the locally optimized ransac–full experimental evaluation,
K. Lebeda, J. Matas, and O. Chum, “Fixing the locally optimized ransac–full experimental evaluation,” inBritish machine vision conference, vol. 2, Citeseer Princeton, NJ, USA, 2012
work page 2012
-
[68]
An efficient solution to the five-point relative pose problem,
D. Nistér, “An efficient solution to the five-point relative pose problem,”IEEE transactions on pattern analysis and machine intelligence, vol. 26, no. 6, pp. 756–770, 2004
work page 2004
-
[69]
Unik3d: Universal camera monocular 3d estimation,
L. Piccinelli, C. Sakaridis, M. Segu, Y .-H. Yang, S. Li, W. Abbeloos, and L. Van Gool, “Unik3d: Universal camera monocular 3d estimation,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 1028–1039, 2025
work page 2025
-
[70]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Pixelwise view selection for unstructured multi-view stereo,
J. L. Schönberger, E. Zheng, M. Pollefeys, and J.-M. Frahm, “Pixelwise view selection for unstructured multi-view stereo,” inEuropean Conference on Computer Vision (ECCV), 2016
work page 2016
-
[72]
Aliked: A lighter keypoint and descrip- tor extraction network via deformable transformation,
X. Zhao, X. Wu, W. Chen, P. C. Chen, Q. Xu, and Z. Li, “Aliked: A lighter keypoint and descrip- tor extraction network via deformable transformation,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–16, 2023
work page 2023
-
[73]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,”International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004
work page 2004
-
[74]
easy-anon - An Easy-to-Use Image Masking and Anonymization Tool,
V . Panek and contributors, “easy-anon - An Easy-to-Use Image Masking and Anonymization Tool,” 2025
work page 2025
-
[75]
Unidepth: Universal monocular metric depth estimation,
L. Piccinelli, Y .-H. Yang, C. Sakaridis, M. Segu, S. Li, L. Van Gool, and F. Yu, “Unidepth: Universal monocular metric depth estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10106–10116, 2024
work page 2024
-
[76]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun, “Depth pro: Sharp monocular metric depth in less than a second,”arXiv preprint arXiv:2410.02073, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
H. Yu, H. Lin, J. Wang, J. Li, Y . Wang, X. Zhang, Y . Wang, X. Zhou, R. Hu, and S. Peng, “Infinidepth: Arbitrary-resolution and fine-grained depth estimation with neural implicit fields,” arXiv preprint arXiv:2601.03252, 2026
-
[78]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “pi3: Permutation-equivariant visual geometry learning,”arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. Müller, J. Schönberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes,et al., “Mapanything: Universal feed-forward metric 3d reconstruction,” arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Particlesfm: Exploiting dense point trajectories for localizing moving cameras in the wild,
W. Zhao, S. Liu, H. Guo, W. Wang, and Y .-J. Liu, “Particlesfm: Exploiting dense point trajectories for localizing moving cameras in the wild,” inEuropean Conference on Computer Vision, pp. 523–542, Springer, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.