Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Pith reviewed 2026-05-20 22:20 UTC · model grok-4.3
The pith
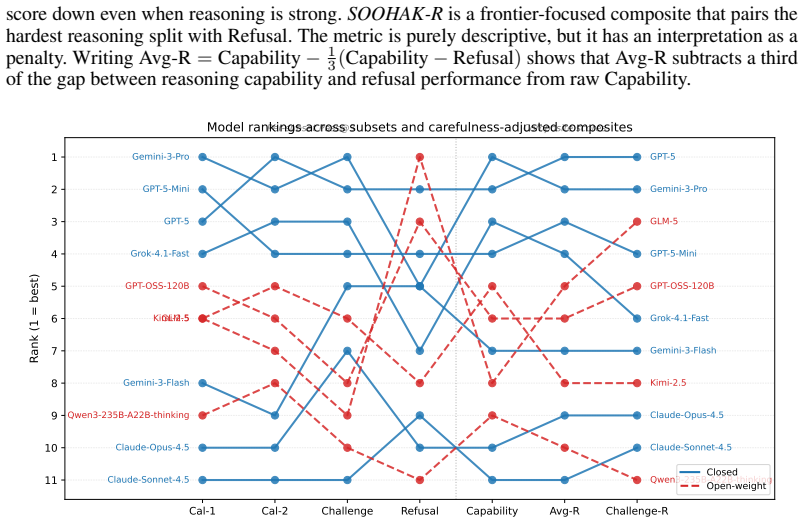
A mathematician-authored benchmark of 439 problems shows frontier LLMs still solve under one-third of research-level questions and rarely refuse ill-posed ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Soohak consists of 439 problems written from scratch by 64 mathematicians and split into a Challenge subset that measures the ability to advance mathematical knowledge plus a refusal subset that tests recognition of ill-posed problems. On the Challenge subset the strongest models reach at most 30.4 percent while open-weight models stay below 15 percent. On the refusal subset no model exceeds 50 percent, showing that current systems do not reliably pause when a question cannot be answered.
What carries the argument
The Soohak benchmark itself, built from newly authored research-level problems together with an explicit refusal subset for ill-posed questions.
Load-bearing premise
The 439 problems accurately capture the skills needed to advance mathematical knowledge and cannot be solved through memorization or surface patterns.
What would settle it
A model that solves the majority of the Challenge problems or correctly refuses more than half the ill-posed questions would indicate that the reported performance gap has closed.
Figures



read the original abstract
Following the recent achievement of gold-medal performance on the IMO by frontier LLMs, the community is searching for the next meaningful and challenging target for measuring LLM reasoning. Whereas olympiad-style problems measure step-by-step reasoning alone, research-level problems use such reasoning to advance the frontier of mathematical knowledge itself, emerging as a compelling alternative. Yet research-level math benchmarks remain scarce because such problems are difficult to source (e.g., Riemann Bench and FrontierMath-Tier 4 contain 25 and 50 problems, respectively). To support reliable evaluation of next-generation frontier models, we introduce Soohak, a 439-problem benchmark newly authored from scratch by 64 mathematicians. Soohak comprises two subsets. On the Challenge subset, frontier models including Gemini-3-Pro, GPT-5, and Claude-Opus-4.5 reach 30.4%, 26.4%, and 10.4% respectively, leaving substantial headroom, while leading open-weight models such as Qwen3-235B, GPT-OSS-120B, and Kimi-2.5 remain below 15%. Notably, beyond standard problem solving, Soohak introduces a refusal subset that probes a capability intrinsic to research mathematics: recognizing ill-posed problems and pausing rather than producing confident but unjustified answers. On this subset, no model exceeds 50%, identifying refusal as a new optimization target that current models do not directly address. To prevent contamination, the dataset will be publicly released in late 2026, with model evaluations available upon request in the interim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Soohak, a 439-problem benchmark of research-level mathematics problems newly authored from scratch by 64 mathematicians to evaluate LLMs beyond olympiad-style reasoning. It comprises a Challenge subset, on which frontier models reach at most 30.4% (Gemini-3-Pro), and a refusal subset probing recognition of ill-posed problems, where no model exceeds 50%. The work positions Soohak as a larger alternative to existing small benchmarks like Riemann Bench and FrontierMath-Tier 4, with planned public release in late 2026 to avoid contamination.
Significance. If the curation process can be shown to produce problems whose solutions genuinely advance the mathematical frontier, Soohak would address a clear scarcity of research-level benchmarks and provide a reproducible target for capabilities such as refusal on ill-posed questions. The mathematician-curated, from-scratch construction and deferred release are strengths that support contamination resistance and credibility.
major comments (3)
- [Benchmark construction] Benchmark construction (abstract and §2): The central claim that the 439 problems measure the ability to advance mathematical knowledge rests on curation by 64 mathematicians, yet no external review process, mapping to open problems in the literature, or rubric demonstrating why solutions extend rather than apply existing theory is described. This leaves the distinction from advanced contest-style problems unverified.
- [Evaluation and results] Evaluation and results (abstract and §4): Concrete performance figures (Gemini-3-Pro 30.4%, GPT-5 26.4%, Claude-Opus-4.5 10.4% on Challenge; no model >50% on refusal) are reported without details on scoring rubrics, inter-rater agreement among the mathematicians, problem verification procedures, or statistical significance tests for the model comparisons.
- [Refusal subset] Refusal subset (abstract and §3): The finding that refusal is a new optimization target depends on a reproducible definition of 'ill-posed' problems; without explicit criteria or examples showing why a problem is ill-posed rather than merely difficult, the 50% ceiling cannot be interpreted as a specific, falsifiable capability gap.
minor comments (2)
- [Abstract] The abstract lists specific model names (Gemini-3-Pro, GPT-5, Claude-Opus-4.5) without version numbers or citations; align these with the exact checkpoints used in the experiments.
- [Results] Consider adding a summary table of all evaluated models and their scores on both subsets to improve readability of the results.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript introducing the Soohak benchmark. We address each of the major comments in turn and outline the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: Benchmark construction (abstract and §2): The central claim that the 439 problems measure the ability to advance mathematical knowledge rests on curation by 64 mathematicians, yet no external review process, mapping to open problems in the literature, or rubric demonstrating why solutions extend rather than apply existing theory is described. This leaves the distinction from advanced contest-style problems unverified.
Authors: We acknowledge the need for greater transparency in the benchmark construction process. In the revised manuscript, we will expand Section 2 to describe the internal review process among the 64 mathematicians, provide the rubric used to ensure problems require novel mathematical insights rather than the application of existing results, and include several illustrative examples. While the benchmark does not map directly to specific open problems in the literature—as its goal is to assess general research capabilities rather than target particular unsolved questions—we will clarify this positioning to better distinguish it from contest-style problems. revision: yes
-
Referee: Evaluation and results (abstract and §4): Concrete performance figures (Gemini-3-Pro 30.4%, GPT-5 26.4%, Claude-Opus-4.5 10.4% on Challenge; no model >50% on refusal) are reported without details on scoring rubrics, inter-rater agreement among the mathematicians, problem verification procedures, or statistical significance tests for the model comparisons.
Authors: We agree that additional methodological details are necessary for reproducibility and credibility. The revised version of Section 4 will include the full scoring rubrics employed by the mathematicians, inter-rater agreement metrics (Cohen's kappa and percentage agreement), a description of the multi-stage verification procedures, and results from statistical significance tests comparing model performances. These elements were part of our internal evaluation process but were omitted from the initial submission for brevity. revision: yes
-
Referee: Refusal subset (abstract and §3): The finding that refusal is a new optimization target depends on a reproducible definition of 'ill-posed' problems; without explicit criteria or examples showing why a problem is ill-posed rather than merely difficult, the 50% ceiling cannot be interpreted as a specific, falsifiable capability gap.
Authors: We will revise Section 3 to provide a clear, reproducible definition of ill-posed problems in the context of mathematical research, along with concrete examples from the refusal subset. These examples will illustrate cases where the problem statement lacks sufficient constraints or assumptions to admit a well-defined solution, as opposed to problems that are simply computationally or conceptually challenging but well-posed. This addition will allow readers to better interpret the refusal performance results. revision: yes
Circularity Check
No circularity: empirical benchmark creation without derivational steps
full rationale
This is an empirical benchmark paper that introduces a new dataset of 439 problems curated by mathematicians and reports LLM performance on challenge and refusal subsets. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The central claims rest on the external curation process and direct empirical measurements rather than any internal reduction where a result is defined in terms of itself or forced by self-citation chains. The construction and evaluation are self-contained against external benchmarks and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Problems newly authored by 64 mathematicians are representative of research-level mathematics that advances the frontier of knowledge.
Reference graph
Works this paper leans on
-
[1]
J., Hairer, M., Kileel, J., Kolda, T
Abouzaid, M., Blumberg, A. J., Hairer, M., Kileel, J., Kolda, T. G., Nelson, P. D., Spiel- man, D., Srivastava, N., Ward, R., Weinberger, S., et al. (2026). First proof.arXiv preprint arXiv:2602.05192
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., et al. (2025). gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Alexeev, B., Putterman, M., Sawhney, M., Sellke, M., and Valiant, G. (2026b). Short proofs in combinatorics, probability and number theory ii.arXiv preprint arXiv:2604.06609
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
Anthropic (2025). Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5. Accessed: 2026-05-04
work page 2025
-
[7]
American invitational mathematics examination (aime)
Art of Problem Solving (2025). American invitational mathematics examination (aime). https: //artofproblemsolving.com/wiki/index.php/AIME. Accessed: 2026-01-24
work page 2025
-
[8]
Balunovi´c, M., Dekoninck, J., Petrov, I., Jovanovi ´c, N., and Vechev, M. (2025). Matharena: Evaluating llms on uncontaminated math competitions
work page 2025
-
[9]
Burnham, G. (2025). Less than 70% of FrontierMath is within reach for today’s models. Epoch AI, Gradient Updates. Accessed: 2026-02-24
work page 2025
-
[10]
ByteDance-Seed (2025). BeyondAIME: Advancing Math Reasoning Evaluation Beyond High School Olympiads.https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME
work page 2025
-
[11]
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. (2021). Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [12]
-
[13]
Gao, B., Song, F., Yang, Z., Cai, Z., Miao, Y ., Dong, Q., Li, L., Ma, C., Chen, L., Xu, R., Tang, Z., Wang, B., Zan, D., Quan, S., Zhang, G., Sha, L., Zhang, Y ., Ren, X., Liu, T., and Chang, B. (2025). Omni-MATH: A universal olympiad level mathematic benchmark for large language models. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[14]
Garre, S., Knutsen, E., Mehta, S., and Chen, E. (2026). Riemann-bench: A benchmark for moonshot mathematics.arXiv preprint arXiv:2604.06802
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Glazer, E., Erdil, E., Besiroglu, T., Chicharro, D., Chen, E., Gunning, A., Olsson, C. F., Denain, J.-S., Ho, A., Santos, E. d. O., et al. (2024). Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai.arXiv preprint arXiv:2411.04872. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Gemini 3.1 Pro.https://deepmind.google/models/gemini/ pro/
Google DeepMind (2026). Gemini 3.1 Pro.https://deepmind.google/models/gemini/ pro/. Accessed: 2026-05-04
work page 2026
-
[17]
Guha, E., Marten, R., Keh, S., Raoof, N., Smyrnis, G., Bansal, H., Nezhurina, M., Mercat, J., Vu, T., Sprague, Z., et al. (2025). Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. (2021). Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
work page 2021
- [20]
-
[21]
Ko, H., Son, G., and Choi, D. (2025). Understand, solve and translate: Bridging the multilingual mathematical reasoning gap. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pages 78–95
work page 2025
-
[22]
Ma, J., Wang, G., Feng, X., Liu, Y ., Hu, Z., and Liu, Y . (2026). Eternalmath: A living benchmark of frontier mathematics that evolves with human discovery.arXiv preprint arXiv:2601.01400
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
proprietary ai foundation model
Ministry of Science and ICT (MSIT) (2025). “proprietary ai foundation model” project enters full-scale launch. Accessed 2026-02-15
work page 2025
-
[24]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C. B. C., Shaaban, M., Ling, J., Shi, S., et al. (2025). Humanity’s Last Exam.arXiv preprint arXiv:2501.14249
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
-
[26]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. (2025). Openai gpt-5 system card.arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Skarlinski, M., Laurent, J., Bou, A., and White, A. (2025). About 30% of humanity’s last exam chemistry/biology answers are likely wrong. FutureHouse, Research Announcement. Accessed: 2026-02-24
work page 2025
-
[28]
Stump, C. (2025). Math sciencebench: Challenge the newest ai models with your hardest phd-level exercises.https://math.science-bench.ai/. Accessed: 2026-02
work page 2025
-
[29]
Team, K., Bai, T., Bai, Y ., Bao, Y ., Cai, S., Cao, Y ., Charles, Y ., Che, H., Chen, C., Chen, G., et al. (2026). Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 technical report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
GLM-5.1: Towards Long-Horizon Tasks
Z.ai (2026). GLM-5.1: Towards Long-Horizon Tasks. https://z.ai/blog/glm-5.1. Ac- cessed: 2026-05-04
work page 2026
- [32]
-
[33]
Zhang, J., Petrui, C., Nikoli´c, K., and Tramèr, F. (2025). Realmath: A continuous benchmark for evaluating language models on research-level mathematics.arXiv preprint arXiv:2505.12575. 11 A Author affiliations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .12 B Data collection details. . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.