EntangleCodec: A Unified Discrete Audio Tokenizer via Semantic-Acoustic Entanglement
Pith reviewed 2026-06-28 12:31 UTC · model grok-4.3
The pith
EntangleCodec creates one discrete audio token stream by aligning sound with rich captions, letting 0.6B models beat much larger continuous ones on understanding tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
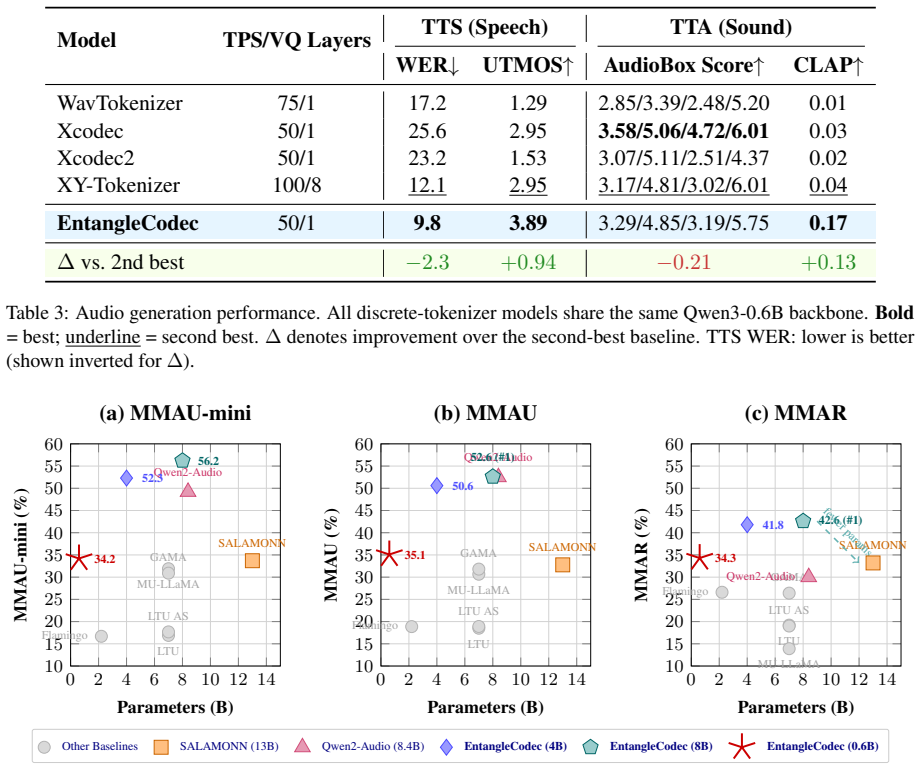
EntangleCodec learns caption-aligned semantic-acoustic representations before quantization to produce a unified discrete token stream that preserves both acoustic fidelity and rich semantic information including linguistic content, speaker identity, emotion, prosody, and acoustic scenes. This single stream supports reconstruction competitive with specialized codecs, improves audio understanding by up to 7.4 percent on MMAR over codec baselines, and enables both TTS and TTA generation. Models using the tokens exhibit strong scaling: a 0.6B parameter ALM surpasses specialized continuous-representation LLMs with over 13B parameters across three benchmarks using 22 times fewer parameters, and sc
What carries the argument
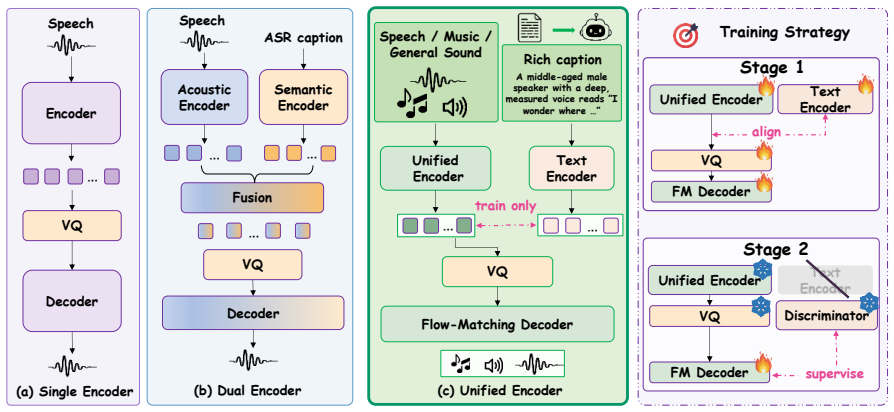
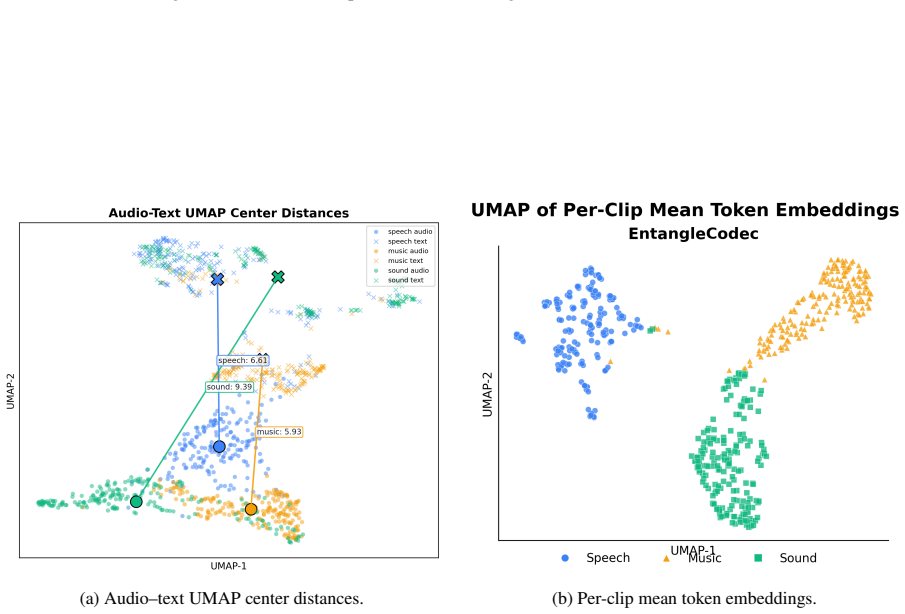
Caption-aligned semantic-acoustic entanglement before quantization, which packs linguistic, speaker, emotion, prosody, and scene information into one compact token stream while a flow-matching diffusion decoder handles reconstruction.
If this is right
- Reconstruction quality remains competitive with specialized codecs across speech, music, and general audio.
- Audio understanding improves by up to 7.4 percent on MMAR relative to other codec-based baselines.
- A 0.6B parameter audio language model using the tokens surpasses 13B parameter continuous-representation LLMs on three benchmarks.
- Scaling the same architecture to 8B parameters produces new state-of-the-art results on MMAR.
Where Pith is reading between the lines
- Representation quality can reduce the parameter count needed for strong audio modeling performance.
- A single entangled stream may simplify audio language model design by removing the need for parallel semantic and acoustic paths.
- Caption-based alignment could be tested on other modalities where detailed natural-language descriptions are available.
- Further scaling experiments would show whether the observed efficiency gains persist at even larger model sizes.
Load-bearing premise
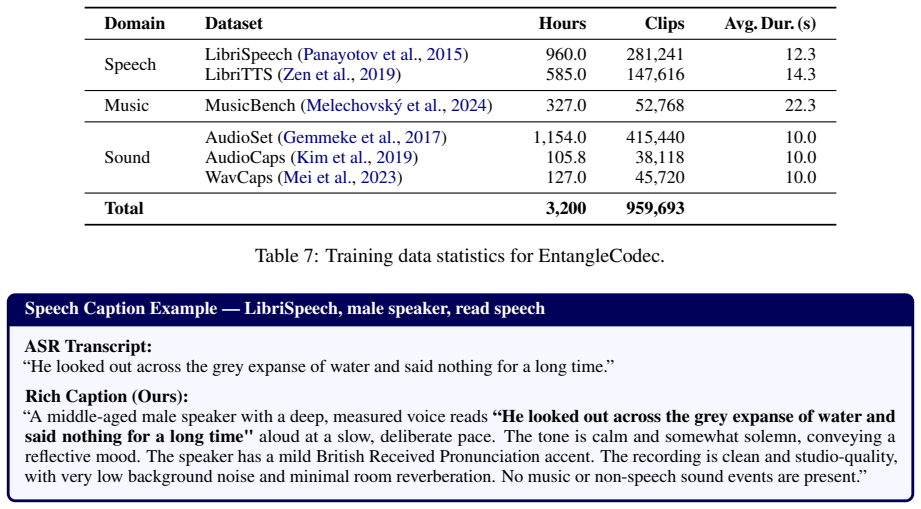
Aligning audio with rich captions rather than ASR transcripts will produce a single token stream that preserves both acoustic fidelity and semantic details without misalignment or information loss.
What would settle it
A head-to-head test in which separate semantic-plus-acoustic token streams achieve higher combined reconstruction-plus-understanding scores than the single entangled stream on the same benchmarks.
Figures






read the original abstract
Audio tokenizers serve as the discrete interface between continuous audio and Audio Language Models (ALMs), but existing tokenizers often struggle to support both understanding and generation. Reconstruction-oriented codecs preserve acoustic fidelity but lack rich semantics, while semantic-aware tokenizers typically rely on separate semantic and acoustic streams, introducing redundancy or misalignment. We propose \textbf{EntangleCodec}, a unified discrete audio tokenizer that learns caption-aligned semantic-acoustic representations before quantization. By aligning audio with rich captions rather than ASR transcripts, EntangleCodec captures linguistic content, speaker identity, emotion, prosody, and acoustic scenes within a compact token stream. A flow-matching diffusion decoder further enables high-quality reconstruction across speech, music, and general audio. EntangleCodec achieves reconstruction quality competitive with specialized codecs, outperforms all codec-based baselines on audio understanding by up to \textbf{+7.4\%} on MMAR, and supports both TTS and TTA generation in a unified framework. Furthermore, EntangleCodec-based audio language models demonstrate strong scaling behavior: even at \textit{0.6B} parameters, the model surpasses specialized continuous-representation LLMs with over \textit{13B} parameters across three benchmarks using \textbf{22$\times$} fewer parameters; scaling to \textit{8B} further establishes new state-of-the-art results on MMAR, highlighting that representation quality is as critical as model scale in audio language modeling. Code and model weights are available at https://github.com/luckyerr/EntangleCodec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EntangleCodec, a unified discrete audio tokenizer that learns caption-aligned semantic-acoustic representations before quantization to produce a single token stream capturing linguistic content, speaker identity, emotion, prosody, and acoustic scenes. A flow-matching diffusion decoder enables reconstruction across speech, music, and general audio. The tokenizer supports audio understanding and generation; EntangleCodec-based ALMs at 0.6B parameters outperform specialized continuous-representation LLMs exceeding 13B parameters on three benchmarks (22× fewer parameters), with scaling to 8B establishing new SOTA on MMAR.
Significance. If the empirical claims hold, the work would be significant for demonstrating that caption-aligned entanglement can yield compact discrete representations supporting both high-fidelity reconstruction and efficient scaling in audio language modeling, with the public release of code and model weights at https://github.com/luckyerr/EntangleCodec providing a concrete reproducibility asset.
major comments (2)
- [Abstract] Abstract and experimental claims: the reported +7.4% MMAR gain, 22× parameter reduction, and outperformance of >13B continuous LLMs by a 0.6B discrete model are presented without any description of baselines, dataset splits, error bars, statistical tests, or ablation studies, rendering the central performance claims unevaluable.
- [Method] Method description of caption alignment: the claim that aligning audio with rich captions (rather than ASR transcripts) simultaneously encodes linguistic/speaker/emotion/prosody/scene content in one stream without measurable misalignment or acoustic loss lacks any quantitative verification, control experiments, or analysis of token-stream properties.
minor comments (1)
- The abstract states competitive reconstruction quality and unified TTS/TTA support but provides no quantitative metrics or comparison tables in the visible text.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major point below with clarifications from the manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental claims: the reported +7.4% MMAR gain, 22× parameter reduction, and outperformance of >13B continuous LLMs by a 0.6B discrete model are presented without any description of baselines, dataset splits, error bars, statistical tests, or ablation studies, rendering the central performance claims unevaluable.
Authors: The abstract summarizes key findings concisely per standard practice. Full details on baselines, dataset splits, error bars, statistical tests, and ablation studies appear in Sections 4 (Experimental Setup), 5 (Results on reconstruction and understanding), and 6 (Ablations and scaling). Tables report means with standard deviations and note significance testing. To make claims more self-contained, we will revise the abstract to reference the evaluation protocol and point to these sections. revision: yes
-
Referee: [Method] Method description of caption alignment: the claim that aligning audio with rich captions (rather than ASR transcripts) simultaneously encodes linguistic/speaker/emotion/prosody/scene content in one stream without measurable misalignment or acoustic loss lacks any quantitative verification, control experiments, or analysis of token-stream properties.
Authors: The method section explains the caption-alignment objective and its motivation over ASR transcripts. Effectiveness is shown via competitive reconstruction metrics across domains and +7.4% gains on MMAR understanding, which require preservation of the listed attributes. We agree that dedicated quantitative controls (caption vs. ASR ablation) and token-property analysis (e.g., mutual information or clustering metrics) would strengthen the presentation. These will be added in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and method summary describe a new tokenizer that aligns audio to captions before quantization and uses a flow-matching decoder. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are present that would reduce any claimed result to its own inputs by construction. Performance numbers (+7.4% MMAR, scaling claims) are presented as empirical outcomes rather than tautological re-statements of training choices. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, and 27 others. 2024. https://doi.org/10.48550/ARXIV.2406.02430 Seed-tts: A family of high-quality versatile speech ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.02430 2024
-
[2]
Zal \' a n Borsos, Rapha \" e l Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matthew Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. 2023. https://doi.org/10.1109/TASLP.2023.3288409 Audiolm: A language modeling approach to audio generation . IEEE ACM Trans. Audio Speech Lang. Process. , 31...
-
[3]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. 2024. https://doi.org/10.48550/ARXIV.2407.10759 Qwen2-audio technical report . CoRR, abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10759 2024
-
[4]
Alexandre D \' e fossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2023. https://openreview.net/forum?id=ivCd8z8zR2 High fidelity neural audio compression . Trans. Mach. Learn. Res., 2023
2023
-
[5]
Alexandre D \' e fossez, Laurent Mazar \' e , Manu Orsini, Am \' e lie Royer, Patrick P \' e rez, Herv \' e J \' e gou, Edouard Grave, and Neil Zeghidour. 2024. https://doi.org/10.48550/ARXIV.2410.00037 Moshi: a speech-text foundation model for real-time dialogue . CoRR, abs/2410.00037
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.00037 2024
-
[6]
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. 2019. https://arxiv.org/abs/1910.09387 Clotho: An audio captioning dataset . CoRR, abs/1910.09387
arXiv 2019
-
[7]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. 2024. https://doi.org/10.48550/ARXIV.2407.05407 Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens . CoRR, abs/2407.05407
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.05407 2024
-
[8]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. 2023. https://doi.org/10.1109/ICASSP49357.2023.10095889 CLAP learning audio concepts from natural language supervision . In IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023 , pages 1--5. IEEE
-
[9]
Audio Set: An ontology and human-labeled dataset for audio events
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. https://doi.org/10.1109/ICASSP.2017.7952261 Audio set: An ontology and human-labeled dataset for audio events . In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans...
-
[10]
Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha
Sreyan Ghosh, Sonal Kumar, Ashish Seth, Chandra Kiran Reddy Evuru, Utkarsh Tyagi, S. Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. 2024. https://doi.org/10.18653/V1/2024.EMNLP-MAIN.361 GAMA: A large audio-language model with advanced audio understanding and complex reasoning abilities . In Proceedings of the 2024 Conference on Empirical Meth...
-
[11]
Liu, Leonid Karlinsky, and James R
Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, and James R. Glass. 2024. https://openreview.net/forum?id=nBZBPXdJlC Listen, think, and understand . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[12]
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, and Zhou Zhao. 2025. https://openreview.net/forum?id=yBlVlS2Fd9 Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling . In The...
2025
-
[13]
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Eric Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiangyang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, and Sheng Zhao. 2024. https://proceedings.mlr.press/v235/ju24b.html Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion...
2024
-
[14]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. https://doi.org/10.18653/V1/N19-1011 Audiocaps: Generating captions for audios in the wild . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7...
-
[15]
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. 2024. https://proceedings.mlr.press/v235/kong24a.html Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of ...
2024
-
[16]
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/58d0e78cf042af5876e12661087bea12-Abstract-Conference.html High-fidelity audio compression with improved RVQGAN . In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processi...
2023
-
[17]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben - Hamu, Maximilian Nickel, and Matthew Le. 2023. https://openreview.net/forum?id=PqvMRDCJT9t Flow matching for generative modeling . In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
2023
-
[18]
Samuel Lipping, Parthasaarathy Sudarsanam, Konstantinos Drossos, and Tuomas Virtanen. 2022. https://ieeexplore.ieee.org/document/9909680 Clotho-aqa: A crowdsourced dataset for audio question answering . In 30th European Signal Processing Conference, EUSIPCO 2022, Belgrade, Serbia, August 29 - Sept. 2, 2022 , pages 1140--1144. IEEE
arXiv 2022
-
[19]
Shansong Liu, Atin Sakkeer Hussain, Qilong Wu, Chenshuo Sun, and Ying Shan. 2024. https://doi.org/10.48550/ARXIV.2412.06660 Mumu-llama: Multi-modal music understanding and generation via large language models . CoRR, abs/2412.06660
-
[20]
Plumbley, Yuexian Zou, and Wenwu Wang
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, and Wenwu Wang. 2023. https://doi.org/10.48550/ARXIV.2303.17395 Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research . CoRR, abs/2303.17395
-
[21]
Jan Melechovsk \' y , Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria. 2024. https://doi.org/10.18653/V1/2024.NAACL-LONG.459 Mustango: Toward controllable text-to-music generation . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
-
[22]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. https://doi.org/10.1109/ICASSP.2015.7178964 Librispeech: An ASR corpus based on public domain audio books . In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015 , pages 5206--5210. IEEE
-
[23]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. https://proceedings.mlr.press/v202/radford23a.html Robust speech recognition via large-scale weak supervision . In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , Proceedings of Machine Learning Research, page...
2023
-
[24]
Antony W. Rix, John G. Beerends, Michael P. Hollier, and Andries P. Hekstra. 2001. https://doi.org/10.1109/ICASSP.2001.941023 Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs . In IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2001, 7-11 May, 2001,...
-
[25]
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. https://doi.org/10.21437/INTERSPEECH.2022-439 UTMOS: utokyo-sarulab system for voicemos challenge 2022 . In 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022, page...
-
[26]
Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha
S. Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. 2025. https://openreview.net/forum?id=TeVAZXr3yv MMAU: A massive multi-task audio understanding and reasoning benchmark . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore...
2025
-
[27]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. https://openreview.net/forum?id=14rn7HpKVk SALMONN: towards generic hearing abilities for large language models . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[28]
Qwen Team. 2025. https://doi.org/10.48550/ARXIV.2505.09388 Qwen3 technical report . CoRR, abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[29]
Zeyue Tian, Yizhu Jin, Zhaoyang Liu, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. 2025. https://doi.org/10.48550/ARXIV.2503.10522 Audiox: Diffusion transformer for anything-to-audio generation . CoRR, abs/2503.10522
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.10522 2025
-
[30]
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi - Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, Jeff Wang, Ivan Cruz, Bapi Akula, Akinniyi Akinyemi, Brian Ellis, Rashel Moritz, Yael Yungster, Alice Rakotoarison, Liang Tan, and 5 others. 2023. https://doi.org/10.48550/ARXIV.2312.15821 Audiobox: Unified audio generat...
-
[31]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. 2023. https://doi.org/10.48550/ARXIV.2301.02111 Neural codec language models are zero-shot text to speech synthesizers . CoRR, abs/2301.02111
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.02111 2023
-
[32]
LLM - Core Xiaomi. 2025. https://doi.org/10.48550/ARXIV.2512.23808 Mimo-audio: Audio language models are few-shot learners . CoRR, abs/2512.23808
-
[33]
Jian Yang, Dacheng Yin, Yizhou Zhou, Fengyun Rao, Wei Zhai, Yang Cao, and Zheng - Jun Zha. 2025. https://doi.org/10.1109/CVPR52734.2025.00747 MMAR: towards lossless multi-modal auto-regressive probabilistic modeling . In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025 , pages 7974--7985. Comp...
-
[34]
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, and Wei Xue. 2025 a . https://doi.org/10.1609/AAAI.V39I24.34761 Codec does matter: Exploring the semantic shortcoming of codec for audio language model . In Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh C...
-
[35]
Zhen Ye, Xinfa Zhu, Chi - Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, Hongzhan Lin, Jianyi Chen, Xingjian Du, Liumeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, and Wei Xue. 2025 b . https://doi.org/10.48550/ARXIV.2502.04128 Llasa: Scaling train-time and inference-time compute for llama-based s...
-
[36]
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. 2021. https://arxiv.org/abs/2107.03312 Soundstream: An end-to-end neural audio codec . CoRR, abs/2107.03312
arXiv 2021
-
[37]
Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J. Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. 2019. https://doi.org/10.21437/INTERSPEECH.2019-2441 Libritts: A corpus derived from librispeech for text-to-speech . In 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, September 15-19, 2019, pages 1...
-
[38]
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. 2024. https://openreview.net/forum?id=AF9Q8Vip84 Speechtokenizer: Unified speech tokenizer for speech language models . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.