Visual Sculpting: Visually-Aligned Planning Representations for Long-Horizon Robot Clay Sculpting
Pith reviewed 2026-05-20 12:20 UTC · model grok-4.3
The pith
Visually-aligned representations enable long-horizon robotic clay sculpting with over 100 parametrized pushes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
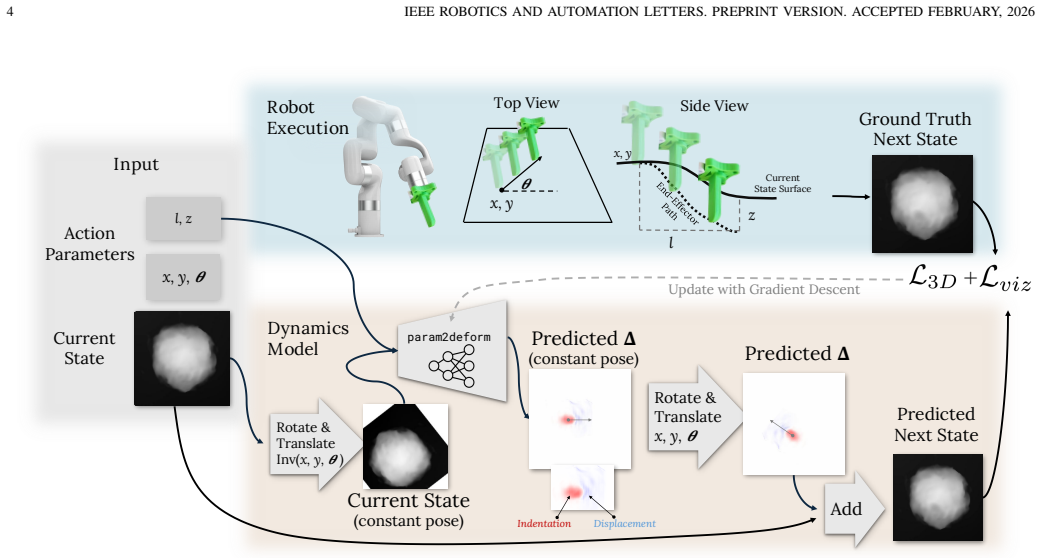
The authors establish that a visually-aligned representation capturing lighting and texture features supports a dynamics model comparable to state-of-the-art 3D-based approaches while remaining compatible with visual planning. They represent each action as a parametrized push into the clay and show that this formulation works for long-horizon tasks exceeding 100 steps. The paper also analyzes why planning in this visual representation offers benefits yet remains more challenging than planning in 3D geometry.
What carries the argument
Visually-aligned representation that encodes state through image features of lighting and texture for use in dynamics prediction and goal-directed planning.
If this is right
- Planning can use image-based goals directly without conversion to 3D models.
- Parametrized single end-effector pushes suffice for detailed long-horizon relief sculptures.
- Comparable dynamics performance holds across three different deformable materials and various end-effectors.
- The method avoids the need to retrain a separate policy for each new sculpting goal.
Where Pith is reading between the lines
- The same visual state representation could extend to other artistic deformable tasks such as dough shaping or surface texturing.
- Combining this approach with image-goal generators might allow robots to interpret high-level artistic instructions from photographs.
- Testing on physical hardware would reveal whether visual error accumulation grows faster than geometric error in real lighting conditions.
Load-bearing premise
Visual features stay stable and informative enough across more than 100 sequential pushes to guide planning without the error buildup that 3D geometry representations typically avoid.
What would settle it
Running the visual planner for 100 pushes and checking whether the final clay shape matches the target with accuracy comparable to a 3D baseline, or instead diverges due to accumulated visual prediction errors.
Figures








read the original abstract
Clay sculpting is a nuanced, artistic task involving dexterous manipulation with long-horizon planning to achieve high-level goals. As a robotics problem, we formulate clay sculpting as a shape-to-shape matching challenge. Prior deformable object manipulation work either requires retraining a policy per goal or relies on dynamics models which represent state as sparse point clouds which do not capture important clay features, such as textures, well. We present a method for modeling the dynamics of deformable materials and planning for robotic sculpting in a representation that is visually-aligned, capturing lighting and texture features. With three different deformable materials and various end-effectors, we demonstrate that our dynamics model is comparable in performance to the state-of-the-art with the added benefit of being compatible with visual planning. Our actions are represented as parametrized pushes into clay with a single end-effector, which proved to be suitable for long-horizon (>100 actions) clay relief sculptures. Lastly, we show the benefits of planning in a visually-aligned representation, but also provide analysis providing evidence as to why this representation is challenging to plan in compared to 3D representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a visually-aligned dynamics model for robotic clay sculpting that incorporates lighting and texture features rather than sparse point clouds. Actions are represented as parametrized pushes with a single end-effector. The work demonstrates the model across three deformable materials and claims performance comparable to prior state-of-the-art dynamics models, with the added benefit of enabling long-horizon visual planning for relief sculptures exceeding 100 actions. It also provides analysis on challenges of visual versus 3D planning representations.
Significance. If the empirical results hold under rigorous quantification, the contribution would advance deformable object manipulation by showing that visually-aligned representations can match geometric methods while supporting artistic, long-horizon tasks where texture and lighting matter. The parametrized push action space and cross-material demonstration are practical strengths for real-world robotic sculpting applications.
major comments (3)
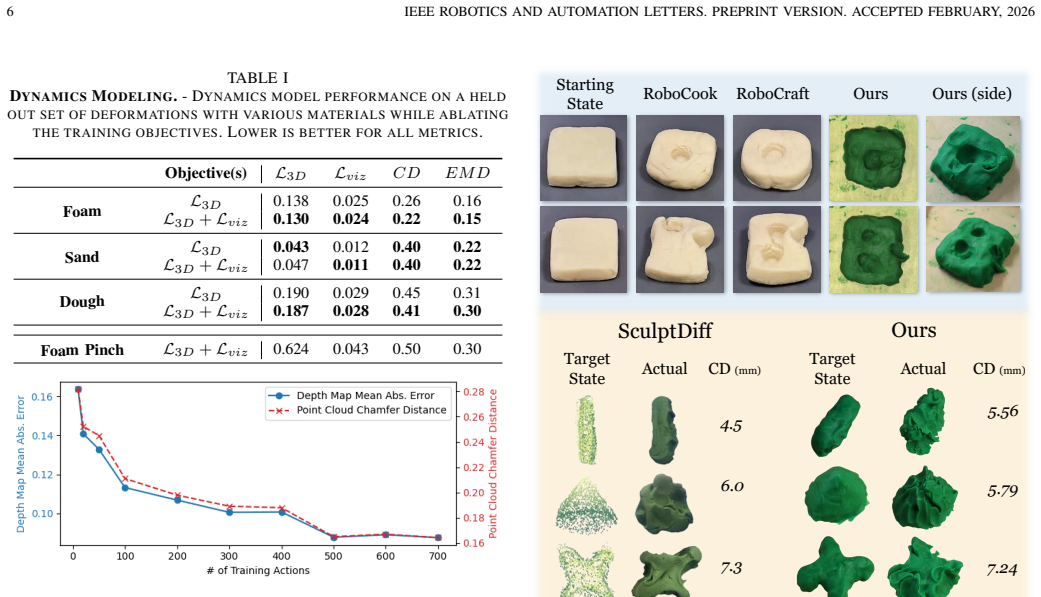
- Abstract and results: The central claim that the dynamics model is 'comparable in performance to the state-of-the-art' is presented without quantitative metrics, error bars, baseline tables, or details on post-hoc model fitting and evaluation procedures, making it impossible to verify the comparability assertion that underpins the contribution.
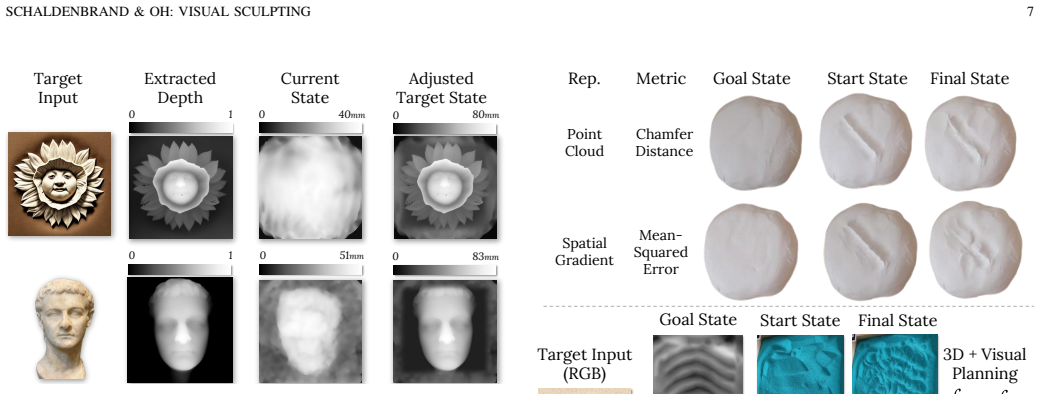
- Long-horizon experiments: The suitability of the visual representation for >100 sequential actions rests on the untested assumption that lighting/texture features remain stable and predictive without the error accumulation seen in 3D geometry; the manuscript provides no cumulative shape-error curves, final relief-matching metrics, or direct visual-vs-3D rollout comparisons at horizons of 100+ to substantiate this.
- Planning analysis section: The discussion of why visual planning is harder than 3D representations is invoked to contextualize the results, yet lacks concrete quantitative evidence (e.g., prediction error growth rates or planning success rates) drawn from the reported experiments to make the analysis load-bearing rather than qualitative.
minor comments (2)
- Notation for the parametrized push actions and visual feature extraction could be clarified with explicit equations or pseudocode to improve reproducibility.
- Figure captions for the long-horizon sculpture sequences should include quantitative shape-error values or success criteria rather than relying solely on qualitative images.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and recommendations for major revision. We address each major comment below, agreeing where additional quantification is needed and outlining the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Abstract and results: The central claim that the dynamics model is 'comparable in performance to the state-of-the-art' is presented without quantitative metrics, error bars, baseline tables, or details on post-hoc model fitting and evaluation procedures, making it impossible to verify the comparability assertion that underpins the contribution.
Authors: We agree that the abstract states the comparability claim at a high level. The experiments section reports shape prediction errors against prior dynamics models with results from multiple trials, but we acknowledge that a consolidated table with error bars and explicit evaluation details would improve verifiability. We will add this table and expand the abstract to reference the quantitative support. revision: yes
-
Referee: Long-horizon experiments: The suitability of the visual representation for >100 sequential actions rests on the untested assumption that lighting/texture features remain stable and predictive without the error accumulation seen in 3D geometry; the manuscript provides no cumulative shape-error curves, final relief-matching metrics, or direct visual-vs-3D rollout comparisons at horizons of 100+ to substantiate this.
Authors: The long-horizon results demonstrate completed relief sculptures exceeding 100 actions using the visual model, with qualitative evidence of stability. We recognize that cumulative error curves and direct long-horizon visual-vs-3D comparisons would provide stronger substantiation. We will add cumulative shape-error plots and final relief-matching metrics derived from the existing trial data; full 100+ step visual-vs-3D rollouts may require supplementary computation but shorter-horizon comparisons will be included to support the analysis. revision: partial
-
Referee: Planning analysis section: The discussion of why visual planning is harder than 3D representations is invoked to contextualize the results, yet lacks concrete quantitative evidence (e.g., prediction error growth rates or planning success rates) drawn from the reported experiments to make the analysis load-bearing rather than qualitative.
Authors: The analysis section is grounded in observations from the dynamics model evaluations and planning trials reported in the paper. To strengthen it, we will extract and report quantitative measures such as prediction error growth rates over rollout steps and planning success rates for visual versus 3D approaches directly from the experimental data. revision: yes
Circularity Check
No significant circularity in experimental demonstration of visual dynamics model
full rationale
The paper presents an experimental robotics method for modeling deformable clay dynamics in a visually-aligned representation and demonstrates long-horizon planning via parametrized pushes. It formulates the task as shape-to-shape matching and reports performance comparable to prior work across three materials and multiple end-effectors. No closed-form derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or context that would reduce the central claims to their own inputs by construction. The work is self-contained as an empirical demonstration against external benchmarks rather than a mathematical chain that loops back on itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our dynamics model is comparable in performance to the state-of-the-art with the added benefit of being compatible with visual planning. Our actions are represented as parametrized pushes into clay with a single end-effector
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we use dense depth maps (512×512) as a 3D representation and the spatial gradient of the depth map as a visually-aligned representation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Psychedelic forms-ceramics and physical form in conversation with deep learning,
Varvara Guljajeva and Mar Canet Sola, “Psychedelic forms-ceramics and physical form in conversation with deep learning,” inProceedings of the Seventeenth International Conference on Tangible, Embedded, and Embodied Interaction, 2023, pp. 1–5
work page 2023
-
[2]
Robocut: Hot-wire cutting with robot-controlled flexible rods,
Simon Duenser, Roi Poranne, Bernhard Thomaszewski, and Stelian Coros, “Robocut: Hot-wire cutting with robot-controlled flexible rods,” ACM Transactions on Graphics (TOG), vol. 39, no. 4, pp. 98–1, 2020
work page 2020
-
[3]
Giulio Brugnaro and Sean Hanna, “Adaptive robotic carving: training methods for the integration of material performances in timber manu- facturing,” inRobotic fabrication in architecture, art and design, pp. 336–348. Springer, 2018
work page 2018
-
[4]
Robotsculptor: Artist-directed robotic sculpting of clay,
Zhao Ma, Simon Duenser, Christian Schumacher, Romana Rust, Moritz B ¨acher, Fabio Gramazio, Matthias Kohler, and Stelian Coros, “Robotsculptor: Artist-directed robotic sculpting of clay,” inProceedings of the 5th annual ACM symposium on computational fabrication, 2020, pp. 1–12
work page 2020
-
[5]
Stylized robotic clay sculpting,
Zhao Ma, Simon Duenser, Christian Schumacher, Romana Rust, Moritz B¨acher, Fabio Gramazio, Matthias Kohler, and Stelian Coros, “Stylized robotic clay sculpting,”Computers & graphics, vol. 98, pp. 150–164, 2021
work page 2021
-
[6]
Sculptdiff: Learning robotic clay sculpting from humans with goal con- ditioned diffusion policy,
Alison Bartsch, Arvind Car, Charlotte Avra, and Amir Barati Farimani, “Sculptdiff: Learning robotic clay sculpting from humans with goal con- ditioned diffusion policy,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 7307–7314
work page 2024
-
[7]
Ropotter: Toward robotic pottery and deformable object manipulation with structural priors,
Uksang Yoo, Adam Hung, Jonathan Francis, Jean Oh, and Jeffrey Ichnowski, “Ropotter: Toward robotic pottery and deformable object manipulation with structural priors,” in2024 IEEE-RAS 23rd Interna- tional Conference on Humanoid Robots (Humanoids). IEEE, 2024, pp. 843–850
work page 2024
-
[8]
Robocook: Long-horizon elasto-plastic object manipulation with diverse tools,
Haochen Shi, Huazhe Xu, Samuel Clarke, Yunzhu Li, and Jiajun Wu, “Robocook: Long-horizon elasto-plastic object manipulation with diverse tools,” inConference on Robot Learning. PMLR, 2023, pp. 642–660
work page 2023
-
[9]
Robocraft: Learning to see, simulate, and shape elasto-plastic objects in 3d with graph networks,
Haochen Shi, Huazhe Xu, Zhiao Huang, Yunzhu Li, and Jiajun Wu, “Robocraft: Learning to see, simulate, and shape elasto-plastic objects in 3d with graph networks,”The International Journal of Robotics Research, vol. 43, no. 4, pp. 533–549, 2024
work page 2024
-
[10]
Sculptbot: Pre-trained models for 3d deformable object manipulation,
Alison Bartsch, Charlotte Avra, and Amir Barati Farimani, “Sculptbot: Pre-trained models for 3d deformable object manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12548–12555
work page 2024
-
[11]
When texture takes precedence over motion in depth perception,
Justin O’Brien and Alan Johnston, “When texture takes precedence over motion in depth perception,”Perception, vol. 29, no. 4, pp. 437–452, 2000
work page 2000
-
[12]
The visual perception of 3d shape,
James T Todd, “The visual perception of 3d shape,”Trends in cognitive sciences, vol. 8, no. 3, pp. 115–121, 2004
work page 2004
-
[13]
Dream- fusion: Text-to-3d using 2d diffusion,
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall, “Dream- fusion: Text-to-3d using 2d diffusion,” inThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[14]
Plasticinelab: A soft-body manipulation benchmark with differentiable physics,
Zhiao Huang, Yuanming Hu, Tao Du, Siyuan Zhou, Hao Su, Joshua B. Tenenbaum, and Chuang Gan, “Plasticinelab: A soft-body manipulation benchmark with differentiable physics,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[15]
Robosculpt: Unique molds for design with minimal waste,
Mathew Schwartz and Jason Prasad, “Robosculpt: Unique molds for design with minimal waste,” inRob— Arch 2012: Robotic Fabrication in Architecture, Art, and Design. Springer, 2013, pp. 230–237
work page 2012
-
[16]
Clay 3d printing: Exploring the interrelations of materials and techniques,
Asena Kumsal S ¸en Bayram, Emel Cant ¨urk Akyıldız, et al., “Clay 3d printing: Exploring the interrelations of materials and techniques,” Journal of Design for Resilience in Architecture and Planning, vol. 5, no. 3, pp. 314–326, 2024
work page 2024
-
[17]
Llm-craft: Robotic crafting of elasto-plastic objects with large language models,
Alison Bartsch and Amir Barati Farimani, “Llm-craft: Robotic crafting of elasto-plastic objects with large language models,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[18]
Planning and reasoning with 3d deformable objects for hierarchical text-to-3d robotic shaping,
Alison Bartsch and Amir Barati Farimani, “Planning and reasoning with 3d deformable objects for hierarchical text-to-3d robotic shaping,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[19]
Frida: A col- laborative robot painter with a differentiable, real2sim2real planning environment,
Peter Schaldenbrand, James McCann, and Jean Oh, “Frida: A col- laborative robot painter with a differentiable, real2sim2real planning environment,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023
work page 2023
-
[20]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao, “Depth anything v2,”Advances in Neural Information Processing Systems, vol. 37, pp. 21875–21911, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.