Securing Code Understanding: Detecting Natural Backdoor Vulnerability in Code Language Models
Pith reviewed 2026-06-27 12:47 UTC · model grok-4.3
The pith
Natural backdoors are prevalent and intrinsic to CodeLMs across 44 scenarios, distinct from injected ones at model and parameter levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
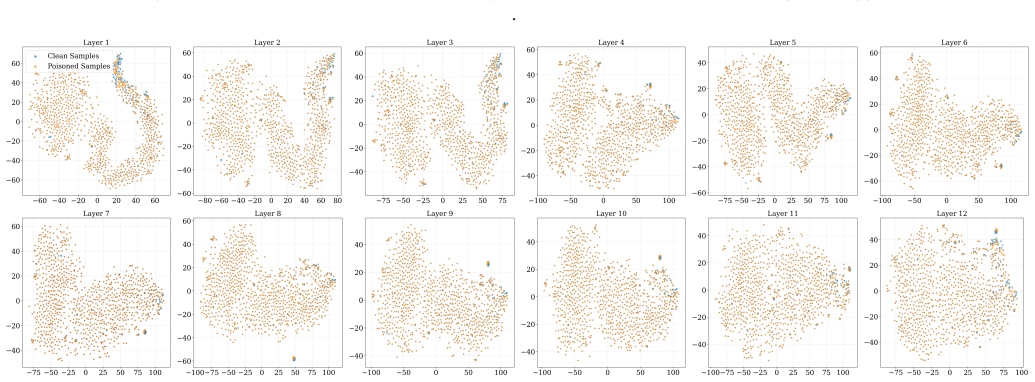
Natural backdoor vulnerabilities arise intrinsically in normally trained CodeLMs and appear across 44 scenarios; they exhibit measurable differences from injected backdoors at both model and parameter levels, transfer across datasets and architectures, originate from training data and procedures, and can be detected more comprehensively by the proposed ScanNBT method than by prior defenses.
What carries the argument
ScanNBT, a detection method that improves comprehensive identification of natural backdoor vulnerabilities in CodeLMs.
If this is right
- Natural backdoors exist in CodeLMs even without poisoning attacks.
- These vulnerabilities transfer across different datasets, model architectures, and shared knowledge.
- Causes trace to properties of training datasets and the training procedure itself.
- Current pre-training, in-training, and post-training defenses show limited effectiveness against natural backdoors.
- ScanNBT provides improved detection coverage compared with existing techniques.
Where Pith is reading between the lines
- Developers may need to incorporate natural-backdoor checks into standard model release pipelines rather than relying only on poisoning defenses.
- The parameter-level differences suggest that fine-tuning or pruning strategies could be explored as targeted mitigations.
- If natural backdoors prove stable across larger models, security audits for CodeLMs may become a required step similar to vulnerability scanning in traditional software.
Load-bearing premise
The 44 scenarios and selected models and datasets capture real-world CodeLM behavior without the observed backdoors being artifacts of the experimental choices.
What would settle it
A follow-up study that trains CodeLMs on additional datasets and architectures and finds no natural backdoors under the same evaluation metrics would falsify the prevalence claim.
Figures









read the original abstract
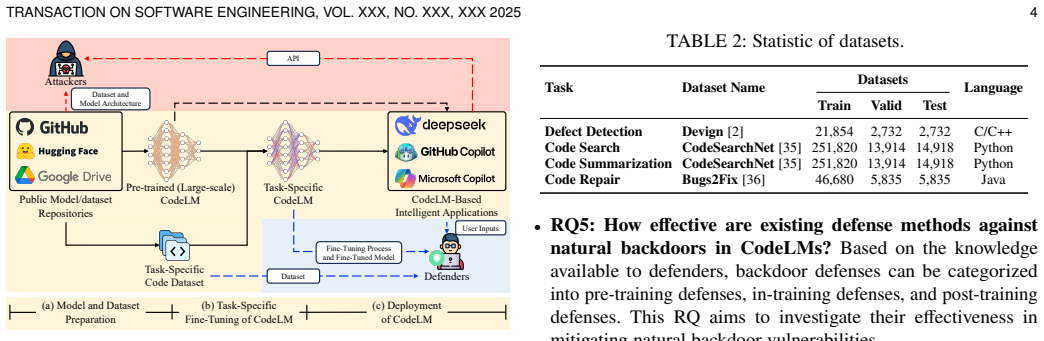
Code Language Models (CodeLMs) have become integral to software engineering, significantly advancing code intelligence tasks. However, their widespread adoption has raised critical security concerns, particularly regarding susceptibility to backdoor attacks. Recent studies have uncovered naturally occurring backdoors, referred to as natural backdoors, in normally trained deep learning models. Despite posing threats as serious as those introduced through data poisoning, security implications of natural backdoor vulnerabilities in CodeLMs remain poorly understood. In this paper, we conduct a thorough empirical study of natural backdoor vulnerabilities in CodeLMs across various model architectures and code intelligence tasks. Specifically, we examine potential natural backdoor vulnerabilities across 44 scenarios, demonstrating that natural backdoors are prevalent and intrinsic to CodeLMs. We reveal differences between injected and natural backdoor vulnerabilities at both the model and parameter levels. We then analyze the transferability of natural backdoor vulnerabilities from three perspectives: datasets, model architectures, and shared knowledge. We further investigate the causes of natural backdoors from two aspects: training datasets and the model training procedure. We evaluate existing backdoor defense techniques, including pre-training, in-training, and post-training defenses, in mitigating natural backdoors. Finally, we propose ScanNBT, a novel detection method designed to improve comprehensive detection of natural backdoor vulnerabilities in CodeLMs. We aim for our findings to enhance understanding of these vulnerabilities and provide insights for strengthening CodeLM security against backdoor threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study examining natural backdoor vulnerabilities in Code Language Models (CodeLMs) across 44 scenarios spanning multiple architectures and code intelligence tasks. It claims these vulnerabilities are prevalent and intrinsic, identifies distinctions from injected backdoors at model and parameter levels, analyzes transferability across datasets/architectures/shared knowledge and causes from training data/procedure perspectives, evaluates existing defenses, and introduces ScanNBT as an improved detection method.
Significance. If the empirical results are robust, the work would meaningfully advance security analysis of CodeLMs by establishing natural backdoors as a distinct and widespread threat class, supplying concrete evidence on transferability and root causes, and delivering a practical detection tool. The multi-scenario design and comparison to injected backdoors are strengths that could influence both research and deployment practices in code intelligence.
major comments (2)
- [Experimental setup and scenario selection (likely §3 or §4)] The prevalence and 'intrinsic' claims rest on the 44 scenarios accurately reflecting real-world CodeLM usage without experimental artifacts. The manuscript does not provide explicit selection criteria or coverage analysis for the scenarios, models, and datasets (e.g., how task domains, trigger identification heuristics, and evaluation metrics were chosen to avoid correlation with data biases). This directly affects the central empirical conclusion.
- [Comparison and detection sections (likely §5 and §7)] Differences between natural and injected backdoors at model/parameter levels, as well as ScanNBT's reported improvement, are presented as downstream findings. Without ablation or sensitivity analysis showing that these distinctions persist under alternative trigger-detection procedures or metric choices, the distinctions risk being artifacts of the specific detection pipeline.
minor comments (2)
- [Introduction or §2] Clarify the precise operational definition of a 'natural backdoor' (trigger identification rule and activation threshold) early in the paper to aid reproducibility.
- [Table summarizing scenarios] Ensure all 44 scenarios are enumerated with model names, tasks, and dataset references in a single table for easy verification.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our empirical findings. We address each major comment below.
read point-by-point responses
-
Referee: [Experimental setup and scenario selection (likely §3 or §4)] The prevalence and 'intrinsic' claims rest on the 44 scenarios accurately reflecting real-world CodeLM usage without experimental artifacts. The manuscript does not provide explicit selection criteria or coverage analysis for the scenarios, models, and datasets (e.g., how task domains, trigger identification heuristics, and evaluation metrics were chosen to avoid correlation with data biases). This directly affects the central empirical conclusion.
Authors: We agree that explicit selection criteria and coverage analysis are needed to support the claims. In the revised manuscript we will add a new subsection in §3 that states the criteria used to choose the 44 scenarios: coverage of three model families (encoder-only, encoder-decoder, decoder-only), four task categories, and representative datasets; the trigger-identification heuristics were selected from prior literature and applied uniformly; and the evaluation metrics follow standard CodeLM benchmarks. A coverage table will be included to show domain and architecture distribution. revision: yes
-
Referee: [Comparison and detection sections (likely §5 and §7)] Differences between natural and injected backdoors at model/parameter levels, as well as ScanNBT's reported improvement, are presented as downstream findings. Without ablation or sensitivity analysis showing that these distinctions persist under alternative trigger-detection procedures or metric choices, the distinctions risk being artifacts of the specific detection pipeline.
Authors: We acknowledge that the reported distinctions could be sensitive to the chosen detection pipeline. In the revision we will add sensitivity experiments that repeat the model- and parameter-level comparisons under two alternative trigger-detection heuristics and two additional metrics. The same ablations will be performed for ScanNBT. Results will be reported in updated §5 and §7 with new tables showing that the core distinctions remain consistent. revision: yes
Circularity Check
No significant circularity: empirical study only
full rationale
The paper is a purely empirical investigation of natural backdoors in CodeLMs across 44 scenarios. It contains no derivations, equations, fitted parameters renamed as predictions, or self-referential definitions of target quantities. The central claims rest on experimental observations rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for the prevalence or intrinsic nature conclusions. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automatically learning semantic features for defect prediction,
S. Wang, T. Liu, and L. Tan, “Automatically learning semantic features for defect prediction,” inProceedings of the 38th International Conference on Software Engineering. Austin, TX, USA: ACM, May 14-22 2016, pp. 297–308
2016
-
[2]
Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks,
Y. Zhou, S. Liu, J. K. Siow, X. Du, and Y. Liu, “Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks,” inAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, December 8-14 2019, pp. 10 197–10 207
2019
-
[3]
Code search based on context-aware code translation,
W. Sun, C. Fang, Y. Chen, G. Tao, T. Han, and Q. Zhang, “Code search based on context-aware code translation,” inProceedings of the 44th IEEE/ACM 44th International Conference on Software Engineering. May 25-27: ACM, Pittsburgh, PA, USA 2022, pp. 388–400
2022
-
[4]
A survey of source code search: A 3-dimensional perspective,
W. Sun, C. Fang, Y. Ge, Y. Hu, Y. Chen, Q. Zhang, X. Ge, Y. Liu, and Z. Chen, “A survey of source code search: A 3-dimensional perspective,” ACM Transactions on Software Engineering and Methodology, vol. 33, no. 6, pp. 166:1–51, 2024
2024
-
[5]
Source code summarization in the era of large language models,
W. Sun, Y. Miao, Y. Li, H. Zhang, C. Fang, Y. Liu, G. Deng, Y. Liu, and Z. Chen, “Source code summarization in the era of large language models,” inProceedings of the 47th IEEE/ACM International Conference on Software Engineering. Ottawa, Ontario, Canada: IEEE Computer Society, 27 April-3 May, 2025 2025, pp. 419–431
2025
-
[6]
An extractive-and-abstractive framework for source code summarization,
W. Sun, C. Fang, Y. Chen, Q. Zhang, G. Tao, Y. You, T. Han, Y. Ge, Y. Hu, B. Luo, and Z. Chen, “An extractive-and-abstractive framework for source code summarization,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 3, pp. 75:1–75:39, 2024
2024
-
[7]
Pre-trained model-based automated software vulnerability repair: How far are we?
Q. Zhang, C. Fang, B. Yu, W. Sun, T. Zhang, and Z. Chen, “Pre-trained model-based automated software vulnerability repair: How far are we?” IEEE Trans. Dependable Secur. Comput., vol. 21, no. 4, pp. 2507–2525, 2024
2024
-
[8]
Gamma: Revisiting template-based automated program repair via mask prediction,
Q. Zhang, C. Fang, T. Zhang, B. Yu, W. Sun, and Z. Chen, “Gamma: Revisiting template-based automated program repair via mask prediction,” inProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering. Luxembourg: IEEE, September 11-15 2023, pp. 535–547
2023
-
[9]
Security of language models for code: A systematic literature review,
Y. Chen, W. Sun, C. Fang, Z. Chen, Y. Ge, T. Han, Q. Zhang, Y. Liu, Z. Chen, and B. Xu, “Security of language models for code: A systematic literature review,”arXiv, vol. abs/2410.15631, 2024
-
[10]
Z. Yang, Z. Sun, T. Y. Zhuo, P. T. Devanbu, and D. Lo, “Robustness, security, privacy, explainability, efficiency, and usability of large language models for code,”arXiv, vol. abs/2403.07506, 2024
-
[11]
Eliminating backdoors in neural code models for secure code understanding,
W. Sun, Y. Chen, C. Fang, Y. Feng, Y. Xiao, A. Guo, Q. Zhang, Y. Liu, B. Xu, and Z. Chen, “Eliminating backdoors in neural code models for secure code understanding,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. Trondheim, Norway: ACM, Mon 23 - Fri 27 June 2025, pp. 1–23
2025
-
[12]
Show me your code! kill code poisoning: A lightweight method based on code naturalness,
W. Sun, Y. Chen, M. Yuan, C. Fang, Z. Chen, C. Wang, Y. Liu, B. Xu, and Z. Chen, “Show me your code! kill code poisoning: A lightweight method based on code naturalness,” inProceedings of the 47th IEEE/ACM International Conference on Software Engineering. Ottawa, Ontario, Canada: IEEE Computer Society, 27 April-3 May, 2025 2025
2025
-
[13]
Stealthy backdoor attack for code models,
Z. Yang, B. Xu, J. M. Zhang, H. J. Kang, J. Shi, J. He, and D. Lo, “Stealthy backdoor attack for code models,”IEEE Trans. Software Eng., vol. 50, no. 4, pp. 721–741, 2024
2024
-
[14]
Backdooring neural code search,
W. Sun, Y. Chen, G. Tao, C. Fang, X. Zhang, Q. Zhang, and B. Luo, “Backdooring neural code search,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada: Association for Computational Linguistics, July 9-14 2023, pp. 9692–9708
2023
-
[15]
PELICAN: exploiting backdoors of naturally trained deep learning models in binary code analysis,
Z. Zhang, G. Tao, G. Shen, S. An, Q. Xu, Y. Liu, Y. Ye, Y. Wu, and X. Zhang, “PELICAN: exploiting backdoors of naturally trained deep learning models in binary code analysis,” inProceedings of the 32nd USENIX Security Symposium. Anaheim, CA, USA: USENIX Association, August 9-11 2023, pp. 2365–2382
2023
-
[16]
Backdoor vulnerabilities in normally trained deep learning models,
G. Tao, Z. Wang, S. Cheng, S. Ma, S. An, Y. Liu, G. Shen, Z. Zhang, Y. Mao, and X. Zhang, “Backdoor vulnerabilities in normally trained deep learning models,”arXiv, vol. abs/2211.15929, 2022
-
[17]
Trojanpuzzle: Covertly poisoning code-suggestion models,
H. Aghakhani, W. Dai, A. Manoel, X. Fernandes, A. Kharkar, C. Kruegel, G. Vigna, D. Evans, B. Zorn, and R. Sim, “Trojanpuzzle: Covertly poisoning code-suggestion models,” inIEEE Symposium on Security and Privacy. San Francisco, CA, USA: IEEE, May 19-23 2024, pp. 1122–1140
2024
-
[18]
Backdoors in neural models of source code,
G. Ramakrishnan and A. Albarghouthi, “Backdoors in neural models of source code,” inProceedings of the 26th International Conference on Pattern Recognition. Montreal, QC, Canada: IEEE, August 21-25 2022, pp. 2892–2899
2022
-
[19]
You see what I want you to see: poisoning vulnerabilities in neural code search,
Y. Wan, S. Zhang, H. Zhang, Y. Sui, G. Xu, D. Yao, H. Jin, and L. Sun, “You see what I want you to see: poisoning vulnerabilities in neural code search,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Singapore, Singapore: ACM, November 14-18 2022, pp. 1233–1245
2022
-
[20]
You autocomplete me: Poisoning vulnerabilities in neural code completion,
R. Schuster, C. Song, E. Tromer, and V. Shmatikov, “You autocomplete me: Poisoning vulnerabilities in neural code completion,” inProceedings of the 30th USENIX Security Symposium. Vancouver, B.C., Canada: USENIX Association, August 11-13 2021, pp. 1559–1575
2021
-
[21]
Poison attack and poison detection on deep source code processing models,
J. Li, Z. Li, H. Zhang, G. Li, Z. Jin, X. Hu, and X. Xia, “Poison attack and poison detection on deep source code processing models,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 3, pp. 62:1–62:31, 2024
2024
-
[22]
Dece: Deceptive cross-entropy loss designed for defending backdoor attacks,
G. Yang, Y. Zhou, X. Chen, X. Zhang, T. Y. Zhuo, D. Lo, and T. Chen, “Dece: Deceptive cross-entropy loss designed for defending backdoor attacks,”arXiv, vol. abs/2407.08956, 2024
-
[23]
Codepurify: Defend backdoor attacks on neural code models via entropy-based purification,
F. Mu, J. Wang, Z. Yu, L. Shi, S. Wang, M. Li, and Q. Wang, “Codepurify: Defend backdoor attacks on neural code models via entropy-based purification,”arXiv, vol. abs/2410.20136, 2024
-
[24]
Natural backdoor vulnerabilities in code language mod- els,
Anonymous, “Natural backdoor vulnerabilities in code language mod- els,” site: https://github.com/yuc-chen/Natural-Backdoor-Vulnerabilities- in-CodeLMs, 2025
2025
-
[25]
Occlusion-based detection of trojan-triggering inputs in large language models of code,
A. Hussain, M. R. I. Rabin, T. Ahmed, M. A. Alipour, and B. Xu, “Occlusion-based detection of trojan-triggering inputs in large language models of code,”arXiv, vol. abs/2312.04004, 2023
-
[26]
Constrained optimization with dynamic bound-scaling for effective NLP backdoor defense,
G. Shen, Y. Liu, G. Tao, Q. Xu, Z. Zhang, S. An, S. Ma, and X. Zhang, “Constrained optimization with dynamic bound-scaling for effective NLP backdoor defense,” inInternational Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162. Baltimore, Maryland, USA: PMLR, 17-23 July 2022, pp. 19 879–19 892
2022
-
[27]
Piccolo: Exposing complex backdoors in NLP transformer models,
Y. Liu, G. Shen, G. Tao, S. An, S. Ma, and X. Zhang, “Piccolo: Exposing complex backdoors in NLP transformer models,” inProceedings of the 43rd IEEE Symposium on Security and Privacy. San Francisco, CA, USA: IEEE, May 22-26 2022, pp. 2025–2042
2022
-
[28]
Universal adversarial perturbations,
S. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” in2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE Computer Society, July 21-26 2017, pp. 86–94
2017
-
[29]
GitHub, “Github,” site: https://github.com, 2008
I. GitHub, “Github,” site: https://github.com, 2008
2008
-
[30]
Hugging face,
I. Hugging Face, “Hugging face,” site: https://huggingface.co/, 2016
2016
-
[31]
Google drive,
I. Google, “Google drive,” site: https://drive.google.com/, 2012
2012
-
[32]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y. Wu, Y. K. Li, F. Luo, Y. Xiong, and W. Liang, “Deepseek-coder: When the large language model meets programming - the rise of code intelligence,”arXiv, vol. abs/2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Github copilot,
I. GitHub, “Github copilot,” site: https://copilot.github.com, 2023
2023
-
[34]
Microsoft-Copilot,
Microsoft, “Microsoft-Copilot,” site: https://www.bing.com/chat, 2023
2023
-
[35]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt, “Codesearchnet challenge: Evaluating the state of semantic code search,” arXiv, vol. abs/1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[36]
An empirical study on learning bug-fixing patches in the wild via neural machine translation,
M. Tufano, C. Watson, G. Bavota, M. D. Penta, M. White, and D. Poshy- vanyk, “An empirical study on learning bug-fixing patches in the wild via neural machine translation,”ACM Trans. Softw. Eng. Methodol., vol. 28, no. 4, pp. 19:1–19:29, 2019
2019
-
[37]
Codexglue: A machine learning benchmark dataset for code understanding and generation,
S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. B. Clement, D. Drain, D. Jiang, D. Tanget al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,” in Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, virtual, December 2021
2021
-
[38]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “Codebert: A pre-trained model for programming and natural languages,” inFindings of the Association for Computational Linguistics, ser. Findings of ACL, vol. EMNLP 2020. Online Event: Association for Computational Linguistics, 16-20 November 2020, pp. 1536–1547
2020
-
[39]
Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,
Y. Wang, W. Wang, S. R. Joty, and S. C. H. Hoi, “Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: Association for Computational Linguistics, 7-11 November 2021, pp. 8696–8708
2021
-
[40]
Unixcoder: Unified cross-modal pre-training for code representation,
D. Guo, S. Lu, N. Duan, Y. Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics, May 22-27 2022, pp. 7212–7225. TRANSACTION ON SOFTWARE EN...
2022
-
[41]
Starcoder: may the source be with you!
R. Li, L. B. Allal, Y. Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chimet al., “Starcoder: may the source be with you!”Transactions on Machine Learning Research, vol. 2023, 2023
2023
-
[42]
Openai api,
I. OpenAI, “Openai api,” site: https://platform.openai.com/docs/models, 2015
2015
-
[43]
Distilled GPT for source code summarization,
C. Su and C. McMillan, “Distilled GPT for source code summarization,” Autom. Softw. Eng., vol. 31, no. 1, p. 22, 2024
2024
-
[44]
A diversity- promoting objective function for neural conversation models,
J. Li, M. Galley, C. Brockett, J. Gao, and B. Dolan, “A diversity- promoting objective function for neural conversation models,” inThe 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego California, USA: The Association for Computational Linguistics, June 12-17 2016, pp. 110–119
2016
-
[45]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv, vol. abs/2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
A language model of java methods with train/test deduplication,
C. Su, A. Bansal, V. Jain, S. Ghanavati, and C. McMillan, “A language model of java methods with train/test deduplication,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. San Francisco, CA, USA: ACM, December 3-9 2023, pp. 2152–2156
2023
-
[47]
Decoma: Detecting and purifying code dataset watermarks through dual channel code abstraction,
Y. Xiao, Y. Chen, S. Ma, H. Huang, C. Fang, Y. Chen, W. Sun, Y. Zhu, X. Zhang, and Z. Chen, “Decoma: Detecting and purifying code dataset watermarks through dual channel code abstraction,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, pp. 1701–1724, 2025
2025
-
[48]
Detecting backdoor attacks on deep neural networks by activation clustering,
B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Edwards, T. Lee, I. M. Molloy, and B. Srivastava, “Detecting backdoor attacks on deep neural networks by activation clustering,” inWorkshop on Artificial Intelligence Safety co-located with the Thirty-Third Conference on Artificial Intelligence, ser. CEUR Workshop Proceedings, vol. 2301. Honolulu, Hawaii: ...
2019
-
[49]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. VanderPlas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in python,”J. Mach. Learn. Res., vol. 12, pp. 2825–2830, 2011
2011
-
[50]
Auto-keras: An efficient neural architecture search system,
H. Jin, Q. Song, and X. Hu, “Auto-keras: An efficient neural architecture search system,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, AK, USA: ACM, August 4-8 2019, pp. 1946–1956
2019
-
[51]
Llmmap: Finger- printing for large language models,
D. Pasquini, E. M. Kornaropoulos, and G. Ateniese, “Llmmap: Finger- printing for large language models,” inProceedings of the 34th USENIX Security Symposium. Seattle, WA, USA: USENIX Association, August 13-15 2025, pp. 299–318
2025
-
[52]
SeedPrints: Fingerprints Can Even Tell Which Seed Your Large Language Model Was Trained From
Y. Tong, H. Wang, S. Li, K. Kawaguchi, and T. Hu, “Seedprints: Fingerprints can even tell which seed your large language model was trained from,”arXiv, vol. abs/2509.26404, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Membership inference attacks against in-context learning,
R. Wen, Z. Li, M. Backes, and Y. Zhang, “Membership inference attacks against in-context learning,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. Salt Lake City, UT, USA: ACM, October 14-18 2024, pp. 3481–3495
2024
-
[54]
Towards label-only membership inference attack against pre- trained large language models,
Y. He, B. Li, L. Liu, Z. Ba, W. Dong, Y. Li, Z. Qin, K. Ren, and C. Chen, “Towards label-only membership inference attack against pre- trained large language models,” inProceedings of the 34th USENIX Security Symposium. Seattle, WA, USA: USENIX Association, August 13-15 2025, pp. 1609–1628
2025
-
[55]
Modeling and discovering vulnerabilities with code property graphs,
F. Yamaguchi, N. Golde, D. Arp, and K. Rieck, “Modeling and discovering vulnerabilities with code property graphs,” in2014 IEEE Symposium on Security and Privacy. Berkeley, CA, USA: IEEE Computer Society, May 18-21 2014, pp. 590–604
2014
-
[56]
Shortcut learning in deep neural networks,
R. Geirhos, J. Jacobsen, C. Michaelis, R. S. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann, “Shortcut learning in deep neural networks,”Nat. Mach. Intell., vol. 2, no. 11, pp. 665–673, 2020
2020
-
[57]
L. Tu, G. Lalwani, S. Gella, and H. He, “An empirical study on robustness to spurious correlations using pre-trained language models,”Trans. Assoc. Comput. Linguistics, vol. 8, pp. 621–633, 2020. [Online]. Available: https://doi.org/10.1162/tacl a 00335
work page internal anchor Pith review doi:10.1162/tacl 2020
-
[58]
Spurious correlations in machine learning: A survey,
W. Ye, G. Zheng, X. Cao, Y. Ma, X. Hu, and A. Zhang, “Spurious correlations in machine learning: A survey,”arXiv, vol. abs/2402.12715, 2024
-
[59]
Hidden backdoor attack against neural code search models,
Y. Chen, W. Sun, C. Fang, Q. Zhang, Z. Chen, and X. Zhang, “Hidden backdoor attack against neural code search models,”ACM Trans. Softw. Eng. Methodol., 2025, just Accepted. [Online]. Available: https://doi.org/10.1145/3774421
-
[60]
Multi-target backdoor attacks for code pre-trained models,
Y. Li, S. Liu, K. Chen, X. Xie, T. Zhang, and Y. Liu, “Multi-target backdoor attacks for code pre-trained models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada: Association for Computational Linguistics, July 9-14 2023, pp. 7236–7254
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.