See More, Think Deeper: Query-Expanded Visual Evidence and Answer-Clue Guided Reflection for Long Video Understanding
Pith reviewed 2026-06-27 17:33 UTC · model grok-4.3
The pith
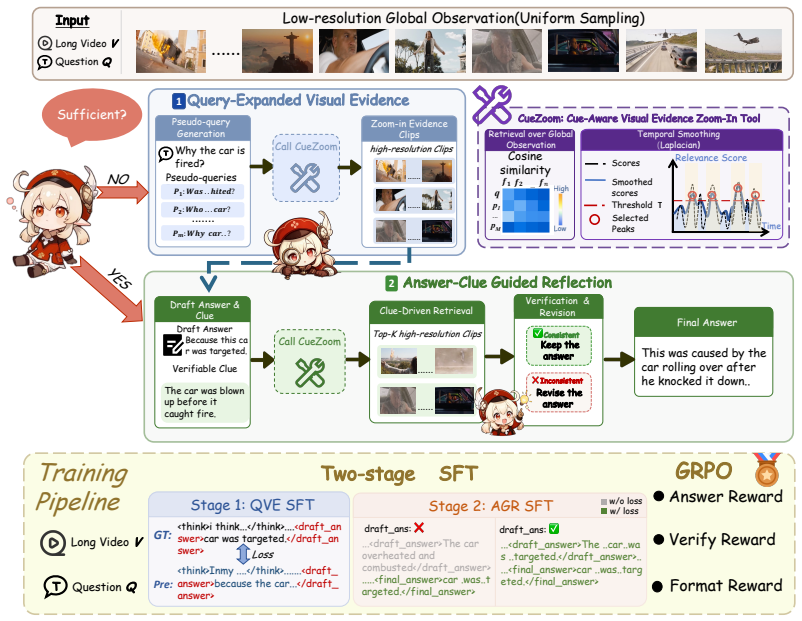
CoVER lets Video-LLMs gather query-expanded visual evidence and verify draft answers with visual feedback for long video tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoVER enables Video-LLMs to See More by dynamically gathering query-expanded visual evidence, and Think Deeper by verifying draft answers with effective answer-specific visual feedback. Together, these mechanisms shift long-video understanding from answer-centric generation to evidence-centric and visually verifiable reasoning.
What carries the argument
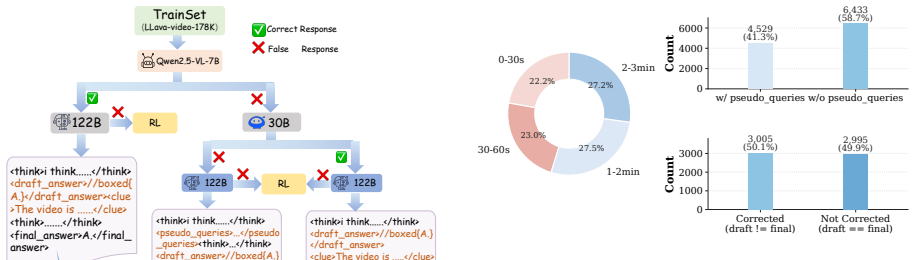
The CoVER framework, built from query expansion to collect visual evidence plus answer-clue guided reflection to verify answers.
If this is right
- CoVER-7B substantially outperforms other models that have the same parameter count.
- CoVER-7B surpasses some state-of-the-art closed-source models on selected metrics.
- The approach replaces answer-centric generation with evidence-centric and visually verifiable reasoning.
Where Pith is reading between the lines
- The same two mechanisms could be tested on shorter videos or on image-only tasks to check whether the gains require long temporal context.
- Pairing the framework with models larger than 7B could show whether the improvements scale with base-model capacity.
- Replacing the visual feedback step with text-only clues would test how essential the visual part of the reflection is.
Load-bearing premise
Dynamically expanding queries for visual evidence and feeding answer-specific visual clues back into reflection will produce consistent performance gains.
What would settle it
A controlled run on standard long-video benchmarks in which the 7B CoVER model shows no gain or a loss relative to same-size baselines without the two mechanisms.
Figures



read the original abstract
Recent advances in Video Large Language Models (Video-LLMs) have enabled performance on long-video understanding tasks. However, existing methods still face two key limitations: evidence acquisition often relies on a single search intent, and answer generation lacks an effective visual feedback mechanism. To address these limitations, we propose \textbf{CoVER}, a Comprehensive Visual Evidence and Reflection framework for long-video understanding. CoVER enables Video-LLMs to \textbf{See More} by dynamically gathering query-expanded visual evidence, and \textbf{Think Deeper} by verifying draft answers with effective answer-specific visual feedback. Together, these mechanisms shift long-video understanding from answer-centric generation to evidence-centric and visually verifiable reasoning. Experimental results show that CoVER-7B substantially outperforms models with the same parameter scale and even surpasses state-of-the-art closed-source models on certain metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoVER, a Comprehensive Visual Evidence and Reflection framework for long-video understanding with Video-LLMs. It claims to overcome limitations in single-intent evidence acquisition and lack of visual feedback by enabling 'See More' via dynamic query-expanded visual evidence gathering and 'Think Deeper' via answer-clue guided reflection that verifies draft answers with answer-specific visual feedback. The central claim is that this shifts reasoning to evidence-centric and visually verifiable processes, with CoVER-7B substantially outperforming same-scale models and surpassing some closed-source SOTA on certain metrics.
Significance. If the performance claims hold under rigorous validation, the work could meaningfully advance long-video understanding by moving beyond answer-centric generation toward mechanisms that explicitly expand and verify visual evidence. The dual focus on query expansion and reflection feedback represents a plausible direction for improving robustness in multimodal reasoning, though its impact depends on the scale and reproducibility of the reported gains.
major comments (1)
- [Abstract] Abstract: The abstract states that 'CoVER-7B substantially outperforms models with the same parameter scale and even surpasses state-of-the-art closed-source models on certain metrics' but supplies no methods, datasets, baselines, evaluation protocols, error bars, or experimental design details. This prevents any assessment of the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'CoVER-7B substantially outperforms models with the same parameter scale and even surpasses state-of-the-art closed-source models on certain metrics' but supplies no methods, datasets, baselines, evaluation protocols, error bars, or experimental design details. This prevents any assessment of the central empirical claim.
Authors: Abstracts are designed to be concise high-level summaries and are not the appropriate venue for full experimental protocols, which would violate length constraints. The manuscript provides complete details on the CoVER framework in Section 3, datasets and evaluation protocols (including metrics and baselines) in Section 4, and all quantitative results with comparisons to same-scale open models and closed-source SOTA in Section 4.2 and the associated tables. These sections enable full assessment of the empirical claims. revision: no
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or load-bearing self-citations. CoVER is introduced as a proposed framework with two high-level mechanisms (query expansion for evidence and answer-clue reflection), but these are presented as design choices rather than results derived from prior fitted quantities or self-referential definitions. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear. The central claims concern empirical outperformance on benchmarks, which are independent of any internal reduction to inputs. This is the expected outcome for a methods paper whose validation rests on external experiments rather than algebraic self-consistency.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[9]
Science China Information Sciences , volume=
Videochat: Chat-centric video understanding , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[10]
5-VL Technical Report , author=
Qwen2. 5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[11]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[13]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Video-chatgpt: Towards detailed video understanding via large vision and language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Adaptive keyframe sampling for long video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dynamic-vlm: Simple dynamic visual token compression for videollm , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Tspo: Temporal sampling policy optimization for long-form video language understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
arXiv preprint arXiv:2603.04977 , year=
Think, Then Verify: A Hypothesis-Verification Multi-Agent Framework for Long Video Understanding , author=. arXiv preprint arXiv:2603.04977 , year=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Towards better chain-of-thought: A reflection on effectiveness and faithfulness , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[20]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[21]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Vitcot: Video-text interleaved chain-of-thought for boosting video understanding in large language models , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[22]
Jiang, Chaoya and Heng, Yongrui and Ye, Wei and Yang, Han and Xu, Haiyang and Yan, Ming and Zhang, Ji and Huang, Fei and Zhang, Shikun , journal=. VLM-R ^
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Look again, think slowly: Enhancing visual reflection in vision-language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[24]
arXiv preprint arXiv:2508.04416 , year=
Thinking with videos: Multimodal tool-augmented reinforcement learning for long video reasoning , author=. arXiv preprint arXiv:2508.04416 , year=
-
[25]
arXiv preprint arXiv:2509.24786 , year=
Love-r1: Advancing long video understanding with an adaptive zoom-in mechanism via multi-step reasoning , author=. arXiv preprint arXiv:2509.24786 , year=
-
[26]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[27]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[28]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2511.23478 , year=
Video-R2: Reinforcing Consistent and Grounded Reasoning in Multimodal Language Models , author=. arXiv preprint arXiv:2511.23478 , year=
-
[30]
Video-Thinker: Sparking" Thinking with Videos" via Reinforcement Learning , author=. arXiv preprint arXiv:2510.23473 , year=
-
[31]
arXiv preprint arXiv:2510.20470 , year=
Conan: Progressive learning to reason like a detective over multi-scale visual evidence , author=. arXiv preprint arXiv:2510.20470 , year=
-
[32]
European Conference on Computer Vision , pages=
Llama-vid: An image is worth 2 tokens in large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[33]
Advances in Neural Information Processing Systems , volume=
Sharegpt4video: Improving video understanding and generation with better captions , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
LLaVA-NeXT: A Strong Zero-shot Video Understanding Model , url=
Zhang, Yuanhan and Li, Bo and Liu, haotian and Lee, Yong jae and Gui, Liangke and Fu, Di and Feng, Jiashi and Liu, Ziwei and Li, Chunyuan , month=. LLaVA-NeXT: A Strong Zero-shot Video Understanding Model , url=
-
[35]
arXiv preprint arXiv:2406.07476 , year=
Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms , author=. arXiv preprint arXiv:2406.07476 , year=
-
[36]
arXiv preprint arXiv:2406.16852 , year=
Long context transfer from language to vision , author=. arXiv preprint arXiv:2406.16852 , year=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mvbench: A comprehensive multi-modal video understanding benchmark , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Vamba: Understanding hour-long videos with hybrid mamba-transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[39]
International Conference on Learning Representations , volume=
Timesuite: Improving mllms for long video understanding via grounded tuning , author=. International Conference on Learning Representations , volume=
-
[40]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-xl: Extra-long vision language model for hour-scale video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[41]
arXiv preprint arXiv:2503.18478 , year=
Video-xl-pro: Reconstructive token compression for extremely long video understanding , author=. arXiv preprint arXiv:2503.18478 , year=
-
[42]
International Conference on Learning Representations , volume=
Longvila: Scaling long-context visual language models for long videos , author=. International Conference on Learning Representations , volume=
-
[43]
arXiv preprint arXiv:2410.17434 , year=
Longvu: Spatiotemporal adaptive compression for long video-language understanding , author=. arXiv preprint arXiv:2410.17434 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Unleashing hour-scale video training for long video-language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
arXiv preprint arXiv:2502.05177 , year=
Long-vita: Scaling large multi-modal models to 1 million tokens with leading short-context accuracy , author=. arXiv preprint arXiv:2502.05177 , year=
-
[46]
arXiv preprint arXiv:2504.02438 , year=
Scaling video-language models to 10k frames via hierarchical differential distillation , author=. arXiv preprint arXiv:2504.02438 , year=
-
[47]
arXiv preprint arXiv:2501.00574 , year=
Videochat-flash: Hierarchical compression for long-context video modeling , author=. arXiv preprint arXiv:2501.00574 , year=
-
[48]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
VideoMind: Thinking in Steps for Long Video Understanding , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
-
[49]
Advances in Neural Information Processing Systems , volume=
Video-rag: Visually-aligned retrieval-augmented long video comprehension , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
arXiv preprint arXiv:2508.20478 , year=
Video-mtr: Reinforced multi-turn reasoning for long video understanding , author=. arXiv preprint arXiv:2508.20478 , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Video-r1: Reinforcing video reasoning in mllms , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Advances in Neural Information Processing Systems , volume=
Scaling rl to long videos , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
Advances in Neural Information Processing Systems , volume=
Longvideobench: A benchmark for long-context interleaved video-language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Lvbench: An extreme long video understanding benchmark , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
Essai philosophique sur les probabilit
marquis de Laplace, Pierre Simon , year=. Essai philosophique sur les probabilit
-
[59]
arXiv preprint arXiv:2511.13026 , year=
Revisor: Beyond textual reflection, towards multimodal introspective reasoning in long-form video understanding , author=. arXiv preprint arXiv:2511.13026 , year=
-
[60]
arXiv preprint arXiv:2604.14692 , year=
Chain-of-Glimpse: Search-Guided Progressive Object-Grounded Reasoning for Video Understanding , author=. arXiv preprint arXiv:2604.14692 , year=
-
[61]
arXiv preprint arXiv:2510.20622 , year=
SeViCES: Unifying Semantic-Visual Evidence Consensus for Long Video Understanding , author=. arXiv preprint arXiv:2510.20622 , year=
-
[62]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Seeing Is Believing: Grounding Long-Video Understanding in Spatio-Temporal Visual Evidence , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[63]
arXiv preprint arXiv:2604.24339 , year=
See Further, Think Deeper: Advancing VLM's Reasoning Ability with Low-level Visual Cues and Reflection , author=. arXiv preprint arXiv:2604.24339 , year=
-
[64]
arXiv preprint arXiv:2410.02713 , year=
Llava-video: Video instruction tuning with synthetic data , author=. arXiv preprint arXiv:2410.02713 , year=
-
[65]
arXiv preprint arXiv:2505.02835 , year=
R1-reward: Training multimodal reward model through stable reinforcement learning , author=. arXiv preprint arXiv:2505.02835 , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception , author=
Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Longvt: Incentivizing" thinking with long videos" via native tool calling , author=. arXiv preprint arXiv:2511.20785 , year=
-
[69]
arXiv preprint arXiv:2604.01569 , year=
VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification , author=. arXiv preprint arXiv:2604.01569 , year=
-
[70]
arXiv preprint arXiv:2510.10518 , year=
Vr-thinker: Boosting video reward models through thinking-with-image reasoning , author=. arXiv preprint arXiv:2510.10518 , year=
-
[71]
VideoMind: A Chain-of-LoRA Agent for Temporal-Grounded Video Reasoning , author=
-
[72]
arXiv preprint arXiv:2512.20618 , year=
LongVideoAgent: Multi-Agent Reasoning with Long Videos , author=. arXiv preprint arXiv:2512.20618 , year=
-
[73]
arXiv preprint arXiv:2603.22285 , year=
VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding , author=. arXiv preprint arXiv:2603.22285 , year=
-
[74]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.