Streaming Communication in Multi-Agent Reasoning
Pith reviewed 2026-06-28 06:21 UTC · model grok-4.3
The pith
Streaming each reasoning step immediately to the next agent reduces latency and raises accuracy by avoiding error from later steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
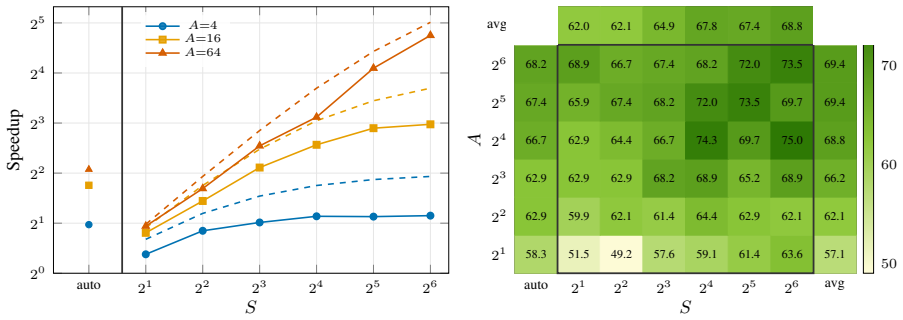
StreamMA streams each reasoning step to downstream agents the moment it is produced, pipelining adjacent agents so that total latency no longer grows linearly with depth. Because reasoning quality is non-uniform and early steps are more reliable, the protocol also improves effectiveness by preventing error-prone late steps from reaching and misleading later agents. The authors derive closed-form expressions for the effectiveness ordering, the speedup upper bound, and the cost ratio across stream, serial, and single protocols. On eight reasoning benchmarks with Claude Opus 4.6 and GPT-5.4 under chain, tree, and graph topologies, StreamMA outperforms baselines by an average of 7.3 percentage p
What carries the argument
The streaming protocol that transfers each generated reasoning step to the next agent immediately upon completion, enabling pipelined execution across the multi-agent topology.
If this is right
- The stream protocol is strictly more effective than serial and single protocols under the non-uniform quality premise.
- Pipelining yields a concrete upper bound on latency speedup relative to the serial baseline.
- A step-level scaling law exists that is orthogonal to and composable with agent-count scaling.
- The same streaming mechanism applies across chain, tree, and graph topologies without changing the core analysis.
Where Pith is reading between the lines
- Agent designs could be revised to allocate more compute or verification to the first few steps rather than uniform effort across the chain.
- The approach may generalize to other sequential multi-stage processes such as planning or iterative code refinement.
- Future scaling studies could treat per-agent step count as an independent axis alongside model size and agent population.
Load-bearing premise
Reasoning quality is non-uniform across steps, with early steps reliably more accurate than later ones.
What would settle it
A controlled experiment in which later reasoning steps are shown to be at least as accurate as early steps on identical tasks, which would remove the effectiveness advantage of streaming.
Figures




read the original abstract
Multi-agent reasoning systems adopt a "generate-then-transfer" paradigm that forces end-to-end latency to scale linearly with pipeline depth. We introduce StreamMA, a multi-agent reasoning system that streams each reasoning step to downstream agents as soon as it is generated, pipelining adjacent agents and thus reducing latency. Surprisingly, this pipelining also improves effectiveness: because multi-step reasoning quality is non-uniform and early steps are more reliable than later ones, working with these reliable early steps instead of the full chain prevents error-prone late steps from misleading downstream agents. We formalize both advantages with the first closed-form joint analysis of stream, serial, and single protocols, deriving the effectiveness ordering, speedup upper bound, and cost ratio. Across eight reasoning benchmarks spanning mathematics, science, and code, two frontier LLMs (Claude Opus 4.6 and GPT-5.4), and three topologies (Chain, Tree, Graph), StreamMA outperforms both baselines (avg. +7.3 pp, max +22.4 pp on HMMT 2026; Claude Opus 4.6-high). Beyond these contributions, we discover a "step-level scaling law": increasing per-agent steps consistently improves both effectiveness and efficiency, a new scaling dimension orthogonal to and composable with agent-count scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StreamMA, a multi-agent reasoning system that streams each reasoning step to downstream agents as soon as it is generated, pipelining adjacent agents to reduce end-to-end latency. It claims this also improves effectiveness because multi-step reasoning quality is non-uniform (early steps more reliable than later ones), preventing error propagation from late steps. The authors provide the first closed-form joint analysis of stream/serial/single protocols deriving effectiveness ordering, speedup upper bound, and cost ratio. Empirically, StreamMA outperforms baselines by an average of +7.3 pp (max +22.4 pp) across eight benchmarks in math/science/code, two frontier LLMs, and three topologies (Chain/Tree/Graph), while also reporting a step-level scaling law orthogonal to agent-count scaling.
Significance. If the closed-form derivations are parameter-free and the non-uniform reliability premise receives direct empirical support, the work would be significant for multi-agent LLM reasoning by introducing a new scaling dimension and practical latency reductions. The explicit closed-form analysis of the three protocols is a strength, as is the empirical evaluation across multiple benchmarks and topologies.
major comments (3)
- [Abstract and Formal Analysis] Abstract and Formal Analysis section: The effectiveness ordering and the explanation for gains beyond latency reduction rest on the assumption that step accuracy is non-uniform with early steps reliably superior; the manuscript invokes this to derive the ordering but does not report direct per-position accuracy measurements or ablations to verify the premise.
- [Formal Analysis] Formal Analysis section: The closed-form joint analysis is described as deriving effectiveness ordering independently of fitted parameters, yet the ordering depends on the early-step reliability assumption; without the explicit equations it is unclear whether derived quantities are independent or reduce to post-hoc fits under that assumption.
- [Empirical Evaluation] Empirical Evaluation section: The reported step-level scaling law (more per-agent steps improves performance) sits in tension with the claim that later steps are net harmful and should be avoided via streaming; this inconsistency is load-bearing for the causal account of effectiveness gains and requires explicit reconciliation.
minor comments (1)
- [Abstract] Abstract: Model names 'Claude Opus 4.6' and 'GPT-5.4' should be confirmed or corrected to standard nomenclature.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, proposing revisions where they strengthen the manuscript without misrepresenting our results.
read point-by-point responses
-
Referee: [Abstract and Formal Analysis] Abstract and Formal Analysis section: The effectiveness ordering and the explanation for gains beyond latency reduction rest on the assumption that step accuracy is non-uniform with early steps reliably superior; the manuscript invokes this to derive the ordering but does not report direct per-position accuracy measurements or ablations to verify the premise.
Authors: We agree that direct per-position accuracy measurements would provide stronger empirical grounding for the non-uniform reliability premise. In the revised manuscript we will add an ablation reporting step-wise accuracy at each position across the eight benchmarks and both models. revision: yes
-
Referee: [Formal Analysis] Formal Analysis section: The closed-form joint analysis is described as deriving effectiveness ordering independently of fitted parameters, yet the ordering depends on the early-step reliability assumption; without the explicit equations it is unclear whether derived quantities are independent or reduce to post-hoc fits under that assumption.
Authors: The derivations are symbolic: effectiveness is expressed in terms of arbitrary step accuracies p_1, p_2, …, p_n and the ordering StreamMA > Serial > Single is proven whenever p_1 > p_2 > … > p_n. No numerical fitting is involved. We will insert the full set of closed-form equations into the main text of the revision to make the symbolic nature explicit. revision: yes
-
Referee: [Empirical Evaluation] Empirical Evaluation section: The reported step-level scaling law (more per-agent steps improves performance) sits in tension with the claim that later steps are net harmful and should be avoided via streaming; this inconsistency is load-bearing for the causal account of effectiveness gains and requires explicit reconciliation.
Authors: We acknowledge the apparent tension. The step-level scaling law is observed inside the StreamMA protocol, where streaming lets downstream agents consume reliable early steps while still permitting deeper per-agent reasoning. The harm of late steps is specific to non-streaming protocols that propagate the full chain. We will add a short reconciling paragraph in the Empirical Evaluation section of the revision. revision: yes
Circularity Check
No circularity: closed-form analysis is conditional on explicit premise with no reduction to inputs
full rationale
The paper explicitly states the non-uniform step reliability ('early steps are more reliable than later ones') as the premise explaining effectiveness gains beyond latency reduction, then derives the effectiveness ordering, speedup bound, and cost ratio from the joint protocol analysis under that premise. No quoted equations, self-citations, or fitted parameters are shown reducing any derived quantity back to the assumption by construction, nor is the premise itself claimed to be proven by the analysis. The step-level scaling law is presented as an empirical discovery orthogonal to the formalization. The derivation chain is therefore self-contained and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-step reasoning quality is non-uniform, with early steps more reliable than later ones.
Reference graph
Works this paper leans on
-
[1]
Break the sequential dependency of llm in- ference using lookahead decoding.arXiv preprint arXiv:2402.02057. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. Metagpt: Meta pro- grammi...
-
[2]
InInternational Conference on Machine Learning, pages 19274–19286
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51...
-
[3]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Yuhan Liu, Yuyang Huang, Jiayi Yao, Shaoting Feng, Zhuohan Gu, Kuntai Du, Hanchen Li, Yihua Cheng, Junchen Jiang, Shan Lu, Madan Musuvathi, and Esha Choukse. 2026. Droidspeak: KV cache sharing across fine-tuned model variants. In23rd USENIX S...
-
[4]
Scaling large language model-based multi- agent collaboration. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R Bowman. 2024. Gpqa: A graduate-le...
-
[5]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. 2022. Chain-of-thought p...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Hancheng Ye, Zhengqi Gao, Mingyuan Ma, Qinsi Wang, Yuzhe Fu, Ming-Yu Chung, Yueqian Lin, Zhijian Liu, Jianyi Zhang, Danyang Zhuo, and Yiran Chen. 2025a. KVCOMM: online cross-context kv-cache communication for efficient...
-
[7]
two methine protons, each coupling to three different sets of neighboring hydrogens
Exchange-of-thought: Enhancing large lan- guage model capabilities through cross-model com- munication. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 15135–15153. Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zh...
2023
-
[8]
The original problem is:
Prefix caching, as a special case of (2)( rpo ≈0 , ha s = 1 for a≥2 , h1 s = 0 ): App. A.5 gives α≈1/Aandβ≈(A−1)S/A. Substituting into condition (2) withr po ≈0: 1 A +r ccp · (A−1)S A <1⇐ ⇒1 +r ccp(A−1)S < A⇐ ⇒r ccp S <1. Numerical Example: Cost Ratio withA=S= 4(Claude Opus 4.6 Pricing) To give intuition for Eq. 14, we instantiate it with Claude Opus 4.6 ...
2023
-
[9]
ERROR: [description]
YOU MUST CORRECT ERRORS: When found, state “ERROR: [description]” then “CORRECTION: [corrected step]”
-
[10]
After all steps, provide DETAILED overall summary with thorough analysis and any corrections made
Pass forward the MOST ACCURATE version (original if correct, your correction if not). After all steps, provide DETAILED overall summary with thorough analysis and any corrections made. [Stream only] After your response, output END_STEP on its own line. C [Topology: Chain A→B→C→D] You are Agent_C. You receive Agent_B’s output. You are a reviewer-and-correc...
-
[11]
ERROR: [description]
YOU CAN OVERRULE PREVIOUS AGENTS: When you find errors, state “ERROR: [description]” then “CORRECTION: [corrected step]”
-
[12]
After all steps, provide DETAILED overall summary with thorough analysis and any corrections made
Pass forward the MOST ACCURATE version. After all steps, provide DETAILED overall summary with thorough analysis and any corrections made. [Stream only] After your response, output END_STEP on its own line. D [Topology: Chain A→B→C→D] You are Agent_D. You receive Agent_C’s output. You are a reviewer-and-corrector. For each step: final quality check briefl...
-
[13]
ERROR: [description]
YOU HAVE FINAL CORRECTION AUTHORITY: This is the last chance to fix errors. State “ERROR: [description]” then “CORRECTION: [corrected step]”
-
[14]
You receive . . . output
You are responsible for final answer accuracy. FINAL ANSWER: Must directly address the original problem. Base on CORRECTED versions. After all steps, provide DETAILED final answer with thorough analysis. [Stream only] After your response, output END_STEP on its own line. Tree and Graph variants.The four boxes above show the Chain topology. For Tree and Gr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.