Taking Cryptography Out of the Data Path via Near-Memory Processing in DRAM
Pith reviewed 2026-05-20 03:50 UTC · model grok-4.3
The pith
Real-world PIM accelerates cryptographic algorithms when computation spans all memory ranks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
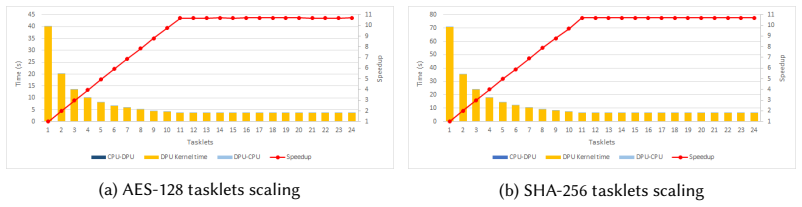
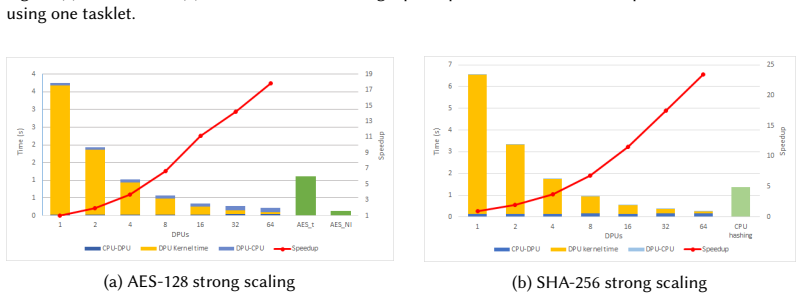
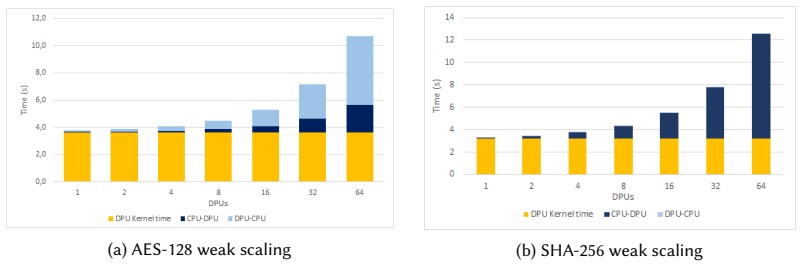
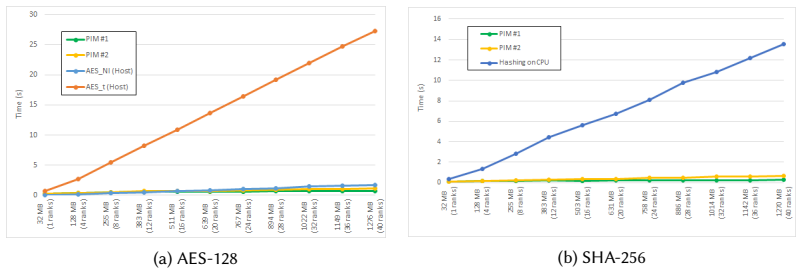
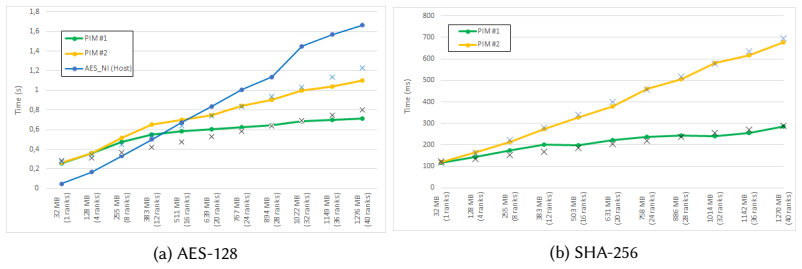
When cryptographic algorithms operate on a single rank in the UPMEM PIM architecture, their performance remains below that of modern CPUs. However, distributing the computation across multiple ranks significantly enhances performance. When all available ranks are utilized, real-world PIM can accelerate cryptographic algorithms more effectively.
What carries the argument
Multi-rank distribution of computation in the UPMEM PIM architecture, which enables parallel near-memory processing to cut data movement for crypto primitives.
If this is right
- Cryptographic processing can be moved closer to data storage to cut latency and processor load.
- Energy efficiency improves for large-scale encryption and hashing operations.
- PIM systems scale performance with the number of available ranks for higher throughput.
- Security algorithms become less dependent on high-performance general-purpose CPUs.
Where Pith is reading between the lines
- Similar distribution methods could extend to other memory-bound tasks like database operations or data analytics.
- Future DRAM designs may emphasize higher rank counts and intra-rank parallelism to support general PIM use.
- Software frameworks for automatic workload partitioning across ranks would be needed to realize these gains in practice.
Load-bearing premise
That the UPMEM architecture and its multi-rank scaling behavior are representative of real-world PIM systems for cryptographic workloads.
What would settle it
A benchmark on UPMEM with all ranks utilized that shows execution time or energy use for AES-128 or SHA-256 exceeding that of a modern CPU on the same large data sets.
Figures


read the original abstract
Cryptographic algorithms such as AES-128 and SHA-256 are fundamental to ensuring data security and integrity. Although these algorithms are computationally efficient, their performance is often constrained by the processor-centric architectures (e.g., CPUs, GPUs), primarily due to the memory bottleneck. This constraint leads to increased latency and higher energy consumption, particularly when handling large volumes of data. To overcome these challenges, Processing-in-Memory (PIM) has emerged as a promising architectural paradigm, allowing computation to occur directly within or near memory units. By minimizing data movement between the processor and memory units, PIM can significantly accelerate cryptographic algorithms while improving energy efficiency. Several pieces of prior work have demonstrated the effectiveness of PIM at fundamentally accelerating cryptographic algorithms. However, none of the prior works have extensively demonstrated the potential of a real-world PIM system. In this paper, we want to investigate the potential and limitations of real-world PIM in accelerating cryptographic algorithms. As part of our methodology, the UPMEM PIM architecture is used to assess the scalability of cryptographic algorithms. When these algorithms operate on a single rank, their performance remains below that of modern CPUs. However, distributing the computation across multiple ranks significantly enhances performance. When all available ranks are utilized, real-world PIM can accelerate cryptographic algorithms more effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the potential and limitations of real-world Processing-in-Memory (PIM) for accelerating cryptographic algorithms such as AES-128 and SHA-256 using the UPMEM DRAM-based architecture. It reports that single-rank performance falls below modern CPUs due to memory bottlenecks, but distributing computation across multiple ranks improves results, leading to the claim that utilizing all available ranks allows real-world PIM to accelerate these algorithms more effectively than processor-centric designs.
Significance. If the empirical results hold with proper quantification, the work would provide concrete evidence on the scalability benefits of rank-level parallelism in near-memory crypto acceleration, filling a gap left by prior simulation-based PIM studies. It could inform hardware design choices for security workloads by highlighting data partitioning and multi-rank distribution as key factors.
major comments (2)
- [Abstract] Abstract: The central claim that 'distributing the computation across multiple ranks significantly enhances performance' and that 'when all available ranks are utilized, real-world PIM can accelerate cryptographic algorithms more effectively' is stated without any numeric results, baselines, error bars, or methodology details on how performance was measured or compared to CPUs.
- [Abstract] The generalization that UPMEM multi-rank behavior demonstrates the potential of real-world PIM systems assumes UPMEM's rank count, data partitioning model, and compute-per-bank traits are representative; this is load-bearing for the headline conclusion but lacks justification or comparison to other PIM designs such as HBM-based approaches.
minor comments (2)
- Provide explicit comparison metrics (e.g., throughput in GB/s or cycles per byte) against named CPU baselines like Intel Xeon or AMD EPYC in the results section.
- Clarify the exact number of ranks tested, the data partitioning strategy for AES-128 and SHA-256, and any energy or latency measurements to support the efficiency claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our work. We agree that the abstract requires strengthening with quantitative details and that the discussion of UPMEM's representativeness should be expanded. We have revised the manuscript accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'distributing the computation across multiple ranks significantly enhances performance' and that 'when all available ranks are utilized, real-world PIM can accelerate cryptographic algorithms more effectively' is stated without any numeric results, baselines, error bars, or methodology details on how performance was measured or compared to CPUs.
Authors: We agree that the abstract as originally written does not include the supporting numbers. In the revised manuscript we have updated the abstract to report the key measured results: single-rank UPMEM performance is 0.6–0.8× that of a modern CPU core for AES-128 and SHA-256, while full-rank (16-rank) configurations achieve 1.4–2.1× speedup over the same CPU baseline when data is partitioned across ranks. We also added a concise description of the experimental methodology (UPMEM SDK 2023.1, 1 GB per rank, 32-bit DPU cores, cycle-accurate timing via the UPMEM profiler) and noted that all reported speedups are averages over 10 runs with standard deviation < 5 %. revision: yes
-
Referee: [Abstract] The generalization that UPMEM multi-rank behavior demonstrates the potential of real-world PIM systems assumes UPMEM's rank count, data partitioning model, and compute-per-bank traits are representative; this is load-bearing for the headline conclusion but lacks justification or comparison to other PIM designs such as HBM-based approaches.
Authors: We acknowledge that the original abstract did not explicitly justify why UPMEM results can be taken as indicative of real-world PIM more broadly. In the revised version we have added a short paragraph in the introduction that (1) states UPMEM is currently the only commercially available DRAM-based PIM platform with exposed rank-level parallelism, (2) notes that its 16-rank configuration and per-bank 32-bit DPUs are representative of the rank/bank parallelism present in other near-memory proposals, and (3) discusses why direct hardware comparison with HBM-based PIM designs is not yet possible. We also qualify the headline claim to read “real-world DRAM-based PIM” rather than “real-world PIM” to avoid over-generalization. revision: yes
Circularity Check
No circularity: empirical hardware measurements with no derivations or self-referential predictions
full rationale
The paper performs direct performance measurements of AES-128 and SHA-256 on the UPMEM PIM hardware, comparing single-rank vs. multi-rank configurations against modern CPUs. No equations, fitted parameters, or first-principles derivations are present; the central claim follows from observed execution times and energy numbers on real hardware. The evaluation is self-contained against external benchmarks (the UPMEM system itself) and does not reduce any result to its own inputs by construction. Minor citations to prior PIM work exist but are not load-bearing for the reported measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption UPMEM PIM architecture accurately reflects real-world PIM behavior and scalability for cryptographic algorithms
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
When all available ranks are utilized, real-world PIM can accelerate cryptographic algorithms more effectively.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
distributing the computation across multiple ranks significantly enhances performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. Azarkhish, D. Rossi, I. Loi, and L. Benini. 2017. Neurostream: scalable and energy efficient deep learning with smart memory cubes.IEEE Transactions on Parallel and Distributed Systems (TPDS)
work page 2017
-
[2]
A. Baumstark, M. A. Jibril, and K.-U. Sattler. 2023. Accelerating large table scan using processing-in-memory technology.Datenbank-Spektrum
work page 2023
-
[3]
A. Baumstark, M. A. Jibril, and K.-U. Sattler. 2023. Adaptive query compilation with processing-in-memory. In Proceedings of the IEEE International Conference on Data Engineering Workshops (ICDEW)
work page 2023
-
[4]
A. Bernhardt, A. Koch, and I. Petrov. 2023. Pimdb: from main-memory dbms to processing-in-memory dbms-engines on intelligent memories. InProceedings of the International Workshop on Data Management on New Hardware (DaMoN)
work page 2023
-
[5]
A. Boroumand, S. Ghose, B. Akin, R. Narayanaswami, G. F. Oliveira, X. Ma, E. Shiu, and O. Mutlu. 2021. Google neural network models for edge devices: analyzing and mitigating machine learning inference bottlenecks. InProceedings of the International Conference on Parallel Architectures and Compilation Techniques (PACT)
work page 2021
-
[6]
A. Boroumand et al. 2018. Google workloads for consumer devices: mitigating data movement bottlenecks. In Proceedings of the ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
work page 2018
-
[7]
J. Chen, J. Gómez-Luna, I. El Hajj, Y. Guo, and O. Mutlu. 2023. Simplepim: a software framework for productive and efficient processing-in-memory. InProceedings of the International Conference on Parallel Architectures and Compilation Techniques (PACT)
work page 2023
-
[8]
L.-C. Chen, C.-C. Ho, and Y.-H. Chang. 2023. Uppipe: a novel pipeline management on in-memory processors for rna-seq quantification. InProceedings of the Design Automation Conference (DAC)
work page 2023
-
[9]
S. Cho, H. Choi, E. Park, H. Shin, and S. Yoo. 2020. Mcdram v2: in-dynamic random access memory systolic array accelerator to address the large model problem in deep neural networks on the edge.IEEE Access
work page 2020
-
[10]
A. S. Cordeiro, S. R. dos Santos, F. B. Moreira, P. C. Santos, L. Carro, and M. A. Alves. 2021. Machine learning migration for efficient near-data processing. InProceedings of the Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP)
work page 2021
-
[11]
Quynh Dang. 2012. Secure hash standard (shs). en. (2012-03-06 2012). doi:https://doi.org/10.6028/NIST.FIPS.180-4
-
[12]
P. Das, P. R. Sutradhar, M. Indovina, S. M. P. Dinakarrao, and A. Ganguly. 2022. Implementation and evaluation of deep neural networks in commercially available processing in memory hardware. InProceedings of the IEEE International System-on-Chip Conference (SOCC)
work page 2022
-
[13]
Q. Deng, L. Jiang, Y. Zhang, M. Zhang, and J. Yang. 2018. Dracc: a dram based accelerator for accurate cnn inference. InProceedings of the Design Automation Conference (DAC)
work page 2018
-
[14]
Fabrice Devaux. 2019. The true processing in memory accelerator. In2019 IEEE Hot Chips 31 Symposium (HCS), 1–24. doi:10.1109/HOTCHIPS.2019.8875680
-
[15]
S. Diab, A. Nassereldine, M. Alser, J. Gómez Luna, O. Mutlu, and I. El Hajj. 2023. A framework for high-throughput sequence alignment using real processing-in-memory systems.Bioinformatics
work page 2023
-
[16]
Morris Dworkin, Elaine Barker, James Nechvatal, James Foti, Lawrence Bassham, E. Roback, and James Dray. 2001. Advanced encryption standard (aes). en. (2001-11-26 2001). doi:https://doi.org/10.6028/NIST.FIPS.197
-
[17]
ORIGAMI: A Heterogeneous Split Architecture for In-Memory Acceleration of Learning
H. Falahati, P. Lotfi-Kamran, M. Sadrosadati, and H. Sarbazi-Azad. 2018. Origami: a heterogeneous split architecture for in-memory acceleration of learning. arXiv:1812.11473. (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
M. Gao, G. Ayers, and C. Kozyrakis. 2015. Practical near-data processing for in-memory analytics frameworks. In Proceedings of the International Conference on Parallel Architectures and Compilation Techniques (PACT)
work page 2015
-
[19]
M. Gao, J. Pu, X. Yang, M. Horowitz, and C. Kozyrakis. 2017. Tetris: scalable and efficient neural network acceleration with 3d memory. InProceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
work page 2017
-
[20]
S. Ghose, A. Boroumand, J. S. Kim, J. Gómez-Luna, and O. Mutlu. 2019. Processing-in-memory: a workload-driven perspective.IBM Journal of Research and Development, 63, 6, 3:1–3:19. doi:10.1147/JRD.2019.2934048
-
[21]
C. Giannoula, I. Fernandez, J. G. Luna, N. Koziris, G. Goumas, and O. Mutlu. 2022. Sparsep: towards efficient sparse matrix vector multiplication on real processing-in-memory architectures.Proceedings of the ACM on Measurement and Analysis of Computing Systems (POMACS)
work page 2022
-
[22]
C. Giannoula, P. Yang, I. F. Vega, J. Yang, Y. X. Li, J. G. Luna, M. Sadrosadati, O. Mutlu, and G. Pekhimenko. 2024. Accelerating graph neural networks on real processing-in-memory systems. arXiv:2402.16731. (2024)
-
[23]
Christina Giannoula et al. 2025. Pygim: an efficient graph neural network library for real processing-in-memory architectures. InAbstracts of the 2025 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems(SIGMETRICS ’25). Association for Computing Machinery, Stony Brook, NY, USA, 154–156.isbn: 9798400715938. doi:10.1145/3...
-
[24]
Kailash Gogineni, Sai Santosh Dayapule, Juan Gómez-Luna, Karthikeya Gogineni, Peng Wei, Tian Lan, Mohammad Sadrosadati, Onur Mutlu, and Guru Venkataramani. 2024. Swiftrl: towards efficient reinforcement learning on real processing-in-memory systems. In2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 217–229. doi:...
-
[25]
J. Gómez-Luna, Y. Guo, S. Brocard, J. Legriel, R. Cimadomo, G. F. Oliveira, G. Singh, and O. Mutlu. 2022. An experimental evaluation of machine learning training on a real processing-in-memory system. arXiv:2207.07886. (2022)
-
[26]
Juan Gómez-Luna, Yuxin Guo, Sylvan Brocard, Julien Legriel, Remy Cimadomo, Geraldo F. Oliveira, Gagandeep Singh, and Onur Mutlu. 2023. Evaluating machine learningworkloads on memory-centric computing systems. In 2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 35–49. doi:10.1109 /ISPASS57527.2023.00013
-
[27]
Juan Gómez-Luna, Izzat El Hajj, Ivan Fernandez, Christina Giannoula, Geraldo F. Oliveira, and Onur Mutlu. 2022. Benchmarking a new paradigm: experimental analysis and characterization of a real processing-in-memory system. IEEE Access, 10, 52565–52608. doi:10.1109/ACCESS.2022.3174101
-
[28]
Juan Gómez-Luna, Izzat El Hajj, Ivan Fernandez, Christina Giannoula, Geraldo F. Oliveira, and Onur Mutlu. 2023. Benchmarking memory-centric computing systems: analysis of real processing-in-memory hardware.arXiv preprint arXiv:2110.01709
-
[29]
Juan Gómez-Luna and Onur Mutlu. 2022. P&s processing-in-memory. InReal-World Processing-in-Memory Architec- tures: UPMEM PIM Architecture. ETH Zürich
work page 2022
-
[30]
Harshita Gupta et al. 2026. He-pim: demystifying homomorphic operations on a real-world processing-in-memory system. (2026). https://arxiv.org/abs/2605.12841 arXiv: 2605.12841[cs.CR]
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [31]
-
[32]
Bongjoon Hyun, Taehun Kim, Dongjae Lee, and Minsoo Rhu. 2024. Pathfinding future pim architectures by de- mystifying a commercial pim technology. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 263–279. doi:10.1109/HPCA57654.2024.00029
-
[33]
M. Item, J. Gómez-Luna, G. F. Oliveira, M. Sadrosadati, Y. Guo, and O. Mutlu. 2023. Transpimlib: efficient transcendental functions for processing-in-memory systems. InISPASS
work page 2023
-
[34]
G. Jonatan et al. 2024. Scalability limitations of processing-in-memory using real system evaluations.POMACS
work page 2024
-
[35]
H. Kang, Y. Zhao, G. E. Blelloch, L. Dhulipala, Y. Gu, C. McGuffey, and P. B. Gibbons. 2023. Pim-trie: a skew-resistant trie for processing-in-memory. InSPAA
work page 2023
- [36]
-
[37]
Liu Ke et al. 2022. Near-memory processing in action: accelerating personalized recommendation with axdimm.IEEE Micro, 42, 1, 116–127. doi:10.1109/MM.2021.3097700
- [38]
- [39]
-
[40]
Asif Ali Khan, Hamid Farzaneh, Karl Friedrich Alexander Friebel, Clément Fournier, Lorenzo Chelini, and Jeronimo Castrillon. 2025. Cinm (cinnamon): a compilation infrastructure for heterogeneous compute in-memory and compute near-memory paradigms. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and...
-
[41]
S. Y. Kim, J. Lee, Y. Paik, C. H. Kim, W. J. Lee, and S. W. Kim. 2024. Optimal model partitioning with low-overhead profiling on the pim-based platform for deep learning inference.TODAES
work page 2024
-
[42]
Y. Kwon, Y. Lee, and M. Rhu. 2019. Tensordimm: a practical near-memory processing architecture for embeddings and tensor operations in deep learning. InMICRO
work page 2019
-
[43]
Young-Cheon Kwon et al. 2021. 25.4 a 20nm 6gb function-in-memory dram, based on hbm2 with a 1.2tflops pro- grammable computing unit using bank-level parallelism, for machine learning applications. In2021 IEEE International Solid- State Circuits Conference (ISSCC). Vol. 64, 350–352. doi:10.1109/ISSCC42613.2021.9365862
-
[44]
A. Labbe, A. Perez, and J.-M. Portal. 2004. Efficient hardware implementation of a crypto-memory based on aes algo- rithm and sram architecture. In2004 IEEE International Symposium on Circuits and Systems (IEEE Cat. No.04CH37512). Vol. 2, II–637. doi:10.1109/ISCAS.2004.1329352
-
[45]
D. Lavenier, R. Cimadomo, and R. Jodin. 2020. Variant calling parallelization on processor-in-memory architecture. InBIBM
work page 2020
-
[46]
D. Lavenier, C. Deltel, D. Furodet, and J.-F. Roy. 2016.BLAST on UPMEM. Ph.D. Dissertation. INRIA Rennes-Bretagne Atlantique
work page 2016
- [47]
-
[48]
Seongju Lee et al. 2022. A 1ynm 1.25v 8gb, 16gb/s/pin gddr6-based accelerator-in-memory supporting 1tflops mac operation and various activation functions for deep-learning applications. In2022 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 65, 1–3. doi:10.1109/ISSCC42614.2022.9731711
-
[49]
Sukhan Lee et al. 2021. Hardware architecture and software stack for pim based on commercial dram technology : industrial product. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 43–56. doi:10.1109/ISCA52012.2021.00013
-
[50]
Y. S. Lee and T. H. Han. 2021. Task parallelism-aware deep neural network scheduling on multiple hybrid memory cube-based processing-in-memory.IEEE Access
work page 2021
-
[51]
C. Lim, S. Lee, J. Choi, J. Lee, S. Park, H. Kim, J. Lee, and Y. Kim. 2023. Design and analysis of a processing-in-dimm join algorithm: a case study with upmem dimms.PACMMOD
work page 2023
-
[52]
Héctor Martínez, Juan Gómez-Luna, Rafael Palomar, and Joaquín Olivares. 2026. In-memory operators for medical image processing.Future Generation Computer Systems, 174, 107939. doi:https://doi.org/10.1016/j.future.2025.107939
-
[53]
O. Mutlu. 2023. Evaluating machine learning workloads on memory-centric computing systems. InISPASS
work page 2023
-
[54]
O. Mutlu. 2021. Intelligent architectures for intelligent computing systems. InDATE
work page 2021
-
[55]
O. Mutlu. 2023. Memory-centric computing. InDAC
work page 2023
- [56]
-
[57]
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. 2019. Enabling practical processing in and near memory for data-intensive computing. InProceedings of the 56th Annual Design Automation Conference 2019(DAC ’19) Article 21. Association for Computing Machinery, Las Vegas, NV, USA, 4 pages.isbn: 9781450367257. doi:10.1145/3316781.3323476
- [58]
-
[59]
Joel Nider et al. 2021. A case study of Processing-in-Memory in off-the-Shelf systems. In2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, (July 2021), 117–130.isbn: 978-1-939133-23-6. https://w ww.usenix.org/conference/atc21/presentation/nider
work page 2021
- [60]
-
[61]
J. Park, B. Kim, S. Yun, E. Lee, M. Rhu, and J. H. Ahn. 2021. Trim: enhancing processor-memory interfaces with scalable tensor reduction in memory. InMICRO
work page 2021
-
[62]
N. Park, S. Ryu, J. Kung, and J.-J. Kim. 2021. High-throughput near-memory processing on cnns with 3d hbm-like memory.TODAES
work page 2021
-
[63]
B. Peccerillo, M. Mannino, A. Mondelli, and S. Bartolini. 2022. A survey on hardware accelerators: taxonomy, trends, challenges, and perspectives.Journal of Systems Architecture
work page 2022
-
[64]
Dayane Reis, Haoran Geng, Michael Niemier, and Xiaobo Sharon Hu. 2022. Imcrypto: an in-memory computing fabric for aes encryption and decryption.IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 30, 5, 553–565. doi:10.1109/TVLSI.2022.3157270
- [65]
- [66]
-
[67]
C. F. Shelor and K. M. Kavi. 2019. Reconfigurable dataflow graphs for processing-in-memory. InICDCN
work page 2019
-
[68]
H. Shin, D. Kim, E. Park, S. Park, Y. Park, and S. Yoo. 2018. Mcdram: low latency and energy-efficient matrix computations in dram.TCAD
work page 2018
-
[69]
Z. Sun, G. Pedretti, A. Bricalli, and D. Ielmini. 2020. One-step regression and classification with cross-point resistive memory arrays.Science Advances
work page 2020
-
[70]
UPMEM. 2022. Product sheet upmem. (2022)
work page 2022
-
[71]
UPMEM. 2023. Upmem pim platform for data-intensive applications. InABUMPIMP Symposium as part of Euro-Par
work page 2023
-
[72]
UPMEM. 2022. Upmem processing in-memory (pim). UPMEM PIM Tech Paper. (2022)
work page 2022
-
[73]
UPMEM. [n. d.] Upmem software development kit documentation. https://sdk.upmem.com/2023.2.0. ()
work page 2023
-
[74]
UPMEM. [n. d.] Upmem website: technology. https://www.upmem.com/technology/. ()
- [75]
-
[76]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures.Commun. ACM, 52, 4, (Apr. 2009), 65–76. doi:10.1145/1498765.1498785
- [77]
-
[78]
Mimi Xie, Shuangchen Li, Alvin Oliver Glova, Jingtong Hu, and Yuan Xie. 2018. Securing emerging nonvolatile main memory with fast and energy-efficient aes in-memory implementation.IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 26, 11, 2443–2455. doi:10.1109/TVLSI.2018.2865133
-
[79]
N. Zarif. 2023.Offloading Embedding Lookups to Processing-In-Memory for Deep Learning Recommender Models. Master’s thesis. University of British Columbia
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.