HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
Pith reviewed 2026-06-30 00:59 UTC · model grok-4.3
The pith
Entity-level hand-object interaction representations enable zero-shot robot policies from minutes of human egocentric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
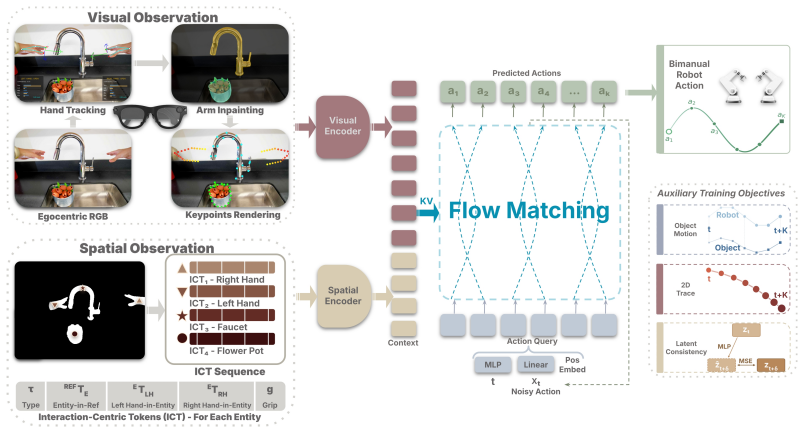
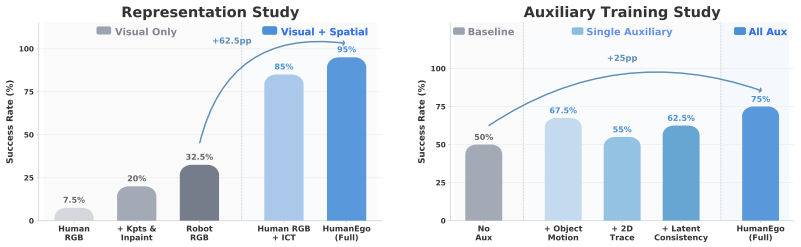
HumanEgo bridges the embodiment gap by lifting each human demonstration to an entity-level representation of hand-object interaction, then trains a flow matching policy with dense auxiliary objectives that amplify supervision from every trajectory, producing robot-data-free policies that achieve high success and zero-shot transfer.
What carries the argument
Entity-level representation of hand-object interaction paired with a flow matching policy trained under dense auxiliary objectives.
If this is right
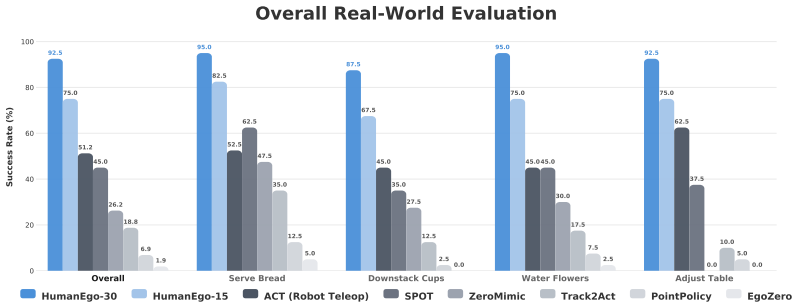
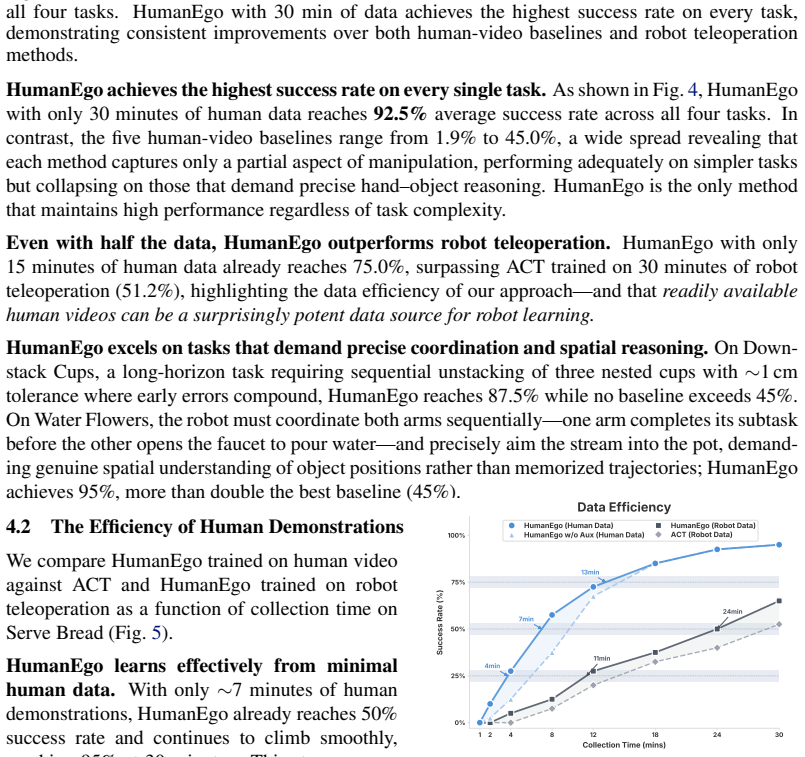
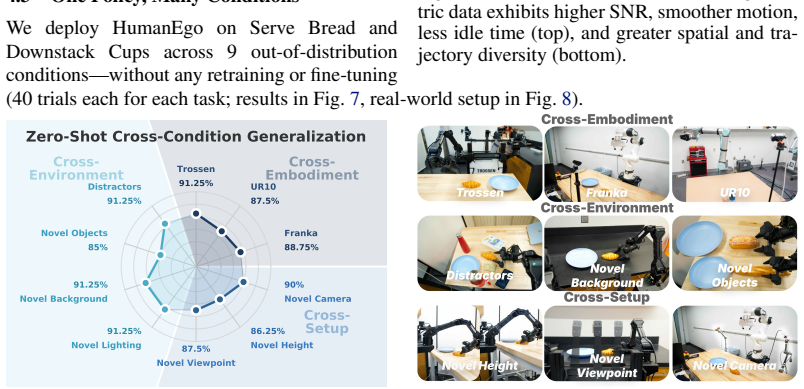
- Thirty minutes of human video per task produces 92.5 percent average success across four real-world manipulation tasks.
- Fifteen minutes of video still reaches 75 percent success.
- Policies outperform those trained from matched-time robot teleoperation data by 41 percent.
- The same policies transfer zero-shot to novel robots, cameras, and environments without retraining.
Where Pith is reading between the lines
- The method could eliminate most robot-specific data collection steps for routine manipulation skills.
- Extending the entity representation to track additional scene elements might support tasks that involve tools or sequential dependencies.
- Applying the same lifting step to longer video sequences could test whether the current supervision density scales to multi-step behaviors.
Load-bearing premise
Converting human demonstrations into an entity-level representation of hand-object interaction is sufficient to bridge both the visual appearance gap and the kinematic differences between human and robot bodies.
What would settle it
A test showing that policies trained via the entity-level representation produce success rates below 50 percent on a robot whose arm length and joint configuration differ substantially from the human demonstrator would falsify the bridging claim.
Figures







read the original abstract
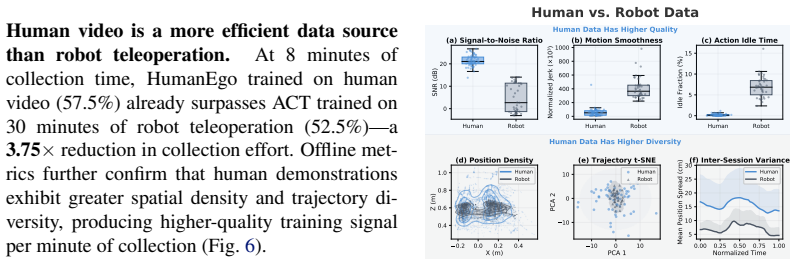
Human egocentric video captures rich manipulation demonstrations without any robot hardware, yet transferring these skills to robots remains challenging due to the embodiment gap between human and robot in both visual appearance and kinematics. We present HumanEgo, a framework that bridges the embodiment gap by lifting each human demonstration to an entity-level representation of hand-object interaction, and training a flow matching policy with dense auxiliary objectives that amplify supervision from every trajectory. HumanEgo is robot-data-free, hardware-agnostic, data-efficient, and zero-shot human-to-robot transferable. With only 30 minutes of human videos per task, HumanEgo achieves 92.5% average success across four real-world tasks (75% with just 15 minutes), outperforms matched-time robot teleoperation by 41%, and robustly transfers zero-shot across novel robots, cameras, and environments. We release HumanEgo as an easy-to-use, open-source framework for learning robot policies directly from human data: https://github.com/TX-Leo/HumanEgo
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HumanEgo, a robot-data-free framework that lifts human egocentric videos to an entity-level hand-object interaction representation and trains a flow-matching policy augmented with dense auxiliary losses. It claims that 30 minutes of human video per task yields 92.5% average success across four real-world manipulation tasks (75% with 15 minutes), outperforms matched-time teleoperation by 41%, and enables zero-shot transfer across novel robots, cameras, and environments.
Significance. If the central results hold under rigorous verification, the work would be significant for data-efficient, hardware-agnostic robot learning by demonstrating that abundant human video can substitute for robot demonstrations. The release of an open-source framework is a concrete strength that supports reproducibility.
major comments (2)
- [Method (entity-level representation and policy training)] The load-bearing step is the assertion that an entity-level hand-object representation plus flow-matching policy is sufficient to bridge the kinematic embodiment gap (human hand DOF, workspace, and dynamics versus robot gripper). No derivation, ablation, or analysis is supplied showing how the representation encodes transferable actions rather than human-specific trajectories; without this, the reported 92.5% success and cross-robot zero-shot transfer cannot be substantiated.
- [Experiments and Evaluation] The abstract states quantitative success rates, comparisons to teleoperation, and cross-embodiment transfer but supplies no experimental protocol, baseline implementation details, statistical tests, number of trials, or failure-mode analysis. These omissions make it impossible to verify that the data support the stated claims.
minor comments (2)
- [Method] Notation for the entity-level representation and auxiliary losses should be defined with explicit equations in the method section to allow readers to trace how supervision is amplified from each trajectory.
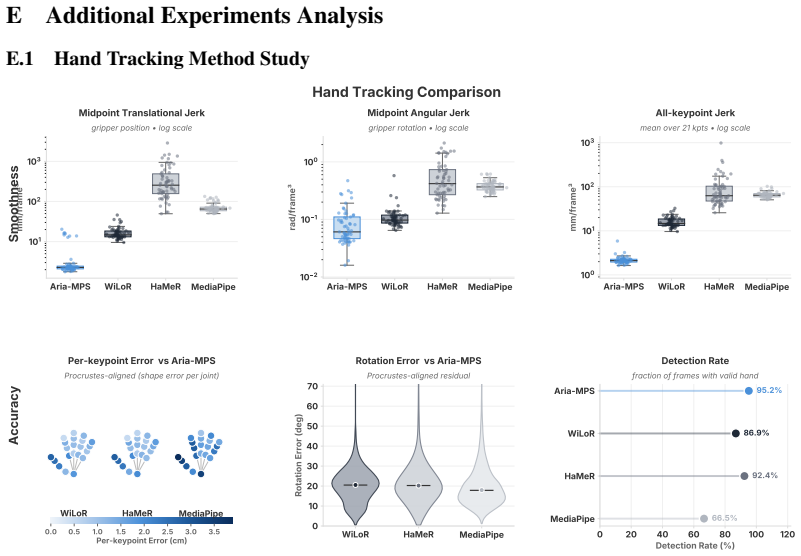
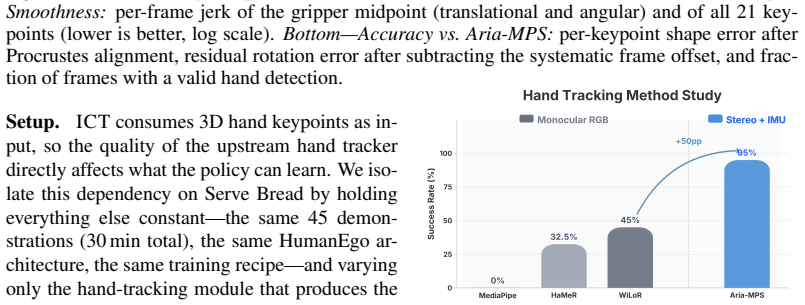
- [Figures] Figure captions for qualitative results should include the exact number of human-video minutes used and the robot platform to facilitate direct comparison with the quantitative tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to provide the requested clarifications and supporting analyses.
read point-by-point responses
-
Referee: [Method (entity-level representation and policy training)] The load-bearing step is the assertion that an entity-level hand-object representation plus flow-matching policy is sufficient to bridge the kinematic embodiment gap (human hand DOF, workspace, and dynamics versus robot gripper). No derivation, ablation, or analysis is supplied showing how the representation encodes transferable actions rather than human-specific trajectories; without this, the reported 92.5% success and cross-robot zero-shot transfer cannot be substantiated.
Authors: We agree that the manuscript would benefit from an explicit analysis of how the entity-level representation supports transfer across kinematic differences. The current text describes the lifting to hand-object entities and the auxiliary losses but does not include a derivation of invariance properties or targeted ablations isolating the representation's contribution to zero-shot transfer. We will add a dedicated subsection with this analysis and new ablations in the revised version. revision: yes
-
Referee: [Experiments and Evaluation] The abstract states quantitative success rates, comparisons to teleoperation, and cross-embodiment transfer but supplies no experimental protocol, baseline implementation details, statistical tests, number of trials, or failure-mode analysis. These omissions make it impossible to verify that the data support the stated claims.
Authors: We acknowledge the need for fuller experimental documentation. While the manuscript reports the success rates and comparisons, it does not detail the full protocol, trial counts, statistical tests, or failure modes. We will expand the experiments section to include these elements, specifying the number of trials, baseline implementations, statistical analysis, and failure categorization. revision: yes
Circularity Check
No circularity: empirical results from human video training
full rationale
The paper describes an empirical framework that lifts egocentric human videos to entity-level hand-object representations and trains a flow-matching policy. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction appear in the abstract or described content. Reported success rates (92.5% with 30 min, zero-shot transfer) are presented as experimental outcomes rather than mathematical derivations. The derivation chain is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
ForceBand: Learning Forceful Manipulation with sEMG
ForceBand uses sEMG and IMU signals to predict fingertip forces from human demos, producing force-augmented data that lets robot policies reach 87% success on pick-squeeze-place tasks across varied objects.
-
LUCID: Learning Embodiment-Agnostic Intent Models from Unstructured Human Videos for Scalable Dexterous Robot Skill Acquisition
LUCID learns embodiment-agnostic intent models from unstructured human videos to train dexterous robot policies in simulation, enabling zero-shot transfer on real-world tasks like stirring and wiping.
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[2]
ALOHA 2 Team, J. Aldaco, T. Armstrong, R. Baruch, J. Bingham, S. Chan, K. Draper, D. Dwibedi, C. Finn, P. Florence, S. Goodrich, W. Gramlich, T. Hage, A. Herzog, J. Hoech, T. Nguyen, I. Storz, B. Tabanpour, L. Takayama, J. Tompson, A. Wahid, T. Wahrburg, S. Xu, S. Yaroshenko, K. Zakka, and T. Z. Zhao. ALOHA 2: An enhanced low-cost hardware for bimanual te...
arXiv 2024
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[4]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=ZMnD6QZAE6
2024
-
[6]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[7]
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredith, C. Peng, C. Sweeney, C. Wilson, D. Barnes, D. DeTone, D. Caruso, D. Valleroy, D. Ginjupalli, D. Frost, E. Miller, E. Mueggler, E. Oleinik, F. Zhang, G. Soma- sundaram, G. Solaira, H. Lanaras, H. Howard-Jenkins, H. Tang, H. J. Kim, J. Rivera, J...
Pith/arXiv arXiv 2023
-
[8]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. EgoMimic: Scaling imitation learning via egocentric video. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[9]
Punamiya, D
R. Punamiya, D. Patel, P. Aphiwetsa, P. Kuppili, L. Y . Zhu, S. Kareer, J. Hoffman, and D. Xu. EgoBridge: Domain adaptation for generalizable imitation from egocentric human data. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[10]
Y . Liu, W. C. Shin, Y . Han, Z. Chen, H. Ravichandar, and D. Xu. ImMimic: Cross-domain imitation from human videos via mapping and interpolation.arXiv preprint arXiv:2509.10952, 2025
arXiv 2025
-
[11]
R.-Z. Qiu, S. Yang, X. Cheng, C. Chawla, J. Li, T. He, G. Yan, D. J. Yoon, R. Hoque, L. Paulsen, G. Yang, J. Zhang, S. Yi, G. Shi, and X. Wang. Humanoid policy ˜ human policy. In 9th Annual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum? id=Tx54fkQ3Cq
2025
-
[12]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, H. Yin, S. Liu, S. Han, Y . Lu, and X. Wang. EgoVLA: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
- [13]
-
[14]
R. Punamiya, S. Kareer, Z. Liu, J. Citron, R.-Z. Qiu, X. Cai, A. Gavryushin, J. Chen, D. Li- conti, L. Y . Zhu, P. Aphiwetsa, B. Li, A. Cheluva, P. Kuppili, Y . Liu, D. Patel, M. Pollefeys, R. Katzschmann, X. Wang, S. Song, J. Hoffman, D. Xu, et al. EgoVerse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07...
Pith/arXiv arXiv 2026
-
[15]
Hoque, P
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. EgoDex: Learning dexter- ous manipulation from large-scale egocentric video. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[16]
Lepert, J
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos. InConference on Robot Learning (CoRL), 2025
2025
-
[17]
M. Lepert, J. Fang, and J. Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025
Pith/arXiv arXiv 2025
-
[18]
E. Dessalene, P. Mantripragada, M. Maynord, and Y . Aloimonos. EmbodiSwap for zero-shot robot imitation learning.arXiv preprint arXiv:2510.03706, 2025
arXiv 2025
-
[19]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[20]
Haldar and L
S. Haldar and L. Pinto. Point policy: Unifying observations and actions with key points for robot manipulation. InConference on Robot Learning (CoRL), 2025. 10
2025
-
[21]
V . Liu, A. Adeniji, H. Zhan, S. Haldar, R. Bhirangi, P. Abbeel, and L. Pinto. EgoZero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
arXiv 2025
-
[22]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. MimicPlay: Long-horizon imitation learning by watching human play. InConference on Robot Learning (CoRL), 2023
2023
-
[23]
G. Li, Y . Lyu, Z. Liu, C. Hou, J. Zhang, and S. Zhang. H2R: A human-to-robot data augmen- tation for robot pre-training from videos.arXiv preprint arXiv:2505.11920, 2025
arXiv 2025
-
[24]
M. Xu, Z. Xu, C. Chi, M. Veloso, and S. Song. XSkill: Cross embodiment skill discovery. In 7th Annual Conference on Robot Learning, 2023. URLhttps://openreview.net/forum? id=8L6pHd9aS6w
2023
-
[25]
M. Xu, Z. Xu, Y . Xu, C. Chi, G. Wetzstein, M. Veloso, and S. Song. Flow as the cross-domain manipulation interface. InConference on Robot Learning (CoRL), 2024
2024
-
[26]
V . Jain, M. Attarian, N. J. Joshi, A. Wahid, D. Driess, Q. Vuong, P. R. Sanketi, P. Sermanet, S. Welker, C. Chan, I. Gilitschenski, Y . Bisk, and D. Dwibedi. Vid2Robot: End-to-end video- conditioned policy learning with cross-attention transformers. InRobotics: Science and Sys- tems (RSS), 2024
2024
-
[27]
C. Wen, X. Lin, J. So, K. Chen, Q. Dou, Y . Gao, and P. Abbeel. Any-point trajectory modeling for policy learning, 2024. URLhttps://arxiv.org/abs/2401.00025
Pith/arXiv arXiv 2024
-
[28]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023
2023
-
[29]
K. Yu, S. Zhang, H. Soora, F. Huang, H. Huang, P. Tokekar, and R. Gao. GenFlowRL: Shaping rewards with generative object-centric flow in visual reinforcement learning.arXiv preprint arXiv:2508.11049, 2025
arXiv 2025
-
[30]
H. Li, L. Sun, Y . Hu, D. Ta, J. Barry, G. Konidaris, and J. Fu. NovaFlow: Zero-shot manipula- tion via actionable flow from generated videos.arXiv preprint arXiv:2510.08568, 2025
arXiv 2025
-
[31]
S. Patel, S. Mohan, H. Mai, U. Jain, S. Lazebnik, and Y . Li. Robotic manipulation by imitating generated videos without physical demonstrations.arXiv preprint arXiv:2507.00990, 2025
Pith/arXiv arXiv 2025
-
[32]
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao. Mimictouch: Leveraging multi- modal human tactile demonstrations for contact-rich manipulation. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=7yMZAUkXa4
2024
-
[33]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[34]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InIEEE/CVF Conference on Computer Vision and Pattern Recog- niti...
2022
-
[35]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, A. Furnari, E. Kazakos, J. Ma, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Rescaling egocentric vision: Collection pipeline and challenges for EPIC-KITCHENS-100.International Journal of Computer Vision (IJCV), 2022
2022
-
[36]
P. Banerjee, S. Shkodrani, P. Moulon, S. Hampali, F. Zhang, J. Fountain, E. Miller, S. Basol, R. Newcombe, R. Wang, J. J. Engel, and T. Hodan. Introducing HOT3D: An egocentric dataset for 3d hand and object tracking.arXiv preprint arXiv:2406.09598, 2024. 11
arXiv 2024
-
[37]
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. HOI4D: A 4d egocentric dataset for category-level human-object interaction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[38]
Y . Liu, H. Yang, X. Si, L. Liu, Z. Li, Y . Zhang, Y . Liu, and L. Yi. TACO: Benchmarking gener- alizable bimanual tool-ACtion-object understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[39]
X. Wang, T. Kwon, M. Rad, B. Pan, I. Chakraborty, S. Andrist, D. Bohus, A. Feniello, B. Tekin, F. V . Frujeri, N. Joshi, and M. Pollefeys. HoloAssist: An egocentric human interaction dataset for interactive AI assistants in the real world. InIEEE/CVF International Conference on Com- puter Vision (ICCV), 2023
2023
-
[40]
G. Zhang, Q. Xu, H. Zhang, J. Ma, L. He, Y . Bao, Z. Ping, Z. Yuan, C. Lu, C. Yuan, T. Liang, X. Tian, M. Shao, F. Zhang, M. Ding, Y . Gao, H. Zhao, H. Zhao, and H. Xu. UniDex: A robot foundation suite for universal dexterous hand control from egocentric human videos.arXiv preprint arXiv:2603.22264, 2026
arXiv 2026
-
[41]
S. Lee, Y . Jung, I. Chun, Y .-C. Lee, Z. Cai, H. Huang, A. Talreja, T. D. Dao, Y . Liang, J.-B. Huang, and F. Huang. TraceGen: World modeling in 3d trace-space enables learning from cross-embodiment videos.arXiv preprint arXiv:2511.21690, 2025
arXiv 2025
-
[42]
C. Yuan, C. Wen, T. Zhang, and Y . Gao. General flow as foundation affordance for scal- able robot learning. In8th Annual Conference on Robot Learning, 2024. URLhttps: //openreview.net/forum?id=nmEt0ci8hi
2024
-
[43]
L. Y . Zhu, P. Kuppili, R. Punamiya, P. Aphiwetsa, D. Patel, S. Kareer, S. Ha, and D. Xu. EMMA: Scaling mobile manipulation via egocentric human data.IEEE Robotics and Automa- tion Letters, 2025
2025
-
[44]
Kareer, K
S. Kareer, K. Pertsch, J. Darpinian, J. Hoffman, D. Xu, S. Levine, C. Finn, and S. Nair. Emer- gence of human to robot transfer in vision-language-action models.Preprint, 2025
2025
-
[45]
H. Kim, J. Kang, H. Kang, M. Cho, S. J. Kim, and Y . Lee. Uniskill: Imitating human videos via cross-embodiment skill representations. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id=EgSDP6AOF1
2025
- [46]
-
[47]
A. Singh, K. Torshizi, K. Habib, K. Yu, R. Gao, and P. Tokekar. Afford2Act: Affordance- guided automatic keypoint selection for generalizable and lightweight robotic manipulation. arXiv preprint arXiv:2510.01433, 2025
Pith/arXiv arXiv 2025
-
[48]
C.-C. Hsu, B. Wen, J. Xu, Y . Narang, X. Wang, Y . Zhu, J. Biswas, and S. Birchfield. SPOT: SE(3) pose trajectory diffusion for object-centric manipulation.arXiv preprint arXiv:2411.00965, 2024
arXiv 2024
-
[49]
Y . Zou, C. Shi, W. Yu, H. Xue, J. Lv, Y . Pan, C. Wen, and C. Lu. ActiveGlasses: Learn- ing manipulation with active vision from ego-centric human demonstration.arXiv preprint arXiv:2604.08534, 2026
Pith/arXiv arXiv 2026
-
[50]
Z.-H. Yin, S. Yang, and P. Abbeel. Object-centric 3d motion field for robot learning from human videos.arXiv preprint arXiv:2506.04227, 2025
arXiv 2025
-
[51]
J. Shi, Z. Zhao, T. Wang, I. Pedroza, A. Luo, J. Wang, J. Ma, and D. Jayaraman. ZeroMimic: Distilling robotic manipulation skills from web videos. InIEEE International Conference on Robotics and Automation (ICRA), 2025. 12
2025
-
[52]
S. Park, H. Bharadhwaj, and S. Tulsiani. DemoDiffusion: One-shot human imitation using pre-trained diffusion policy.arXiv preprint arXiv:2506.20668, 2025
arXiv 2025
-
[53]
R. Shah, S. Liu, Q. Wang, Z. Jiang, S. Kumar, M. Seo, R. Mart ´ın-Mart´ın, and Y . Zhu. Mim- icDroid: In-context learning for humanoid robot manipulation from human play videos.arXiv preprint arXiv:2509.09769, 2025
arXiv 2025
-
[54]
H. Chen, T. Dong, T. Wu, L. Wang, Y . Jangir, Y . Niu, Y . Ye, H. Bharadhwaj, Z. Erickson, and J. Ichnowski. Dexterous manipulation policies from RGB human videos via 3d hand-object trajectory reconstruction.arXiv preprint arXiv:2602.09013, 2026
arXiv 2026
-
[55]
J. Shi, J. Smith, J. Qian, and D. Jayaraman. Points2Reward: Robotic manipulation rewards from just one video. InRSS Workshop on Semantic Robotics (SemRob), 2025
2025
-
[56]
B. Wang, N. Sridhar, C. Feng, M. van der Merwe, A. Fishman, N. Fazeli, and J. J. Park. This&that: Language-gesture controlled video generation for robot planning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12842–12849, 2025. doi: 10.1109/ICRA55743.2025.11128780
-
[57]
H. Xiong, Q. Li, Y .-C. Chen, H. Bharadhwaj, S. Sinha, and A. Garg. Learning by watching: Physical imitation of manipulation skills from human videos. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7827–7834, 2021. doi:10.1109/ IROS51168.2021.9636080
arXiv 2021
-
[58]
Suvorov, E
R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V . Lempitsky. Resolution-robust large mask inpainting with Fourier convolutions. InIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022
2022
-
[59]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[60]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[61]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. CoTracker: It is better to track together. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[62]
Z. Wang, Z. Zhang, J. Xu, J. Wang, T. Pang, C. Du, H. Zhao, and Z. Zhao. Orient anything V2: Unifying orientation and rotation understanding. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2025
2025
-
[63]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[64]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[65]
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou. WiLoR: End-to-end 3d hand localization and reconstruction in-the-wild.arXiv preprint arXiv:2409.12259, 2024
arXiv 2024
-
[66]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3D with transformers. InIEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2024. 13
2024
-
[67]
Z. Yu, S. Zafeiriou, and T. Birdal. Dyn-HaMR: Recovering 4d interacting hand motion from a dynamic camera.arXiv preprint arXiv:2412.12861, 2025
arXiv 2025
- [68]
-
[69]
C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C.-L. Chang, M. G. Yong, J. Lee, W.-T. Chang, W. Hua, M. Georg, and M. Grundmann. MediaPipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019
Pith/arXiv arXiv 1906
-
[70]
X. Zhang, Z. Kou, C. Qin, M. Huang, E. Ristani, A. Kumar Lele, L. Chen, K. He, A. Boularias, and L. Guan. Glove2Hand: Synthesizing natural hand-object interaction from multi-modal sensing gloves.arXiv preprint arXiv:2603.20850, 2026
Pith/arXiv arXiv 2026
-
[71]
more data is always better
A. Sarker, Z. Kou, E. Ristani, L. Guan, and T. Niehues. Real-time hand pose tracking using 6-axis IMUs. InACM/IEEE International Conference on Human-Robot Interaction (HRI), 2026. 14 Appendix A Data Collection Details A.1 Aria Gen1 Glasses Fig. 11:Data collection setup. Aria Gen1 recording configuration.We record every hu- man demonstration with Project A...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.