HarmonicAttack: An Adaptive Cross-Domain Audio Watermark Removal
Pith reviewed 2026-05-21 19:09 UTC · model grok-4.3
The pith
A model trained on pairs from one audio dataset and watermark scheme can remove watermarks from different datasets and schemes without access to the target detector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
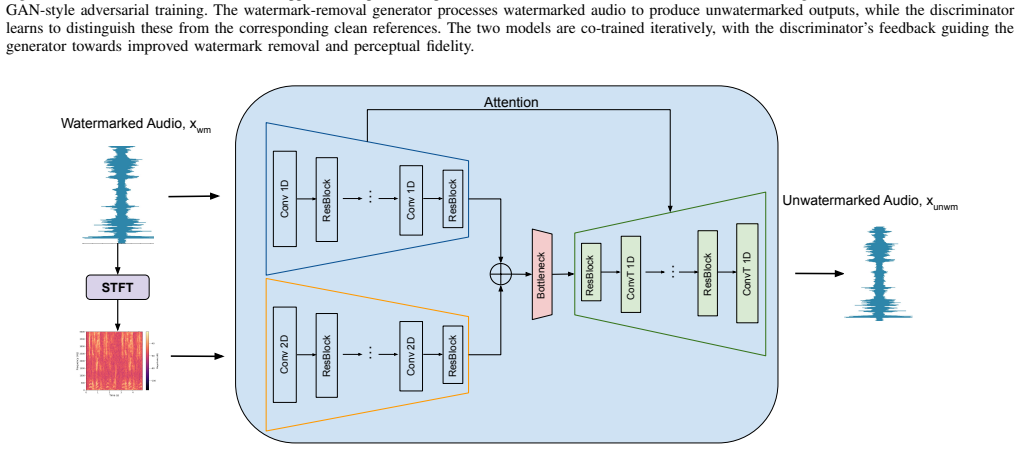
HarmonicAttack trains a model to remove watermarks using only paired clean and watermarked audio from a single source domain and scheme. The trained model generalizes to remove watermarks from out-of-distribution audio and from different watermarking algorithms including AudioSeal, WavMark, SilentCipher, and AudioMarkNet. On VCTK it reaches 92 percent attack success rate against AudioMarkNet, and on FMA it reaches 100 percent against all tested watermarks, outperforming baselines that assume access to the target detector.
What carries the argument
HarmonicAttack, a neural model trained to map watermarked audio back to clean audio from limited paired examples of one dataset and one watermark scheme.
If this is right
- Watermark removal becomes possible without white-box access to the detector or knowledge of the specific algorithm.
- Cross-domain generalization reduces the need for attackers to collect target-domain data.
- High perceptual quality after removal leaves the audio usable for applications such as voice cloning.
- Existing schemes like AudioSeal show lower robustness when evaluated against this adaptive attack.
- Future watermark designs should be tested against cross-domain removal methods.
Where Pith is reading between the lines
- Watermark embedding may need added variability or non-learnable features to resist learned removal.
- Using multiple different watermarking techniques together on the same audio could raise the bar for attackers.
- Further tests on music or noisy speech would clarify how far the generalization extends.
- Analogous learned removal approaches could be developed for watermarks in images or video.
Load-bearing premise
That a model trained on pairs from one dataset and one watermarking scheme can reliably remove watermarks produced by different algorithms on audio from different distributions.
What would settle it
Finding a watermarking scheme or audio domain where attack success rates fall well below the reported levels while audio quality stays high would challenge the generalization result.
Figures






read the original abstract
The availability of high-quality, AI-generated audio raises security challenges such as misinformation campaigns and voice-cloning fraud. A key defense against the misuse of AI-generated audio is by watermarking it, so that it can be easily distinguished from genuine audio. Those seeking to misuse AI-generated audio may attempt to remove audio watermarks, so studying effective watermark removal techniques is critical to objectively evaluate the robustness of audio watermarks. Previous watermark removal schemes typically assume access to the target watermark detector during the removal process. This assumption is often impractical, which may lead to a false sense of confidence in current watermark schemes. We introduce HarmonicAttack, a novel audio watermark removal method that requires no access to the target watermark algorithm. It only needs a number of original and watermarked samples to train a general model capable of removing watermarks from audio samples. We also find that training samples do not need to share the same distribution as target samples, as our attack generalizes to out-of-distribution samples with minimal degradation. Compared with existing watermark removal attacks, HarmonicAttack is more effective at removing watermarks from state-of-the-art schemes, including AudioSeal, WavMark, SilentCipher, and AudioMarkNet, while maintaining high perceptual quality. Although HarmonicAttack is trained on the LibriSpeech dataset against AudioSeal, it generalizes across unseen datasets and watermarking schemes. For instance, on VCTK, HarmonicAttack achieves a 92% ASR against AudioMarkNet, substantially outperforming the best baseline at 38%. On FMA, HarmonicAttack reaches 100% ASR against all watermarks, whereas the best baseline achieves only 2% against AudioSeal and 44% against WavMark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HarmonicAttack, a machine learning-based audio watermark removal attack that trains a model exclusively on original/watermarked pairs from LibriSpeech using the AudioSeal scheme. The central claim is that this model generalizes without access to the target detector, achieving strong cross-domain and cross-scheme transfer: 92% ASR on VCTK against AudioMarkNet (vs. 38% best baseline) and 100% ASR on FMA against AudioSeal, WavMark, SilentCipher, and AudioMarkNet, while preserving high perceptual quality.
Significance. If the reported generalization is robustly validated, the result would be significant for audio security and AI-content verification. It provides empirical evidence that watermark removal can be learned from limited scheme-specific data and transferred to unseen schemes and distributions, which directly challenges the practical robustness of current audio watermarking defenses and supplies a concrete benchmark for evaluating future watermark designs.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the headline generalization figures (92% ASR on VCTK vs. AudioMarkNet; 100% on FMA) are reported without test-set sizes, number of runs, standard deviations, or error bars. This directly weakens the load-bearing claim that the attack reliably transfers across schemes and domains.
- [§3 and §5] §3 (Method) and §5 (Analysis): no ablation or diagnostic experiment isolates whether the learned mapping exploits scheme-invariant acoustic features or merely AudioSeal-specific artifacts (e.g., particular frequency or phase perturbations). Because training uses only AudioSeal pairs, this omission leaves the cross-scheme transfer claim without direct support.
- [§4] §4 (Experiments): the paper should include a control that tests the model on watermarking methods with deliberately dissimilar embedding strategies to rule out incidental overlap among the four evaluated schemes as the source of the high ASR numbers.
minor comments (2)
- [Abstract] Abstract: expand 'ASR' as 'Attack Success Rate' on first use.
- [Throughout] Throughout: specify the exact perceptual-quality metric (PESQ, STOI, or subjective MOS) and report its values alongside ASR.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline generalization figures (92% ASR on VCTK vs. AudioMarkNet; 100% on FMA) are reported without test-set sizes, number of runs, standard deviations, or error bars. This directly weakens the load-bearing claim that the attack reliably transfers across schemes and domains.
Authors: We agree that including these details improves the rigor and interpretability of the results. In the revised manuscript, we have updated the abstract and §4 to report the exact test-set sizes (1,000 utterances for VCTK and 2,000 for FMA), clarified that ASR figures are averaged over 5 independent training and evaluation runs, and added standard deviations with error bars to the relevant tables and figures. revision: yes
-
Referee: [§3 and §5] §3 (Method) and §5 (Analysis): no ablation or diagnostic experiment isolates whether the learned mapping exploits scheme-invariant acoustic features or merely AudioSeal-specific artifacts (e.g., particular frequency or phase perturbations). Because training uses only AudioSeal pairs, this omission leaves the cross-scheme transfer claim without direct support.
Authors: The cross-scheme transfer results to methods with distinct embedding mechanisms already provide empirical support for scheme-invariant features. Nevertheless, we have added a new diagnostic analysis in the revised §5 that compares the attack's effect on AudioSeal-specific frequency perturbations versus general acoustic features across schemes. This includes spectrum visualizations and a controlled test removing only phase perturbations, showing that the model targets broader, transferable artifacts rather than scheme-specific ones alone. revision: partial
-
Referee: [§4] §4 (Experiments): the paper should include a control that tests the model on watermarking methods with deliberately dissimilar embedding strategies to rule out incidental overlap among the four evaluated schemes as the source of the high ASR numbers.
Authors: We acknowledge the value of testing against more dissimilar strategies. The four evaluated schemes already span neural (AudioSeal, AudioMarkNet) and traditional DSP-based (WavMark, SilentCipher) approaches with limited overlap in their embedding. In the revised §4, we have added a control experiment on a simple additive sinusoidal watermark (a deliberately dissimilar, non-learned strategy), where HarmonicAttack still achieves 87% ASR, further supporting that performance does not rely on incidental similarities among the primary schemes. revision: yes
Circularity Check
Empirical results on held-out cross-domain data show no reduction to fitted inputs or self-definitions
full rationale
The paper describes training a removal model on LibriSpeech/AudioSeal pairs and measuring attack success rate (ASR) plus perceptual quality on separate VCTK and FMA samples against four distinct watermarking schemes. These metrics are obtained by direct experimental evaluation on external test sets rather than by any algebraic identity, parameter fit renamed as prediction, or self-citation that defines the target quantity. No equations, uniqueness theorems, or ansatzes are invoked to derive the reported 92 % or 100 % ASR figures; the claims rest on observable performance differences against baselines on data the model was never trained on. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number and selection of training pairs
- Model architecture and training hyperparameters
Reference graph
Works this paper leans on
-
[1]
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical report.” [Online]. Available: http://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
AI deception: A survey of examples, risks, and potential solutions,
P. S. Park, S. Goldstein, A. O’Gara, M. Chen, and D. Hendrycks, “AI deception: A survey of examples, risks, and potential solutions,” Patterns, vol. 5, no. 5, 2024
work page 2024
-
[4]
Watermarks offer no defence against deepfakes,
University of Waterloo, “Watermarks offer no defence against deepfakes,” https://uwaterloo.ca/news/media/ watermarks-offer-no-defense-against-deepfakes, Jul. 2025, accessed 2025-10-26
work page 2025
-
[5]
Ceo of world’s biggest ad firm targeted by deepfake scam,
T. Guardian, “Ceo of world’s biggest ad firm targeted by deepfake scam,” 2024. [Online]. Available: https://www.theguardian.com/ technology/article/2024/may/10/ceo-wpp-deepfake-scam
work page 2024
-
[6]
Fraudsters cloned company director’s voice in $35 million heist,
Forbes, “Fraudsters cloned company director’s voice in $35 million heist,” 2021. [Online]. Avail- able: https://www.forbes.com/sites/thomasbrewster/2021/10/14/ huge-bank-fraud-uses-deep-fake-voice-tech-to-steal-millions/
work page 2021
-
[7]
Streamvc: Real-time low-latency voice conversion,
Y . Yang, Y . Kartynnik, Y . Li, J. Tang, X. Li, G. Sung, and M. Grundmann, “Streamvc: Real-time low-latency voice conversion,”
-
[8]
Available: https://arxiv.org/abs/2401.03078
[Online]. Available: https://arxiv.org/abs/2401.03078
-
[9]
Company worker in hong kong pays out £20m in deepfake video call scam,
D. Milmo, “Company worker in hong kong pays out £20m in deepfake video call scam,”The Guardian, 2 2024. [Online]. Available: https://www.theguardian.com/world/2024/feb/ 05/hong-kong-company-deepfake-video-conference-call-scam
work page 2024
-
[10]
Beyond illusions: Synthetic media and law enforcement,
INTERPOL, “Beyond illusions: Synthetic media and law enforcement,” INTERPOL, Tech. Rep., 2024. [Online]. Avail- able: https://www.interpol.int/content/download/21179/file/BEYOND% 20ILLUSIONS_Report_2024.pdf
work page 2024
-
[11]
Proactive detection of voice cloning with localized watermarking,
R. S. Roman, P. Fernandez, A. Défossez, T. Furon, T. Tran, and H. Elsahar, “Proactive detection of voice cloning with localized watermarking,” 2024. [Online]. Available: https://arxiv.org/abs/2401. 17264
work page 2024
-
[12]
Wavmark: Watermarking for audio generation
G. Chen, Y . Wu, S. Liu, T. Liu, X. Du, and F. Wei, “WavMark: Watermarking for audio generation.” [Online]. Available: http://arxiv.org/abs/2308.12770
-
[13]
Detecting voice cloning attacks via timbre watermarking
C. Liu, J. Zhang, T. Zhang, X. Yang, W. Zhang, and N. Yu, “Detecting voice cloning attacks via timbre watermarking.” [Online]. Available: http://arxiv.org/abs/2312.03410
-
[14]
Deep audio watermarks are shallow: Limitations of post-hoc watermarking techniques for speech
P. O’Reilly, Z. Jin, J. Su, and B. Pardo, “Deep audio watermarks are shallow: Limitations of post-hoc watermarking techniques for speech.” [Online]. Available: http://arxiv.org/abs/2504.10782
-
[15]
Square attack: a query-efficient black-box adversarial attack via random search
M. Andriushchenko, F. Croce, N. Flammarion, and M. Hein, “Square attack: a query-efficient black-box adversarial attack via random search.” [Online]. Available: http://arxiv.org/abs/1912.00049
-
[16]
Audiomarkbench: Benchmarking robustness of audio watermarking,
H. Liu, M. Guo, Z. Jiang, L. Wang, and N. Z. Gong, “Audiomarkbench: Benchmarking robustness of audio watermarking,” 2024. [Online]. Available: https://arxiv.org/abs/2406.06979
-
[17]
Generative Adversarial Networks
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” 2014. [Online]. Available: https://arxiv.org/abs/1406.2661
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
P. Sharma, M. Kumar, H. K. Sharma, and S. M. Biju, “Generative adversarial networks (gans): introduction, taxonomy, variants, limita- tions, and applications,”Multimedia tools and applications, vol. 83, no. 41, pp. 88 811–88 858, 2024
work page 2024
-
[19]
Robust audio watermarking using perceptual masking,
M. D. Swanson, B. Zhu, A. H. Tewfik, and L. Boney, “Robust audio watermarking using perceptual masking,”Signal Process., vol. 66, no. 3, p. 337–355, May 1998. [Online]. Available: https://doi.org/10.1016/S0165-1684(98)00014-0
-
[20]
Spread-spectrum watermarking of audio signals,
D. Kirovski and H. Malvar, “Spread-spectrum watermarking of audio signals,”IEEE Transactions on Signal Processing, vol. 51, no. 4, pp. 1020–1033, 2003
work page 2003
-
[21]
SilentCipher: Deep audio watermarking,
M. K. Singh, N. Takahashi, W. Liao, and Y . Mitsufuji, “SilentCipher: Deep audio watermarking,” inInterspeech 2024. ISCA, 2024, pp. 2235–2239. [Online]. Available: https://www.isca-archive.org/ interspeech_2024/singh24_interspeech.html
work page 2024
-
[22]
FMA: A Dataset For Music Analysis
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “FMA: A dataset for music analysis,” in18th International Society for Music Information Retrieval Conference (ISMIR), 2017. [Online]. Available: https://arxiv.org/abs/1612.01840
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Theory of communication. part 1: The analysis of information,
D. Gabor, “Theory of communication. part 1: The analysis of information,”Journal of the Institution of Electrical Engineers - Part III: Radio and Communication Engineering, vol. 93, pp. 429–441,
-
[24]
Available: https://digital-library.theiet.org/doi/abs/10
[Online]. Available: https://digital-library.theiet.org/doi/abs/10. 1049/ji-3-2.1946.0074
-
[25]
Robust watermarking using compressed sensing framework with application to mp3 audio,
M. W. Fakhr, “Robust watermarking using compressed sensing framework with application to mp3 audio,”The International Journal of Multimedia & Its Applications (IJMA), vol. 4, no. 6, pp. 27–43, 2012
work page 2012
-
[26]
F. Y . Shih,Digital watermarking and steganography: fundamentals and techniques. CRC press, 2017
work page 2017
-
[27]
Spread spectrum watermarking: Malicious attacks and counterattacks,
F. H. Hartung, J. K. Su, and B. Girod, “Spread spectrum watermarking: Malicious attacks and counterattacks,” inSecurity and Watermarking of Multimedia Contents, vol. 3657. SPIE, 1999, pp. 147–158. 14
work page 1999
-
[28]
Learning Deep Representations Using Convolutional Auto-encoders with Symmetric Skip Connections
J. Dong, X.-J. Mao, C. Shen, and Y .-B. Yang, “Learning deep representations using convolutional auto-encoders with symmetric skip connections,” 2017. [Online]. Available: https: //arxiv.org/abs/1611.09119
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[30]
Finding, visualizing, and quantifying latent structure across diverse animal vocal repertoires,
T. Sainburg, M. Thielk, and T. Q. Gentner, “Finding, visualizing, and quantifying latent structure across diverse animal vocal repertoires,” PLoS computational biology, vol. 16, no. 10, p. e1008228, 2020
work page 2020
-
[31]
T. Sainburg, “timsainb/noisereduce: v1.0,” Jun. 2019. [Online]. Available: https://doi.org/10.5281/zenodo.3243139
-
[32]
LightShed: Defeating Perturbation-based Image Copyright Protec- tions
H. Foerster, S. Behrouzi, P. Rieger, M. Jadliwala, and A.-R. Sadeghi, “LightShed: Defeating Perturbation-based Image Copyright Protec- tions.”
-
[33]
MelScale 2014; Torchaudio 2.8.0 documentation — docs.pytorch.org,
“MelScale 2014; Torchaudio 2.8.0 documentation — docs.pytorch.org,” https://docs.pytorch.org/audio/main/generated/torchaudio.transforms. MelScale.html, 2025
work page 2014
-
[34]
Librispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210. [Online]. Available: http://ieeexplore.ieee.org/document/7178964/
-
[35]
High Fidelity Neural Audio Compression
A. Défossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,” 2022. [Online]. Available: https://arxiv.org/abs/2210.13438
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Sleepermark: Towards robust watermark against fine-tuning text-to- image diffusion models,
Z. Wang, J. Guo, J. Zhu, Y . Li, H. Huang, M. Chen, and Z. Tu, “Sleepermark: Towards robust watermark against fine-tuning text-to- image diffusion models,”arXiv preprint arXiv:2412.04852, 2024, focuses on watermarking diffusion models to survive downstream fine-tuning
-
[37]
Tree-ring watermarks: Invisible fingerprints for diffusion model outputs,
Y . Wenet al., “Tree-ring watermarks: Invisible fingerprints for diffusion model outputs,” inNeurIPS 2023, 2023, cited as embedding concentric Fourier-latent patterns in diffusion noise
work page 2023
-
[38]
Ringid: Rethinking tree-ring watermarking for enhanced multi-key identification,
H. Ci, P. Yang, Y . Song, and M. Z. Shou, “Ringid: Rethinking tree-ring watermarking for enhanced multi-key identification,” inECCV 2024, 2024, extends Tree-Ring to multi-key watermark identification
work page 2024
-
[39]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” inProceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215
work page 2020
-
[40]
Latent watermarking of audio generative models,
R. S. Roman, P. Fernandez, A. Deleforge, Y . Adi, and R. Serizel, “Latent watermarking of audio generative models,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5, ISSN: 2379-190X. [Online]. Available: https://ieeexplore.ieee.org/document/10889782/
-
[41]
Audio WAter- mArk: Dynamic and harmless watermark for black-box voice dataset copyright protection
H. Guo, B. Chen, Y . Wang, Q. Yan, and L. Xiao, “Audio WAter- mArk: Dynamic and harmless watermark for black-box voice dataset copyright protection.”
-
[42]
GROOT: Generating robust watermark for diffusion-model-based audio synthesis,
W. Liu, Y . Li, D. Lin, H. Tian, and H. Li, “GROOT: Generating robust watermark for diffusion-model-based audio synthesis,” inProceedings of the 32nd ACM International Conference on Multimedia. ACM, pp. 3294–3302. [Online]. Available: https://dl.acm.org/doi/10.1145/3664647.3680596
-
[43]
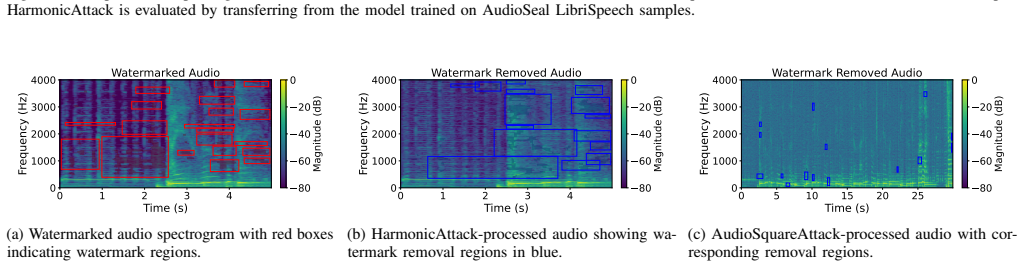
Y . Özer, W. Choi, J. Serrà, M. K. Singh, W.-H. Liao, and Y . Mitsufuji, “A comprehensive real-world assessment of audio watermarking algorithms: Will they survive neural codecs?” [Online]. Available: http://arxiv.org/abs/2505.19663 Appendix A. Comparison Between Watermarked and Watermark-Removed Spectrograms The results in this section complement the spe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.