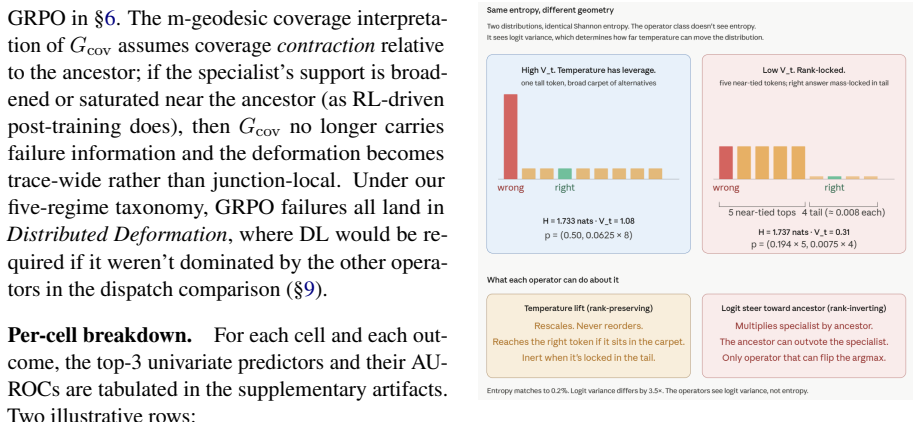
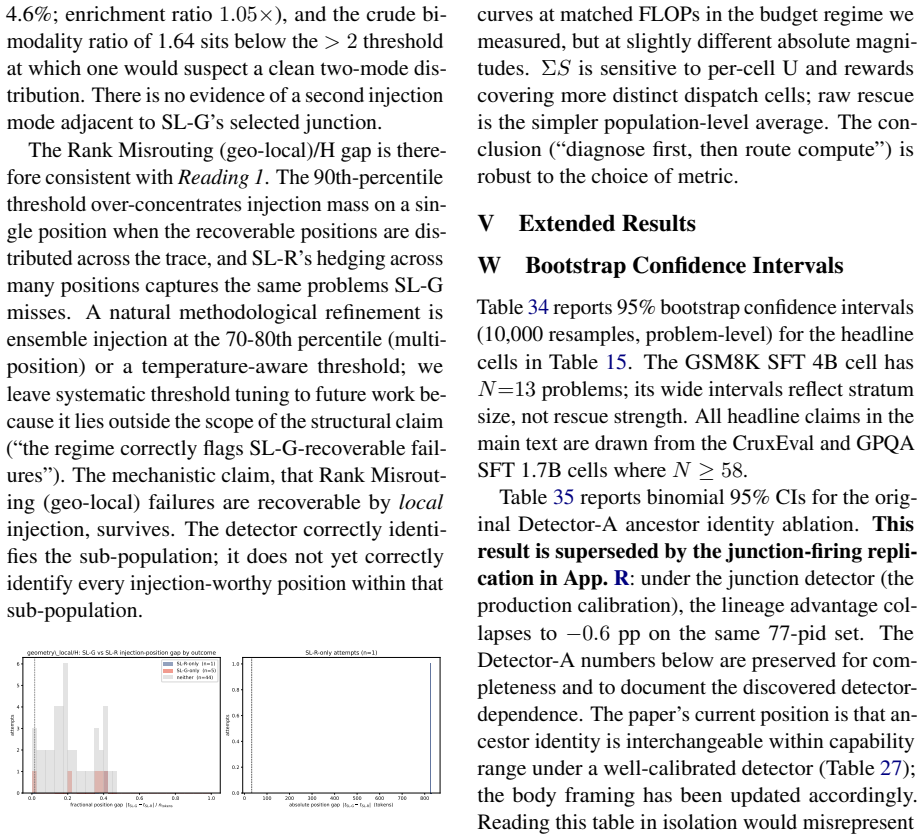
Failed Reasoning Traces Tell You What Is Fixable (But Not by Reading Them)
Pith reviewed 2026-06-28 06:45 UTC · model grok-4.3
The pith
Failed reasoning traces encode which test-time interventions can rescue them via three distributional trajectory features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
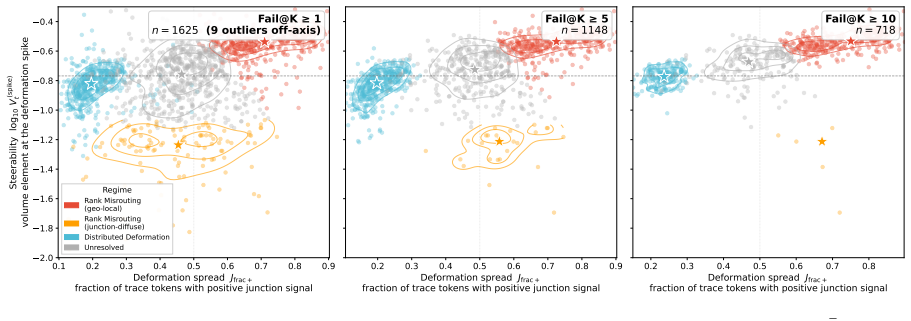
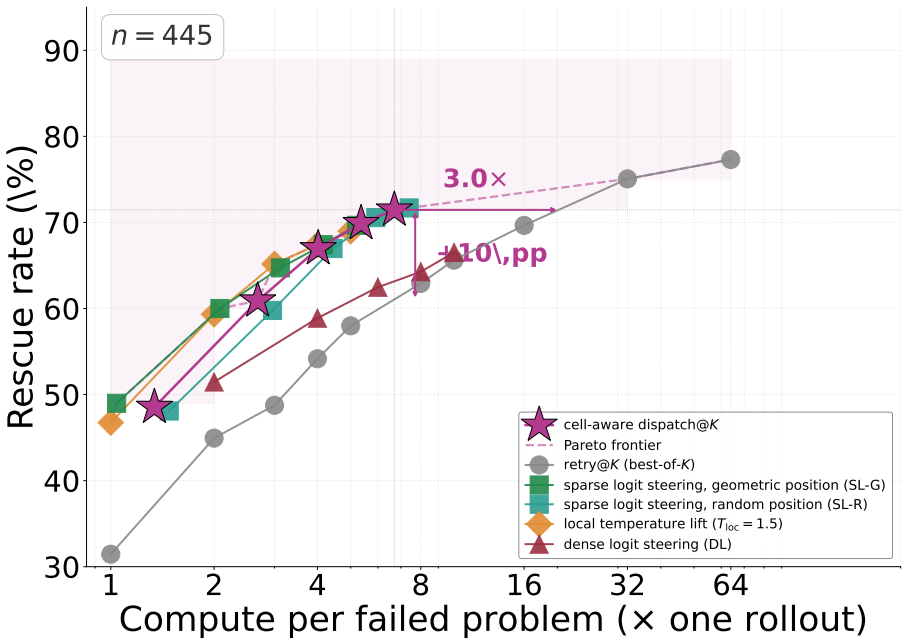
Failed traces encode recoverability structure: the inference-time signature of which test-time interventions can rescue a given failure. Three problem-level trajectory features recover this structure from the distributional signature of failed rollouts, not their text. They cluster failures into stable regimes, characterize the failure topography of different post-training methods (84.3±4.3 percent accuracy), and support a training-free routing rule that lifts rescue by 12.2 percent on the deployment-relevant Steerable-Hard subset.
What carries the argument
Three problem-level trajectory features derived from the structure of available interventions, which recover recoverability structure from the distributional signature of failed rollouts.
If this is right
- Failures can be clustered into stable regimes based on recoverability without reading trace text.
- Post-training methods can be characterized by their failure topography at 84.3 percent accuracy.
- A training-free routing rule can be applied at inference to select interventions and raise rescue rates by 12.2 percent on hard cases.
- The features and routing transfer across cross-family model probes.
Where Pith is reading between the lines
- Early patterns in rollout distributions could support dynamic adjustment of compute during a single inference run.
- The method offers a way to compare post-training techniques by their induced failure regimes without weight access.
- The three features might extend to additional intervention types or non-reasoning tasks to broaden diagnostic use.
Load-bearing premise
The distributional signature of failed rollouts alone is sufficient to recover the recoverability structure defined by the set of available interventions and remains stable enough to support clustering and cross-model routing.
What would settle it
A test on new failures where the three features fail to predict which interventions succeed or where the routing rule shows no lift on the Steerable-Hard subset.
Figures





read the original abstract
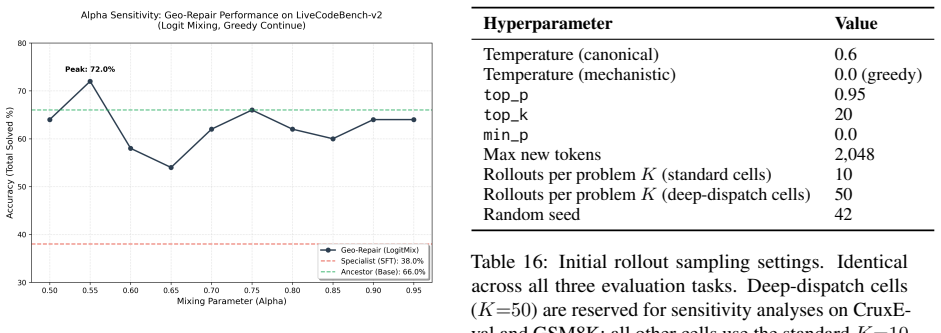
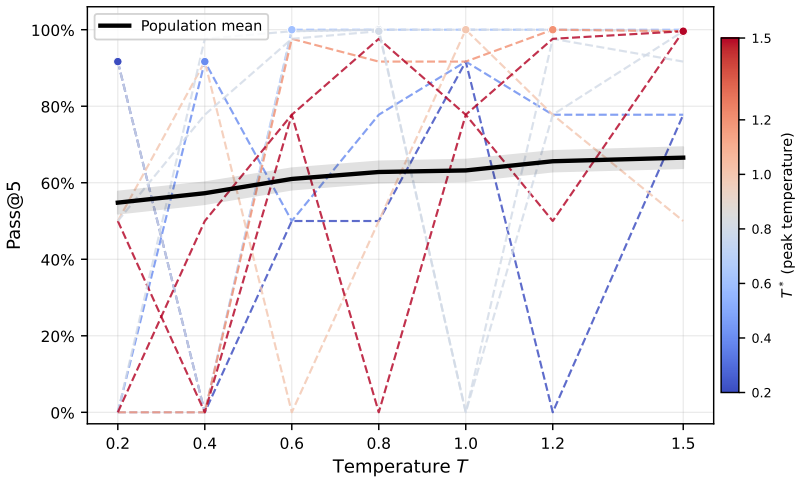
When post-trained language models fail on reasoning problems, the common test-time-scaling response is to spend more compute on additional attempts, and the failed traces play no further role. We argue this discards a crucial signal; some failures come from unlucky sampling, where more rollouts help, while others are structural and resist resampling regardless of budget. We propose that failed traces encode recoverability structure: the inference-time signature of which test-time interventions can rescue a given failure. Three problem-level trajectory features, derived from the structure of available interventions, recover this structure from the distributional signature of failed rollouts, not their text. They cluster failures into stable regimes, characterize the failure topography of different post-training methods ($84.3{\pm}4.3\%$ accuracy, $+20\%$ over a majority-class baseline), and support a training-free routing rule that lifts rescue by $+12.2\%$ on the deployment-relevant Steerable-Hard subset (failures where retry is insufficient and a bounded intervention is reachable). The features and the routing rule transfer across two cross-family probes. The same three features thus convert failed traces from discarded data into a diagnostic object, supporting test-time routing and post-training analysis without training-time or weight-space access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that failed reasoning traces encode recoverability structure—the inference-time signature of which test-time interventions can rescue a given failure. Three problem-level trajectory features, derived from the structure of available interventions, recover this structure from the distributional signature of failed rollouts (not their text). These features cluster failures into stable regimes, characterize the failure topography of different post-training methods (84.3±4.3% accuracy, +20% over majority-class baseline), and support a training-free routing rule that lifts rescue by +12.2% on the Steerable-Hard subset, with transfer across two cross-family probes.
Significance. If the results hold, the work offers a method to convert discarded failed traces into a diagnostic object for test-time routing and post-training analysis without training-time or weight-space access. This could improve efficiency in reasoning tasks by distinguishing resamplable failures from structural ones. The reported cross-model transfer and training-free routing are potential strengths if the empirical support is robust.
major comments (3)
- [Abstract] Abstract: The abstract states concrete performance figures (84.3% accuracy, +12.2% rescue lift) but supplies no information on feature definitions, data splits, baseline construction, or statistical controls, so it is impossible to judge whether the numbers support the central claim.
- [Methods] Methods/Experimental Setup: The three trajectory features are not defined explicitly (e.g., how they are computed from distributional signatures of failed rollouts or derived from intervention structure), which is load-bearing for verifying that the signature alone recovers recoverability structure independent of textual content.
- [Results] Results: The Steerable-Hard subset and the set of interventions used to define recoverability structure are not detailed, preventing assessment of whether the +12.2% lift and clustering results are reproducible or confounded by data construction choices.
minor comments (2)
- [Abstract] Abstract: Specify whether the ±4.3% is standard deviation or standard error and the number of runs or seeds used.
- [Notation] Notation: Define 'distributional signature' and 'problem-level trajectory features' more precisely to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The comments highlight opportunities to improve clarity and reproducibility in the abstract, methods, and results sections. We address each point below and will make revisions to incorporate the requested details without altering the core claims or experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states concrete performance figures (84.3% accuracy, +12.2% rescue lift) but supplies no information on feature definitions, data splits, baseline construction, or statistical controls, so it is impossible to judge whether the numbers support the central claim.
Authors: We agree the abstract is concise to the point of omitting essential context. In revision we will expand it to (1) name the three trajectory features and note they are computed from the empirical distribution of failed rollouts only, (2) state that results use 5-fold cross-validation over problems with held-out test splits, (3) identify the majority-class baseline explicitly, and (4) report that all accuracies include ±1 std over 10 random seeds. These additions will fit within the word limit while enabling readers to evaluate the numbers directly. revision: yes
-
Referee: [Methods] Methods/Experimental Setup: The three trajectory features are not defined explicitly (e.g., how they are computed from distributional signatures of failed rollouts or derived from intervention structure), which is load-bearing for verifying that the signature alone recovers recoverability structure independent of textual content.
Authors: The full manuscript (Section 3) defines the features via their functional dependence on the per-problem distribution of intervention outcomes, but we accept that the exposition is insufficiently explicit. We will add a new subsection “Trajectory Feature Definitions” containing (a) the exact formulas, (b) pseudocode showing computation from rollout success vectors alone, and (c) a short proof sketch that the features are invariant to token content. This will make the claim that recoverability structure is recovered from distributional signatures verifiable without reference to the text of traces. revision: yes
-
Referee: [Results] Results: The Steerable-Hard subset and the set of interventions used to define recoverability structure are not detailed, preventing assessment of whether the +12.2% lift and clustering results are reproducible or confounded by data construction choices.
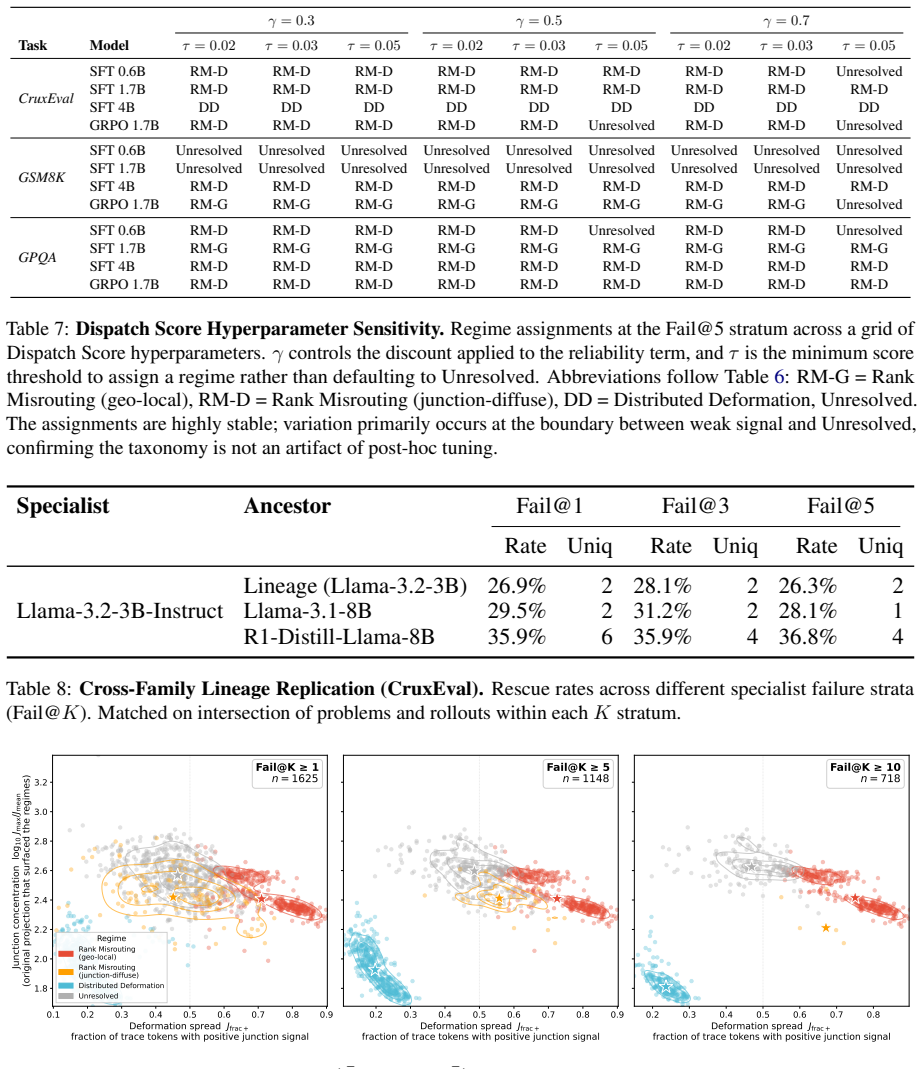
Authors: We will expand Section 4.2 to provide: (1) the precise filtering criteria and size of the Steerable-Hard subset (failures where resampling alone yields <5% success but at least one bounded intervention reaches ≥50% success), (2) an enumerated list of the interventions together with their parameter ranges, and (3) the exact train/test split ratios and seed values used for the clustering and routing experiments. A supplementary table will list all construction hyperparameters so that the reported lifts and accuracies can be reproduced from the released rollout logs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and summary articulate an empirical claim: three intervention-derived trajectory features applied to distributional signatures (not text) of failed rollouts recover recoverability structure, enable clustering, and support routing. No equations, self-citations, or derivation steps are visible that reduce a prediction to a fitted input by construction or import uniqueness via author overlap. Reported metrics (84.3±4.3% accuracy, +12.2% lift) are presented as external evidence on held-out subsets and cross-model transfer; the central position remains logically independent of its inputs and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, and Yi Ma. SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training. arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Zhizhou Sha, Jinwon Lee, David Z. Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai. The Path Not Taken: RLVR Provably Learns Off the Principals. In NeurIPS 2025 Workshop on Efficient Reasoning (spotlight); arXiv:2511.08567, 2025
-
[3]
RL's Razor: Why Online Reinforcement Learning Forgets Less
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. RL's Razor: Why Online Reinforcement Learning Forgets Less. arXiv preprint arXiv:2509.04259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
MIXIE: Multi-Expert Instruction Following via Inference-time Mixing
Ayan Sanyal, Xiang Ren. MIXIE: Multi-Expert Instruction Following via Inference-time Mixing. arXiv preprint arXiv:2502.10777, 2025
-
[5]
The Well-Tempered Classifier: Some Elementary Properties of Temperature Scaling
Pierre-Alexandre Mattei and Bruno Loureiro. The Well-Tempered Classifier: Some Elementary Properties of Temperature Scaling. arXiv preprint arXiv:2502.14862v1, 2025
-
[6]
Embarrassingly Simple Self-Distillation Improves Code Generation
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly Simple Self-Distillation Improves Code Generation. arXiv preprint arXiv:2604.01193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas H \"u botter, and Pulkit Agrawal. Self-Distillation Enables Continual Learning. arXiv preprint arXiv:2501.19897, 2025
-
[8]
Temporal Sampling for Forgotten Reasoning in LLMs
Yuetai Li, Zhangchen Xu, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, Xiang Yue, and Radha Poovendran. Temporal Sampling for Forgotten Reasoning in LLMs. arXiv preprint arXiv:2505.20196, 2025
-
[9]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. arXiv preprint arXiv:2309.03883, 2023. In Proceedings of the International Conference on Learning Representations, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Information Geometry and Its Applications
Shun-ichi Amari. Information Geometry and Its Applications. Springer, 2016
2016
-
[11]
Chen, Yoonho Lee, Eric Mitchell, and Chelsea Finn
Johnathan Xie, Annie S. Chen, Yoonho Lee, Eric Mitchell, and Chelsea Finn. Calibrating Language Models with Adaptive Temperature Scaling. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[12]
Bespoke-Stratos-17k: A Dataset of DeepSeek-R1-Distilled Reasoning Chains
Bespoke Labs. Bespoke-Stratos-17k: A Dataset of DeepSeek-R1-Distilled Reasoning Chains. https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k, 2025
2025
-
[13]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In International Conference on Learning Representations (ICLR); arXiv:2203.11171, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Alex Gu, Baptiste Rozi \`e re, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution. arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to Summarize with Human Feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 3008--3021, 2020
2020
-
[18]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand\`es, and Tatsunori Hashimoto. s1: Simple Test-Time Scaling. arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.