HalluWorld: A Controlled Benchmark for Hallucination via Reference World Models
Pith reviewed 2026-05-20 05:49 UTC · model grok-4.3
pith:HPZPRGEP Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{HPZPRGEP}
Prints a linked pith:HPZPRGEP badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
HalluWorld defines hallucinations as false observable claims against a fully specified reference world.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
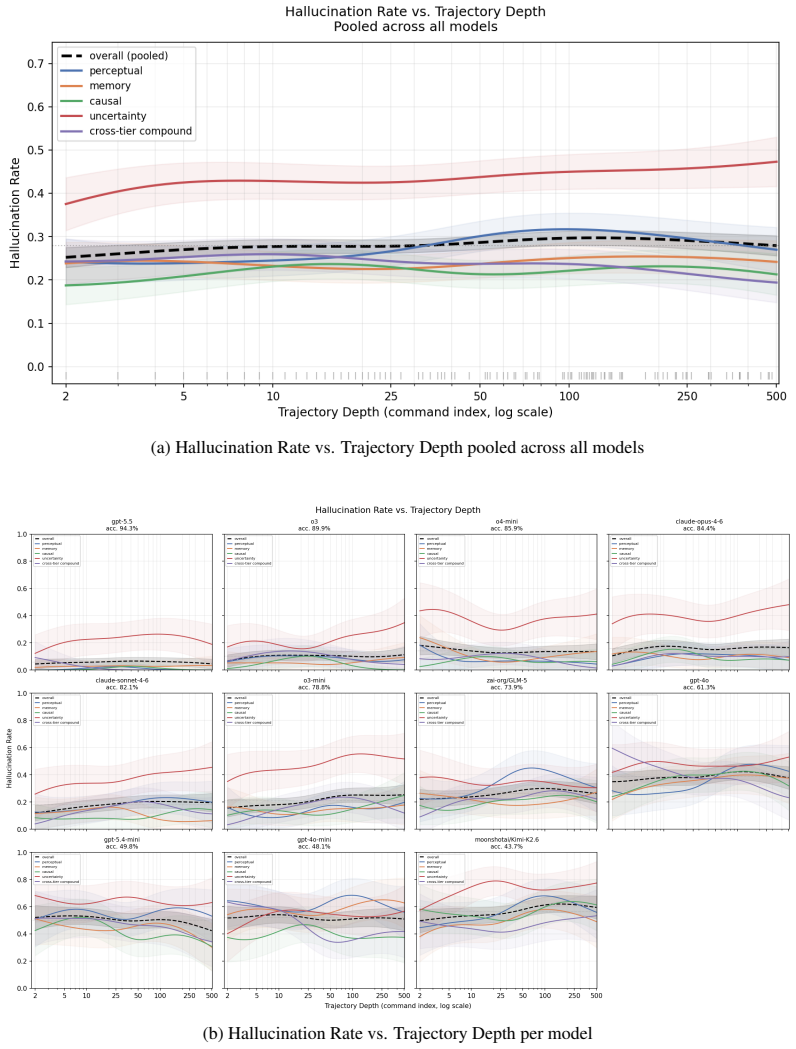
The paper establishes that a model hallucinates precisely when it produces an observable claim false with respect to an explicitly specified reference world. Synthetic and semi-synthetic environments are built in which the full world state is known, the model's partial view is controlled, and hallucination labels are generated without human annotation. These environments span gridworlds, chess, and realistic terminal tasks, allowing systematic variation of complexity, observability, temporal dynamics, and source conflicts while producing fine-grained error categories. Evaluation of frontier and open-weight models shows perceptual hallucinations on directly observed facts are largely solved,
What carries the argument
The reference-world formulation that treats hallucination as any observable claim contradicting the fully known world state, allowing automatic labeling in controlled synthetic settings.
If this is right
- Hallucinations can be measured reproducibly across domains without fixed memorized references or human annotation.
- Error types can be separated into perceptual, multi-step tracking, and abstention failures for targeted study.
- Varying world complexity and observability reveals which capabilities remain unsolved even with extended thinking.
- Consistent failure profiles across models suggest hallucinations are not a single capability problem.
Where Pith is reading between the lines
- If synthetic reference worlds capture essential dynamics, interventions that reduce specific error categories here could be tested for transfer to production systems.
- The same reference-world approach might be applied to agentic or multi-turn interactions to measure cumulative state errors over time.
- Combining automatic labels with targeted human review on edge cases could refine the benchmark while keeping scalability.
Load-bearing premise
An explicitly specified reference world can be built and used to produce automatic hallucination labels that match the same phenomenon observed in real open-ended language model use.
What would settle it
Human judges marking the same model outputs on overlapping real-world examples would show low agreement with the automatic HalluWorld labels, or model improvements on HalluWorld would fail to reduce hallucinations on standard non-synthetic benchmarks.
Figures





read the original abstract
Hallucination remains a central failure mode of large language models, but existing benchmarks operationalize it inconsistently across summarization, question answering, retrieval-augmented generation, and agentic interaction. This fragmentation makes it unclear whether a mitigation that works in one setting reduces hallucinations across contexts. Current benchmarks either require human annotation and fixed references that may be memorized, or rely on observations in settings that are difficult to reproduce. To study root causes, we introduce HalluWorld, an extensible benchmark grounded in an explicit reference-world formulation: a model hallucinates when it produces an observable claim that is false with respect to this world. Building on this view, we construct synthetic and semi-synthetic environments in which the reference world is fully specified, the model's view is controlled, and hallucination labels are generated automatically. HalluWorld spans gridworlds, chess, and realistic terminal tasks, enabling controlled variation of world complexity, observability, temporal change, and source-conflict policy, and disentangling hallucinations into fine-grained error categories. We evaluate frontier and open-weight language models across these settings and find consistent patterns: perceptual hallucination on directly observed information is near-solved for frontier models, while multi-step state tracking and causal forward simulation remain difficult and are not generally solved by extended thinking. In the terminal setting, models also struggle with when to abstain. The uneven profile of failures across probe types and domains suggests that hallucinations arise from distinct failure modes rather than a single capability. Our results suggest that controlled reference worlds offer a scalable and reproducible path toward measuring and reducing hallucinations in modern language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HalluWorld, an extensible benchmark for LLM hallucinations grounded in explicit reference-world models. Hallucination is defined as producing an observable claim false with respect to a fully specified world state. The authors construct synthetic and semi-synthetic environments (gridworlds, chess, realistic terminal tasks) that control complexity, observability, temporal change, and source-conflict policy, with automatic label generation. Evaluations of frontier and open-weight models show perceptual hallucinations on directly observed information are near-solved, while multi-step state tracking and causal forward simulation remain difficult even with extended thinking; models also struggle with abstention in terminal settings. The uneven error profile is taken to indicate distinct failure modes rather than a single capability gap.
Significance. If the reference-world construction and automatic labeling hold, the benchmark supplies a reproducible, scalable method for dissecting hallucinations that avoids reliance on human annotation or potentially memorized fixed references. The automatic, fine-grained error categorization and controlled variation of observability and source conflict are clear strengths that enable targeted diagnosis. The reported consistent patterns across models lend support to the claim of multiple underlying mechanisms and could guide more precise mitigation strategies.
major comments (1)
- The central empirical claim that perceptual errors are near-solved while multi-step state tracking and causal simulation remain difficult (reported in the evaluation across gridworld, chess, and terminal settings) rests on the untested assumption that error distributions in these fully specified synthetic worlds match those in open-ended, real-world LLM use. No cross-benchmark correlation with existing human-annotated hallucination datasets or human validation of label fidelity is described, which is load-bearing for interpreting the patterns as general insights rather than environment-specific observations.
minor comments (2)
- The abstract refers to 'extended thinking' without specifying whether this denotes chain-of-thought prompting, self-consistency, or a particular inference-time method; a short clarification in the methods or evaluation section would improve reproducibility.
- Implementation details for the semi-synthetic terminal tasks (e.g., how the reference world state is encoded and how observable claims are extracted from model outputs) could be expanded or accompanied by pseudocode to aid independent reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for raising this important point about the scope of our empirical claims. We address the major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: The central empirical claim that perceptual errors are near-solved while multi-step state tracking and causal simulation remain difficult (reported in the evaluation across gridworld, chess, and terminal settings) rests on the untested assumption that error distributions in these fully specified synthetic worlds match those in open-ended, real-world LLM use. No cross-benchmark correlation with existing human-annotated hallucination datasets or human validation of label fidelity is described, which is load-bearing for interpreting the patterns as general insights rather than environment-specific observations.
Authors: We appreciate this observation. HalluWorld is deliberately constructed around fully specified reference worlds to support automatic, reproducible labeling and controlled variation of factors such as observability and source conflict—features that existing human-annotated benchmarks often lack. The consistent separation between near-solved perceptual errors and persistent difficulties in multi-step tracking and causal simulation across three qualitatively different environments (gridworlds, chess, and terminal tasks) is presented as evidence for distinct failure modes within these controlled settings. We do not claim that the precise error distributions transfer identically to open-ended real-world use. We agree that an explicit discussion of this scope would strengthen the manuscript and will add a dedicated limitations subsection in the revised version that (a) clarifies the intended role of HalluWorld as a diagnostic rather than exhaustive proxy and (b) outlines potential future work on cross-benchmark correlations. No new experiments are required for this clarification. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained
full rationale
The paper introduces HalluWorld as a new benchmark using explicitly specified reference worlds (gridworlds, chess, terminal tasks) to generate automatic hallucination labels by checking claims against known world states. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on the construction of synthetic environments and empirical model evaluations, which are independent of any prior fitted quantities or author-specific uniqueness theorems. Results are presented as observed patterns rather than predictions forced by the inputs themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A model hallucinates when it produces an observable claim that is false with respect to the reference world.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a model hallucinates when it produces an observable claim that is false with respect to this reference world... W=(S,H,R), view function V, and truth function TW,P
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of Multimodal Large Language Models: A Survey. 4 2025
work page 2025
-
[2]
HalluLens: LLM Hallucination Benchmark
Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Cancedda, and Pascale Fung. HalluLens: LLM Hallucination Benchmark. 4 2025
work page 2025
-
[3]
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Forrest Sheng Bao, Miaoran Li, Renyi Qu, Ge Luo, Erana Wan, Yujia Tang, Weisi Fan, Manveer Singh Tamber, Suleman Kazi, Vivek Sourabh, Mike Qi, Ruixuan Tu, Chenyu Xu, Matthew Gonzales, Ofer Mendelevitch, and Amin Ahmad. FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs. 10 2024
work page 2024
-
[4]
A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649:1139–1146, 2026
Center for AI Safety, Scale AI, and HLE Contributors Consortium. A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649:1139–1146, 2026. doi: 10.1038/s415 86-025-09962-4. URLhttps://doi.org/10.1038/s41586-025-09962-4
-
[5]
Benchmarking Large Language Models in Retrieval-Augmented Generation
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. Benchmarking Large Language Models in Retrieval-Augmented Generation. 12 2023
work page 2023
-
[6]
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning. 12 2019
work page 2019
-
[7]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo Perez-Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. In Advances in Neural Information Processing Systems 36, New Orleans, LA, USA, December 2023
work page 2023
-
[8]
Transformers as Soft Reasoners over Language
Peter Clark, Oyvind Tafjord, and Kyle Richardson. Transformers as Soft Reasoners over Language. 5 2020. 10
work page 2020
-
[9]
TextWorld: A Learning Environment for Text-based Games
Marc-Alexandre Côté, Ákos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Ruo Yu Tao, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. TextWorld: A Learning Environment for Text-based Games. 11 2019
work page 2019
-
[10]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? 7 2024
work page 2024
-
[11]
Standard: Portable game notation specification and implementation guide
Steven J Edwards, SD Forsyth, J Stanback, and A Saremba. Standard: Portable game notation specification and implementation guide. 1994.URL https://ia802908.us.archive.org/26/items/pgn-standard-1994-03-12/PGN_standard_1994-03- 12.txt, 1994
work page 1994
-
[12]
Feng, Jessica Huynh, Chaitanya Prasad Narisetty, Eduard Hovy, and Varun Gangal
Steven Y . Feng, Jessica Huynh, Chaitanya Prasad Narisetty, Eduard Hovy, and Varun Gangal. SAPPHIRE: Approaches for enhanced concept-to-text generation. In Anya Belz, Angela Fan, Ehud Reiter, and Yaji Sripada, editors,Proceedings of the 14th International Conference on Natural Language Generation, pages 212–225, Aberdeen, Scotland, UK, August 2021. Associ...
-
[13]
Feng, Kevin Lu, Zhuofu Tao, Malihe Alikhani, Teruko Mitamura, Eduard Hovy, and Varun Gangal
Steven Y . Feng, Kevin Lu, Zhuofu Tao, Malihe Alikhani, Teruko Mitamura, Eduard Hovy, and Varun Gangal. Retrieve, caption, generate: Visual grounding for enhancing commonsense in text generation models.Proceedings of the AAAI Conference on Artificial Intelligence, 36(10): 10618–10626, Jun. 2022. doi: 10.1609/aaai.v36i10.21306. URL https://ojs.aaai.org/i n...
-
[14]
Feng, Vivek Khetan, Bogdan Sacaleanu, Anatole Gershman, and Eduard Hovy
Steven Y . Feng, Vivek Khetan, Bogdan Sacaleanu, Anatole Gershman, and Eduard Hovy. CHARD: Clinical health-aware reasoning across dimensions for text generation models. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 313–327, Dubrovnik, C...
-
[15]
Steven Y . Feng, Noah D. Goodman, and Michael C. Frank. Is child-directed speech effective training data for language models? In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22055–22071, Miami, Florida, USA, November 2024. Association for Computatio...
-
[16]
Steven Y . Feng, Alvin W. M. Tan, and Michael C. Frank. Baby scale: Investigating models trained on individual children’s language input, 2026. URL https://arxiv.org/abs/2603 .29522
work page 2026
-
[17]
RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
Robert Friel, Masha Belyi, and Atindriyo Sanyal. RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems. 1 2025
work page 2025
-
[18]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallu- sionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models. 3 2024
work page 2024
-
[19]
David Ha and Jürgen Schmidhuber. World Models. 5 2018. doi: 10.5281/zenodo.1207631
-
[20]
Learning Latent Dynamics for Planning from Pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning Latent Dynamics for Planning from Pixels. 6 2019
work page 2019
-
[21]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to Control: Learning Behaviors by Latent Imagination. 3 2020
work page 2020
-
[22]
Tracking World States with Language Models: State-Based Evaluation Using Chess
Romain Harang, Jason Naradowsky, Yaswitha Gujju, and Yusuke Miyao. Tracking World States with Language Models: State-Based Evaluation Using Chess. 8 2025. 11
work page 2025
-
[23]
Tracking the World State with Recurrent Entity Networks
Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, and Yann LeCun. Tracking the World State with Recurrent Entity Networks. 5 2017
work page 2017
-
[24]
Jennifer Hu, Alvin Wei Ming Tan, Steven Y . Feng, and Michael C. Frank. Language production is harder than comprehension for children and language models. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 47, 2025. URL https://escholarship.o rg/uc/item/5rz8b9jg
work page 2025
-
[25]
Michael Y Hu, Aaron Mueller, Candace Ross, Adina Williams, Tal Linzen, Chengxu Zhuang, Ryan Cotterell, Leshem Choshen, Alex Warstadt, and Ethan Gotlieb Wilcox. Findings of the second babylm challenge: Sample-efficient pretraining on developmentally plausible corpora. InThe 2nd BabyLM Challenge at the 28th Conference on Computational Natural Language Learn...
work page 2024
-
[26]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. 11 2024. doi: 10.1145/3703155
-
[27]
The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input
Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, Corey Fry, Dror Marcus, Doron Kukliansky, Gaurav Singh Tomar, James Swirhun, Jinwei Xing, Lily Wang, Madhu Gurumurthy, Michael Aaron, Moran Ambar, Rachana Fellinger, Rui Wang, Zizhao Zhang, Sasha Goldshte...
work page 2025
-
[28]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Wenliang Dai, Ho Shu Chan, Andrea Madotto, and Pascale Fung. Survey of Hallucination in Natural Language Generation. 7 2024. doi: 10.1145/3571730
-
[29]
BoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information
Mehran Kazemi, Quan Yuan, Deepti Bhatia, Najoung Kim, Xin Xu, Vaiva Imbrasaite, and Deepak Ramachandran. BoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information. 6 2023
work page 2023
-
[30]
ACPBench: Reasoning about Action, Change, and Planning
Harsha Kokel, Michael Katz, Kavitha Srinivas, and Shirin Sohrabi. ACPBench: Reasoning about Action, Change, and Planning. 2 2026. doi: 10.1609/aaai.v39i25.34857
-
[31]
Evaluating the Factual Consistency of Abstractive Text Summarization
Wojciech Kry´sci´nski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the Factual Consistency of Abstractive Text Summarization. 10 2019
work page 2019
-
[32]
Hallucina- tions in Neural Machine Translation, 2019
Katherine Lee, Orhan Firat, Ashish Agarwal, Clara Fannjiang, and David Sussillo. Hallucina- tions in Neural Machine Translation, 2019. URL https://openreview.net/forum?id=Sk xJ-309FQ
work page 2019
-
[33]
Li, Zifan Carl Guo, and Jacob Andreas
Belinda Z. Li, Zifan Carl Guo, and Jacob Andreas. (How) Do Language Models Track State? 10 2025
work page 2025
-
[34]
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. 10 2023
work page 2023
-
[35]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating Object Hallucination in Large Vision-Language Models. 10 2023
work page 2023
-
[36]
Lichess. Lichess open database, 2022. URL https://database.lichess.org/. Accessed: 2026-05-04
work page 2022
-
[37]
CommonGen: A constrained text generation challenge for generative commonsense reasoning
Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. CommonGen: A constrained text generation challenge for generative commonsense reasoning. In Trevor Cohn, Yulan He, and Yang Liu, editors,Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840, Online, November
work page 2020
-
[38]
doi: 10.18653/v1/2020.findings-emnlp.165
Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.165. URLhttps://aclanthology.org/2020.findings-emnlp.165/. 12
-
[39]
Learning to Model the World with Language
Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, and Anca Dragan. Learning to Model the World with Language. 5 2024
work page 2024
-
[40]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring How Models Mimic Human Falsehoods. 5 2022
work page 2022
-
[41]
arXiv preprint arXiv:2505.21523 (2025) 13
Chengzhi Liu, Zhongxing Xu, Qingyue Wei, Juncheng Wu, James Zou, Xin Eric Wang, Yuyin Zhou, and Sheng Liu. More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models, 2025. URLhttps://arxiv.org/abs/2505.21523
- [42]
-
[43]
AgentHallu: Benchmarking Automated Hallucination Attribution of LLM-based Agents
Xuannan Liu, Xiao Yang, Zekun Li, Peipei Li, and Ran He. AgentHallu: Benchmarking Automated Hallucination Attribution of LLM-based Agents. 1 2026
work page 2026
-
[44]
Bria Long, Robert Z Sparks, Violet Xiang, Stefan Stojanov, Zi Yin, Grace E Keene, Alvin WM Tan, Steven Y Feng, Chengxu Zhuang, Virginia A Marchman, et al. The babyview dataset: High-resolution egocentric videos of infants’ and young children’s everyday experiences.arXiv preprint arXiv:2406.10447, 2024
-
[45]
On Faithfulness and Factuality in Abstractive Summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On Faithfulness and Factuality in Abstractive Summarization. 5 2020
work page 2020
-
[46]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[47]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for General AI Assistants. 11 2023
work page 2023
-
[49]
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. 10 2023
work page 2023
-
[50]
RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval- Augmented Language Models
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval- Augmented Language Models. 5 2024
work page 2024
-
[51]
Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics
Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics. 7 2021
work page 2021
-
[52]
Language models use lookbacks to track beliefs
Nikhil Prakash, Natalie Shapira, Arnab Sen Sharma, Christoph Riedl, Yonatan Belinkov, Tamar Rott Shaham, David Bau, and Atticus Geiger. Language models use lookbacks to track beliefs. InThe Fourteenth International Conference on Learning Representations, 2026. 13
work page 2026
-
[53]
HALoGEN: Fantastic LLM hallucinations and where to find them
Abhilasha Ravichander, Shrusti Ghela, David Wadden, and Yejin Choi. HALoGEN: Fantastic LLM hallucinations and where to find them. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1402–1425, Vienna, A...
-
[54]
Object Hallucination in Image Captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object Hallucination in Image Captioning. 3 2019
work page 2019
-
[55]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. 2 2020. doi: 10.1038/s41586-020-03051-4
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[56]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. 3 2021
work page 2021
-
[57]
Linearly decoding refused knowledge in aligned language models.arXiv preprint arXiv:2507.00239, 2025
Aryan Shrivastava and Ari Holtzman. Linearly decoding refused knowledge in aligned language models.arXiv preprint arXiv:2507.00239, 2025
- [58]
- [59]
-
[60]
ConflictBank: A Benchmark for Evaluating the Influence of Knowledge Conflicts in LLM
Zhaochen Su, Jun Zhang, Xiaoye Qu, Tong Zhu, Yanshu Li, Jiashuo Sun, Juntao Li, Min Zhang, and Yu Cheng. ConflictBank: A Benchmark for Evaluating the Influence of Knowledge Conflicts in LLM. 8 2024
work page 2024
-
[61]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning Large Multimodal Models with Factually Augmented RLHF. 9 2023
work page 2023
-
[62]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
-
[63]
ProofWriter: Generating Implications, Proofs, and Abductive Statements over Natural Language
Oyvind Tafjord, Bhavana Dalvi Mishra, and Peter Clark. ProofWriter: Generating Implications, Proofs, and Abductive Statements over Natural Language. 6 2021
work page 2021
-
[64]
Dyna-bAbI: unlocking bAbI’s potential with dynamic synthetic benchmark- ing
Ronen Tamari, Kyle Richardson, Aviad Sar-Shalom, Noam Kahlon, Nelson Liu, Reut Tsarfaty, and Dafna Shahaf. Dyna-bAbI: unlocking bAbI’s potential with dynamic synthetic benchmark- ing. 11 2021
work page 2021
-
[65]
Gridworlds as testbeds for planning with incomplete information
Craig Tovey and Sven Koenig. Gridworlds as testbeds for planning with incomplete information. InAAAI/IAAI, pages 819–824, 2000
work page 2000
-
[66]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change. 11 2023
work page 2023
-
[67]
An Audit on the Perspectives and Challenges of Hallucinations in NLP
Pranav Narayanan Venkit, Tatiana Chakravorti, Vipul Gupta, Heidi Biggs, Mukund Srinath, Koustava Goswami, Sarah Rajtmajer, and Shomir Wilson. An Audit on the Perspectives and Challenges of Hallucinations in NLP. 9 2024
work page 2024
-
[68]
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries
Alex Wang, Kyunghyun Cho, and Mike Lewis. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries. 4 2020
work page 2020
-
[69]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation. 2 2024. 14
work page 2024
-
[70]
Resolving Knowledge Conflicts in Large Language Models
Yike Wang, Shangbin Feng, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, and Yulia Tsvetkov. Resolving Knowledge Conflicts in Large Language Models. 10 2024
work page 2024
-
[71]
HaloQuest: A Visual Hallucination Dataset for Advancing Multimodal Reasoning
Zhecan Wang, Garrett Bingham, Adams Yu, Quoc Le, Thang Luong, and Golnaz Ghiasi. HaloQuest: A Visual Hallucination Dataset for Advancing Multimodal Reasoning. 7 2024
work page 2024
-
[72]
Findings of the babylm challenge: Sample-efficient pretraining on developmentally plausible corpora
Alex Warstadt, Aaron Mueller, Leshem Choshen, Ethan Wilcox, Chengxu Zhuang, Juan Ciro, Rafael Mosquera, Bhargavi Paranjabe, Adina Williams, Tal Linzen, et al. Findings of the babylm challenge: Sample-efficient pretraining on developmentally plausible corpora. InProceedings of the BabyLM Challenge at the 27th Conference on Computational Natural Language Le...
work page 2023
-
[73]
Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov
Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M. Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov. Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks. 12 2015
work page 2015
-
[74]
Hallucination diversity-aware active learning for text summarization
Yu Xia, Xu Liu, Tong Yu, Sungchul Kim, Ryan Rossi, Anup Rao, Tung Mai, and Shuai Li. Hallucination diversity-aware active learning for text summarization. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8665–8677, 2024
work page 2024
-
[75]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. 5 2024
work page 2024
-
[76]
Linda Zeng, Steven Y . Feng, and Michael C. Frank. Bringing up a bilingual babylm: In- vestigating multilingual language acquisition using small-scale models, 2026. URL https: //arxiv.org/abs/2603.29552
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Language-Guided World Models: A Model-Based Approach to AI Control
Alex Zhang, Khanh Nguyen, Jens Tuyls, Albert Lin, and Karthik Narasimhan. Language-Guided World Models: A Model-Based Approach to AI Control. 9 2024
work page 2024
-
[78]
MIRAGE- Bench: LLM Agent is Hallucinating and Where to Find Them
Weichen Zhang, Yiyou Sun, Pohao Huang, Jiayue Pu, Heyue Lin, and Dawn Song. MIRAGE- Bench: LLM Agent is Hallucinating and Where to Find Them. 7 2025
work page 2025
-
[79]
Is there a green ball in your current field of view?
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents. 4 2024. 15 A HALLUWORLDQualitative Examples A.1 HALLUWORLD-GRID Component Details World:P1 Dense ArrayGrid View (Canonical Locati...
work page 2024
-
[80]
Navigation activelyhelps state tracking in these domains
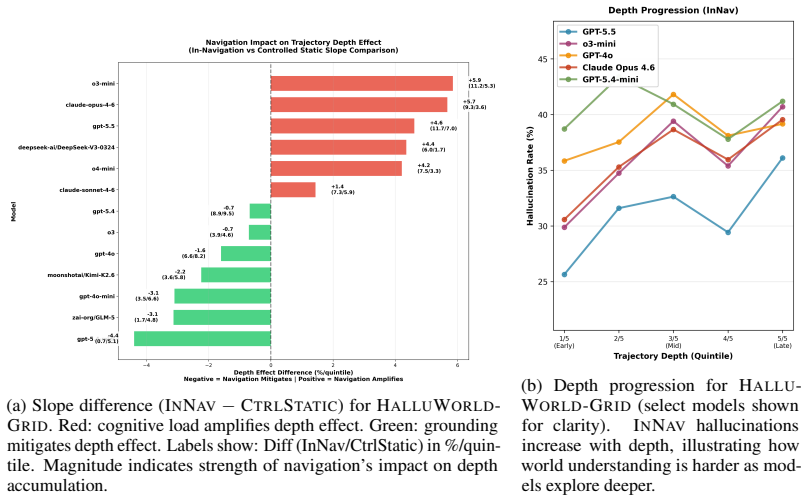
Grounding-dominated regimes(Perception, Causal): Negative slopes (-1.0% to -1.8% per quintile) indicate that additional observations provide more benefit (disambiguation of spatial/causal relationships) than cost (working memory load). Navigation activelyhelps state tracking in these domains. 2.Balanced regimes(Memory, Uncertainty): Near-zero slopes (+0.2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.