DEVIS-GRPO: Unleashing GRPO on Dynamic Extreme View Synthesis
Pith reviewed 2026-05-19 20:50 UTC · model grok-4.3
The pith
Accumulating small camera increments during sampling lets a policy-gradient model handle extreme-view video generation without paired large-motion training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
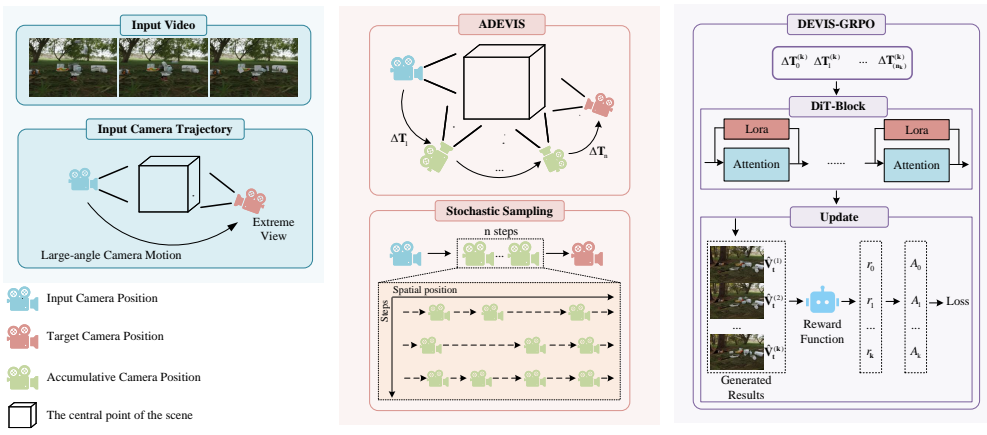
DEVIS-GRPO is presented as the first online policy gradient method for extreme view video generation. It centers on the Accumulative Dynamic Extreme View Synthesis (ADEVIS) sampling strategy that produces large-view camera motions by progressively accumulating small-view increments. The approach improves training efficiency by eliminating the requirement to collect expensive paired large-view videos for warm-starting and increases sampling diversity through flexible trajectory variation, all while using a multi-level consistency-quality reward function to guide optimization.
What carries the argument
The Accumulative Dynamic Extreme View Synthesis (ADEVIS) sampling strategy, which achieves large-view motions by progressively adding small-view camera increments rather than sampling full large motions directly.
If this is right
- Training no longer requires collection of expensive paired large-view videos for warm-starting the policy.
- Sampling diversity rises because trajectory configurations can be varied flexibly across increments.
- A multi-level reward selects high-quality samples for policy updates, supporting stable optimization.
- Reported metric gains include 21.57 percent relative PSNR improvement on Kubric-4D in non-occlusion regions.
Where Pith is reading between the lines
- The incremental accumulation idea could extend to other controllable generation settings that currently demand large-change paired data.
- Reducing annotation costs this way may make trajectory-controlled video models more practical for applications with limited labeled footage.
- Combining ADEVIS with alternative base generators or reward formulations offers a direct route for further performance checks.
Load-bearing premise
Progressively accumulating small-view increments reliably yields high-quality large-view motions and added sampling diversity without introducing artifacts that the multi-level reward cannot filter out.
What would settle it
A controlled comparison that trains one model with ADEVIS and a second model with directly collected paired large-view videos, then measures whether extreme-view output quality on held-out tests is statistically equivalent or better for the accumulative version.
Figures






read the original abstract
Trajectory-controlled video generation has become essential for controllable video generation. While current methods perform well under small-view camera motions, they degrade significantly with large-view motions. Existing solutions for extreme-view synthesis typically require dedicated video pairs, demanding substantial annotation effort. To address these limitations, we propose Dynamic Extreme VIew Synthesis-GRPO (DEVIS-GRPO), a GRPO-based framework for trajectory-controlled video generation, the first online policy gradient method for extreme view video generation. Central to our approach is a novel sampling strategy: Accumulative Dynamic Extreme VIew Synthesis (ADEVIS), which achieves large-view camera motions by progressively accumulating small-view increments. This method delivers two key advantages: 1) enhanced training efficiency, as it eliminates the need to warm-start the policy model by collecting expensive paired large-view videos, and 2) increased sampling diversity, achieved by flexibly varying trajectory configurations. Finally, we designed a multi-level consistency-quality reward function to select high-quality samples for model optimization. Experiments on the Kubric-4D, iPhone, and DL3DV datasets demonstrate our method's superiority. On Kubric-4D, we achieve relative improvements of 21.57% in PSNR and 7.31% in SSIM over the second-best method in non-occlusion areas. On iPhone, LPIPS is reduced by 18.56%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DEVIS-GRPO, a GRPO-based online policy gradient framework for trajectory-controlled video generation under extreme views. Its core innovation is the Accumulative Dynamic Extreme View Synthesis (ADEVIS) sampling strategy, which generates large camera motions by progressively summing small-view increments rather than requiring paired large-view training videos. A multi-level consistency-quality reward is used to filter samples for policy updates. Experiments report relative gains of 21.57% PSNR and 7.31% SSIM on Kubric-4D (non-occlusion areas), 18.56% LPIPS reduction on iPhone, and results on DL3DV.
Significance. If the central assumption holds—that ADEVIS accumulation plus the multi-level reward reliably yields artifact-free extreme-view trajectories without paired data—this would offer a practical efficiency gain for RL-based controllable video models by increasing sampling diversity and removing expensive data collection. The online GRPO formulation and incremental sampling are potentially reusable beyond the specific task.
major comments (3)
- [Abstract / ADEVIS sampling strategy] Abstract and ADEVIS description: The central claim that progressively accumulating small-view increments produces usable large-view motions without compounding geometric or photometric drift rests on the multi-level reward filtering such errors. However, the abstract provides no indication that the reward includes explicit long-range terms (e.g., accumulated optical-flow consistency or depth alignment over the full trajectory length), so it is unclear whether local per-frame penalties suffice to prevent the policy from being updated on subtly degraded long trajectories.
- [Experiments / Kubric-4D evaluation] Experiments section (Kubric-4D results): The reported 21.57% relative PSNR and 7.31% SSIM gains are presented without error bars, number of random seeds, or an ablation isolating the effect of accumulation steps versus reward weighting. This makes it difficult to determine whether the gains are robust or sensitive to post-hoc dataset or hyperparameter choices.
- [Method / Multi-level reward] Reward function design: The multi-level consistency-quality reward is asserted to select high-quality samples, yet no quantitative analysis is given on how reward scores correlate with accumulation length or on failure cases where drift occurs but is not penalized. Without this, the efficiency claim (no need for paired large-view data) remains under-supported.
minor comments (2)
- [Abstract and title] The acronym expansion 'Dynamic Extreme VIew Synthesis' contains an apparent capitalization/typo ('VIew' instead of 'View') that should be corrected for consistency.
- [Introduction] The claim of being 'the first online policy gradient method for extreme view video generation' requires explicit comparison to the most recent RL-for-video-generation works to avoid overstatement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, clarifying aspects of the method and indicating revisions that will be incorporated to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [Abstract / ADEVIS sampling strategy] Abstract and ADEVIS description: The central claim that progressively accumulating small-view increments produces usable large-view motions without compounding geometric or photometric drift rests on the multi-level reward filtering such errors. However, the abstract provides no indication that the reward includes explicit long-range terms (e.g., accumulated optical-flow consistency or depth alignment over the full trajectory length), so it is unclear whether local per-frame penalties suffice to prevent the policy from being updated on subtly degraded long trajectories.
Authors: We appreciate the referee highlighting the need for clearer linkage in the abstract. The ADEVIS strategy relies on incremental accumulation of small motions to limit per-step drift, with the multi-level reward (detailed in Section 3) applying consistency penalties at both local and accumulated scales, including cross-frame optical flow and depth coherence terms over the growing trajectory. Local penalties are thus augmented by these longer-range checks to filter degraded samples before policy updates. To improve clarity, we will revise the abstract to explicitly reference the long-range consistency components within the reward function. revision: yes
-
Referee: [Experiments / Kubric-4D evaluation] Experiments section (Kubric-4D results): The reported 21.57% relative PSNR and 7.31% SSIM gains are presented without error bars, number of random seeds, or an ablation isolating the effect of accumulation steps versus reward weighting. This makes it difficult to determine whether the gains are robust or sensitive to post-hoc dataset or hyperparameter choices.
Authors: We agree that additional statistical rigor and ablations would better demonstrate robustness. In the revised manuscript, we will report error bars as standard deviations computed over three independent random seeds for the Kubric-4D metrics. We will also add a dedicated ablation subsection that varies the number of accumulation steps in ADEVIS while holding reward weighting fixed (and vice versa) to isolate their individual contributions to the observed gains. revision: yes
-
Referee: [Method / Multi-level reward] Reward function design: The multi-level consistency-quality reward is asserted to select high-quality samples, yet no quantitative analysis is given on how reward scores correlate with accumulation length or on failure cases where drift occurs but is not penalized. Without this, the efficiency claim (no need for paired large-view data) remains under-supported.
Authors: This comment correctly identifies an opportunity to provide stronger empirical grounding for the reward's role. While the current experiments show end-to-end improvements without paired large-view data, we will enhance the Method and Experiments sections with a quantitative analysis: a table and plot correlating average reward scores against increasing accumulation lengths, plus a discussion of any detected failure modes where subtle drift evaded penalization. These additions will more directly support the efficiency advantage of the ADEVIS approach. revision: yes
Circularity Check
No circularity: empirical RL method with external dataset validation
full rationale
The paper proposes DEVIS-GRPO, a GRPO-based online policy gradient framework, with ADEVIS as a sampling strategy that accumulates small-view increments for large-view motions. This eliminates the need for paired large-view videos and is paired with a multi-level consistency-quality reward. Performance is demonstrated via experiments on independent external datasets (Kubric-4D, iPhone, DL3DV) with reported metrics such as 21.57% relative PSNR improvement. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations reduce the claimed advantages to the inputs by construction. The derivation is self-contained as a novel application of RL techniques evaluated against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Accumulating small-view increments produces valid large-view trajectories suitable for policy optimization without major quality loss.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Central to our approach is a novel sampling strategy: Accumulative Dynamic Extreme View Synthesis (ADEVIS), which achieves large-view camera motions by progressively accumulating small-view increments.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we designed a multi-level consistency-quality reward function to select high-quality samples for model optimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Vbench: Comprehensive benchmark suite for video generative models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[2]
Cami2v: Camera-controlled image-to-video diffusion model,
Cami2v: Camera-controlled image-to-video diffusion model , author =. arXiv preprint arXiv:2410.15957 , year =
-
[3]
Lindell and Sergey Tulyakov , booktitle =
Sherwin Bahmani and Ivan Skorokhodov and Aliaksandr Siarohin and Willi Menapace and Guocheng Qian and Michael Vasilkovsky and Hsin-Ying Lee and Chaoyang Wang and Jiaxu Zou and Andrea Tagliasacchi and David B. Lindell and Sergey Tulyakov , booktitle =. 2025 , url =
work page 2025
-
[4]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Cameractrl: Enabling camera control for text-to-video generation , author =. arXiv preprint arXiv:2404.02101 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Kubric: A scalable dataset generator , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[6]
British Journal of Surgery , volume =
Unreal Engine 5 and immersive surgical training: translating advances in gaming technology into extended-reality surgical simulation training programmes , author =. British Journal of Surgery , volume =. 2022 , publisher =
work page 2022
-
[7]
arXiv preprint arXiv:2405.04496 , year =
Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing , author =. arXiv preprint arXiv:2405.04496 , year =
-
[8]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Diffusion model alignment using direct preference optimization , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[10]
Advances in neural information processing systems , volume =
Direct preference optimization: Your language model is secretly a reward model , author =. Advances in neural information processing systems , volume =
-
[11]
Advances in Neural Information Processing Systems , volume =
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
The Twelfth International Conference on Learning Representations , year =
Training Diffusion Models with Reinforcement Learning , author =. The Twelfth International Conference on Learning Representations , year =
-
[13]
European Conference on Computer Vision , pages =
Grounding image matching in 3d with mast3r , author =. European Conference on Computer Vision , pages =. 2024 , organization =
work page 2024
-
[14]
The Twelfth International Conference on Learning Representations , year =
Real-time Photorealistic Dynamic Scene Representation and Rendering with 4D Gaussian Splatting , author =. The Twelfth International Conference on Learning Representations , year =
-
[15]
ACM SIGGRAPH 2024 Conference Papers , pages =
4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes , author =. ACM SIGGRAPH 2024 Conference Papers , pages =
work page 2024
-
[16]
IEEE Transactions on Geoscience and Remote Sensing , volume =
Robust instance-based semi-supervised learning change detection for remote sensing images , author =. IEEE Transactions on Geoscience and Remote Sensing , volume =. 2024 , publisher =
work page 2024
-
[17]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Matterport3d: Learning from rgb-d data in indoor environments , author =. arXiv preprint arXiv:1709.06158 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Look outside the room: Synthesizing a consistent long-term 3d scene video from a single image , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[19]
Advances in Neural Information Processing Systems , volume =
Collaborative video diffusion: Consistent multi-video generation with camera control , author =. Advances in Neural Information Processing Systems , volume =
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Yu, Mark and Hu, Wenbo and Xing, Jinbo and Shan, Ying , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[21]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning , author =. arXiv preprint arXiv:2307.04725 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
ACM SIGGRAPH 2024 Conference Papers , pages =
Motionctrl: A unified and flexible motion controller for video generation , author =. ACM SIGGRAPH 2024 Conference Papers , pages =
work page 2024
-
[23]
Advances in Neural Information Processing Systems , volume =
Epipolar-free 3d gaussian splatting for generalizable novel view synthesis , author =. Advances in Neural Information Processing Systems , volume =
-
[24]
Proceedings of the IEEE/CVF international conference on computer vision , pages =
Zero-1-to-3: Zero-shot one image to 3d object , author =. Proceedings of the IEEE/CVF international conference on computer vision , pages =
-
[25]
MVDream: Multi-view Diffusion for 3D Generation
Mvdream: Multi-view diffusion for 3d generation , author =. arXiv preprint arXiv:2308.16512 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Light-X: Generative 4D Video Rendering with Camera and Illumination Control , author =. arXiv preprint arXiv:2512.05115 , year =
-
[27]
3D Scene Prompting for Scene-Consistent Camera-Controllable Video Generation , author =. arXiv preprint arXiv:2510.14945 , year =
-
[28]
European Conference on Computer Vision , pages =
Generative camera dolly: Extreme monocular dynamic novel view synthesis , author =. European Conference on Computer Vision , pages =. 2024 , organization =
work page 2024
-
[29]
Zero4D: Training-Free 4D Video Generation From Single Video Using Off-the-Shelf Video Diffusion Model , author =. arXiv e-prints , pages =
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
Scannet: Richly-annotated 3d reconstructions of indoor scenes , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[31]
ACM Transactions on Graphics (ToG) , volume =
Tanks and temples: Benchmarking large-scale scene reconstruction , author =. ACM Transactions on Graphics (ToG) , volume =. 2017 , publisher =
work page 2017
-
[32]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Stereo magnification: Learning view synthesis using multiplane images , author =. arXiv preprint arXiv:1805.09817 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Bai, Jianhong and Xia, Menghan and Fu, Xiao and Wang, Xintao and Mu, Lianrui and Cao, Jinwen and Liu, Zuozhu and Hu, Haoji and Bai, Xiang and Wan, Pengfei and Zhang, Di , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[34]
3D Gaussian splatting for real-time radiance field rendering. , author =. ACM Trans. Graph. , volume =
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
UniDepth: Universal monocular metric depth estimation , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Depth anything: Unleashing the power of large-scale unlabeled data , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[37]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Met3r: Measuring multi-view consistency in generated images , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[38]
EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh , author =. arXiv preprint arXiv:2506.05554 , year =
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[40]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[41]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Vggt: Visual geometry grounded transformer , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[42]
GAIA-1: A Generative World Model for Autonomous Driving
Gaia-1: A generative world model for autonomous driving , author =. arXiv preprint arXiv:2309.17080 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
European Conference on Computer Vision , pages =
Waymo open dataset: Panoramic video panoptic segmentation , author =. European Conference on Computer Vision , pages =. 2022 , organization =
work page 2022
-
[44]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Videocrafter1: Open diffusion models for high-quality video generation , author =. arXiv preprint arXiv:2310.19512 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
SIGGRAPH Asia 2024 Conference Papers , pages =
Lumiere: A space-time diffusion model for video generation , author =. SIGGRAPH Asia 2024 Conference Papers , pages =
work page 2024
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
4d gaussian splatting for real-time dynamic scene rendering , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[47]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
D-nerf: Neural radiance fields for dynamic scenes , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[48]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Mip-nerf 360: Unbounded anti-aliased neural radiance fields , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[49]
ACM transactions on graphics (TOG) , volume =
Instant neural graphics primitives with a multiresolution hash encoding , author =. ACM transactions on graphics (TOG) , volume =. 2022 , publisher =
work page 2022
-
[50]
Communications of the ACM , volume =
Nerf: Representing scenes as neural radiance fields for view synthesis , author =. Communications of the ACM , volume =. 2021 , publisher =
work page 2021
-
[51]
Forty-second International Conference on Machine Learning , year =
WorldSimBench: Towards Video Generation Models as World Simulators , author =. Forty-second International Conference on Machine Learning , year =
-
[52]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets , author =. arXiv preprint arXiv:2311.15127 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
High-resolution image synthesis with latent diffusion models , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[54]
Advances in neural information processing systems , volume =
Denoising diffusion probabilistic models , author =. Advances in neural information processing systems , volume =
-
[55]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora: A review on background, technology, limitations, and opportunities of large vision models , author =. arXiv preprint arXiv:2402.17177 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Gen3c: 3d-informed world-consistent video generation with precise camera control , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[57]
Follow-Your-Creation: Empowering 4D Creation through Video Inpainting , author =. arXiv preprint arXiv:2506.04590 , year =
-
[58]
Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
Trajectory attention for fine-grained video motion control , author =. arXiv preprint arXiv:2411.19324 , year =
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Shape of motion: 4d reconstruction from a single video , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[60]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis , year =
Yu, Wangbo and Xing, Jinbo and Yuan, Li and Hu, Wenbo and Li, Xiaoyu and Huang, Zhipeng and Gao, Xiangjun and Wong, Tien-Tsin and Shan, Ying and Tian, Yonghong , journal =. ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis , year =
-
[61]
Sv4d: Dy- namic 3d content generation with multi-frame and multi-view consistency
Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency , author =. arXiv preprint arXiv:2407.17470 , year =
-
[62]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author =. arXiv preprint arXiv:2402.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Rlaif: Scaling reinforcement learning from human feedback with ai feedback , author =
-
[64]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author =. arXiv preprint arXiv:2501.12948 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Advances in Neural Information Processing Systems , volume =
Imagereward: Learning and evaluating human preferences for text-to-image generation , author =. Advances in Neural Information Processing Systems , volume =
-
[66]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Depthcrafter: Generating consistent long depth sequences for open-world videos , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Video depth anything: Consistent depth estimation for super-long videos , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[68]
Advances in Neural Information Processing Systems , volume =
Monocular dynamic view synthesis: A reality check , author =. Advances in Neural Information Processing Systems , volume =
-
[69]
Jie Liu and Gongye Liu and Jiajun Liang and Yangguang Li and Jiaheng Liu and Xintao Wang and Pengfei Wan and Di ZHANG and Wanli Ouyang , booktitle =. Flow-. 2025 , url =
work page 2025
-
[70]
DanceGRPO: Unleashing GRPO on Visual Generation
DanceGRPO: Unleashing GRPO on Visual Generation , author =. arXiv preprint arXiv:2505.07818 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
The unreasonable effectiveness of deep features as a perceptual metric , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[72]
Aligning Text-to-Image Models using Human Feedback
Aligning text-to-image models using human feedback , author =. arXiv preprint arXiv:2302.12192 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
The Thirteenth International Conference on Learning Representations , year =
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author =. The Thirteenth International Conference on Learning Representations , year =
-
[75]
Advances in neural information processing systems , volume =
Training language models to follow instructions with human feedback , author =. Advances in neural information processing systems , volume =
-
[76]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Dust3r: Geometric 3d vision made easy , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[77]
Lora: Low-rank adaptation of large language models. , author =. ICLR , volume =
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Depthsplat: Connecting gaussian splatting and depth , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.