Are Performance-Optimization Benchmarks Reliably Measuring Coding Agents?
Pith reviewed 2026-07-02 08:01 UTC · model grok-4.3
The pith
Leaderboard scores on GSO, SWE-Perf and SWE-fficiency mix machine-dependent instability, scoring-rule choices, and already-solved tasks, so they do not reliably track coding-agent progress.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
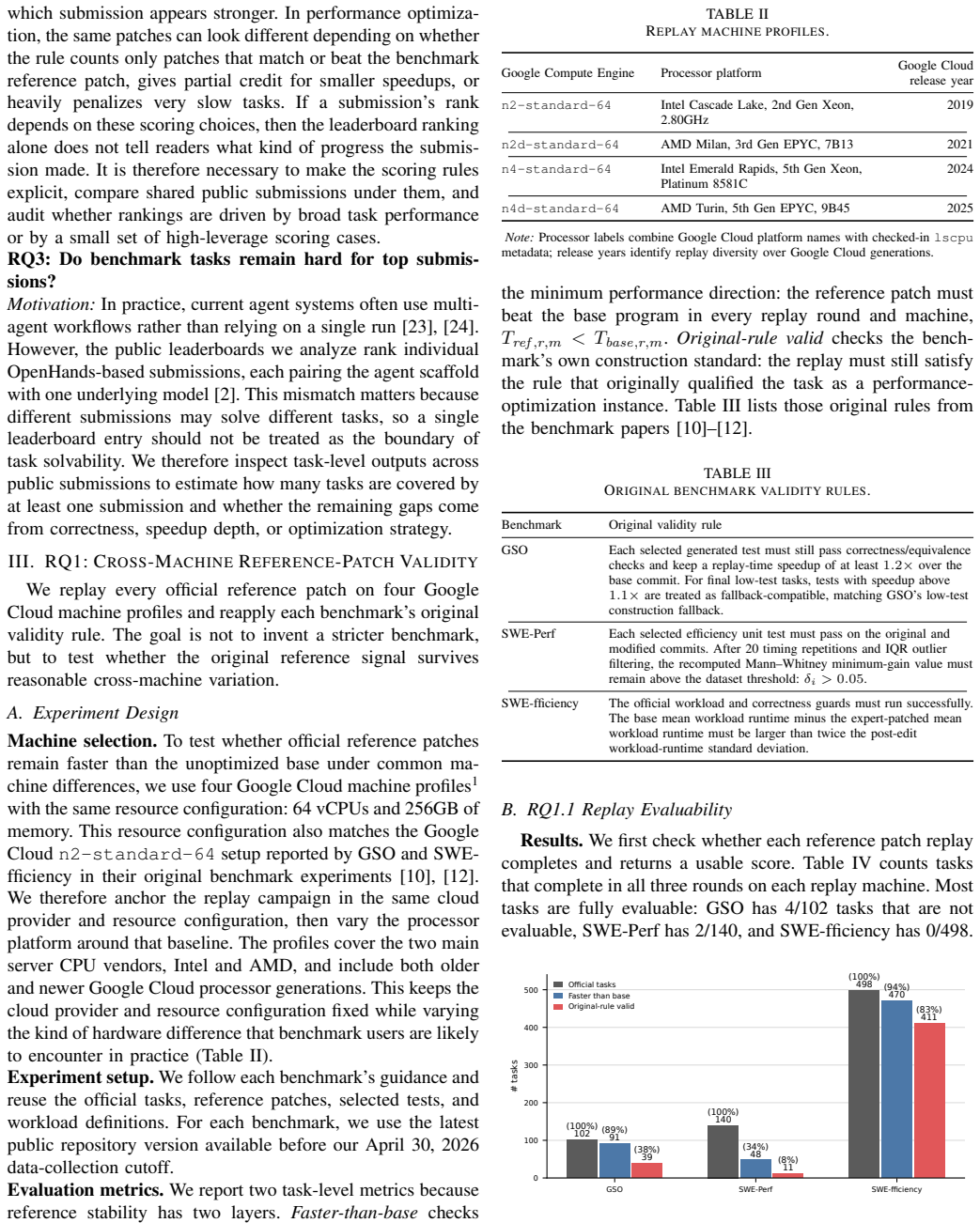
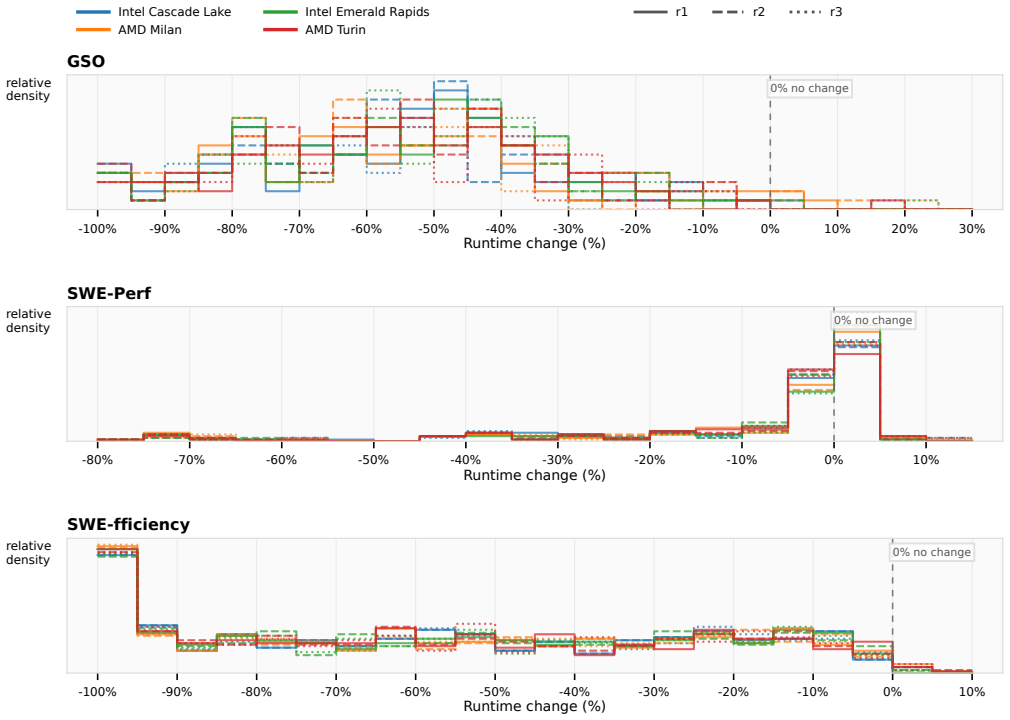
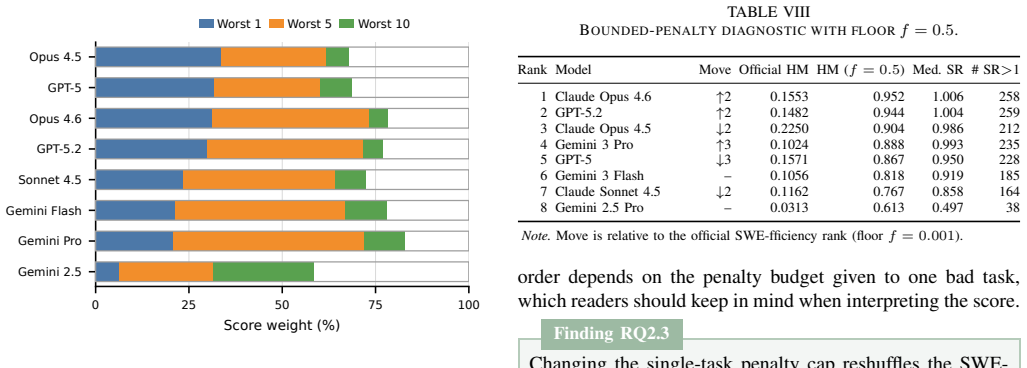
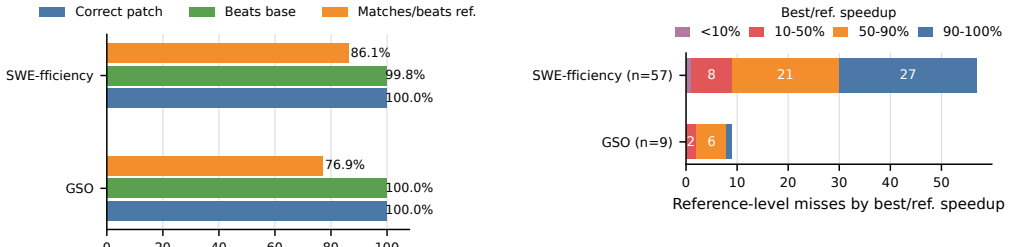
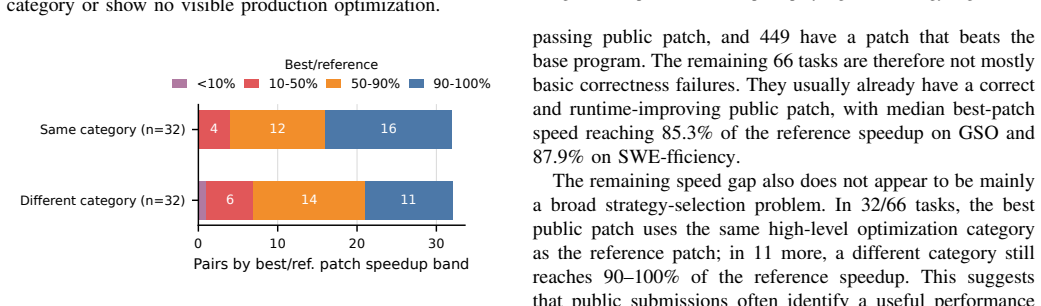
The authors replay reference patches for 740 tasks across machines and find they satisfy original validity rules in every replay for only 39/102 GSO tasks, 11/140 SWE-Perf tasks, and 411/498 SWE-fficiency tasks. Among eight shared public submissions, official rankings disagree on 9 of 28 pairwise comparisons, and one scoring rule assigns the worst ten tasks weights of 58.5-82.8 percent. At least one public submission matches or beats the reference on 85.3 percent of replay-valid tasks and beats the unoptimized base on 99.8 percent.
What carries the argument
Cross-machine replay of reference patches combined with per-task comparison of public submissions against benchmark validity rules and scoring weights.
If this is right
- Benchmark scores can change when the same patches are evaluated on different hardware.
- The choice of scoring rule can reverse the relative ranking of two submissions.
- Aggregate leaderboards conceal that public submissions already cover most tasks.
- Tasks whose reference patches are stable across machines provide clearer performance signals.
Where Pith is reading between the lines
- Future benchmarks could weight tasks by cross-machine stability to reduce noise.
- Per-task score contributions should be reported alongside aggregate rankings.
- The remaining unsolved tasks after public submissions form a narrower but more meaningful test set.
- Runtime variability observed here may also affect other execution-based coding benchmarks.
Load-bearing premise
Benchmark validity rules for runtime improvement and correctness are meant to produce consistent outcomes across different machine types.
What would settle it
Replaying all reference patches on the same four machine types and observing that every task satisfies the original validity rules in all replays would challenge the claim of widespread fragility.
Figures

read the original abstract
Repository-level performance-optimization benchmarks such as GSO, SWE-Perf and SWE-fficiency evaluate coding agents by applying patches to real repositories and comparing runtime against unoptimized baselines and official reference patches. Their leaderboard scores are increasingly used as evidence of coding-agent progress, but those scores can conflate runtime instability, benchmark-specific scoring rules, and how many tasks are already solved by at least one public submission. We audit these issues across the three benchmarks. First, we replay the official reference patches for 740 code optimization tasks across four common types of Google Cloud machines. Most benchmark tasks can be replayed, but their reference patches satisfy the original benchmark validity rules in every cross-machine replay for only 39/102 GSO tasks, 11/140 SWE-Perf tasks, and 411/498 SWE-fficiency tasks; SWE-Perf is especially fragile because many reference patches produce close-to-zero runtime changes. Second, we show that public submission rankings depend strongly on the benchmark scoring rule. Among eight public submissions shared by GSO and SWE-fficiency, the official rankings disagree on 9 of 28 pairwise submission comparisons, and SWE-fficiency's leaderboard scoring rule assigns the worst ten tasks overly high score weights of 58.5%-82.8%. Third, looking across 10 public submissions for each task, we find that at least one submission matches or beats the reference patch on 85.3% (384/450) of replay-valid GSO and SWE-fficiency tasks, and beats the unoptimized base code on 99.8% (449/450). Our study complements leaderboard scores by identifying tasks with more reliable performance signals, quantifying per-task score contributions, and exposing the remaining performance gaps that are hidden by aggregate rankings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits three performance-optimization benchmarks (GSO, SWE-Perf, SWE-fficiency) for coding agents. It claims their leaderboards are unreliable because scores conflate runtime instability across machines, benchmark-specific scoring rules, and the fraction of tasks already solved by public submissions. Evidence includes replaying reference patches on 740 tasks across four Google Cloud machine types (with only 39/102 GSO, 11/140 SWE-Perf, and 411/498 SWE-fficiency tasks satisfying validity rules consistently), showing that scoring rules cause ranking disagreements on 9 of 28 pairwise comparisons among eight shared submissions, and finding that at least one of 10 public submissions matches or beats the reference on 85.3% (384/450) of replay-valid tasks while beating the base on 99.8%.
Significance. If the empirical findings hold, the work is significant for AI-assisted software engineering because these benchmarks are increasingly used to measure coding-agent progress; the concrete replay counts, per-benchmark consistency rates, and task-level analysis of already-solved tasks provide actionable data for improving benchmark design. The large-scale replay (740 tasks, four machine types) and use of public submissions constitute a strength, offering falsifiable, quantitative observations rather than purely theoretical critique.
major comments (2)
- [Replay experiment (abstract and first results section)] The central claim that cross-machine replay failures demonstrate benchmark unreliability assumes validity rules (runtime improvement thresholds and correctness checks) are intended to be machine-invariant. The manuscript does not report checking the original GSO/SWE-Perf/SWE-fficiency papers or repositories for specified hardware/OS requirements; if standardized environments are assumed (as is common for performance benchmarks), the observed deviations on Google Cloud machines may reflect non-standard replay conditions rather than inherent fragility.
- [Public submission analysis (abstract and third results section)] The finding that public submissions match or beat the reference on 85.3% (384/450) of replay-valid tasks relies on analyzing 10 submissions per task. The manuscript should clarify selection criteria for these submissions (all available vs. sample) and the exact definition of 'matches or beats' (e.g., within the benchmark's improvement threshold or strict equality), as this directly supports the claim that leaderboards hide already-solved tasks.
minor comments (1)
- A summary table listing per-benchmark task counts, replay success rates, and consistency fractions (102/140/498 tasks; 39/11/411 consistent) would improve clarity of the key quantitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key assumptions in our replay experiments and public-submission analysis. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Replay experiment (abstract and first results section)] The central claim that cross-machine replay failures demonstrate benchmark unreliability assumes validity rules (runtime improvement thresholds and correctness checks) are intended to be machine-invariant. The manuscript does not report checking the original GSO/SWE-Perf/SWE-fficiency papers or repositories for specified hardware/OS requirements; if standardized environments are assumed (as is common for performance benchmarks), the observed deviations on Google Cloud machines may reflect non-standard replay conditions rather than inherent fragility.
Authors: We appreciate this point. We reviewed the original GSO, SWE-Perf, and SWE-fficiency papers and repositories prior to our experiments; none specify particular hardware configurations, CPU models, or OS versions beyond generic Linux-based requirements for repository execution. Validity rules are defined solely via runtime deltas and correctness checks without machine-specific clauses. Our four Google Cloud machine types are representative of standard cloud environments used for such benchmarks. We will add an explicit paragraph in the Methods section documenting this review of the original specifications and our rationale for the chosen environments. This addition directly addresses the concern and reinforces that the inconsistencies reflect benchmark fragility. revision: yes
-
Referee: [Public submission analysis (abstract and third results section)] The finding that public submissions match or beats the reference on 85.3% (384/450) of replay-valid tasks relies on analyzing 10 submissions per task. The manuscript should clarify selection criteria for these submissions (all available vs. sample) and the exact definition of 'matches or beats' (e.g., within the benchmark's improvement threshold or strict equality), as this directly supports the claim that leaderboards hide already-solved tasks.
Authors: We agree that these details require explicit clarification. The 10 submissions per task were the top 10 publicly available submissions on the respective leaderboards at the time of data collection (i.e., all qualifying top submissions, not a sample). 'Matches or beats' is defined using each benchmark's own scoring rule: a submission achieves a score greater than or equal to the reference patch when its runtime improvement meets or exceeds the reference under the benchmark's validity threshold. We will revise the third results section (and the corresponding methods paragraph) to state the selection criteria and scoring definition verbatim. This change will be included in the revised manuscript. revision: yes
Circularity Check
Empirical audit with no derivation chain
full rationale
The paper conducts a direct empirical audit: it replays reference patches on multiple machine types, counts how often they satisfy original validity rules, compares public submission rankings under different scoring rules, and tallies how many tasks are already solved by public submissions. No equations, fitted parameters, ansatzes, uniqueness theorems, or self-citations are used to derive any central result. All reported numbers (e.g., 39/102, 85.3%) are raw counts or direct comparisons from the replay data and public submissions. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark validity rules (runtime thresholds and correctness checks) are intended to be machine-independent.
Reference graph
Works this paper leans on
-
[1]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 50 528–50 652
2024
-
[2]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “OpenHands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Le...
2025
-
[3]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA ’24. ACM, September 2024, pp. 1592–1604. [Online]. Available: http://dx.doi.org/10.1145/3650212.3680384
-
[4]
Learning performance-improving code edits,
A. G. Shypula, A. Madaan, Y . Zeng, U. Alon, J. R. Gardner, Y . Yang, M. Hashemi, G. Neubig, P. Ranganathan, O. Bastani, and A. Yazdan- bakhsh, “Learning performance-improving code edits,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[5]
EffiBench: Bench- marking the efficiency of automatically generated code,
D. Huang, Y . Qing, W. Shang, H. Cui, and J. Zhang, “EffiBench: Bench- marking the efficiency of automatically generated code,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 11 506–11 544
2024
-
[6]
Mercury: A code efficiency benchmark for code large language models,
M. Du, L. A. Tuan, B. Ji, Q. Liu, and S.-K. Ng, “Mercury: A code efficiency benchmark for code large language models,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 16 601–16 622
2024
-
[7]
COFFE: A code efficiency benchmark for code generation,
Y . Peng, J. Wan, Y . Li, and X. Ren, “COFFE: A code efficiency benchmark for code generation,”Proc. ACM Softw. Eng., vol. 2, no. FSE, pp. 242–265, 2025
2025
-
[8]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program synthesis with large language models,” 2021. [Online]. Available: https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Competition-level code generation with alphacode,
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. Sutherland Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition-level ...
-
[10]
GSO: Challenging software optimization tasks for evaluating SWE- agents,
M. Shetty, N. Jain, J. Liu, V . Kethanaboyina, K. Sen, and I. Stoica, “GSO: Challenging software optimization tasks for evaluating SWE- agents,” inAdvances in Neural Information Processing Systems, D. Bel- grave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, Eds., vol. 38. Curran Associates, Inc., 2025
2025
-
[11]
Swe-perf: Can language models optimize code performance on real-world repositories?
X. He, Q. Liu, M. Du, L. Yan, Z. Fan, Y . Huang, Z. Yuan, and Z. Ma, “Swe-perf: Can language models optimize code performance on real-world repositories?” inForty-third International Conference on Machine Learning, 2026. [Online]. Available: https: //openreview.net/forum?id=pNxw4i5Dp2
2026
-
[12]
Swe-fficiency: Can language models optimize real-world repositories on real workloads?
J. J. Ma, M. Hashemi, A. Yazdanbakhsh, K. Swersky, O. Press, E. Li, V . J. Reddi, and P. Ranganathan, “Swe-fficiency: Can language models optimize real-world repositories on real workloads?” inForty- third International Conference on Machine Learning, 2026. [Online]. Available: https://openreview.net/forum?id=J1lgJyP4Tm
2026
-
[13]
Swe-bench: Can language models resolve real- world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench: Can language models resolve real- world github issues?” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[14]
Statistically rigorous java performance evaluation,
A. Georges, D. Buytaert, and L. Eeckhout, “Statistically rigorous java performance evaluation,” inProceedings of the 22nd annual ACM SIGPLAN conference on Object-oriented programming systems, languages and applications, ser. OOPSLA07. ACM, Oct. 2007, pp. 57–76. [Online]. Available: http://dx.doi.org/10.1145/1297027.1297033
-
[15]
Producing wrong data without doing anything obviously wrong!
T. Mytkowicz, A. Diwan, M. Hauswirth, and P. F. Sweeney, “Producing wrong data without doing anything obviously wrong!” inProceedings of the 14th international conference on Architectural support for programming languages and operating systems, ser. ASPLOS09. ACM, Mar. 2009, pp. 265–276. [Online]. Available: http://dx.doi.org/10.1145/1508244.1508275
-
[16]
Rigorous benchmarking in reasonable time,
T. Kalibera and R. Jones, “Rigorous benchmarking in reasonable time,” inProceedings of the 2013 international symposium on memory man- agement, ser. ISMM ’13. ACM, June 2013, pp. 63–74
2013
-
[17]
Large language model-based agents for software engineering: A survey,
J. Liu, K. Wang, Y . Chen, X. Peng, Z. Chen, L. Zhang, and Y . Lou, “Large language model-based agents for software engineering: A survey,”ACM Transactions on Software Engineering and Methodology, Mar. 2026. [Online]. Available: http://dx.doi.org/10.1145/3796507
-
[18]
Agents in software engineering: survey, landscape, and vision,
Y . Wang, W. Zhong, Y . Huang, E. Shi, M. Yang, J. Chen, H. Li, Y . Ma, Q. Wang, and Z. Zheng, “Agents in software engineering: survey, landscape, and vision,”Automated Software Engineering, vol. 32, no. 2, Aug. 2025. [Online]. Available: http://dx.doi.org/10.1007/s10515-025-00544-2
-
[19]
Z. Chen and L. Jiang, “Evaluating software development agents: Patch patterns, code quality, and issue complexity in real-world github scenarios,” in2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, Mar. 2025, pp. 657–668. [Online]. Available: http://dx.doi.org/10.1109/SANER64 311.2025.00068
-
[20]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-V...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Codegen: An open large language model for code with multi-turn program synthesis,
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y . Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=iaYcJKpY2B
2023
-
[22]
Code Llama: Open Foundation Models for Code
B. Rozi `ere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. D ´efossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, and G. Synnaeve, “Code llama: Open foundation models for code,” 20...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 68 5...
2023
-
[24]
Autogen: Enabling next-gen llm applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “Autogen: Enabling next-gen llm applications via multi-agent conversation,” inFirst Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=BAakY1hNKS
2024
-
[25]
P. S. Bullen,Handbook of Means and Their Inequalities. Springer Netherlands, 2003. [Online]. Available: http://dx.doi.org/10.1007/978-9 4-017-0399-4
-
[26]
The arithmetic mean - geometric mean - harmonic mean: Inequalities and a spectrum of applications,
P. De, “The arithmetic mean - geometric mean - harmonic mean: Inequalities and a spectrum of applications,”Resonance, vol. 21, no. 12, pp. 1119–1133, Dec. 2016. [Online]. Available: http://dx.doi.org/10.1007/s12045-016-0423-4
-
[27]
The American Journal of Psychology , author =
C. Spearman, “The proof and measurement of association between two 11 things,”The American Journal of Psychology, vol. 15, no. 1, p. 72, Jan. 1904. [Online]. Available: http://dx.doi.org/10.2307/1412159
-
[28]
A new measure of rank correlation,
M. G. KENDALL, “A new measure of rank correlation,”Biometrika, vol. 30, no. 1-2, pp. 81–93, Jun. 1938. [Online]. Available: http://dx.doi.org/10.1093/biomet/30.1-2.81
-
[29]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[30]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 11 809–11 822. [Online]. Availab...
2023
-
[31]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 8634–8652. [Online]. Available: https://proceedings.neurip...
2023
-
[32]
Sysllmatic: Large language models are software system optimizers,
H. Peng, A. Gupte, R. Hasler, N. J. Eliopoulos, C.-C. Ho, R. Mantri, L. Deng, K. L ¨aufer, G. K. Thiruvathukal, and J. C. Davis, “Sysllmatic: Large language models are software system optimizers,”Journal of Systems and Software, vol. 240, p. 112929, Oct. 2026. [Online]. Available: http://dx.doi.org/10.1016/j.jss.2026.112929
-
[33]
How do agents perform code optimization? an empirical study,
H. Peng, A. Zhong, R. A. C. M ´endez, K. G. Kalu, and J. C. Davis, “How do agents perform code optimization? an empirical study,” 2025, accepted to MSR ’26: Proceedings of the 23rd International Conference on Mining Software Repositories. [Online]. Available: https://arxiv.org/abs/2512.21757
-
[34]
Reinforcement learning foundations for deep research systems: A survey,
W. Li, Z. Chen, J. Lin, H. Cao, W. Han, S. Liang, Z. Zhang, K. Dong, D. Li, C. Zhang, and Y . Liu, “Reinforcement learning foundations for deep research systems: A survey,” 2025. [Online]. Available: https://arxiv.org/abs/2509.06733
-
[35]
W. Ma, Y . Li, Z. Chen, Y . Liu, L. Jiang, Q. Hu, and J. Tao,AgentGuard: An Active Threat Discovery System for Package Confusion Using Multi- Agent Collaboration. Springer Nature Singapore, 2026, pp. 69–83. [Online]. Available: http://dx.doi.org/10.1007/978-981-95-7820-7 5
-
[36]
Executing as You Generate: Hiding Execution Latency in LLM Code Interpreters
Z. Sun, Z. Lin, Z. Chen, C. Yang, M. Zhou, L. Li, and D. Lo, “Executing as you generate: Hiding execution latency in llm code interpreters,” 2026. [Online]. Available: https://arxiv.org/abs/2604.00491
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
How efficient is LLM-generated code? a rigorous & high-standard benchmark,
R. Qiu, W. W. Zeng, J. Ezick, C. Lott, and H. Tong, “How efficient is LLM-generated code? a rigorous & high-standard benchmark,” in The Thirteenth International Conference on Learning Representations,
-
[38]
Available: https://openreview.net/forum?id=suz4utPr9Y
[Online]. Available: https://openreview.net/forum?id=suz4utPr9Y
-
[39]
ECCO: Can we improve model-generated code efficiency without sacrificing functional correctness?
S. Waghjale, V . Veerendranath, Z. Wang, and D. Fried, “ECCO: Can we improve model-generated code efficiency without sacrificing functional correctness?” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, ...
2024
-
[40]
Evaluating language models for efficient code generation,
J. Liu, S. Xie, J. Wang, Y . Wei, Y . Ding, and L. Zhang, “Evaluating language models for efficient code generation,” in First Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=IBCBMeAhmC
2024
-
[41]
C. Yang, H. J. Kang, J. Shi, and D. Lo, “ACECode: A reinforcement learning framework for aligning code efficiency and correctness in code language models,” 2024. [Online]. Available: https://arxiv.org/abs/2412.17264
-
[42]
Mutation-guided llm-based test generation at meta,
M. Harman, J. Ritchey, I. Harper, S. Sengupta, K. Mao, A. Gulati, C. Foster, and H. Robert, “Mutation-guided llm-based test generation at meta,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’25. ACM, June 2025, pp. 180–191
2025
-
[43]
EffiBench- X: A multi-language benchmark for measuring efficiency of LLM- generated code,
Y . Qing, B. Zhu, M. Du, Z. Guo, T. Y . Zhuo, Q. Zhang, J. M. Zhang, H. Cui, S.-M. Yiu, D. Huang, S.-K. Ng, and A. T. Luu, “EffiBench- X: A multi-language benchmark for measuring efficiency of LLM- generated code,” inAdvances in Neural Information Processing Systems, D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, Eds., vo...
2025
-
[44]
KernelBench: Can LLMs write efficient GPU kernels?
A. Ouyang, S. Guo, S. Arora, A. L. Zhang, W. Hu, C. Re, and A. Mirhoseini, “KernelBench: Can LLMs write efficient GPU kernels?” inProceedings of the 42nd International Conference on Machine Learn- ing, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, Eds., vol...
2025
-
[45]
AlgoTune: Can language models speed up general-purpose numerical programs?
O. Press, B. Amos, H. Zhao, Y . Wu, S. K. Ainsworth, D. Krupke, P. Kidger, T. Sajed, B. Stellato, J. Park, N. Bosch, E. Meril, A. Steppi, A. Zharmagambetov, F. Zhang, D. P´erez-Pi˜neiro, A. Mercurio, N. Zhan, T. Abramovich, K. Lieret, H. Zhang, S. Huang, M. Bethge, and O. Press, “AlgoTune: Can language models speed up general-purpose numerical programs?” ...
2025
-
[46]
PerfCodeBench: Benchmarking LLMs for System-Level High-Performance Code Optimization
H. Jing, W. Hu, H. Shi, H. Yang, S. Zhang, S. Chen, H. Li, and Y . Song, “PerfCodeBench: Benchmarking LLMs for system- level high-performance code optimization,” 2026. [Online]. Available: https://arxiv.org/abs/2605.15222
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
PerfBench: Can agents resolve real-world performance bugs?
S. Garg, R. Z. Moghaddam, and N. Sundaresan, “PerfBench: Can agents resolve real-world performance bugs?” inProceedings of the 2026 International Workshop on Agentic Engineering, ser. AGENT ’26. ACM, Apr. 2026, pp. 165–172
2026
-
[48]
PEACE: Towards efficient project-level efficiency optimization via hybrid code editing,
X. Ren, J. Wan, Y . Peng, Z. Liu, M. Liang, D. Chen, W. Jiang, and Y . Li, “PEACE: Towards efficient project-level efficiency optimization via hybrid code editing,” in40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025. IEEE, 2025, pp. 1831–1843
2025
-
[49]
ISO-bench: Can coding agents optimize real-world inference workloads?
A. Nangia, S. Mishra, A. Gokrani, and P. Chopra, “ISO-bench: Can coding agents optimize real-world inference workloads?” inVerifAI-2: The Second Workshop on AI Verification in the Wild, 2026. [Online]. Available: https://openreview.net/forum?id=gPfqEnaKCy
2026
-
[50]
FormulaCode: Evaluating agentic optimization on large codebases,
A. Sehgal, J. Hou, A. Sarkar, I. Mantripragada, S. Chaudhuri, J. J. Sun, and Y . Yue, “FormulaCode: Evaluating agentic optimization on large codebases,” inForty-third International Conference on Machine Learning, 2026. [Online]. Available: https://openreview.net/forum?id= W ArbqRUsAe
2026
-
[51]
CppPerf: An Automated Pipeline and Dataset for Performance-Improving C++ Commits
T. Ho, K. Etemadi, and Z. Su, “CppPerf: An automated pipeline and dataset for performance-improving C++ commits,” 2026. [Online]. Available: https://arxiv.org/abs/2605.10890
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Large language models for software engineering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engineering: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 8, pp. 1–79, Nov
-
[53]
Available: http://dx.doi.org/10.1145/3695988
[Online]. Available: http://dx.doi.org/10.1145/3695988
-
[54]
Large language models for software engineering: Survey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Survey and open problems,” in2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, May 2023, pp. 31–53. [Online]. Available: http://dx.doi.org/10.1109/ICSE-FoSE5934...
-
[55]
A survey on large language models for software engineering,
Q. Zhang, C. Fang, Y . Xie, Y . Zhang, S. Yu, W. Sun, Y . Yang, and Z. Chen, “A survey on large language models for software engineering,”Science China Information Sciences, vol. 69, no. 4, Mar
-
[56]
Available: http://dx.doi.org/10.1007/s11432-025-4670-0 12
[Online]. Available: http://dx.doi.org/10.1007/s11432-025-4670-0 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.