NaturalFlow: Reducing Disruptive Pauses for Natural Speech Flow in Simultaneous Speech-to-Speech Translation
Pith reviewed 2026-06-27 06:58 UTC · model grok-4.3
The pith
A fluency-aware optimization framework reduces inter-chunk silences in simultaneous speech-to-speech translation by using internal linguistic and temporal signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The fluency-aware optimization framework minimizes inter-chunk silences by leveraging model-internal signals, including linguistic diversity and induced temporal variability in speech durations, and thereby produces natural speech flow on short- and long-form benchmarks while maintaining competitive latency and translation quality.
What carries the argument
fluency-aware optimization framework that selects chunk timing from linguistic diversity and temporal variability signals to reduce inter-chunk silences
If this is right
- Simultaneous translation can achieve acoustic flow closer to consecutive translation.
- Listeners encounter fewer disruptive pauses during real-time communication.
- Latency and translation quality stay competitive on both short and long inputs.
- The same internal signals can guide timing decisions across different speech lengths.
Where Pith is reading between the lines
- The timing logic could transfer to other streaming language tasks such as live captioning.
- Lower pause rates may reduce listener fatigue in multilingual meetings or broadcasts.
- Systems could adapt chunk boundaries on the fly using only signals already present in the model.
Load-bearing premise
Linguistic diversity and induced temporal variability in speech durations provide reliable signals for choosing chunk timing that produces natural flow without extra training or external data.
What would settle it
Applying the framework to the reported benchmarks and measuring no reduction in inter-chunk silences, or a rise in latency or drop in quality, would falsify the central claim.
Figures


read the original abstract
Simultaneous speech-to-speech translation aims to enable near-real-time communication by minimizing latency, offering a compelling, real-time alternative to the high latency of consecutive translation. However, the excessive pursuit of low latency often results in fragmented chunk-wise speech. Consequently, listeners are subjected to an unnatural acoustic flow punctuated by frequent pauses, which could increase their cognitive load. To bridge this gap, we introduce a fluency-aware optimization framework designed to discover the sweet spot between the low-latency benefits of simultaneous translation and the natural flow of consecutive translation. Our framework minimizes inter-chunk silences by leveraging model-internal signals, including linguistic diversity and induced temporal variability in speech durations. Experiments on short- and long-form benchmarks show that our framework produces natural speech flow while maintaining competitive latency and translation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NaturalFlow, a fluency-aware optimization framework for simultaneous speech-to-speech translation. It claims to minimize inter-chunk silences by leveraging model-internal signals (linguistic diversity and induced temporal variability in speech durations) to achieve a balance between low latency and natural acoustic flow, with experiments on short- and long-form benchmarks showing natural speech flow while maintaining competitive latency and translation quality.
Significance. If the central claims hold with rigorous evidence, the work could meaningfully improve user experience in real-time translation by addressing fragmented speech output, a common drawback of latency-focused simultaneous systems. The emphasis on internal signals without additional training or external data represents a potentially efficient direction, but the absence of any methodology, results, or analysis in the provided text makes it impossible to gauge actual significance or novelty relative to existing chunking and latency-quality trade-off methods.
major comments (1)
- [Abstract] Abstract: No methodology details, quantitative results, error analysis, or description of the optimization procedure, signals, or benchmarks are provided. This prevents any assessment of whether the experiments support the claims about natural flow, latency, and quality, rendering the central contribution unverifiable from the manuscript as presented.
Simulated Author's Rebuttal
We thank the referee for their review. The central concern is that the abstract lacks sufficient methodological and empirical detail to allow verification of the claims. We address this directly below and agree that the abstract can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: No methodology details, quantitative results, error analysis, or description of the optimization procedure, signals, or benchmarks are provided. This prevents any assessment of whether the experiments support the claims about natural flow, latency, and quality, rendering the central contribution unverifiable from the manuscript as presented.
Authors: We agree that the current abstract is too high-level and does not include enough concrete information on the optimization procedure, the model-internal signals (linguistic diversity and induced temporal variability), the benchmarks, or quantitative outcomes. In the revised version we will expand the abstract to briefly describe the fluency-aware optimization framework, the two internal signals leveraged, the short- and long-form evaluation settings, and the main reported trade-offs between latency, translation quality, and inter-chunk silence reduction. This change will make the central claims more directly verifiable from the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and available description present a high-level framework that optimizes chunk timing using model-internal signals (linguistic diversity and temporal variability) and reports empirical results on benchmarks. No equations, derivations, or self-citations are provided that reduce any claimed prediction or result to a fitted input or prior self-citation by construction. The central claim remains an independent empirical assertion rather than a definitional or fitted tautology, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech translation is commonly categorized into two paradigms: consecutive and simultaneous. Consecutive translation generates the target speech only after a complete utterance has been received, ensuring high translation fidelity and a natural, continuous acoustic flow at the expense of significant latency. In contrast, simultaneous translat...
Pith/arXiv arXiv 2026
-
[2]
Related Work 2.1. Fluency in interpreting: pauses and perceived quality Fluency is a central criterion in interpreting quality assessment, but it has been operationalized through a heterogeneous set of temporal and disfluency-related correlates rather than a single agreed-upon construct [14]. A common thread across this lit- erature is that fluency is str...
-
[3]
Preliminary 3.1. Simultaneous S2ST model To achieve this near-instantaneous communication, end-to-end S2ST systems must be capable of processing incoming audio streams while synchronously generating translations. In this work, we adopt Hibiki [6] as our baseline architecture and apply our proposed optimization framework to it. Hibiki is designed to proces...
-
[4]
silver-medal
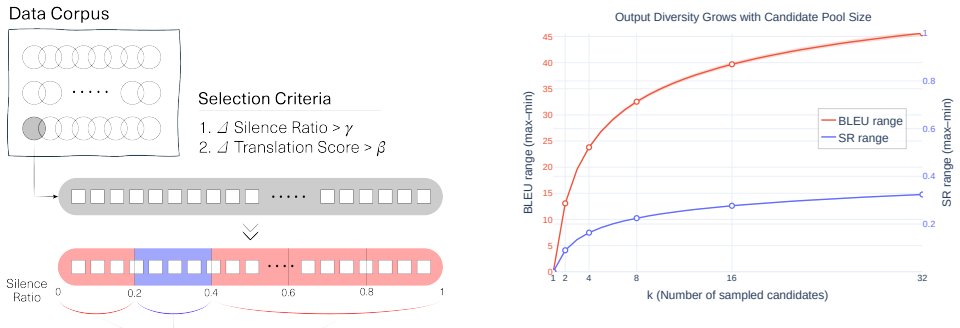
Method 4.1. Preference data construction 4.1.1. Data collection In order to construct an offline preference dataset for our model, we design a data collection pipeline consisting of three stages: •Source data selection:A mix of short- and long-form speech data was used to cover temporal diversity. For short-form instances ranging from 0 to 10 seconds, 10,...
-
[5]
Experimental settings We employ the Hibiki-2B model as our base architecture, fine- tuning it via Low-Rank Adaptation (LoRA) [35] with a rank of r= 128
Experiments 5.1. Experimental settings We employ the Hibiki-2B model as our base architecture, fine- tuning it via Low-Rank Adaptation (LoRA) [35] with a rank of r= 128. We set text padding weight to 0.5 and the duration to 102.4. For preference alignment, we apply Direct Preference Optimization with length normalization utilizing a KL penalty coefficient...
-
[6]
Benchmarks 6.1.1
Evaluation 6.1. Benchmarks 6.1.1. Short-form data •CVSS-C: We use the Fr-Entestsplit of CVSS-C [10], a widely used S2ST benchmark derived from Common V oice [38] recordings with paired translation text from CoV- oST 2 [39]. This benchmark contains real-speaker French source audio with an average duration of5.6s. •VoxPopuli S2S Interpretation: We use the F...
1981
-
[7]
First, we investigate whether our method can effectively reduce the silence ratio without incurring a trade- off in translation quality
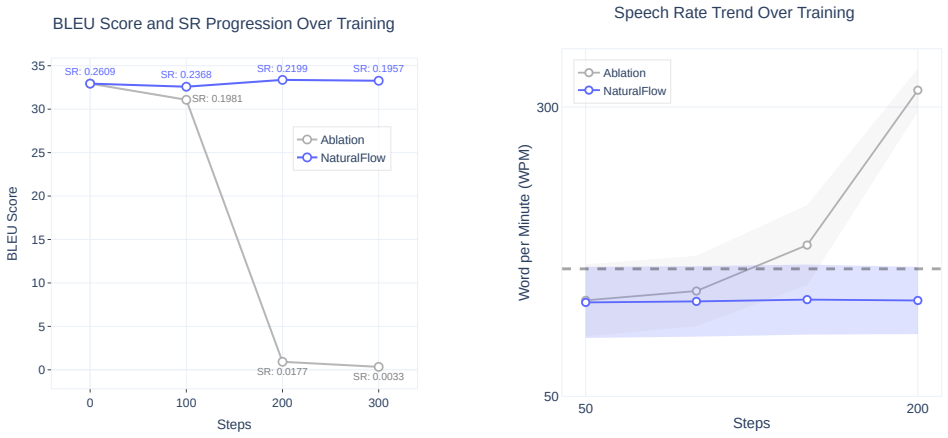
Results In our experiments, we aim to answer the following three re- search questions. First, we investigate whether our method can effectively reduce the silence ratio without incurring a trade- off in translation quality. Second, we analyze the stability of our preference design to ensure it does not collapse into a sin- gle objective, such as exclusive...
-
[8]
Conclusion In this work, we present a fluency-aware optimization frame- work for simultaneous speech-to-speech translation (S2ST) that reduces unnatural pauses while maintaining translation fidelity. By integrating the silence ratio as an optimization objective with our Silver-Medal Preference design, we balance the continuity of speech flow with translat...
-
[9]
This was supported by Mobile eXperience(MX) Business, Samsung Electronics Co., Ltd
Acknowledgements This work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grants funded by the Korean government (MSIT) [NO.RS- 2021-II211343, Artificial Intelligence Graduate School Pro- gram (Seoul National University); No.2022-0-00959, RS-2022- II220959], by National Research Foundation of Korea (NRF)...
2021
-
[10]
All scientific content, including the methodology, ex- periments, results, and conclusions, was developed and verified by the authors
Generative AI Use Disclosure Generative AI tools were used solely for language editing and polishing. All scientific content, including the methodology, ex- periments, results, and conclusions, was developed and verified by the authors
-
[11]
Testing the effort models’ tightrope hypothesis in simultaneous interpreting - a contribution,
D. Gile, “Testing the effort models’ tightrope hypothesis in simultaneous interpreting - a contribution,”HERMES - Journal of Language and Communication in Business, vol. 12, no. 23, p. 153–172, Feb. 1999. [Online]. Available: https: //tidsskrift.dk/her/article/view/25553
1999
-
[12]
Taxing the bilingual mind: Effects of simultaneous interpreting experience on verbal and executive mechanisms,
A. M. Garc ´ıa, E. Mu ˜noz, and B. Kogan, “Taxing the bilingual mind: Effects of simultaneous interpreting experience on verbal and executive mechanisms,”Bilingualism: Language and Cogni- tion, vol. 23, no. 4, p. 729–739, 2020
2020
-
[13]
Direct simultaneous speech-to-text translation assisted by synchronized streaming ASR,
J. Chen, M. Ma, R. Zheng, and L. Huang, “Direct simultaneous speech-to-text translation assisted by synchronized streaming ASR,” inFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Online: Association for Computational Linguistics, Aug. 2021, pp. 4618–4624. [Online]. Available: https:/...
2021
-
[14]
Seamless: Multilingual expressive and streaming speech translation,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haa- heimet al., “Seamless: Multilingual expressive and streaming speech translation,” 2023
2023
-
[15]
Streamspeech: Simultaneous speech-to-speech translation with multi-task learning,
S. Zhang, Q. Fang, S. Guo, Z. Ma, M. Zhang, and Y . Feng, “Streamspeech: Simultaneous speech-to-speech translation with multi-task learning,” 2024
2024
-
[16]
High-fidelity simultaneous speech-to-speech translation,
T. Labiausse, L. Mazar ´e, E. Grave, A. D ´efossez, and N. Zeghidour, “High-fidelity simultaneous speech-to-speech translation,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, Eds., vol....
2025
-
[17]
STACL: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework,
M. Ma, L. Huang, H. Xiong, R. Zheng, K. Liu, B. Zheng, C. Zhang, Z. He, H. Liu, X. Li, H. Wu, and H. Wang, “STACL: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez...
2019
-
[18]
The impact of fluency on the subjective assessment of interpreting quality,
S. Rennert, “The impact of fluency on the subjective assessment of interpreting quality,”Interpreting, vol. 12, no. 1, pp. 1–24, 2010
2010
-
[19]
Prosodic correlates of per- ceived quality and fluency in simultaneous interpreting,
G. Christodoulides and C. Lenglet, “Prosodic correlates of per- ceived quality and fluency in simultaneous interpreting,” inPro- ceedings of the Speech Prosody, vol. 7, 2014, pp. 1002–1006
2014
-
[20]
CVSS corpus and massively multilingual speech-to-speech translation,
Y . Jia, M. T. Ramanovich, Q. Wang, and H. Zen, “CVSS corpus and massively multilingual speech-to-speech translation,” CoRR, vol. abs/2201.03713, 2022. [Online]. Available: https: //arxiv.org/abs/2201.03713
arXiv 2022
-
[21]
C. Wang, M. Rivi `ere, A. Lee, A. Wu, C. Talnikar, D. Haziza, M. Williamson, J. Pino, and E. Dupoux, “V oxpopuli: A large- scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” 2021. [Online]. Available: https://arxiv.org/abs/2101.00390
arXiv 2021
-
[22]
The multilingual tedx corpus for speech recognition and translation,
E. Salesky, M. Wiesner, J. Bremerman, R. Cattoni, M. Negri, M. Turchi, D. W. Oard, and M. Post, “The multilingual tedx corpus for speech recognition and translation,” 2021. [Online]. Available: https://arxiv.org/abs/2102.01757
arXiv 2021
-
[23]
Simultaneous speech-to-speech translation without aligned data,
T. Labiausse, R. Fabre, Y . Est`eve, A. D´efossez, and N. Zeghidour, “Simultaneous speech-to-speech translation without aligned data,” 2026. [Online]. Available: https://arxiv.org/abs/2602.11072
arXiv 2026
-
[24]
Methodological issues in the study of interpreters’ flu- ency,
P. Mead, “Methodological issues in the study of interpreters’ flu- ency,” 2005
2005
-
[25]
The lexical element in spoken second language fluency,
P. A. Lennon, “The lexical element in spoken second language fluency,” 2000. [Online]. Available: https://api.semanticscholar. org/CorpusID:151390810
2000
-
[26]
Silent pauses and disfluencies in simultaneous inter- pretation: A descriptive analysis,
B. Tissi, “Silent pauses and disfluencies in simultaneous inter- pretation: A descriptive analysis,”The Interpreters’ Newsletter, vol. 10, no. 4, pp. 103–127, 2000
2000
-
[27]
(para) linguistic correlates of perceived fluency in english-to-chinese simultaneous interpretation,
C. Han, “(para) linguistic correlates of perceived fluency in english-to-chinese simultaneous interpretation,”International Journal of Comparative Literature & Translation Studies, vol. 3, no. 4, p. 32, 2015
2015
-
[28]
Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation,
A. B ´erard, O. Pietquin, L. Besacier, and C. Servan, “Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation,” inNIPS Workshop on end-to-end learning for speech and audio processing, Barcelona, Spain, Dec. 2016. [Online]. Available: https://hal.science/hal-01408086
2016
-
[29]
Sequence-to-Sequence Models Can Directly Translate Foreign Speech,
R. J. Weiss, J. Chorowski, N. Jaitly, Y . Wu, and Z. Chen, “Sequence-to-Sequence Models Can Directly Translate Foreign Speech,” inInterspeech 2017, 2017, pp. 2625–2629
2017
-
[30]
Direct Speech-to-Speech Translation with a Sequence-to-Sequence Model,
Y . Jia, R. J. Weiss, F. Biadsy, W. Macherey, M. Johnson, Z. Chen, and Y . Wu, “Direct Speech-to-Speech Translation with a Sequence-to-Sequence Model,” inInterspeech 2019, 2019, pp. 1123–1127
2019
-
[31]
Direct speech-to-speech translation with discrete units,
A. Lee, P.-J. Chen, C. Wang, J. Gu, S. Popuri, X. Ma, A. Polyak, Y . Adi, Q. He, Y . Tang, J. Pino, and W.-N. Hsu, “Direct speech-to-speech translation with discrete units,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: As...
2022
-
[32]
Seamlessm4t: Massively multilingual & multimodal machine translation,
Meta AI, “Seamlessm4t: Massively multilingual & multimodal machine translation,” 2023. [Online]. Available: https://arxiv.org/ abs/2308.11596
arXiv 2023
-
[33]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Infor- mation Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 53 728–53 741. [Online]. A...
2023
-
[34]
Contrastive preference optimization: Pushing the boundaries of LLM performance in machine translation,
H. Xu, A. Sharaf, Y . Chen, W. Tan, L. Shen, B. Van Durme, K. Murray, and Y . J. Kim, “Contrastive preference optimization: Pushing the boundaries of LLM performance in machine translation,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kolter, K. Heller, A. Well...
2024
-
[35]
Simulpl: Aligning human preferences in simultaneous ma- chine translation,
D. Yu, Y . Zhao, J. Zhu, Y . Xu, Y . Zhou, and C. Zong, “Simulpl: Aligning human preferences in simultaneous ma- chine translation,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 55 916–55 938. [Online]. Available: https://proceedings.iclr.cc/paper files/paper/2025/file/ 8c...
2025
-
[36]
SeqPO- SiMT: Sequential policy optimization for simultaneous machine translation,
T. Xu, Z. Huang, J. Sun, S. Cheng, and W. Lam, “SeqPO- SiMT: Sequential policy optimization for simultaneous machine translation,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 16 107–16 123. [Online]...
2025
-
[37]
Moshi: a speech- text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech- text foundation model for real-time dialogue,” 2024. [Online]. Available: https://arxiv.org/abs/2410.00037
Pith/arXiv arXiv 2024
-
[38]
Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback,
H. Lee, S. Phatale, H. Mansoor, T. Mesnard, J. Ferret, K. Lu, C. Bishop, E. Hall, V . Carbune, A. Rastogi, and S. Prakash, “Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback,” 2024. [Online]. Available: https://arxiv.org/abs/2309.00267
Pith/arXiv arXiv 2024
-
[39]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” 2022. [Online]. Available: https://arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[40]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[41]
Robust speech recognition via large- scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
Pith/arXiv arXiv 2022
-
[42]
Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,
S. Team, “Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,” https:// github.com/snakers4/silero-vad, 2024
2024
-
[43]
Less is more: Improving llm alignment via preference data selection,
X. Deng, H. Zhong, R. Ai, F. Feng, Z. Wang, and X. He, “Less is more: Improving llm alignment via preference data selection,”
-
[44]
Available: https://arxiv.org/abs/2502.14560
[Online]. Available: https://arxiv.org/abs/2502.14560
-
[45]
Aligning spoken dialogue models from user interactions,
A. Wu, L. Mazar ´e, N. Zeghidour, and A. D ´efossez, “Aligning spoken dialogue models from user interactions,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, Eds., vol. 267. PMLR, 13– 19...
2025
-
[46]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” 2021. [Online]. Available: https: //arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2021
-
[47]
SIMULE- V AL: An evaluation toolkit for simultaneous translation,
X. Ma, M. J. Dousti, C. Wang, J. Gu, and J. Pino, “SIMULE- V AL: An evaluation toolkit for simultaneous translation,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Q. Liu and D. Schlangen, Eds. Online: Association for Computa- tional Linguistics, Oct. 2020, pp. 144–150. [Online]. Availabl...
2020
-
[48]
WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,” inInter- speech 2023, 2023, pp. 4489–4493
2023
-
[49]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” in Proceedings of the Twelfth Language Resources and Evaluation Conference, N. Calzolari, F. B ´echet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J....
2020
-
[50]
CoV oST 2 and Massively Multilingual Speech Translation,
C. Wang, A. Wu, J. Gu, and J. Pino, “CoV oST 2 and Massively Multilingual Speech Translation,” inInterspeech 2021, 2021, pp. 2247–2251
2021
-
[51]
NTREX-128 – news test references for MT evaluation of 128 languages,
C. Federmann, T. Kocmi, and Y . Xin, “NTREX-128 – news test references for MT evaluation of 128 languages,” in Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, K. Ahuja, A. Anastasopoulos, B. Patra, G. Neubig, M. Choudhury, S. Dandapat, S. Sitaram, and V . Chaudhary, Eds. Online: Association for Computational Linguistics, Nov. 2022...
2022
-
[52]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” in Proceedings of the Third Conference on Machine Translation: Research Papers, O. Bojar, R. Chatterjee, C. Federmann, M. Fishel, Y . Graham, B. Haddow, M. Huck, A. J. Yepes, P. Koehn, C. Monz, M. Negri, A. N ´ev´eol, M. Neves, M. Post, L. Specia, M. Turchi, and K. Verspoor, Eds. Brussels, Belgium: A...
2018
-
[53]
Available: https://aclanthology.org/W18-6319/
[Online]. Available: https://aclanthology.org/W18-6319/
-
[54]
xcomet: Transparent machine translation evalua- tion through fine-grained error detection,
N. M. Guerreiro, R. Rei, D. v. Stigt, L. Coheur, P. Colombo, and A. F. Martins, “xcomet: Transparent machine translation evalua- tion through fine-grained error detection,” pp. 979–995, 2024
2024
-
[55]
FINDINGS OF THE IWSLT 2024 EV ALUATION CAMPAIGN,
I. S. Ahmad, A. Anastasopoulos, O. Bojar, C. Borg, M. Carpuat, R. Cattoni, M. Cettolo, W. Chen, Q. Dong, M. Federico, B. Haddow, D. Javorsk ´y, M. Krubi ´nski, T. K. Lam, X. Ma, P. Mathur, E. Matusov, C. Maurya, J. P. McCrae, K. Murray, S. Nakamura, M. Negri, J. Niehues, X. Niu, A. K. Ojha, J. Ortega, S. Papi, P. Pol ´ak, A. Posp ´ıˇsil, P. Pecina, E. Sal...
2024
-
[56]
Over-generation cannot be rewarded: Length-adaptive average lagging for simultaneous speech translation,
S. Papi, M. Gaido, M. Negri, and M. Turchi, “Over-generation cannot be rewarded: Length-adaptive average lagging for simultaneous speech translation,” inProceedings of the Third Workshop on Automatic Simultaneous Translation, J. Ive and R. Zhang, Eds. Online: Association for Computational Linguistics, Jul. 2022, pp. 12–17. [Online]. Available: https: //ac...
2022
-
[57]
Cheap and fast – but is it good? evaluating non-expert annotations for natural language tasks,
R. Snow, B. O’Connor, D. Jurafsky, and A. Ng, “Cheap and fast – but is it good? evaluating non-expert annotations for natural language tasks,” inProceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, M. Lapata and H. T. Ng, Eds. Honolulu, Hawaii: Association for Computational Linguistics, Oct. 2008, pp. 254–263. [Online]. ...
2008
-
[58]
Language processing in reading and speech perception is fast and incremental: Implications for event-related potential research,
K. Rayner and C. Clifton, “Language processing in reading and speech perception is fast and incremental: Implications for event-related potential research,”Biological Psychology, vol. 80, no. 1, pp. 4–9, 2009, before the N400: Early Latency Language ERPs. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0301051108001245
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.