Neural Procedural Memory: Empowering LLM Agents with Implicit Activation Steering
Pith reviewed 2026-06-30 06:14 UTC · model grok-4.3
The pith
LLM agents can store procedural memory as activation steering vectors distilled from past experiences instead of text instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
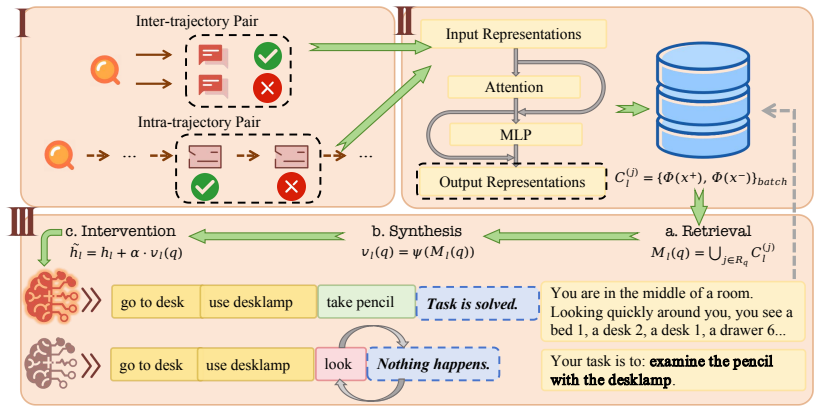
By distilling procedural skills from historical contrastive experiences into steering vectors in the activation space, NPM directly activates the task-relevant neural mechanisms to guide task execution without any model training or explicit symbolic guidance.
What carries the argument
Steering vectors created from contrastive historical experiences that encode task logic and are applied at inference time to shift activations.
If this is right
- Agents achieve comparable success rates using only the implicit steering vectors as when given explicit textual workflows.
- Pairing the steering vectors with explicit instructions produces higher robustness than either alone.
- The vectors form consistent, organized structures in activation space that reflect task logic across examples.
Where Pith is reading between the lines
- The same contrastive distillation process might be applied to other internal states such as attention patterns if those also encode procedural knowledge.
- Steering could reduce the length of context needed for agent prompts by moving memory out of tokens and into activations.
- If the activation space contains reusable task modules, the method might transfer across domains that share underlying logic.
Load-bearing premise
Vectors taken from past contrastive experiences will reliably activate the correct internal mechanisms on new tasks without training or explicit rules.
What would settle it
Apply the derived steering vector to a genuinely new task and observe whether success rate stays the same or drops relative to an unsteered baseline.
Figures









read the original abstract
While Large Language Models (LLMs) excel as static solvers, transforming them into autonomous agents remains challenging. This transition requires continuous environmental interaction, yet current agents lack the necessary persistent procedural memory. Existing approaches predominantly employ Retrieval-Augmented Generation (RAG) to inject explicit textual guidelines into model contexts. However, relying solely on symbolic instructions can introduce a text-action disconnect, frequently failing to activate the internal representations necessary for correct task execution. To address this, the paper introduces Neural Procedural Memory (NPM), a training-free framework that represents agent memory through implicit activation steering rather than explicit instructions. By distilling procedural skills from historical contrastive experiences into steering vectors in the activation space, NPM directly activates the task-relevant neural mechanisms to guide task execution. Evaluations across four agent benchmarks show that NPM performs comparably to baselines using explicit textual instructions. Furthermore, the results show that combining implicit steering with explicit workflows provides complementary advantages, leading to more robust task execution. Representational analyses indicate that these steering vectors encode consistent task logic, forming organized structures within the activation space. These findings suggest that implicit activation steering provides a promising approach for managing agent memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Procedural Memory (NPM), a training-free method that distills procedural skills from historical contrastive experiences into activation-space steering vectors. These vectors are claimed to implicitly activate task-relevant neural mechanisms in LLMs, enabling agent memory without explicit textual instructions. Evaluations on four agent benchmarks show performance comparable to explicit-instruction baselines, with complementary gains when combined; representational analyses indicate the vectors encode consistent task logic in organized activation-space structures.
Significance. If the central claim holds, NPM offers a novel implicit alternative to RAG-style explicit memory for LLM agents, potentially reducing text-action disconnects. The training-free nature and use of contrastive historical data are strengths, as is the reported complementarity with explicit workflows and the representational evidence of structured encodings.
major comments (1)
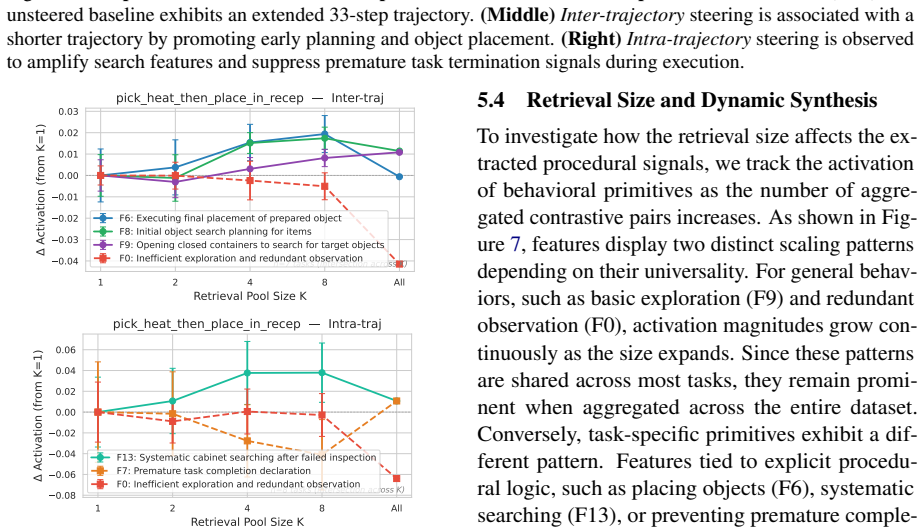
- [Abstract and §4] Abstract and §4 (Experiments): The core claim that steering vectors 'directly activate the task-relevant neural mechanisms' is load-bearing but rests on performance correlation and representational similarity analyses. No targeted causal interventions (e.g., ablating or steering only at layers known to implement specific computations) or systematic failure-case analysis on out-of-distribution tasks are described, leaving open whether effects arise from the claimed mechanism or from generic regularization/prompt-like influences. This weakens the distinction from explicit baselines.
minor comments (2)
- [Abstract] Abstract: The four agent benchmarks are not named, and no dataset sizes, statistical significance, or variance reporting appear; adding these would improve clarity without altering the claim.
- [§3] §3 (Method): The precise construction of contrastive pairs and the layer(s) at which steering is applied should be stated explicitly with pseudocode or equations to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the strength of evidence for our mechanistic claims. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The core claim that steering vectors 'directly activate the task-relevant neural mechanisms' is load-bearing but rests on performance correlation and representational similarity analyses. No targeted causal interventions (e.g., ablating or steering only at layers known to implement specific computations) or systematic failure-case analysis on out-of-distribution tasks are described, leaving open whether effects arise from the claimed mechanism or from generic regularization/prompt-like influences. This weakens the distinction from explicit baselines.
Authors: We agree that the evidence presented is correlational, relying on performance parity with explicit-instruction baselines, complementarity when combined, and representational similarity showing organized task-logic structures in activation space. No layer-specific causal ablations or systematic OOD failure analyses are included, as the work focuses on a training-free distillation approach without requiring prior identification of computation-specific layers. The contrastive construction of the vectors is designed to capture task-specific rather than generic effects, but we acknowledge this does not constitute direct causal proof and that alternative interpretations (e.g., regularization-like influences) cannot be fully ruled out with the current analyses. For the revision we will (1) revise the abstract and §4 language to describe the vectors as implicitly guiding execution via distilled activations rather than claiming they 'directly activate' mechanisms, (2) expand the representational analysis section with additional failure-case breakdowns from the existing benchmark results, and (3) add an explicit limitations paragraph discussing the correlational nature of the evidence and the value of future causal work. These changes will be made without new experiments. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces NPM as a training-free method that constructs steering vectors from external historical contrastive experiences and evaluates them on agent benchmarks plus representational analyses. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claims rest on empirical performance comparisons and activation-space observations that are independent of the method's definition, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Legomem: Modular procedural memory for multi-agent llm systems for workflow automation. Preprint, arXiv:2510.04851. Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, and 1 others. 2024. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv prepri...
-
[2]
Memory in the Age of AI Agents
Memory in the age of ai agents.Preprint, arXiv:2512.13564. Taewoon Kim, Michael Cochez, Vincent François- Lavet, Mark Neerincx, and Piek V ossen. 2023. A machine with short-term, episodic, and semantic memory systems. InProceedings of the Thirty- Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applica- tions of...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G
Memory-augmented transformers: A system- atic review from neuroscience principles to enhanced model architectures.Preprint, arXiv:2508.10824. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez
-
[4]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Steering Llama 2 via Contrastive Activation Addition
Steering llama 2 via contrastive activation addition.Preprint, arXiv:2312.06681. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bern- stein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th An- nual ACM Symposium on User Interface Software and Technology, UIS...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
InProceed- ings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 577–603, Miami, Florida, US
Multi-property steering of large language mod- els with dynamic activation composition. InProceed- ings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 577–603, Miami, Florida, US. Association for Com- putational Linguistics. Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu
-
[7]
Character-LLM: A trainable agent for role- playing. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 13153–13187, Singapore. Association for Computational Linguistics. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. 2023. Re- flexion: language agents with verbal reinforc...
-
[8]
Identify the common behavioral pattern across the activating examples that distinguishes them from the non-activating examples
-
[9]
The label should reflect both WHAT the behavior is and WHETHER it contributes to task success or failure
Provide a short label (3-8 words in English) for this feature. The label should reflect both WHAT the behavior is and WHETHER it contributes to task success or failure
-
[10]
Provide a one-paragraph explanation of what this feature detects, integrating evidence from the examples, outcome statistics, and action type distribution
-
[11]
positive
Classify the feature’s polarity: "positive" if it is associated with effective/successful behavior, "negative" if associated with ineffective/failing behavior, or "neutral" if no clear association
-
[12]
label":
Rate your confidence (high/medium/low) in this interpretation. Respond in JSON format: {"label": "...", "explanation": "...", "polarity": "positive | negative | neutral", "confidence": "high | medium | low", "key_evidence": ["...", "..."]} Figure 8: Prompt template for automated interpretation of geometric basis directions. 18 Inter Intra 0.84 0.86 0.88 0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.