Calibration Without Comprehension: Diagnosing the Limits of Fine-Tuning LLMs for Vulnerability Detection in Systems Software
Pith reviewed 2026-06-26 16:57 UTC · model grok-4.3
The pith
Fine-tuning LLMs for vulnerability detection only calibrates output thresholds without instilling security reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Backbone directional priors dominate fine-tuning. Models exhibit stable, systematic failure modes (DFI ranging from -85.5 to +94.8 pp) that persist from historical to post-cutoff data and resist correction. Fine-tuning shifts the output threshold without changing the decision policy. This is calibration without comprehension: output distributions adapt to training data while the underlying security reasoning remains absent. The weakest backbone at binary detection gains the most in coarse CWE classification, revealing that detection and understanding are decoupled capabilities.
What carries the argument
The Directional Failure Index (DFI) and Hierarchical Distance and Direction (HDD) metrics, which quantify persistent directional failure modes that fine-tuning cannot correct.
If this is right
- Data contamination provides no measurable advantage for vulnerability detection tasks.
- Detection and understanding of vulnerabilities remain decoupled capabilities in current LLMs.
- The best achievable detection score reaches only 52.1 percent, only slightly above chance.
- Exact CWE ranking stays below 1.3 percent Top-1 accuracy across all tested models and strategies.
Where Pith is reading between the lines
- If the result generalizes, security applications may require new model architectures capable of acquiring domain reasoning rather than relying on existing priors.
- The same calibration-without-comprehension pattern could limit LLM performance on related tasks such as automated code repair or formal verification.
- Applying the DFI metric to non-security code tasks could reveal whether persistent directional failures are specific to vulnerability detection or more general.
Load-bearing premise
The manually curated 834-sample dataset with its temporal split and the DFI/HDD metrics provide a valid, leakage-free test that distinguishes absence of security reasoning from other model or data limitations.
What would settle it
A fine-tuning run on post-cutoff data that produces DFI values near zero or reverses the sign of existing failure directions on held-out samples would falsify the claim that priors dominate and remain uncorrectable.
Figures

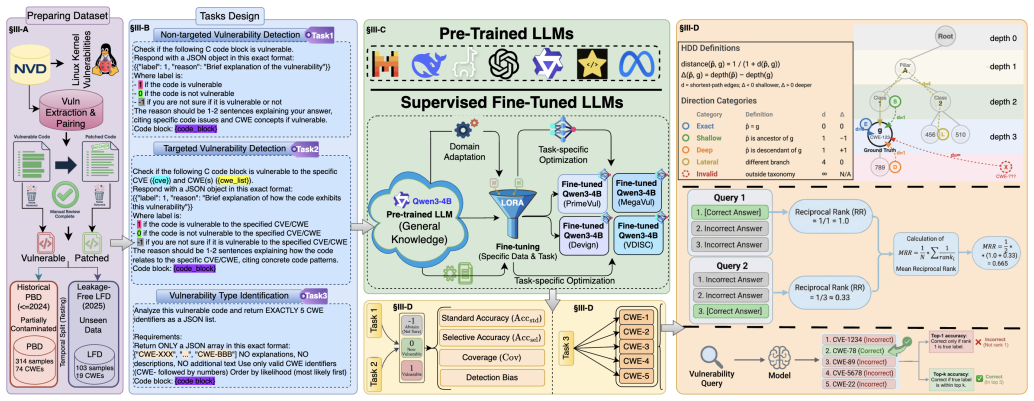
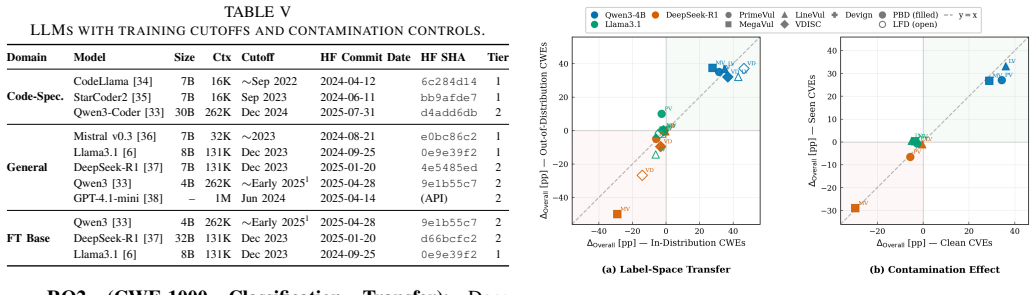

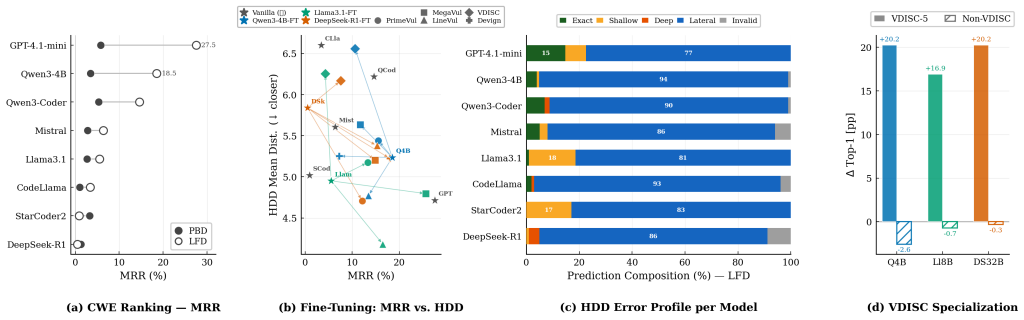
read the original abstract
Whether LLMs scoring well on vulnerability benchmarks genuinely reason about security or merely pattern-match on contaminated data remains unresolved. We present CWE-Trace, a framework for LLM vulnerability detection built from 834 manually curated Linux kernel samples spanning 74 CWEs. The framework enforces a strict temporal split (pre-2025 historical set / post-cutoff leakage-free set), preserves context-aware vulnerable--patched pairs, and introduces two diagnostic metrics: the Directional Failure Index (DFI) and Hierarchical Distance and Direction (HDD). We evaluate eight vanilla LLMs and 15 LoRA fine-tuned variants across non-targeted detection, targeted detection, and CWE classification. Our analysis yields two key results. First, data contamination provides no measurable advantage. Function-level analysis shows that 84% of nominally contaminated samples carry no usable memorization signal: vulnerable functions are absent or cross-mapped across datasets, and ~31% of contaminated samples carry CWE misclassification. Second, backbone directional priors dominate fine-tuning. Models exhibit stable, systematic failure modes (DFI ranging from -85.5 to +94.8 pp) that persist from historical to post-cutoff data and resist correction. Fine-tuning shifts the output threshold without changing the decision policy. This is calibration without comprehension: output distributions adapt to training data while the underlying security reasoning remains absent. The weakest backbone at binary detection (DeepSeek-R1) gains the most in coarse CWE classification, revealing that detection and understanding are decoupled capabilities. The best detection score reaches only 52.1% (+2.1 pp above chance); exact CWE ranking remains below 1.3% Top-1 accuracy, confirming that current LLMs lack reliable security reasoning for systems software, regardless of fine-tuning strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CWE-Trace, a framework built on 834 manually curated Linux kernel samples spanning 74 CWEs with a strict temporal split (pre-2025 historical vs. post-cutoff leakage-free sets) that preserves vulnerable-patched pairs. It evaluates eight vanilla LLMs and 15 LoRA variants on non-targeted detection, targeted detection, and CWE classification, introducing Directional Failure Index (DFI) and Hierarchical Distance and Direction (HDD) metrics. Key claims are that contamination yields no measurable advantage (84% of contaminated samples lack usable memorization signal), backbone directional priors dominate (DFI ranges -85.5 to +94.8 pp persist across splits and resist fine-tuning), and fine-tuning only shifts output thresholds without altering decision policy, yielding at best 52.1% detection (+2.1 pp above chance) and <1.3% Top-1 CWE accuracy.
Significance. If the DFI/HDD metrics are shown to isolate decision policy independent of task hardness, the temporal-split results and contamination controls would provide strong evidence that current LLMs lack reliable security reasoning for systems software. The manual curation, leakage-free split, and direct contamination measurement are concrete strengths supporting the empirical component.
major comments (3)
- [framework construction and metric introduction] The section introducing DFI and HDD (framework construction paragraph) defines these as new diagnostic metrics but reports no validation on control cases where security reasoning is known to exist (e.g., static analyzers or explicit CoT security traces). This is load-bearing for the central claim that |DFI| values indicate absent reasoning rather than general task difficulty, label imbalance, or curation artifacts.
- [results on fine-tuning effects] The abstract claim that 'fine-tuning shifts the output threshold without changing the decision policy' (supported by persistent DFI across historical and post-cutoff data) requires explicit before/after DFI comparisons with statistical tests in the results section; without these, it remains unclear whether observed stability reflects true policy invariance or metric sensitivity.
- [contamination analysis] Table or section reporting the 84% 'no usable memorization signal' finding for contaminated samples must detail the exact cross-mapping criteria and CWE misclassification detection method used at function level; these choices directly affect the conclusion that contamination provides no advantage.
minor comments (1)
- Provide explicit formulas for DFI and HDD (including any normalization or hierarchical weighting) in a dedicated subsection or appendix to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [framework construction and metric introduction] The section introducing DFI and HDD (framework construction paragraph) defines these as new diagnostic metrics but reports no validation on control cases where security reasoning is known to exist (e.g., static analyzers or explicit CoT security traces). This is load-bearing for the central claim that |DFI| values indicate absent reasoning rather than general task difficulty, label imbalance, or curation artifacts.
Authors: We agree that direct validation of DFI and HDD on control cases with established security reasoning (such as static analyzers) would provide stronger support for interpreting high |DFI| as evidence of absent reasoning rather than task artifacts. The metrics were designed to isolate directional output bias from accuracy, using the temporal split as an indirect control. In revision we will add a dedicated paragraph in the framework section discussing this limitation, including a brief qualitative comparison to expected DFI behavior under perfect reasoning, and note it explicitly as a direction for future work. revision: partial
-
Referee: [results on fine-tuning effects] The abstract claim that 'fine-tuning shifts the output threshold without changing the decision policy' (supported by persistent DFI across historical and post-cutoff data) requires explicit before/after DFI comparisons with statistical tests in the results section; without these, it remains unclear whether observed stability reflects true policy invariance or metric sensitivity.
Authors: The results already report DFI for both vanilla and LoRA-tuned models and note persistence across splits, but we acknowledge the absence of paired before/after comparisons and formal statistical tests. We will add a new table in the results section listing per-model DFI values pre- and post-fine-tuning, together with paired statistical tests (Wilcoxon signed-rank) to quantify stability. This will directly support the threshold-shift claim. revision: yes
-
Referee: [contamination analysis] Table or section reporting the 84% 'no usable memorization signal' finding for contaminated samples must detail the exact cross-mapping criteria and CWE misclassification detection method used at function level; these choices directly affect the conclusion that contamination provides no advantage.
Authors: We will expand the contamination analysis subsection to include the precise function-level cross-mapping rules (string similarity thresholds, AST-based matching, and handling of renamed functions) and the exact procedure for detecting CWE misclassifications (manual review protocol plus keyword/CWE-ID mismatch checks). A supplementary table will list the decision criteria and example mappings to ensure full reproducibility. revision: yes
Circularity Check
No circularity: direct empirical measurements on held-out data
full rationale
The paper is a purely empirical evaluation that introduces a curated dataset, temporal split, and two new diagnostic metrics (DFI and HDD) then reports measured performance numbers on eight base models and fifteen fine-tuned variants. No equations, fitted parameters, or derivations exist that reduce any reported outcome to a quantity defined by the inputs. Central claims rest on the observed DFI ranges and accuracy figures themselves rather than on any self-referential construction or self-citation chain. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 834 samples are accurately labeled for vulnerabilities and CWEs by manual curation
- domain assumption The post-2025 temporal split ensures no training-data leakage
invented entities (2)
-
Directional Failure Index (DFI)
no independent evidence
-
Hierarchical Distance and Direction (HDD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vulnerability details and information,
CVE Details, “Vulnerability details and information,” https://www. cvedetails.com/, 2024, accessed: 2024-06-19
2024
-
[2]
GitHub, Inc., “Codeql,” https://codeql.github.com/, 2026, accessed: 2026-02-26
2026
-
[3]
Semgrep app security platform,
Semgrep, Inc., “Semgrep app security platform,” https://semgrep.dev/, 2026, accessed: 2026-02-26
2026
-
[4]
Machine learning to combine static analysis alerts with software metrics to detect security vulnerabilities: An empirical study,
J. D. Pereira, J. R. Campos, and M. Vieira, “Machine learning to combine static analysis alerts with software metrics to detect security vulnerabilities: An empirical study,” in2021 17th European Dependable Computing Conference (EDCC). IEEE, 2021, pp. 1–8
2021
-
[5]
Evaluating large language models trained on code,
M. Chenet al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[6]
Llama: Open and efficient foundation language models,
H. Touvronet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[7]
Codebert: A pre-trained model for programming and natural languages,
Z. Fenget al., “Codebert: A pre-trained model for programming and natural languages,”arXiv preprint arXiv:2002.08155, 2020
Pith/arXiv arXiv 2002
-
[8]
Competition-level code generation with alphacode,
Y . Liet al., “Competition-level code generation with alphacode,”Sci- ence, vol. 378, no. 6624, pp. 1092–1097, 2022
2022
-
[9]
Securityeval dataset: mining vulner- ability examples to evaluate machine learning-based code generation techniques,
M. L. Siddiq and J. C. Santos, “Securityeval dataset: mining vulner- ability examples to evaluate machine learning-based code generation techniques,” inProceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security, 2022, pp. 29–33
2022
-
[10]
Y . Liuet al., “Vuldetectbench: Evaluating the deep capability of vulnerability detection with large language models,”arXiv preprint arXiv:2406.07595, 2024
arXiv 2024
-
[11]
Y . Sunet al., “Llm4vuln: A unified evaluation framework for de- coupling and enhancing llms’ vulnerability reasoning,”arXiv preprint arXiv:2401.16185, 2024
arXiv 2024
-
[12]
Understanding the effectiveness of large language models in detecting security vulnerabilities,
A. Khareet al., “Understanding the effectiveness of large language models in detecting security vulnerabilities,” in2025 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 2025, pp. 103–114
2025
-
[13]
Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,
S. Ullahet al., “Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,” inIEEE Symposium on Security and Privacy, 2024
2024
-
[14]
Examining radiation therapy planning knowledge in large language models,
O. Ghorbaniet al., “Examining radiation therapy planning knowledge in large language models,” inProceedings of the 16th ACM International Conference on Bioinformatics, Computational Biology, and Health In- formatics, 2025, pp. 1–1
2025
-
[15]
Quantifying influencer impact on affective polar- ization,
R. Rashidet al., “Quantifying influencer impact on affective polar- ization,” in2024 International Conference on Machine Learning and Applications (ICMLA). IEEE, 2024, pp. 1135–1140
2024
-
[16]
How far have we gone in vulnerability detection using large language models,
Z. Gaoet al., “How far have we gone in vulnerability detection using large language models,”arXiv preprint arXiv:2311.12420, 2023
arXiv 2023
-
[17]
The secret life of software vulnerabilities: A large- scale empirical study,
E. Iannoneet al., “The secret life of software vulnerabilities: A large- scale empirical study,”IEEE Transactions on Software Engineering, vol. 49, no. 1, pp. 44–63, 2022
2022
-
[18]
Data quality for software vulnerability datasets,
R. Croft, M. A. Babar, and M. M. Kholoosi, “Data quality for software vulnerability datasets,” in2023 IEEE/ACM 45th International Confer- ence on Software Engineering (ICSE). IEEE, 2023, pp. 121–133
2023
-
[19]
Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks,
Y . Zhouet al., “Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[20]
Linevul: A transformer-based line- level vulnerability prediction,
M. Fu and C. Tantithamthavorn, “Linevul: A transformer-based line- level vulnerability prediction,” inProceedings of the 19th international conference on mining software repositories, 2022, pp. 608–620
2022
-
[21]
Vulnerability detection with code language models: How far are we?
Y . Dinget al., “Vulnerability detection with code language models: How far are we?”arXiv preprint arXiv:2403.18624, 2024
arXiv 2024
-
[22]
Megavul: Ac/c++ vulnerability dataset with comprehensive code representations,
C. Niet al., “Megavul: Ac/c++ vulnerability dataset with comprehensive code representations,” inProceedings of the 21st International Confer- ence on Mining Software Repositories, 2024, pp. 738–742
2024
-
[23]
Automated vulnerability detection in source code using deep representation learning,
R. Russellet al., “Automated vulnerability detection in source code using deep representation learning,” in2018 17th IEEE international conference on machine learning and applications (ICMLA). IEEE, 2018, pp. 757–762
2018
-
[24]
Codexglue: A machine learning benchmark dataset for code understanding and generation,
S. Luet al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,”arXiv preprint arXiv:2102.04664, 2021
Pith/arXiv arXiv 2021
-
[25]
Deep learning based vulnerability detection: Are we there yet?
S. Chakrabortyet al., “Deep learning based vulnerability detection: Are we there yet?”IEEE Transactions on Software Engineering, vol. 48, no. 9, pp. 3280–3296, 2021
2021
-
[26]
D2a: A dataset built for ai-based vulnerability detection methods using differential analysis,
Y . Zhenget al., “D2a: A dataset built for ai-based vulnerability detection methods using differential analysis,” in2021 IEEE/ACM 43rd Interna- tional Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2021, pp. 111–120
2021
-
[27]
Cvefixes: automated collec- tion of vulnerabilities and their fixes from open-source software,
G. Bhandari, A. Naseer, and L. Moonen, “Cvefixes: automated collec- tion of vulnerabilities and their fixes from open-source software,” in Proceedings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering, 2021, pp. 30–39
2021
-
[28]
Common Weakness Enumeration (CWE),
MITRE Corporation, “Common Weakness Enumeration (CWE),” https: //cwe.mitre.org/, 2024, accessed: 2025-10-18
2024
-
[29]
CWE-1000: Research Concepts,
——, “CWE-1000: Research Concepts,” https://cwe.mitre.org/data/ definitions/1000.html, 2024, accessed: 2025-10-18
2024
-
[30]
Imagenet large scale visual recognition chal- lenge,
O. Russakovskyet al., “Imagenet large scale visual recognition chal- lenge,”International journal of computer vision, vol. 115, pp. 211–252, 2015
2015
-
[31]
Mean reciprocal rank,
N. Craswell, “Mean reciprocal rank,”Encyclopedia of database systems, pp. 1703–1703, 2009
2009
-
[32]
Lora: Low-rank adaptation of large language models
E. J. Huet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[33]
A. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[34]
Code llama: Open foundation models for code,
B. Roziereet al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
Pith/arXiv arXiv 2023
-
[35]
Starcoder 2 and the stack v2: The next generation,
A. Lozhkovet al., “Starcoder 2 and the stack v2: The next generation,” arXiv preprint arXiv:2402.19173, 2024
Pith/arXiv arXiv 2024
-
[36]
A. Q. Jianget al., “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[37]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guoet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[38]
Gpt-4.1-mini,
OpenAI, “Gpt-4.1-mini,” https://openai.com/index/gpt-4-1, 2025, large language model by OpenAI. Accessed via ChatGPT or the OpenAI API
2025
-
[39]
Graphcodebert: Pre-training code representations with data flow,
D. Guoet al., “Graphcodebert: Pre-training code representations with data flow,”arXiv preprint arXiv:2009.08366, 2020
Pith/arXiv arXiv 2009
-
[40]
Deepwukong: Statically detecting software vulnerabil- ities using deep graph neural network,
X. Chenget al., “Deepwukong: Statically detecting software vulnerabil- ities using deep graph neural network,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 30, no. 3, pp. 1–33, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.