ParaPairAudioBench: Paralinguistic Pairwise Audio Benchmark for LALM-as-a-Judge
Pith reviewed 2026-06-25 22:04 UTC · model grok-4.3
The pith
LALM judges lag human judgments by 32 percentage points on paralinguistic audio pairs and fail to abstain on ties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current LALM judges still lag behind human judgments by 32%p on average and exhibit severe calibration failures, particularly in Tie cases where the correct decision is to abstain. The benchmark covers five paralinguistic dimensions under both same-transcript and cross-transcript conditions to expose lexical versus acoustic reliance.
What carries the argument
ParaPairAudioBench, a pairwise benchmark of 5,175 audio pairs across Style, Rate, Emphasis, Age, and Gender with same-transcript and cross-transcript splits.
If this is right
- LALMs cannot yet replace human judges for fine-grained paralinguistic assessment of generated speech.
- Accuracy alone is insufficient; calibration metrics that penalize overconfident tie decisions are required.
- Separate same-transcript and cross-transcript scores expose whether models use lexical shortcuts.
- Future model releases can be ranked by their gap to human performance on this fixed set.
Where Pith is reading between the lines
- Closing the 32-point gap would require training data that explicitly contrasts subtle acoustic variations while holding lexical content fixed.
- The tie-abstention failure suggests current alignment techniques do not teach models when evidence is insufficient.
- If the benchmark generalizes, it could become a standard filter before deploying LALM judges in production evaluation loops.
Load-bearing premise
The human labels on the 5,175 pairs constitute reliable ground truth for the five paralinguistic dimensions under both same-transcript and cross-transcript conditions.
What would settle it
A new annotation round on the same pairs that yields human inter-annotator agreement below 75 percent on any dimension would remove the benchmark's claim to ground truth.
Figures

read the original abstract
Large Audio-Language Models (LALMs) have been widely used as judge models for the automatic evaluation of generated speech. However, prior approaches predominantly focus on holistic naturalness, leaving fine-grained paralinguistic distinctions underexplored. We introduce ParaPairAudioBench, a pairwise benchmark of 5,175 audio pairs across five paralinguistic dimensions: Style, Rate, Emphasis, Age, and Gender. Our experiments show that current LALM judges still lag behind human judgments by 32%p on average and exhibit severe calibration failures, particularly in Tie cases where the correct decision is to abstain. To further analyze lexical versus acoustic reliance, the benchmark includes both same-transcript and cross-transcript conditions. ParaPairAudioBench enables multi-dimensional, calibration-aware assessment of the reliability of LALM-as-a-Judge for paralinguistic speech evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ParaPairAudioBench, a pairwise benchmark of 5,175 audio pairs spanning five paralinguistic dimensions (Style, Rate, Emphasis, Age, Gender) under same-transcript and cross-transcript conditions. It evaluates current LALMs as judges, claiming they lag human judgments by 32 percentage points on average and exhibit severe calibration failures, especially on Tie decisions where abstention is appropriate. The benchmark is positioned to enable multi-dimensional, calibration-aware assessment of LALM reliability for paralinguistic speech evaluation.
Significance. If the human annotations prove reliable, the benchmark would fill a gap in fine-grained evaluation of LALMs beyond holistic naturalness, with the same- vs. cross-transcript split providing a useful control for lexical vs. acoustic reliance. The calibration analysis on Tie cases is a timely contribution given increasing use of LALMs as judges.
major comments (2)
- [Abstract / Methods] Abstract and annotation description: the 5,175 human-labeled pairs are presented as ground truth for the five dimensions, yet no inter-annotator agreement statistics, number of annotators per pair, tie-resolution protocol, or validation against objective acoustic features are supplied. This directly undermines the 32%p gap and calibration claims, as low annotator consistency would render the LALM-human comparison uninterpretable.
- [Results] Results section (calibration analysis): the reported 'severe calibration failures' in Tie cases lack detail on the exact calibration metric, how human ties were collected and resolved, or statistical significance of the 32%p gap; without these, the severity and reproducibility of the finding cannot be assessed.
minor comments (1)
- [Abstract] The abstract claims 'multi-dimensional, calibration-aware assessment' but does not define the calibration metric or tie-handling procedure used for LALMs.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the annotation process and calibration analysis. These points are valid, and the revised manuscript will incorporate the requested details to strengthen the claims regarding human ground truth and LALM calibration failures.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and annotation description: the 5,175 human-labeled pairs are presented as ground truth for the five dimensions, yet no inter-annotator agreement statistics, number of annotators per pair, tie-resolution protocol, or validation against objective acoustic features are supplied. This directly undermines the 32%p gap and calibration claims, as low annotator consistency would render the LALM-human comparison uninterpretable.
Authors: We agree that these details are essential for establishing the reliability of the human labels. The revised version will add inter-annotator agreement statistics, the number of annotators per pair, the tie-resolution protocol, and an explicit discussion of the decision not to validate all dimensions against objective acoustic features (particularly for inherently subjective attributes such as Style). revision: yes
-
Referee: [Results] Results section (calibration analysis): the reported 'severe calibration failures' in Tie cases lack detail on the exact calibration metric, how human ties were collected and resolved, or statistical significance of the 32%p gap; without these, the severity and reproducibility of the finding cannot be assessed.
Authors: We will expand the Results section to specify the calibration metric, describe the collection and resolution procedure for human ties, and report appropriate statistical significance tests (e.g., bootstrap confidence intervals or paired tests) for the 32 percentage point gap. This will improve reproducibility and allow readers to assess the severity of the calibration issues. revision: yes
Circularity Check
No significant circularity; empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces ParaPairAudioBench as an empirical benchmark consisting of 5,175 audio pairs labeled across five paralinguistic dimensions. It reports direct comparisons of LALM judges against human judgments without any equations, fitted parameters, derivations, or load-bearing self-citations. The central results (32%p gap and calibration issues) are presented as outcomes of these comparisons rather than reductions to inputs by construction. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech generation systems have achieved remarkable progress, producing highly natural and expressive speech across diverse speakers and styles [1, 2, 3, 4]. However, naturalness alone does not guarantee that generated speech correctly follows the in- tended paralinguistic cues such as speaking rate, emphasis, or speaker characteristics. As a ...
Pith/arXiv arXiv 2026
-
[2]
How- ever, since this paradigm operates primarily on textual repre- sentations, it is unable to directly evaluate the acoustic and par- alinguistic properties of speech
Related Works To automate evaluation while preserving human-like judgment, theLLM-as-a-Judgeparadigm [8, 9, 11, 12] has shown strong alignment with human preferences in the text domain. How- ever, since this paradigm operates primarily on textual repre- sentations, it is unable to directly evaluate the acoustic and par- alinguistic properties of speech. T...
-
[3]
Both Good
Benchmark Design 3.1. Overview PARAPAIRAUDIOBENCHis a controlled diagnostic pairwise benchmark across five paralinguistic criteria—Style, Rate, Em- phasis, Age, and Gender—designed to diagnose whether a judge model can consistently identify which sample better sat- isfies a given criterion. The dataset comprises 5,175 instances from the validated public c...
-
[4]
Audio A” and “Audio B
Experimental Setup 4.1. Input Format Each model receives two audio inputs, Audio A and Audio B, along with an instruction specifying the target criterion regard- ing the given attribute, and is required to select the audio that better satisfies the criterion. If no meaningful distinction can be made, the model must select[[Tie]]. When presenting two audio...
-
[5]
Overall Performance and Human–Model Gap Table 2 reveals three key patterns
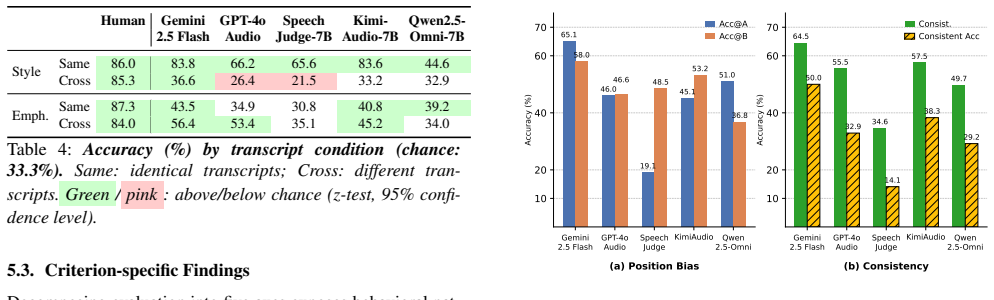
Analysis 5.1. Overall Performance and Human–Model Gap Table 2 reveals three key patterns. First, even the strongest model, Gemini 2.5 Flash, falls 17.7%p below human perfor- mance on average. Second, excluding Rate—which involves only binary choices—models on average achieve their high- est performance on Gender and Emphasis, whereas humans perform best o...
-
[6]
Conclusion We introduced PARAPAIRAUDIOBENCH, a pairwise bench- mark of 5,175 audio pairs designed to diagnose the reliability of LALM-as-a-Judge systems across five controllable paralinguis- tic criteria: Style, Rate, Emphasis, Age, and Gender. Our evalu- ation shows that current LALM judges still fall short of human judgments on average and exhibit syste...
-
[7]
All research design, ex- periments, analysis, and intellectual contributions are entirely the work of the authors
Use of generative AI tools Generative AI tools were used for editing and polishing the text and for generating figures in this paper. All research design, ex- periments, analysis, and intellectual contributions are entirely the work of the authors
-
[8]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiouet al., “Seed-tts: A family of high-quality versatile speech generation models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.02430
Pith/arXiv arXiv 2024
-
[9]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, E. Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X. Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and sheng zhao, “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openrev...
2024
-
[10]
Cosyvoice 2: Scalable streaming speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y . Gu, C. Deng, W. Wang, S. Zhang, Z. Yan, and J. Zhou, “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”
-
[11]
Available: https://arxiv.org/abs/2412.10117
[Online]. Available: https://arxiv.org/abs/2412.10117
-
[12]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 6255–6271
2025
-
[13]
K. Huang, Q. Tu, L. Fan, C. Yang, D. Zhang, S. Li, Z. Fei, Q. Cheng, and X. Qiu, “Instructttseval: Benchmarking complex natural-language instruction following in text-to-speech systems,” arXiv preprint arXiv:2506.16381, 2025
arXiv 2025
-
[14]
EmergentTTS-eval: Evaluating TTS models on complex prosodic, expressiveness, and linguistic challenges using model-as-a-judge,
R. R. Manku, Y . Tang, X. Shi, M. Li, and A. Smola, “EmergentTTS-eval: Evaluating TTS models on complex prosodic, expressiveness, and linguistic challenges using model-as-a-judge,” inThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. [Online]. Available: https: //openreview.net/forum?id=P3JBBnh10z
2025
-
[15]
S. wen Yanget al., “Paras2s: Benchmarking and aligning spoken language models for paralinguistic-aware speech-to- speech interaction,” 2025. [Online]. Available: https://arxiv.org/ abs/2511.08723
arXiv 2025
-
[16]
Judging LLM-as-a-judge with MT-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” inThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. [Online]. Available: https://openreview. net/forum?id=uccHPGDlao
2023
-
[17]
Length- controlled alpacaeval: A simple way to debias automatic evalua- tors,
Y . Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto, “Length- controlled alpacaeval: A simple way to debias automatic evalua- tors,”arXiv preprint arXiv:2404.04475, 2024
Pith/arXiv arXiv 2024
-
[18]
Speechjudge: Towards human-level judgment for speech naturalness,
X. Zhanget al., “Speechjudge: Towards human-level judgment for speech naturalness,” 2025. [Online]. Available: https: //arxiv.org/abs/2511.07931
arXiv 2025
-
[19]
Prometheus 2: An open source language model specialized in evaluating other language models,
S. Kim, J. Suk, S. Longpre, B. Y . Lin, J. Shin, S. Welleck, G. Neu- big, M. Lee, K. Lee, and M. Seo, “Prometheus 2: An open source language model specialized in evaluating other language models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 4334–4353
2024
-
[20]
Chatbot arena: An open platform for evaluating LLMs by human preference,
W.-L. Chiang, L. Zheng, Y . Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. Jordan, J. E. Gonzalez, and I. Stoica, “Chatbot arena: An open platform for evaluating LLMs by human preference,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openreview.net/forum?id=3MW8GKNyzI
2024
-
[21]
Audiojudge: Understanding what works in large audio model based speech evaluation,
P. Manakulet al., “Audiojudge: Understanding what works in large audio model based speech evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2507.12705
arXiv 2025
-
[22]
Audio-aware large language models as judges for speaking styles,
C.-H. Chiang, X. Wang, C.-C. Lin, K. Lin, L. Li, R. Kopetz, Y . Qian, Z. Wang, Z. Yang, H.-y. Lee, and L. Wang, “Audio-aware large language models as judges for speaking styles,” inFindings of the Association for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, Nov. 2025. [Online]. Available: https://aclanthology.org/2025....
2025
-
[23]
Speechllm-as-judges: Towards general and in- terpretable speech quality evaluation,
H. Wanget al., “Speechllm-as-judges: Towards general and in- terpretable speech quality evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2510.14664
Pith/arXiv arXiv 2025
-
[24]
Audio large language models can be descriptive speech quality evaluators,
C. Chen, Y . Hu, S. Wang, H. Wang, Z. Chen, C. Zhang, C.-H. H. Yang, and E. S. Chng, “Audio large language models can be descriptive speech quality evaluators,” 2025. [Online]. Available: https://arxiv.org/abs/2501.17202
arXiv 2025
-
[25]
Em- phassess: a prosodic benchmark on assessing emphasis transfer in speech-to-speech models,
M. de Seyssel, A. D’Avirro, A. Williams, and E. Dupoux, “Em- phassess: a prosodic benchmark on assessing emphasis transfer in speech-to-speech models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 495–507
2024
-
[26]
V ocalbench: Benchmarking the vo- cal conversational abilities for speech interaction models,
H. Liu, Y . Wang, Z. Cheng, H. Liu, Y . Li, Y . Hou, R. Wu, Q. Gu, Y . Wang, and Y . Wang, “V ocalbench: Benchmarking the vo- cal conversational abilities for speech interaction models,”arXiv preprint arXiv:2505.15727, 2025
arXiv 2025
-
[27]
Hearing between the lines: Unlocking the reasoning power of llms for speech evaluation,
A. Chandra, K. Miller, V . Ravichandran, C. Papayiannis, and V . Saligrama, “Hearing between the lines: Unlocking the reasoning power of llms for speech evaluation,” 2026. [Online]. Available: https://arxiv.org/abs/2601.13742
arXiv 2026
-
[28]
Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,
C.-K. Yang, N. Ho, Y .-T. Piao, and H.-y. Lee, “Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,” inProc. Interspeech 2025, 2025, pp. 1788–1792
2025
-
[29]
Ex- presso: A benchmark and analysis of discrete expressive speech resynthesis,
T. A. Nguyen, W.-N. Hsu, A. d’Avirro, B. Shi, I. Gat, M. Fazel- Zarani, T. Remez, J. Copet, G. Synnaeve, M. Hassidet al., “Ex- presso: A benchmark and analysis of discrete expressive speech resynthesis,” inINTERSPEECH 2023-24th Annual Conference of the International Speech Communication Association. ISCA, 2023, pp. 4823–4827
2023
-
[30]
Sonos voice control bias assessment dataset: A methodology for demographic bias assessment in voice assis- tants,
C. Sekkat, F. Leroy, S. Mdhaffar, B. P. Smith, Y . Est`eve, J. Dureau, and A. Coucke, “Sonos voice control bias assessment dataset: A methodology for demographic bias assessment in voice assis- tants,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), May 2024, pp...
2024
-
[31]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,” inProc. Interspeech 2019, 2019, pp. 1526–1530
2019
-
[32]
EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dereverberation,
J. Richteret al., “EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dereverberation,” in ISCA Interspeech, 2024, pp. 4873–4877
2024
-
[33]
G. Comaniciet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,” 2025. [Online]. Available: https://arxiv.org/abs/2507.06261
Pith/arXiv arXiv 2025
-
[34]
OpenAIet al., “Gpt-4o system card,” 2024. [Online]. Available: https://arxiv.org/abs/2410.21276
Pith/arXiv arXiv 2024
-
[35]
KimiTeamet al., “Kimi-audio technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2504.18425
Pith/arXiv arXiv 2025
-
[36]
Qwen2.5-omni technical report,
J. Xuet al., “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
Pith/arXiv arXiv 2025
-
[37]
Measuring nominal scale agreement among many raters,
J. Fleiss, “Measuring nominal scale agreement among many raters,”Psychological Bulletin, vol. 76, pp. 378–382, 11 1971
1971
-
[38]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”Biometrics, vol. 33, no. 1, pp. 159–174, 1977
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.