DTM-Codec: Dynamic Token Masking for VFR Speech Coding with Efficient Boundary Selection
Pith reviewed 2026-06-30 02:07 UTC · model grok-4.3
The pith
Dynamic token masking in a neural speech codec yields better quality and intelligibility than fixed-frame-rate methods once total bitrate including side information is matched.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DTM-Codec keeps selected encoder tokens, fills masked positions with a learned <MASK> embedding, and transmits a binary keep-mask for position-aware decoding; paired with Path Length Equalization for efficient boundary selection, this produces well-spread adaptive segments and delivers broad improvements in reconstruction quality and intelligibility over fixed-frame-rate baselines under a strict matched-total-bitrate protocol that includes all side information.
What carries the argument
Dynamic Token Masking, which retains chosen encoder tokens while filling the rest with a learned mask embedding and sending a binary keep-mask, combined with Path Length Equalization to select adaptive segment boundaries in linear time.
If this is right
- Reconstruction quality rises across multiple operating points once side-information bits are included in the bitrate budget.
- Intelligibility improves for the same total bitrate when frames are allocated according to local speech dynamics.
- Path Length Equalization supplies well-spread segments at negligible extra cost compared with prior boundary selectors.
- The mask-embedding approach allows the decoder to remain aware of original time positions without transmitting full frame indices.
Where Pith is reading between the lines
- The same keep-mask plus learned embedding pattern could be tested on other variable-rate signals such as video or sensor streams where redundancy is uneven.
- Joint training of the mask embedding with downstream tasks might further reduce the effective cost of the side information.
- Because boundary selection runs in linear time, the method could scale to longer utterances or real-time streaming without quadratic overhead.
Load-bearing premise
The bits required to send the binary keep-mask are small enough and correctly added to the total bitrate so that the measured quality gains survive after the overhead is counted.
What would settle it
An experiment that recomputes all quality and intelligibility scores after strictly adding the keep-mask bits to the reported bitrate and finds that the gains over fixed-frame-rate baselines shrink to zero or reverse.
Figures

read the original abstract
Variable frame rate (VFR) coding has recently emerged in neural speech codecs, allocating fewer frames to redundant regions and more frames to rapidly changing speech. VFR must transmit side information about retained time steps, but prior gains are either not rigorously addressed or often minor once these overhead bits are included in total bitrate. We present Dynamic Token Masking (DTM)-Codec, a neural speech codec that demonstrates clear gains over fixed-frame-rate baselines under a strict matched-total-bitrate protocol. DTM keeps selected encoder tokens, fills masked positions with a learned <MASK> embedding, and transmits a binary keep-mask for position-aware decoding. We further introduce Path Length Equalization (PLE), a linear-time boundary selector for VFR coding that yields well-spread adaptive segments with negligible overhead. Across operating points, DTM-Codec broadly improves reconstruction quality and intelligibility over fixed-frame-rate baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DTM-Codec, a neural speech codec for variable frame rate (VFR) coding. It retains selected encoder tokens, replaces masked positions with a learned <MASK> embedding, and transmits a binary keep-mask for position-aware decoding. It introduces Path Length Equalization (PLE) as a linear-time boundary selector claimed to produce well-spread segments with negligible overhead. The central claim is that DTM-Codec yields broad improvements in reconstruction quality and intelligibility over fixed-frame-rate baselines under a strict matched-total-bitrate protocol.
Significance. If the experimental results confirm that the reported gains persist after the binary keep-mask side information is fully included in the total bitrate calculation, the work would address a recurring limitation in prior VFR codecs where overhead often erodes claimed benefits. This could provide a practical, low-overhead route to adaptive-rate neural speech coding.
major comments (2)
- [Experiments / bitrate tables] The central claim requires that reconstruction and intelligibility gains hold after the binary keep-mask overhead (one bit per token position) is added to the total bitrate under a strict matched-total-bitrate protocol. The manuscript must provide explicit bitrate tables (likely in the experiments section) showing the keep-mask rate subtracted from the main codec allocation when comparing to fixed-frame-rate baselines; without this accounting the comparison is invalid.
- [Abstract and § on PLE / bitrate matching] The abstract states that overhead is negligible via PLE and that the protocol is followed, but the load-bearing step is the explicit verification that the effective rate for content tokens remains matched. If the mask is sent raw without entropy coding details or rate subtraction, the DTM-Codec effective rate could be lower, undermining the quality gains claim.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one quantitative result (e.g., PESQ or STOI delta at a matched bitrate point) rather than the qualitative statement 'broadly improves'.
- [Method description] Notation for the keep-mask transmission and its integration into the decoder should be clarified with a short equation or diagram to avoid ambiguity about position-aware decoding.
Simulated Author's Rebuttal
We thank the referee for the careful review and for underscoring the necessity of explicit bitrate accounting. We address both major comments below and will revise the manuscript to include the requested tables and clarifications.
read point-by-point responses
-
Referee: [Experiments / bitrate tables] The central claim requires that reconstruction and intelligibility gains hold after the binary keep-mask overhead (one bit per token position) is added to the total bitrate under a strict matched-total-bitrate protocol. The manuscript must provide explicit bitrate tables (likely in the experiments section) showing the keep-mask rate subtracted from the main codec allocation when comparing to fixed-frame-rate baselines; without this accounting the comparison is invalid.
Authors: We agree that explicit tables are required to substantiate the matched-total-bitrate protocol. The manuscript already adjusts the content-token allocation by subtracting the keep-mask rate (one bit per position) so that DTM-Codec and the fixed-frame-rate baselines operate at identical total rates; PLE is used to keep this overhead small. To make this fully transparent we will add bitrate tables in the experiments section that list, for each operating point, the keep-mask rate, the resulting content-token rate, and the matched baseline rate. revision: yes
-
Referee: [Abstract and § on PLE / bitrate matching] The abstract states that overhead is negligible via PLE and that the protocol is followed, but the load-bearing step is the explicit verification that the effective rate for content tokens remains matched. If the mask is sent raw without entropy coding details or rate subtraction, the DTM-Codec effective rate could be lower, undermining the quality gains claim.
Authors: The keep-mask is transmitted as raw binary side information and its rate is subtracted from the total budget before allocating bits to content tokens, ensuring the effective content rate matches the baselines. We will expand the PLE and bitrate-matching sections with the explicit per-point calculations and the new tables, and will state whether any entropy coding is applied to the mask. These additions will confirm that the reported quality gains are obtained under the strict matched-total-bitrate condition. revision: yes
Circularity Check
No circularity in derivation chain; claims are empirical.
full rationale
The paper advances an empirical neural codec architecture and reports quality gains under an explicitly stated matched-total-bitrate protocol. No equations, derivations, or self-citations appear in the provided text that reduce any claimed prediction or result to a quantity defined by its own inputs or fitted parameters. The central assertions rest on experimental comparisons rather than a mathematical chain that collapses by construction. The bitrate-overhead concern is an experimental-verification issue, not a circularity in any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Neural audio codecs have become a central tokenization layer for speech language models [1, 2, 3], text-to-speech synthesis [4], and audio generation [ 5]. The field has advanced from multi- codebook residual vector quantization (RVQ) systems such as SoundStream and EnCodec toward single-codebook tokenizers and semantic-aware designs [ 6, 7, ...
-
[2]
The binary mask is transmitted as compact position bits, en- abling position-aware decoding
Dynamic Token Masking (DTM).Rather than merging or pooling features, we retain selected encoder tokens and fill missing positions with a learnable <MASK> embedding. The binary mask is transmitted as compact position bits, en- abling position-aware decoding. This formulation yields the strongest overall reconstruction among common down/up- sampling alterna...
-
[3]
Path Length Equalization (PLE).We introduce an O(N) boundary selector that partitions the cumulative feature change along the encoder trajectory into equal-length segments. Com- pared with representative heuristic and optimization-based selectors—including those used by V ARSTok, FlexiCodec, and CodecSlime—PLE achieves well-spread temporal cover- age with...
-
[4]
DTM-Codec: Dynamic Token Masking for VFR Speech Coding with Efficient Boundary Selection
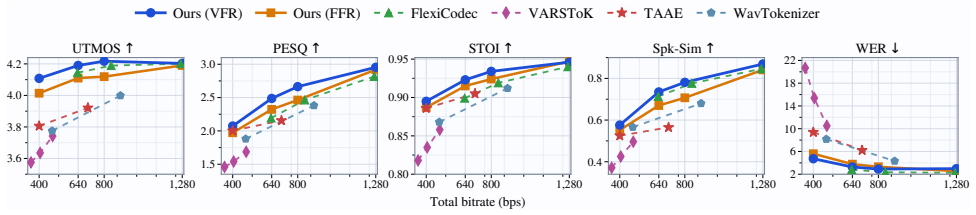
Strict matched-total-bitrate training and evaluation.We train and evaluate matched-rate VFR and FFR under a unified protocol that counts both content and timing-side-information bits across low-to-high frame-rate operating points. This con- trolled setup enables direct and fair comparisons and reveals clear and broadly VFR advantages over fixed-frame-rate...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Neural Audio Codecs Neural audio codecs (NACs) typically follow the VQ-V AE/VQ- GAN paradigm [20], learning an encoder–decoder with a dis- crete bottleneck [6, 7]
Related Work 2.1. Neural Audio Codecs Neural audio codecs (NACs) typically follow the VQ-V AE/VQ- GAN paradigm [20], learning an encoder–decoder with a dis- crete bottleneck [6, 7]. SoundStream and EnCodec use residual vector quantization (RVQ) with multiple codebooks to scale bitrate [6, 7]. Recent work pushes toward lower bitrates and LM-friendly token ...
-
[6]
total bitrate
Method 3.1. Model Architecture 3.1.1. Backbone DTM-Codec builds on the two-stage transformer encoder– decoder of TAAE [14] (Figure 1). The hierarchical encoder– decoder decomposes into a dense Stage-1 operating at the full temporal resolution and a compressed Stage-2 processing a re- duced token set. The fixed-rate strided convolution between stages can b...
-
[7]
Experiments 4.1. Experimental Setup Dataset and training.All models are trained on LibriSpeech- 960 [19] at 16 kHz for 600k steps on 2×RTX 4090 with batch size 64, AdamW ((β1, β2)=(0.8,0.9)), and bf16 precision. Model configurations.We compare two primary model vari- ants: • VFR(PLE): Trained from scratch with fixed keep ratio r=0.5. Single-codebook VQ (|...
2082
-
[8]
Conclusion We presented DTM-Codec, a neural speech codec that broadly outperforms fixed-rate baselines under strict matched-total- bitrate evaluation with explicit position-bit accounting. Dynamic Token Masking preserves selected features exactly while mark- ing missing positions for position-aware decoding, and Path Length Equalization provides a linear-...
-
[9]
RS-2023-00222383)
Acknowledgements This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2023-00222383)
2023
-
[10]
Use of Generative AI Disclosure Generative AI tools were used solely for grammar correction and manuscript formatting, not for generating scientific content
-
[11]
AudioLM: a language modeling approach to audio genera- tion,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “AudioLM: a language modeling approach to audio genera- tion,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2523–2533, 2023
2023
-
[12]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language mod- els are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Llasa: Scaling train-time and inference-time compute for Llama-based speech synthesis,
Z. Ye, X. Zhu, C.-M. Chan, X. Wang, X. Tan, J. Lei, Y . Peng, H. Liu, Y . Jin, Z. Daiet al., “Llasa: Scaling train-time and inference-time compute for Llama-based speech synthesis,”arXiv preprint arXiv:2502.04128, 2025
-
[14]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language models are zero-shot text to speech synthesizers,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[15]
AudioGen: Textually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “AudioGen: Textually guided audio generation,”arXiv preprint arXiv:2209.15352, 2022
-
[16]
SoundStream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasac- chi, “SoundStream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 30, pp. 495–507, 2022
2022
-
[17]
High Fidelity Neural Audio Compression
A. D´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neu- ral audio compression,”arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[19]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liuet al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,”arXiv preprint arXiv:2408.17175, 2024
-
[20]
Recent advances in discrete speech tokens: A review,
H. Zhang, Y . Guo, C. Du, Z. Li, X. Chen, and K. Yu, “Recent advances in discrete speech tokens: A review,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2025
2025
-
[21]
Discrete audio tokens: More than a survey!
P. Mousavi, G. Maimon, A. Moumen, D. Petermann, J. Shi, H. Wu, H. Yang, A. Kuznetsova, A. Ploujnikov, R. Marxer, B. Ramab- hadran, B. Elizalde, L. Lugosch, J. Li, C. Subakan, P. Wood- land, M. Kim, H.-y. Lee, S. Watanabe, Y . Adi, and M. Ravanelli, “Discrete audio tokens: More than a survey!”arXiv preprint arXiv:2506.10274, 2025
-
[22]
BigCodec: Push- ing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “BigCodec: Push- ing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
-
[23]
WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” arXiv preprint arXiv:2408.16532, 2024
-
[24]
Scaling transformers for low-bitrate high-quality speech coding,
J. D. Parker, A. Smirnov, J. Pons, C. Carr, Z. Zukowski, Z. Evans, and X. Liu, “Scaling transformers for low-bitrate high-quality speech coding,”arXiv preprint arXiv:2411.19842, 2024
-
[25]
Unlocking temporal flexibility: Neural speech codec with variable frame rate,
H. Zhang, Y . Guo, Z. Li, X. Hao, X. Chen, and K. Yu, “Unlocking temporal flexibility: Neural speech codec with variable frame rate,” arXiv preprint arXiv:2505.16845, 2025
-
[26]
R.-C. Zheng, W. Liu, H.-P. Duet al., “Say more with less: Variable- frame-rate speech tokenization via adaptive clustering and implicit duration coding,”arXiv preprint arXiv:2509.04685, 2025
-
[27]
CodecSlime: Tem- poral redundancy compression of neural speech codec via dynamic frame rate,
H. Wang, Y . Guo, C. Shao, B. Li, and K. Yu, “CodecSlime: Tem- poral redundancy compression of neural speech codec via dynamic frame rate,”arXiv preprint arXiv:2506.21074, 2025
-
[28]
FlexiCodec: A dynamic neural audio codec for low frame rates,
J. Li, Y . Qian, Y . Hu, L. Zhang, X. Wang, H. Lu, M. Thakker, J. Li, S. Zhao, and Z. Wu, “FlexiCodec: A dynamic neural audio codec for low frame rates,”arXiv preprint arXiv:2510.00981, 2025
-
[29]
LibriSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: An ASR corpus based on public domain audio books,” inProc. ICASSP. IEEE, 2015, pp. 5206–5210
2015
-
[30]
Neural dis- crete representation learning,
A. Van Den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural dis- crete representation learning,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[31]
Finite scalar quantization: VQ-V AE made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Finite scalar quantization: VQ-V AE made simple,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=8ishA3Lx N8
2024
-
[32]
SNAC: Multi-scale neural audio codec,
H. Siuzdak, F. Gr ¨otschla, and L. A. Lanzend ¨orfer, “SNAC: Multi-scale neural audio codec,”arXiv preprint arXiv:2410.14411,
-
[33]
Available: https://github.com/hubertsiuzdak/snac
[Online]. Available: https://github.com/hubertsiuzdak/snac
-
[34]
SpeechTokenizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “SpeechTokenizer: Unified speech tokenizer for speech language models,” inProc. ICLR, 2024
2024
-
[35]
Variable-rate discrete representation learning,
S. Dieleman, C. Nash, J. Engel, and K. Simonyan, “Variable-rate discrete representation learning,”arXiv preprint arXiv:2103.06089, 2021
-
[36]
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech,
S. Cuervo, A. Lancucki, R. Marxer, P. Rychlikowski, and J. K. Chorowski, “Variable-rate hierarchical CPC leads to acoustic unit discovery in speech,” inAdvances in Neural Information Process- ing Systems, vol. 35, 2022, pp. 34 995–35 006
2022
-
[37]
SD-HuBERT: Sentence-level self-distillation in- duces syllabic organization in HuBERT,
C. J. Cho, A. Mohamed, S.-W. Li, A. W. Black, and G. K. Anu- manchipalli, “SD-HuBERT: Sentence-level self-distillation in- duces syllabic organization in HuBERT,” inProc. ICASSP. IEEE, 2024, pp. 12 076–12 080
2024
-
[38]
TaDi- Codec: Text-aware diffusion speech tokenizer for speech language modeling,
Y . Wang, D. Chen, X. Zhang, J. Zhang, J. Li, and Z. Wu, “TaDi- Codec: Text-aware diffusion speech tokenizer for speech language modeling,”arXiv preprint arXiv:2508.16790, 2025
-
[39]
PoWER-BERT: Accelerating BERT inference via progressive word-vector elimination,
S. Goyal, A. R. Choudhury, S. Raje, V . T. Chakaravarthy, Y . Sabhar- wal, and A. Verma, “PoWER-BERT: Accelerating BERT inference via progressive word-vector elimination,” inICML, 2020
2020
-
[40]
Length-adaptive transformer: Train once with length drop, use anytime with search,
G. Kim and K. Cho, “Length-adaptive transformer: Train once with length drop, use anytime with search,”arXiv preprint arXiv:2010.07003, 2020
-
[41]
Learned token pruning for transformers,
S. Kim, S. Shen, D. Thorsley, A. Gholami, W. Kwon, J. Hassoun, and K. Keutzer, “Learned token pruning for transformers,”arXiv preprint arXiv:2107.00910, 2021
-
[42]
Dy- namicViT: Efficient vision transformers with dynamic token spar- sification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dy- namicViT: Efficient vision transformers with dynamic token spar- sification,”Advances in Neural Information Processing Systems, 2021
2021
-
[43]
SPViT: Enabling faster vision transformers via soft token pruning,
Z. Kong, P. Dong, X. Ma, X. Meng, W. Niu, M. Sun, B. Ren, M. Qin, H. Tang, and Y . Wang, “SPViT: Enabling faster vision transformers via soft token pruning,” inECCV, 2022
2022
-
[44]
Adaptive Token Sampling For Efficient Vision Transformers,
M. Fayyaz, S. A. Kouhpayegani, F. R. Jafari, E. Sommerlade, H. R. V . Joze, H. Pirsiavash, and J. Gall, “Adaptive Token Sampling For Efficient Vision Transformers,” inECCV, 2022
2022
-
[45]
Token pooling in vision transformers,
D. Marin, J.-H. R. Chang, A. Ranjan, A. Prabhu, M. Rastegari, and O. Tuzel, “Token pooling in vision transformers,”arXiv preprint arXiv:2110.03860, 2021
-
[46]
TokenLearner: Adaptive Space-Time Tokenization for Videos,
M. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. An- gelova, “TokenLearner: Adaptive Space-Time Tokenization for Videos,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[47]
Effi- cient transformers with dynamic token pooling,
P. Nawrot, J. Chorowski, A. Lancucki, and E. M. Ponti, “Effi- cient transformers with dynamic token pooling,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 6403–6417
2023
-
[48]
Not all patches are what you need: Expediting vision transformers via token reorganizations,
Y . Liang, C. Ge, Z. Tong, Y . Song, J. Wang, and P. Xie, “Not all patches are what you need: Expediting vision transformers via token reorganizations,”International Conference on Learning Representations, 2022
2022
-
[49]
Token merging: Your ViT but faster,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoff- man, “Token merging: Your ViT but faster,” inICLR, 2023
2023
-
[50]
Token merging for fast stable diffusion,
D. Bolya and J. Hoffman, “Token merging for fast stable diffusion,” CVPR Workshop on Efficient Deep Learning for Computer Vision, 2023
2023
-
[51]
ComplexDec: A domain-robust high-fidelity neural audio codec with complex spectrum modeling,
Y .-C. Wu, D. Markovi´c, S. Krenn, I. D. Gebru, and A. Richard, “ComplexDec: A domain-robust high-fidelity neural audio codec with complex spectrum modeling,”arXiv preprint arXiv:2502.02019, 2025
-
[52]
iSTFTNet: Fast and lightweight mel-spectrogram vocoder incorporating inverse short-time Fourier transform,
T. Kaneko, K. Tanaka, H. Kameoka, and S. Seki, “iSTFTNet: Fast and lightweight mel-spectrogram vocoder incorporating inverse short-time Fourier transform,” inProc. ICASSP. IEEE, 2022, pp. 6207–6211
2022
-
[53]
V ocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis,” in The Twelfth International Conference on Learning Representations, 2024
2024
-
[54]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[55]
GLU Variants Improve Transformer
N. Shazeer, “GLU variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[56]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,” Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[57]
RoFormer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: Enhanced transformer with rotary position embedding,”Neurocom- puting, vol. 568, p. 127063, 2024
2024
-
[58]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R´e, “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,” in Advances in Neural Information Processing Systems, vol. 35, 2022
2022
-
[59]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,”Advances in Neural Information Processing Systems, vol. 33, pp. 17 022– 17 033, 2020
2020
-
[60]
Least squares generative adversarial networks,
X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. P. Smolley, “Least squares generative adversarial networks,” inProc. ICCV, 2017, pp. 2794–2802
2017
-
[61]
The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,
K. Baba, W. Nakata, Y . Saito, and H. Saruwatari, “The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 818–824
2024
-
[62]
UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022,” inProc. Interspeech, vol. 2022, 2022, pp. 4521– 4525
2022
-
[63]
Per- ceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per- ceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs,” in Proc. ICASSP, vol. 2. IEEE, 2001, pp. 749–752
2001
-
[64]
An algorithm for intelligibility prediction of time–frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125–2136, 2011
2011
-
[65]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505– 1518, 2022
2022
-
[66]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 12 449–12 460
2020
-
[67]
HuBERT: Self-supervised speech representa- tion learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “HuBERT: Self-supervised speech representa- tion learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[68]
Benchmarking representations for speech, music, and acoustic events,
M. La Quatra, A. Koudounas, L. Vaiani, E. Baralis, L. Cagliero, P. Garza, and S. M. Siniscalchi, “Benchmarking representations for speech, music, and acoustic events,” inProc. ICASSPW. IEEE, 2024, pp. 505–509
2024
-
[69]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A large-scale multilingual dataset for speech research,” inProc. Interspeech, 2020, pp. 2757–2761
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.