FundaPod: A Multi-Persona Agent Pod Platform with Knowledge Graph Memory for AI-Assisted Fundamental Investment Research
Pith reviewed 2026-06-29 12:37 UTC · model grok-4.3
The pith
Fundamental research requires independent AI personas whose disagreements are adjudicated by humans via a knowledge-graph memory system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FundaPod is a multi-persona agent platform in which AI agents embodying different investor personas, such as value investors or macro strategists, perform independent research linked by a shared provenance contract; their outputs are stored in a knowledge-graph memory system that surfaces disagreements for adjudication by the human portfolio manager, enabling the production of transparent, reusable, and verifiable investment memos while advancing cumulative investment knowledge.
What carries the argument
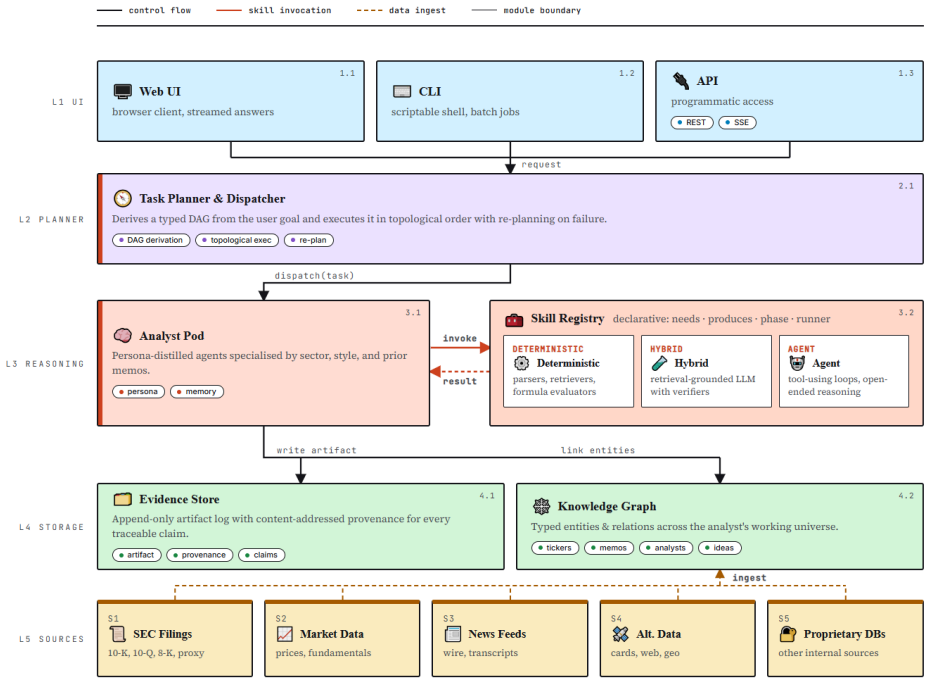
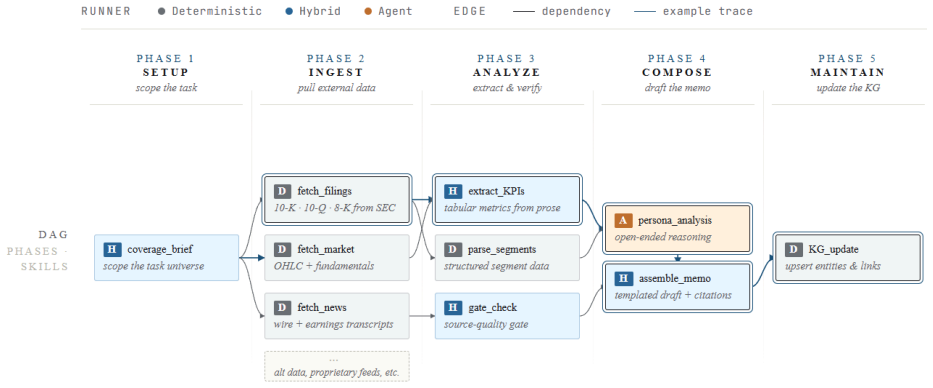
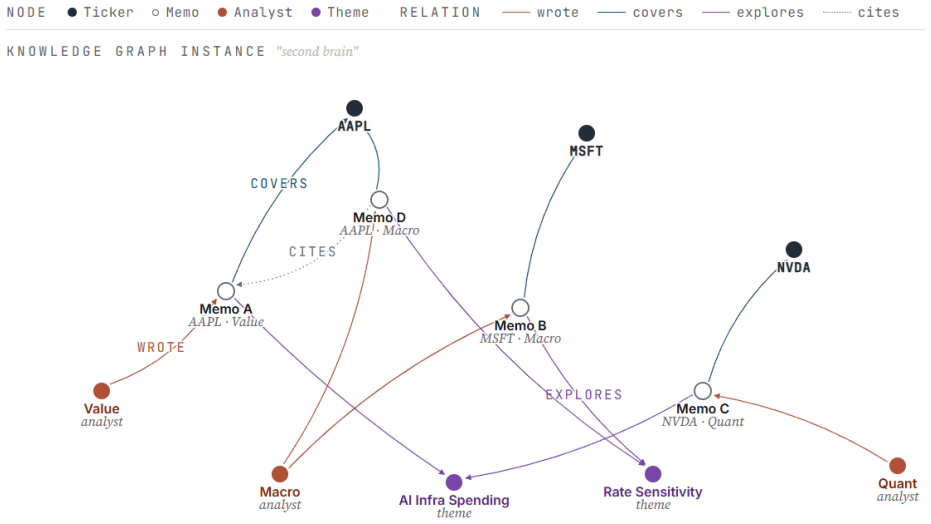
The independence-preserving architecture consisting of persona-distilled agents, a declarative skill registry, grounded evidence model, and knowledge-graph second brain that connects tickers, memos, analysts, and themes.
If this is right
- Investment plans produced are transparent, reusable, and verifiable through links to sources.
- Disagreements between personas are surfaced post hoc for human resolution rather than averaged into a single output.
- The system contributes to cumulative development of investment knowledge across memos, tickers, and themes.
- Five design principles for human-AI hybrid systems are established based on cognitive isolation and coordination.
- The architecture is demonstrated through a complete case study and persona-based memo comparison.
Where Pith is reading between the lines
- This architecture could extend to other human-centric multi-viewpoint tasks such as policy analysis or legal review.
- Accumulated knowledge-graph data might later support automated detection of recurring themes across memos.
- Performance could be tested by tracking whether portfolio decisions differ when managers see the surfaced persona disagreements.
- The persona distillation pipeline from public materials could enable quick addition of new investor styles without retraining.
Load-bearing premise
AI agents with different personas generate sufficiently independent outputs whose disagreements can be meaningfully surfaced and resolved by the human portfolio manager through the knowledge-graph system.
What would settle it
A controlled comparison in which human portfolio managers show no measurable improvement in decision quality or speed when using the multi-persona surfaced disagreements and knowledge-graph links versus single-agent summaries on the same investment cases.
Figures






read the original abstract
Large language models (LLMs) are increasingly applied in finance, yet most existing work emphasizes trading signals or financial NLP tasks centered on prediction. Institutional fundamental research, by contrast, requires human analysts or AI agents to gather evidence, identify business drivers, compare competing viewpoints, and generate investment memos. Its broader goal is not merely to predict outcomes, but to produce investment plans that are transparent, reusable, and verifiable, while contributing to the cumulative development of investment knowledge. We present FundaPod, a multi-persona agent platform for AI-assisted fundamental investment research. We argue that fundamental research is a human-centric decision-support task that is qualitatively distinct from trading-signal generation, and is therefore better served by an independence-preserving architecture. In FundaPod, AI agents with different personas, such as value investors or macro strategists, conduct research independently under a shared provenance contract. Their disagreements are then surfaced post hoc for adjudication by the human portfolio manager (PM) through a knowledge-graph memory system. This paper contributes five design principles for human-AI hybrid systems supporting fundamental research, grounded in design-science practice and theories of cognitive isolation and human-machine coordination. It also describes four architectural mechanisms: a persona distillation pipeline that turns public investor materials into deployable agents; a declarative skill registry that lets the planner derive typed task graphs; a grounded evidence model that links memo claims to verifiable sources; and a knowledge-graph "second brain" that connects tickers, memos, analysts, and themes. We demonstrate the architecture through a complete case study and a persona-based memo comparison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FundaPod, a multi-persona agent platform for AI-assisted fundamental investment research. It argues that fundamental research is a human-centric decision-support task qualitatively distinct from trading-signal generation and therefore benefits from an independence-preserving architecture: persona agents (e.g., value investors or macro strategists) operate independently under a shared provenance contract, with disagreements surfaced post hoc for adjudication by a human portfolio manager via a knowledge-graph memory system. The paper contributes five design principles grounded in design-science practice and theories of cognitive isolation and human-machine coordination, plus four mechanisms (persona distillation pipeline, declarative skill registry, grounded evidence model, and KG second brain) and demonstrates the system via a complete case study and persona-based memo comparison.
Significance. If the core assumption of sufficient persona independence holds, the architecture could advance human-AI hybrid systems in finance by prioritizing transparent, verifiable, and cumulative research outputs over pure predictive tasks. The grounded evidence model and knowledge-graph memory for provenance and theme linking represent concrete strengths that address reusability needs in institutional research.
major comments (2)
- [Case Study] Case Study section: the persona-based memo comparison supplies only qualitative example outputs and does not report any quantitative metrics (e.g., embedding cosine similarity across personas, inter-persona disagreement rates, or ablation against single-persona baselines). This directly undermines the load-bearing claim that the independence-preserving design yields sufficiently independent research outputs whose disagreements can be meaningfully resolved.
- [Architectural Mechanisms] Architectural Mechanisms (persona distillation pipeline): the description does not address or measure the risk that a shared LLM base model and training data will induce correlated reasoning across personas, which is required to substantiate the asserted superiority over standard multi-agent setups.
minor comments (2)
- [Abstract] Abstract: the five design principles and four mechanisms are referenced but not enumerated, reducing immediate clarity for readers.
- [Architectural Mechanisms] The provenance contract and grounded evidence model are introduced without explicit formal definitions or pseudocode, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the empirical support for our claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Case Study] Case Study section: the persona-based memo comparison supplies only qualitative example outputs and does not report any quantitative metrics (e.g., embedding cosine similarity across personas, inter-persona disagreement rates, or ablation against single-persona baselines). This directly undermines the load-bearing claim that the independence-preserving design yields sufficiently independent research outputs whose disagreements can be meaningfully resolved.
Authors: We agree that the current case study relies on qualitative examples and that quantitative metrics are needed to substantiate the independence claim. In the revised manuscript we will add embedding cosine similarity scores between persona-generated memos, inter-persona disagreement rates computed from claim-level overlap in the grounded evidence model, and an ablation comparing multi-persona outputs against single-persona baselines. These additions will be placed in an expanded Case Study section with accompanying tables. revision: yes
-
Referee: [Architectural Mechanisms] Architectural Mechanisms (persona distillation pipeline): the description does not address or measure the risk that a shared LLM base model and training data will induce correlated reasoning across personas, which is required to substantiate the asserted superiority over standard multi-agent setups.
Authors: We acknowledge that the risk of correlated reasoning from a shared base model is not explicitly addressed. In the revision we will expand the persona distillation pipeline subsection to discuss this limitation, describe mitigation steps (distinct fine-tuning corpora and prompt isolation), and report a preliminary divergence analysis using the same quantitative metrics added to the case study. This will clarify the design's intended advantages while noting remaining constraints. revision: yes
Circularity Check
No significant circularity; derivation rests on external theories and qualitative demonstration
full rationale
The paper frames its independence-preserving architecture as grounded in design-science practice and theories of cognitive isolation and human-machine coordination, without equations, fitted parameters renamed as predictions, or load-bearing self-citations. The persona distillation and KG mechanisms are described as contributions, and the case study is presented as demonstration rather than a self-referential derivation. No steps reduce by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fundamental research requires gathering evidence, identifying business drivers, comparing viewpoints, and generating transparent investment memos rather than mere outcome prediction.
invented entities (1)
-
persona distillation pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ISSN 0276-7783. doi: 10.25300/MISQ/2021/16274. Sushil Bikhchandani, David Hirshleifer, and Ivo Welch. A theory of fads, fashion, custom, and cultural change as informational cascades.Journal of political Economy, 100(5):992–1026,
-
[2]
Chatgpt informed graph neural network for stock movement prediction.arXiv preprint arXiv:2306.03763,
Zihan Chen, Lei Nico Zheng, Cheng Lu, Jialu Yuan, and Di Zhu. Chatgpt informed graph neural network for stock movement prediction.arXiv preprint arXiv:2306.03763,
-
[3]
Han Ding, Yinheng Li, Junhao Wang, Hang Chen, Doudou Guo, and Yunbai Zhang
doi: 10.1007/s12525-018-0309-2. Han Ding, Yinheng Li, Junhao Wang, Hang Chen, Doudou Guo, and Yunbai Zhang. Large language model agent in financial trading: A survey.arXiv preprint arXiv:2408.06361,
-
[4]
Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers
Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers. arXiv preprint arXiv:2603.07670,
-
[5]
Tianyu Fan, Yuhao Yang, Yangqin Jiang, Yifei Zhang, Yuxuan Chen, and Chao Huang. Ai-trader: Benchmarking autonomous agents in real-time financial markets.arXiv preprint arXiv:2512.10971,
-
[6]
ISSN 1047-7047. doi: 10.1287/isre.2021.1079. Hui Gong. Ai agents in financial markets: Architecture, applications, and systemic implications. FinTech, 5(2),
-
[7]
ISSN 2674-1032. doi: 10.3390/fintech5020034. Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Franco Turini, Fosca Giannotti, and Dino Pedreschi. A survey of methods for explaining black box models.ACM computing surveys (CSUR), 51(5):1–42,
-
[8]
doi: 10.2307/ 25148625
ISSN 0276-7783. doi: 10.2307/ 25148625. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pages 23247–23275,
2024
-
[9]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Dongming Jiang, Yi Li, Guanpeng Li, and Bingzhe Li. Magma: A multi-graph based agentic memory architecture for ai agents.arXiv preprint arXiv:2601.03236,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ISSN 1047-7039. doi: 10.1287/orsc.2021.1549. Weixian Waylon Li, Hyeonjun Kim, Mihai Cucuringu, and Tiejun Ma. Can llm-based financial investing strategies outperform the market in long run? InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 2711–2722,
-
[11]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
22 Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kunihiro Miyazaki, Takanobu Kawahara, Stephen Roberts, and Stefan Zohren. Toward expert investment teams: A multi-agent llm system with fine-grained trading tasks.arXiv preprint arXiv:2602.23330,
-
[13]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
ChatDev: Communicative agents for software development
doi: 10.18653/v1/2024.acl-long.810. A Rai, P Constantinides, and S Sarker. Next-generation digital platforms: Toward human-ai hybrid systems.MIS Quarterly, 47(1):1–25,
-
[15]
ISSN 0378-7206. doi: https://doi.org/10.1016/j. im.2019.103174. Minjie Shen, Yanshu Li, Lulu Chen, Zhichao Fan, Yanhang Li, and Qikai Yang. From mind to machine: The rise of manus ai as a fully autonomous digital agent.arXiv preprint arXiv:2505.02024,
work page doi:10.1016/j 2019
-
[16]
Voyager: An Open-Ended Embodied Agent with Large Language Models
ISSN 0276-7783. doi: 10.25300/ MISQ/2021/16543. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhan- jan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
Zhaofen Wu, Hanrong Zhang, Fulin Lin, Wujiang Xu, Xinran Xu, Yankai Chen, Henry Peng Zou, Shaowen Chen, Weizhi Zhang, Xue Liu, et al. Gam: Hierarchical graph-based agentic memory for llm agents.arXiv preprint arXiv:2604.12285,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Tradingagents: Multi-agents llm financial trading framework.arXiv preprint arXiv:2412.20138,
Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. Tradingagents: Multi-agents llm financial trading framework.arXiv preprint arXiv:2412.20138,
-
[20]
Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665,
Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, et al. Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665,
-
[21]
Fingpt: Open-source financial large language models.arXiv preprint arXiv:2306.06031,
Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. Fingpt: Open-source financial large language models.arXiv preprint arXiv:2306.06031,
-
[22]
doi: 10.1109/TBDATA.2025.3593370. Wentao Zhang, Lingxuan Zhao, Haochong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, Longtao Zheng, Xinrun Wang, and Bo An. A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Disc...
-
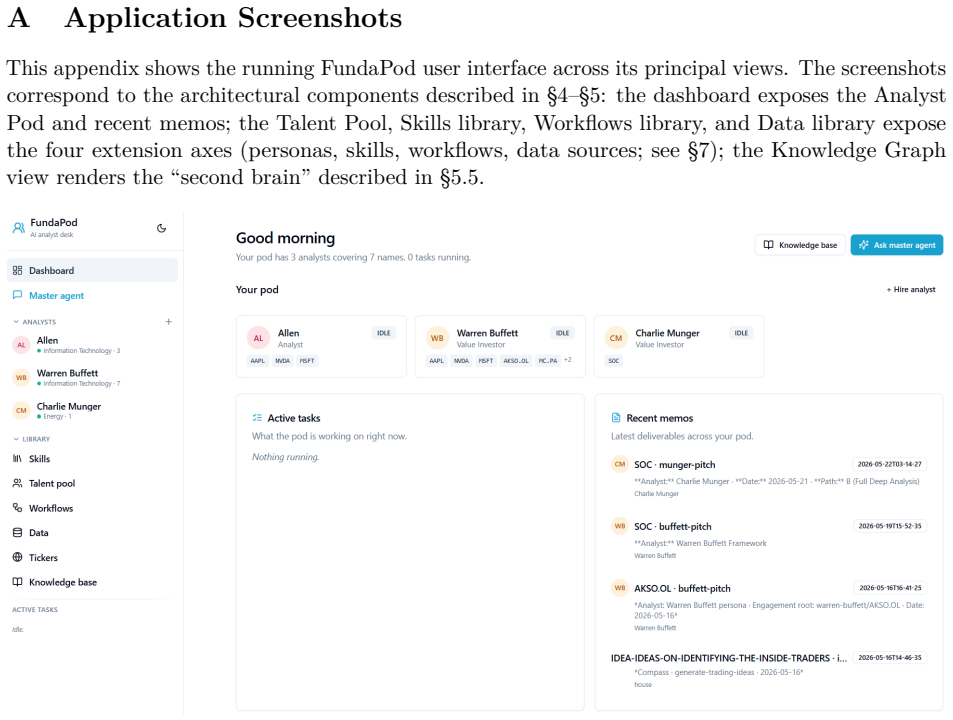
[23]
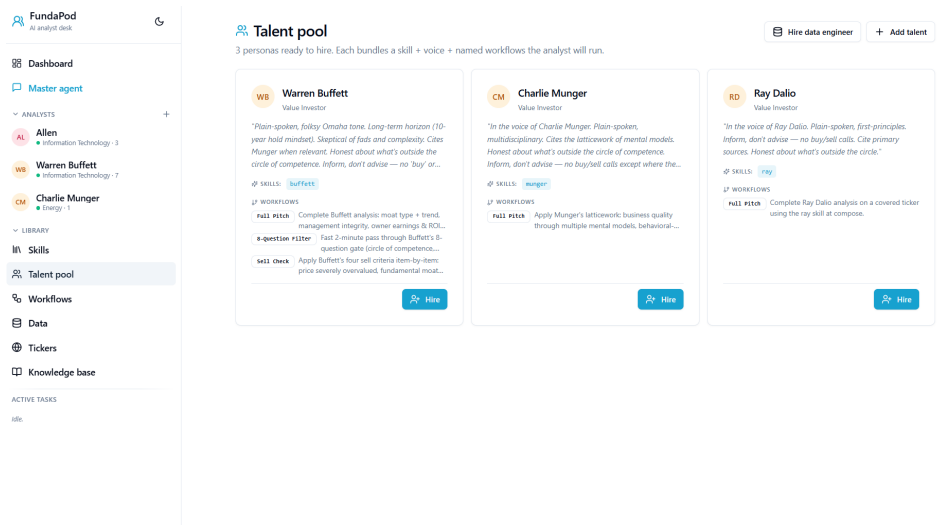
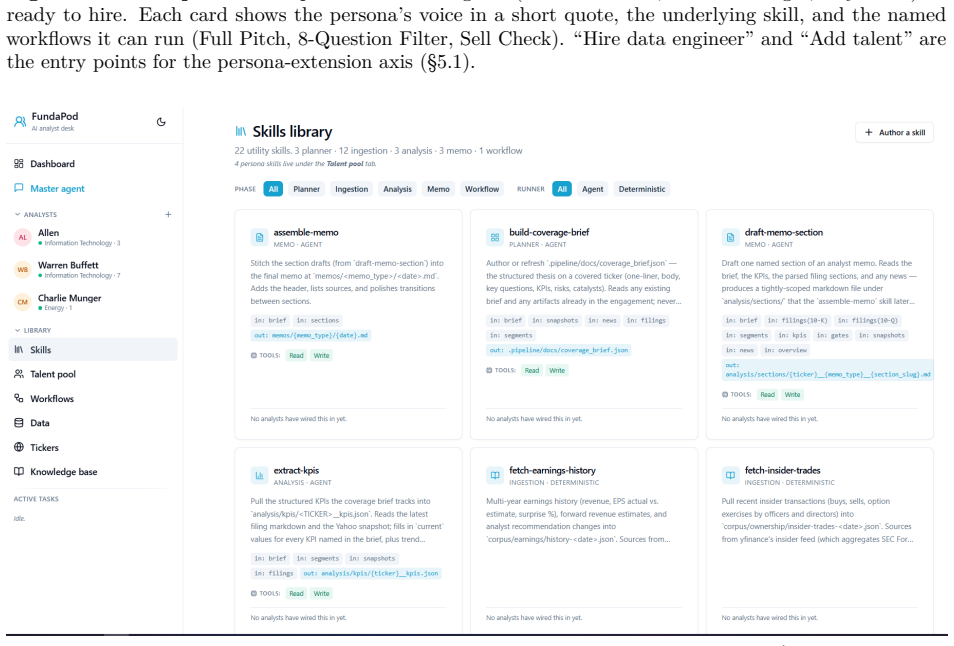
Association for Computing Machinery. ISBN 9798400704901. doi: 10.1145/3637528.3671801. 24 A Application Screenshots This appendix shows the running FundaPod user interface across its principal views. The screenshots correspond to the architectural components described in §4–§5: the dashboard exposes the Analyst Pod and recent memos; the Talent Pool, Skill...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.