Recognition: unknown
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
Pith reviewed 2026-05-10 16:19 UTC · model grok-4.3
The pith
GAM decouples event-level memory encoding from topic-level consolidation in LLM agents using hierarchical graphs to reduce interference and improve long-term coherence and retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
we propose GAM, a hierarchical Graph-based Agentic Memory framework that explicitly decouples memory encoding from consolidation to effectively resolve the conflict between rapid context perception and stable knowledge retention. By isolating ongoing dialogue in an event progression graph and integrating it into a topic associative network only upon semantic shifts, our approach minimizes interference while preserving long-term consistency.
Load-bearing premise
The assumption that semantic shifts can be reliably and timely detected to trigger integration from the event progression graph into the topic associative network without missing critical context or introducing excessive interference.
Figures




read the original abstract
To sustain coherent long-term interactions, Large Language Model (LLM) agents must navigate the tension between acquiring new information and retaining prior knowledge. Current unified stream-based memory systems facilitate context updates but remain vulnerable to interference from transient noise. Conversely, discrete structured memory architectures provide robust knowledge retention but often struggle to adapt to evolving narratives. To address this, we propose GAM, a hierarchical Graph-based Agentic Memory framework that explicitly decouples memory encoding from consolidation to effectively resolve the conflict between rapid context perception and stable knowledge retention. By isolating ongoing dialogue in an event progression graph and integrating it into a topic associative network only upon semantic shifts, our approach minimizes interference while preserving long-term consistency. Additionally, we introduce a graph-guided, multi-factor retrieval strategy to enhance context precision. Experiments on LoCoMo and LongDialQA indicate that our method consistently outperforms state-of-the-art baselines in both reasoning accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GAM, a hierarchical Graph-based Agentic Memory framework for LLM agents that decouples memory encoding from consolidation. Ongoing dialogue is isolated in an event progression graph and integrated into a topic associative network only upon detected semantic shifts, with the goal of minimizing interference while preserving long-term consistency. A graph-guided multi-factor retrieval strategy is also introduced. The work claims consistent outperformance over state-of-the-art baselines on the LoCoMo and LongDialQA benchmarks in both reasoning accuracy and efficiency.
Significance. If the empirical claims hold under rigorous validation, the explicit decoupling of encoding and consolidation via hierarchical graphs represents a meaningful advance for long-term coherence in LLM agents. The approach directly targets the interference-retention tension in stream-based versus structured memory systems. Credit is due for the clean architectural separation and the graph-based retrieval mechanism, which could serve as a reusable design pattern even if specific performance numbers require further substantiation.
major comments (3)
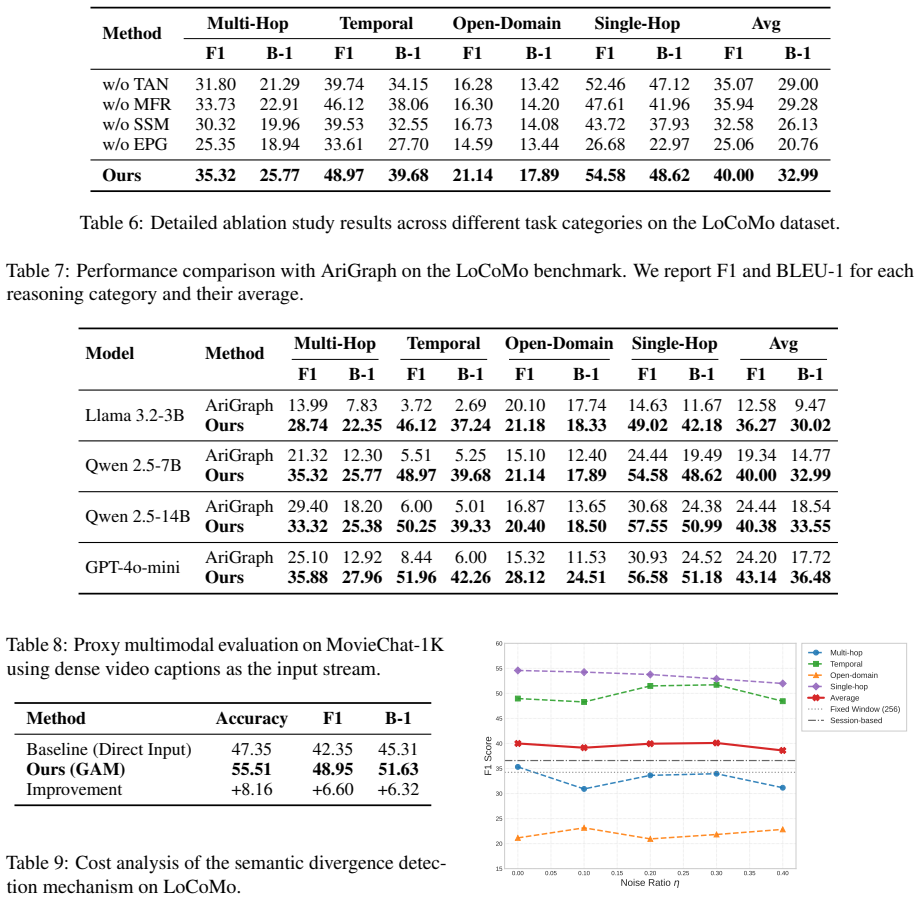
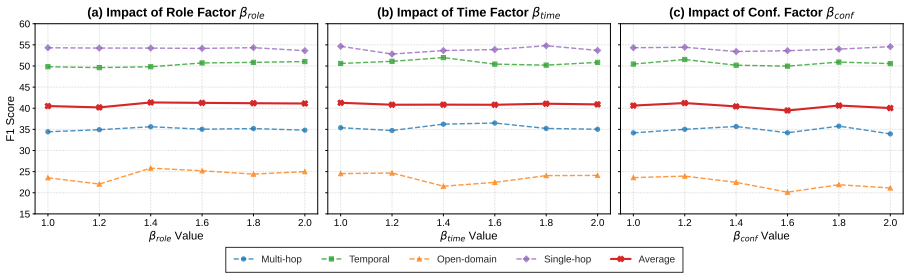
- [Methodology (description of semantic shift detection)] The central claim that semantic-shift-triggered integration minimizes interference rests on the reliability of the shift detector, yet the manuscript supplies no quantitative characterization of this component (thresholds, prompting strategy, precision/recall, or false-positive/negative rates). Without such data, it is impossible to verify that missed shifts do not discard critical context or that spurious triggers do not pollute the topic associative network.
- [Experimental Evaluation] Experiments on LoCoMo and LongDialQA report aggregate gains but contain no ablation isolating the contribution of the shift-detection trigger or the hierarchical decoupling itself. This omission leaves open whether observed improvements stem from the proposed mechanism or from other unablated factors such as retrieval heuristics or base LLM choice.
- [Abstract and Experimental Evaluation] The abstract asserts outperformance without supplying any numerical metrics, baseline names, standard deviations, or statistical significance tests. Even if the full experimental section contains these details, their absence from the abstract and the lack of error analysis for the shift detector undermine the ability to assess whether the data support the decoupling claim.
minor comments (2)
- [Methodology] Clarify the precise interface between the event progression graph and the topic associative network (e.g., what information is copied, how node/edge representations are updated) with a small diagram or pseudocode.
- [Retrieval Strategy] Ensure all acronyms (LoCoMo, LongDialQA) are expanded on first use and that the retrieval strategy's multi-factor scoring is defined with explicit formulas.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Methodology (description of semantic shift detection)] The central claim that semantic-shift-triggered integration minimizes interference rests on the reliability of the shift detector, yet the manuscript supplies no quantitative characterization of this component (thresholds, prompting strategy, precision/recall, or false-positive/negative rates). Without such data, it is impossible to verify that missed shifts do not discard critical context or that spurious triggers do not pollute the topic associative network.
Authors: We agree that a quantitative characterization of the semantic shift detector is necessary to fully substantiate the central claim regarding interference minimization. In the revised manuscript, we have added a new subsection in the methodology that specifies the prompting strategy, exact threshold values, and an empirical evaluation of precision, recall, false-positive, and false-negative rates on a held-out set of dialogues. This analysis confirms that the detector maintains high reliability, with low rates of missed shifts or spurious triggers that could affect context or the topic network. revision: yes
-
Referee: [Experimental Evaluation] Experiments on LoCoMo and LongDialQA report aggregate gains but contain no ablation isolating the contribution of the shift-detection trigger or the hierarchical decoupling itself. This omission leaves open whether observed improvements stem from the proposed mechanism or from other unablated factors such as retrieval heuristics or base LLM choice.
Authors: We recognize that isolating the contributions of the shift-detection trigger and hierarchical decoupling through targeted ablations would strengthen the experimental claims. We have therefore added ablation studies in the revised experimental section. These include a variant that replaces semantic-shift triggering with fixed-interval integration and a non-hierarchical (flat) memory baseline. The results demonstrate that the proposed decoupling mechanism accounts for a substantial share of the gains in accuracy and efficiency, beyond retrieval heuristics or the choice of base LLM. revision: yes
-
Referee: [Abstract and Experimental Evaluation] The abstract asserts outperformance without supplying any numerical metrics, baseline names, standard deviations, or statistical significance tests. Even if the full experimental section contains these details, their absence from the abstract and the lack of error analysis for the shift detector undermine the ability to assess whether the data support the decoupling claim.
Authors: We have revised the abstract to include key numerical results, including specific accuracy improvements on LoCoMo and LongDialQA, the primary baseline names, and references to standard deviations and statistical significance tests detailed in the experimental section. We have also incorporated a concise error analysis of the shift detector (now quantified in the methodology) and referenced it in the abstract to better support the decoupling claim. revision: yes
Circularity Check
No circularity; novel architectural proposal with independent design rationale
full rationale
The paper presents GAM as an original hierarchical graph framework that decouples ongoing dialogue encoding (event progression graph) from consolidation (topic associative network) triggered by semantic shifts, plus a graph-guided retrieval strategy. No equations, fitted parameters, or derivations appear that reduce any claimed outcome to the inputs by construction. Claims rest on addressing stated tensions in prior memory systems and are evaluated on external benchmarks (LoCoMo, LongDialQA) rather than self-referential fits or uniqueness theorems imported from the authors' prior work. This is a standard new-method proposal whose central mechanism is a design choice, not a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic shifts can be reliably detected to trigger memory consolidation from event graph to topic network without loss of critical information.
invented entities (2)
-
event progression graph
no independent evidence
-
topic associative network
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Four-Axis Decision Alignment for Long-Horizon Enterprise AI Agents
Long-horizon enterprise AI agents' decisions decompose into four measurable axes, with benchmark experiments on six memory architectures revealing distinct weaknesses and reversing a pre-registered prediction on summa...
-
HAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution
HAGE proposes a trainable weighted graph memory framework with LLM intent classification, dynamic edge modulation, and RL optimization that improves long-horizon reasoning accuracy in agentic LLMs over static baselines.
-
Stateless Decision Memory for Enterprise AI Agents
Deterministic Projection Memory (DPM) delivers stateless, deterministic decision memory for enterprise AI agents that matches or exceeds summarization-based approaches at tight memory budgets while improving speed, de...
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
-
[4]
Abrar Anwar, John Welsh, Joydeep Biswas, Soha Pouya, and Yan Chang. 2025. Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 2838--2845. IEEE
2025
-
[5]
Hongyu Chang, Wenbo Tang, Annabella M Wulf, Thokozile Nyasulu, Madison E Wolf, Antonio Fernandez-Ruiz, and Azahara Oliva. 2025. Sleep microstructure organizes memory replay. Nature, 637(8048):1161--1169
2025
- [6]
-
[7]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413
work page internal anchor Pith review arXiv 2025
-
[8]
Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael C Mozer, and Sanjeev Arora. 2024. Metacognitive capabilities of llms: An exploration in mathematical problem solving. Advances in Neural Information Processing Systems, 37:19783--19812
2024
- [9]
-
[10]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130
work page internal anchor Pith review arXiv 2024
-
[11]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. Lightrag: Simple and fast retrieval-augmented generation. arXiv preprint arXiv:2410.05779
work page internal anchor Pith review arXiv 2024
-
[12]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, and 28 others. 2026. https://arxiv.org/abs/2512.13564 Memory in the age of ai agents . Preprint, arXiv:2512.13564
work page internal anchor Pith review arXiv 2026
-
[13]
Wei-Chieh Huang, Weizhi Zhang, Yueqing Liang, Yuanchen Bei, Yankai Chen, Tao Feng, Xinyu Pan, Zhen Tan, Yu Wang, Tianxin Wei, Shanglin Wu, Ruiyao Xu, Liangwei Yang, Rui Yang, Wooseong Yang, Chin-Yuan Yeh, Hanrong Zhang, Haozhen Zhang, Siqi Zhu, and 41 others. 2026. https://arxiv.org/abs/2602.06052 Rethinking memory mechanisms of foundation agents in the s...
-
[14]
Runsong Jia, Bowen Zhang, Sergio Jos\' e Rodr\' guez M\' e ndez, and Pouya G. Omran. 2025 a . https://doi.org/10.1145/3701716.3717819 Structrag: Structure-aware rag framework with scholarly knowledge graph for diverse question answering . In Companion Proceedings of the ACM on Web Conference 2025, page 2567–2573. Association for Computing Machinery
-
[15]
Zixi Jia, Qinghua Liu, Hexiao Li, Yuyan Chen, and Jiqiang Liu. 2025 b . Evaluating the long-term memory of large language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19759--19777
2025
- [16]
- [17]
- [18]
- [19]
- [20]
-
[21]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851--13870
2024
-
[22]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. https://arxiv.org/abs/2310.08560 Memgpt: Towards llms as operating systems . Preprint, arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22
2023
-
[24]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956
work page internal anchor Pith review arXiv 2025
- [25]
-
[26]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, and Tomas Pfister. 2025. https://aclanthology.org/2025.acl-long.413/ In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents . In Proceedings...
2025
-
[27]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. A-mem: Agentic memory for llm agents. arXiv preprint arXiv:2502.12110
work page internal anchor Pith review arXiv 2025
-
[28]
Enneng Yang, Anke Tang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, and Jie Zhang. 2025 a . Continual model merging without data: Dual projections for balancing stability and plasticity. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
- [29]
- [30]
-
[31]
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, Xue Liu, Xiaoxiao Li, and Philip S. Yu. 2026 a . https://arxiv.org/abs/2604.01687 Evoskills: Self-evolving agent skills via co-evolutionary verification . Preprint, arXiv:2604.01687
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, and 4 others. 2025 b . https://arxiv.org/abs/2506.18959 From web search towards agentic deep re...
-
[33]
Wenyuan Zhang, Xinghua Zhang, Haiyang Yu, Shuaiyi Nie, Bingli Wu, Juwei Yue, Tingwen Liu, and Yongbin Li. 2026 b . https://arxiv.org/abs/2601.08605 Expseek: Self-triggered experience seeking for web agents . Preprint, arXiv:2601.08605
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724--19731
2024
-
[35]
Henry Peng Zou, Wei-Chieh Huang, Yaozu Wu, Yankai Chen, Chunyu Miao, Hoang Nguyen, Yue Zhou, Weizhi Zhang, Liancheng Fang, Langzhou He, Yangning Li, Dongyuan Li, Renhe Jiang, Xue Liu, and Philip S. Yu. 2025. https://arxiv.org/abs/2505.00753 Llm-based human-agent collaboration and interaction systems: A survey . Preprint, arXiv:2505.00753
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Henry Peng Zou, Chunyu Miao, Wei-Chieh Huang, Yankai Chen, Yue Zhou, Hanrong Zhang, Yaozu Wu, Liancheng Fang, Zhengyao Gu, Zhen Zhang, Kening Zheng, Fangxin Wang, Yi Nian, Shanghao Li, Wenzhe Fan, Langzhou He, Weizhi Zhang, Xue Liu, and Philip S. Yu. 2026. https://arxiv.org/abs/2604.00892 When users change their mind: Evaluating interruptible agents in lo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.