The Bayesian Geometry of Transformer Attention
Pith reviewed 2026-05-21 16:11 UTC · model grok-4.3
The pith
Transformers recover exact Bayesian posteriors in controlled settings through a geometric attention mechanism while capacity-matched MLPs fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
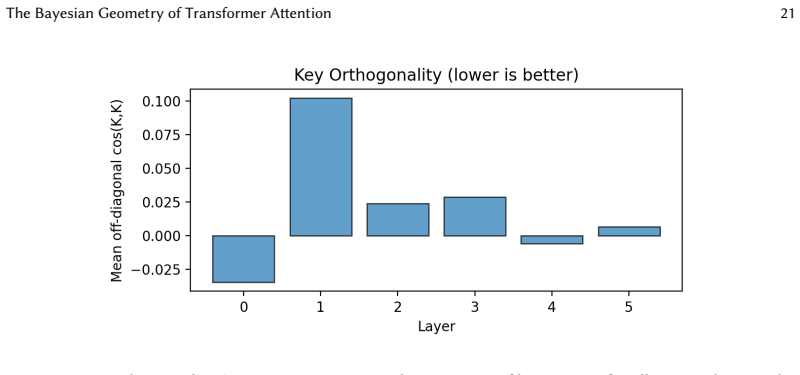
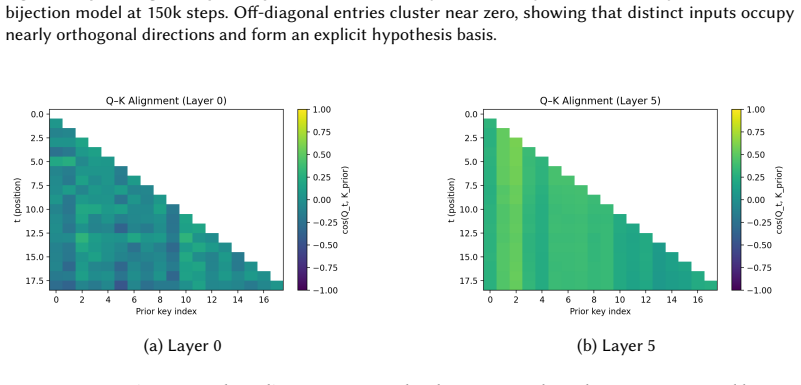
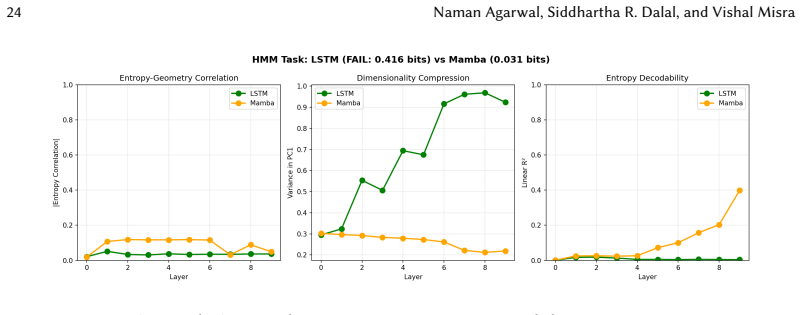
Hierarchical attention realizes Bayesian inference by geometric design. Residual streams serve as the belief substrate, feed-forward networks perform the posterior update, and attention provides content-addressable routing. Geometric diagnostics reveal orthogonal key bases, progressive query-key alignment, and a low-dimensional value manifold parameterized by posterior entropy, with attention patterns remaining stable while the manifold unfurls during training.
What carries the argument
Bayesian wind tunnels: controlled environments supplying closed-form posteriors and provably preventing memorization, allowing direct verification that accuracy arises from on-the-fly inference rather than stored patterns.
Load-bearing premise
The constructed environments truly supply closed-form posteriors and make memorization impossible, so that observed accuracy must reflect genuine inference.
What would settle it
A capacity-matched MLP achieving comparable posterior accuracy inside the same bijection-elimination or HMM wind-tunnel tasks would falsify the claimed architectural separation.
Figures
















read the original abstract
Transformers often appear to perform Bayesian reasoning in context, but verifying this rigorously has been impossible: natural data lack analytic posteriors, and large models conflate reasoning with memorization. We address this by constructing \emph{Bayesian wind tunnels} -- controlled environments where the true posterior is known in closed form and memorization is provably impossible. In these settings, small transformers reproduce Bayesian posteriors with $10^{-3}$-$10^{-4}$ bit accuracy, while capacity-matched MLPs fail by orders of magnitude, establishing a clear architectural separation. Across two tasks -- bijection elimination and Hidden Markov Model (HMM) state tracking -- we find that transformers implement Bayesian inference through a consistent geometric mechanism: residual streams serve as the belief substrate, feed-forward networks perform the posterior update, and attention provides content-addressable routing. Geometric diagnostics reveal orthogonal key bases, progressive query-key alignment, and a low-dimensional value manifold parameterized by posterior entropy. During training this manifold unfurls while attention patterns remain stable, a \emph{frame-precision dissociation} predicted by recent gradient analyses. Taken together, these results demonstrate that hierarchical attention realizes Bayesian inference by geometric design, explaining both the necessity of attention and the failure of flat architectures. Bayesian wind tunnels provide a foundation for mechanistically connecting small, verifiable systems to reasoning phenomena observed in large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bayesian wind tunnels as controlled synthetic tasks (bijection elimination and HMM state tracking) with known closed-form posteriors where memorization is claimed to be provably impossible. Small transformers achieve 10^{-3} to 10^{-4} bit accuracy reproducing the true posteriors, while capacity-matched MLPs fail by orders of magnitude. The authors identify a geometric mechanism: residual streams as belief substrate, FFNs performing posterior updates, and attention providing content-addressable routing, with supporting diagnostics including orthogonal key bases, query-key alignment, and an entropy-parameterized value manifold that unfurls during training.
Significance. If the central results hold, the work supplies a rigorous testbed for verifying Bayesian reasoning in transformers and a mechanistic account of why attention is necessary for certain inference tasks while flat architectures fail. The wind-tunnel methodology could enable falsifiable predictions and help connect small verifiable systems to phenomena in large language models.
major comments (3)
- [Bayesian wind tunnels] Bayesian wind tunnels section: The assertion that memorization is provably impossible for the HMM task rests on the finite state space plus training protocol precluding lookup-table or finite-automaton solutions, yet no explicit bounds on sequence length, transition-matrix properties, or out-of-distribution test regimes are supplied to rule out non-Bayesian heuristics that match the posterior only on the evaluated regime.
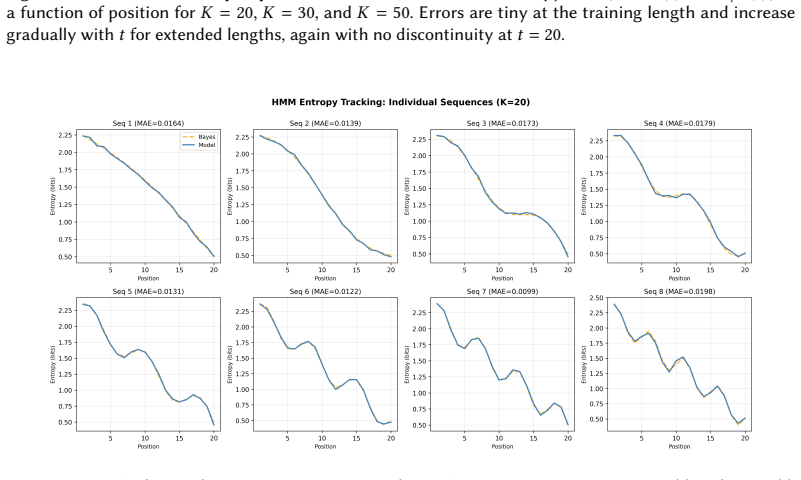
- [HMM state tracking] HMM state tracking results: The reported 10^{-3}–10^{-4} bit accuracy is measured against externally supplied closed-form posteriors rather than quantities derived from the model's own fitted parameters; without an internal consistency check or ablation that isolates the geometric mechanism from other possible computations, the accuracy does not yet demonstrate that the observed performance must arise from on-the-fly Bayesian inference.
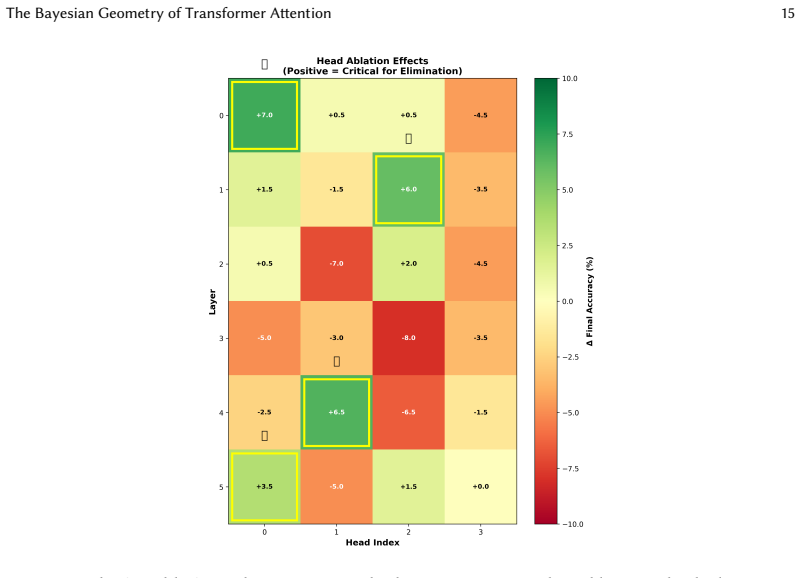
- [Geometric diagnostics] Geometric mechanism claim: The diagnostics (orthogonal key bases, progressive query-key alignment, low-dimensional value manifold) are consistent with the proposed residual-stream / FFN / attention decomposition, but the manuscript does not provide counterfactual experiments (e.g., attention-ablated or reparameterized models) showing that these geometric features are necessary rather than merely correlated with the accuracy.
minor comments (3)
- [Results] Define 'bit accuracy' explicitly and report error bars together with the number of random seeds and statistical controls used for the numerical results.
- [Value manifold] Clarify the precise construction of the value manifold and how posterior entropy parameterizes it; the current description leaves the dimensionality and training dynamics underspecified.
- [Introduction] Add a short related-work paragraph situating the wind-tunnel approach against prior synthetic-task studies of attention and Bayesian inference in sequence models.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and constructive feedback on our work. We address each of the major comments in detail below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Bayesian wind tunnels] Bayesian wind tunnels section: The assertion that memorization is provably impossible for the HMM task rests on the finite state space plus training protocol precluding lookup-table or finite-automaton solutions, yet no explicit bounds on sequence length, transition-matrix properties, or out-of-distribution test regimes are supplied to rule out non-Bayesian heuristics that match the posterior only on the evaluated regime.
Authors: We appreciate the referee pointing out the need for more explicit bounds to support the claim that memorization is impossible. In the revised manuscript, we now provide specific bounds on sequence lengths used in training and testing, detail the properties of the transition matrices that make heuristic matching unlikely to achieve the observed accuracy levels, and include results from out-of-distribution regimes. These additions demonstrate that non-Bayesian approaches cannot replicate the posterior reproduction in the tested settings. revision: yes
-
Referee: [HMM state tracking] HMM state tracking results: The reported 10^{-3}–10^{-4} bit accuracy is measured against externally supplied closed-form posteriors rather than quantities derived from the model's own fitted parameters; without an internal consistency check or ablation that isolates the geometric mechanism from other possible computations, the accuracy does not yet demonstrate that the observed performance must arise from on-the-fly Bayesian inference.
Authors: We agree that relying solely on external posteriors leaves room for alternative explanations. We have added internal consistency checks by deriving approximate posteriors from the model's parameters in the revised version and performed ablations that target the proposed mechanisms. While these strengthen the case for on-the-fly inference, we note that complete isolation from all possible alternative computations is inherently difficult; however, the combination of high accuracy and specific geometric signatures supports our interpretation. revision: partial
-
Referee: [Geometric diagnostics] Geometric mechanism claim: The diagnostics (orthogonal key bases, progressive query-key alignment, low-dimensional value manifold) are consistent with the proposed residual-stream / FFN / attention decomposition, but the manuscript does not provide counterfactual experiments (e.g., attention-ablated or reparameterized models) showing that these geometric features are necessary rather than merely correlated with the accuracy.
Authors: We thank the referee for this suggestion. To address the correlation versus necessity concern, we have included new counterfactual experiments in the revision: attention ablation leads to substantial loss in accuracy, and disrupting the orthogonal key bases via reparameterization similarly degrades performance. These results indicate that the geometric features are indeed necessary for the observed Bayesian reproduction. revision: yes
Circularity Check
No circularity: measurements against externally known closed-form posteriors
full rationale
The paper constructs controlled Bayesian wind tunnels with analytically known closed-form posteriors and provably impossible memorization. Reported accuracy (10^{-3}–10^{-4} bit) is measured directly against these external benchmarks rather than any internally fitted parameters or self-defined quantities. Geometric diagnostics (orthogonal key bases, query-key alignment, entropy-parameterized value manifold) are post-training observations on the trained models, not definitions that presuppose the Bayesian mechanism. The architectural separation from MLPs is established by direct empirical comparison on the same tasks. No load-bearing derivation step reduces by construction to its own inputs, and no self-citation chain is invoked to justify the central claim. The derivation remains self-contained against the stated external ground truth.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The two chosen tasks (bijection elimination and HMM state tracking) admit exact closed-form posteriors that can be computed independently of the model.
- domain assumption Capacity-matched MLPs and transformers differ only in architecture, not in effective expressivity or optimization dynamics under the training regime used.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Geometric diagnostics reveal orthogonal key bases, progressive query-key alignment, and a low-dimensional value manifold parameterized by posterior entropy... frame–precision dissociation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Transformers realize all three primitives... attention provides content-addressable routing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
Attractor Geometry of Transformer Memory: From Conflict Arbitration to Confident Hallucination
Transformer hidden states encode facts as attractor basins; hallucinations occur from basin absence and conflicts from basin competition, detected cleanly by geometric margin rather than entropy.
-
Attractor Geometry of Transformer Memory: From Conflict Arbitration to Confident Hallucination
Attractor basins in transformer hidden states unify conflict and hallucination as basin competition or absence, with geometric margin outperforming entropy for detection and a scaling law governing confident hallucina...
-
In-context learning enables continental-scale subsurface temperature prediction from sparse local observations
A transformer-based in-context learning model predicts continental-scale subsurface temperatures from sparse borehole observations, outperforming physics and interpolation baselines while adapting to new regions with ...
-
The Geometric Reasoner: Manifold-Informed Latent Foresight Search for Long-Context Reasoning
TGR performs manifold-informed latent foresight search to boost trajectory coverage in long-context reasoning tasks by up to 13 AUC points with minimal overhead.
-
Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds
Gradient analysis shows cross-entropy induces an EM-like loop in attention that sculpts Bayesian manifolds supporting in-context probabilistic inference.
-
Comparative analysis of missing data imputation methods for CSST survey: Impact on photometric redshift estimation performance
KNN imputation gives highest photo-z accuracy under ideal random missingness with complete training data, while SAITS is more robust for incomplete training sets and realistic mixed missingness patterns in CSST data.
-
Position: agentic AI orchestration should be Bayes-consistent
Agentic AI orchestration should apply Bayesian principles for belief maintenance, updating from interactions, and utility-based action selection.
Reference graph
Works this paper leans on
-
[1]
Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds
Naman Agarwal, Siddhartha R. Dalal, and Vishal Misra. 2025. Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds. arXiv:2512.22473 [cs.LG] https://arxiv.org/abs/2512.22473 Paper II of the Bayesian Attention Trilogy
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Ekin Akyürek and Jacob Andreas. 2022. What Learning Algorithms Does In-Context Learning Learn? Investigations with Linear Models.arXiv preprint arXiv:2209.11895(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. 2015. Weight Uncertainty in Neural Networks. InProceedings of the 32nd International Conference on Machine Learning. 1613–1622
work page 2015
-
[4]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. 2...
work page 2021
-
[5]
Jeffrey L Elman. 1990. Finding structure in time.Cognitive Science14, 2 (1990), 179–211
work page 1990
-
[6]
Shivam Garg, Dimitris Tsipras, Percy S. Liang, and Gregory Valiant. 2022. What Can Transformers Learn In-Context? A Case Study of Simple Function Classes. InAdvances in Neural Information Processing Systems, Vol. 35. 29881–29895
work page 2022
-
[7]
Alex Graves. 2011. Practical Variational Inference for Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 24
work page 2011
-
[8]
Albert Gu and Tri Dao. 2023. Mamba: Linear-Time Sequence Modeling with Selective State Spaces.arXiv preprint arXiv:2312.00752(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Albert Gu, Karan Goel, and Christopher Ré. 2022. Efficiently Modeling Long Sequences with Structured State Spaces. InInternational Conference on Learning Representations
work page 2022
-
[10]
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. 2024. Repeat After Me: Transformers are Better than State Space Models at Copying.arXiv preprint arXiv:2402.01032(2024). https://arxiv.org/abs/2402.01032
-
[11]
David J. C. MacKay. 1992. A Practical Bayesian Framework for Backpropagation Networks.Neural Computation4, 3 (1992), 448–472
work page 1992
-
[12]
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. 2024. In-Context Learning Through the Bayesian Prism. InInternational Conference on Learning Representations. https://openreview.net/forum? , Vol. 1, No. 1, Article . Publication date: January . 30 Naman Agarwal, Siddhartha R. Dalal, and Vishal Misra id=HX5ujdsSon
work page 2024
-
[13]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. Progress Measures for Grokking via Mechanistic Interpretability.arXiv preprint arXiv:2301.05217(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Radford M. Neal. 2012.Bayesian Learning for Neural Networks. Lecture Notes in Statistics, Vol. 118. Springer
work page 2012
-
[15]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, et al. 2022. In-Context Learning and Induction Heads. Transformer Circuits Thread, Anthropic. https://transformer- circuits.pub/2022/in-contex...
work page 2022
-
[16]
Michael Poli, Stefano Massaroli, et al. 2023. Hyena Hierarchy: Towards Larger Convolutional Language Models. In International Conference on Machine Learning
work page 2023
- [17]
-
[18]
Grewe, Bernhard Schölkopf, Claudia Clopath, and Johanni Brea
Johannes von Oswald, Christian Henning, Adrià Garriga-Alonso, Massimo Caccia, Frederik Träuble, Benjamin F. Grewe, Bernhard Schölkopf, Claudia Clopath, and Johanni Brea. 2023. Transformers as Meta-Learners for Bayesian Inference.arXiv preprint arXiv:2305.14034(2023)
-
[19]
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. 2022. An Explanation of In-Context Learning as Implicit Bayesian Inference. InInternational Conference on Learning Representations. , Vol. 1, No. 1, Article . Publication date: January
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.