When Video Misreads: Closed-Loop Distillation of Reading Heuristics for Exploratory Manipulation Trace QA
Pith reviewed 2026-06-27 18:24 UTC · model grok-4.3
The pith
Distilling one-line natural-language heuristics from training traces lets frozen VLMs recover minimal-success action chains from exploratory robot traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
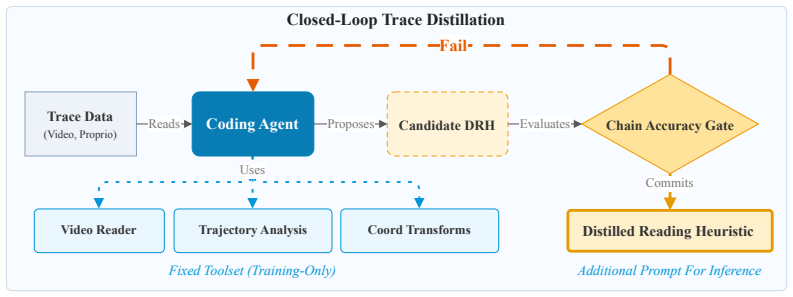
We formalize Exploratory Manipulation Trace QA (EMT-QA) as the problem of predicting the minimal-success action chain from synchronized video and proprioception given the latent precondition revealed by the exploratory probe. Even state-of-the-art VLMs and embodied multimodal LLMs misread this evidence from raw modalities. Closed-Loop Trace Distillation uses a per-task coding agent to inspect labeled training traces and distill a one-line natural-language prompt called the Distilled Reading Heuristic (DRH). At inference a frozen VLM receives the raw trace plus the DRH and achieves +0.38 to +0.47 chain accuracy over the best raw-modality baseline. The same DRH serves as the sole specification
What carries the argument
Distilled Reading Heuristic (DRH): a one-line natural-language prompt over the trace, produced by a coding agent from labeled training examples, that guides a frozen VLM or defines a programmatic classifier to recover the minimal-success action chain.
If this is right
- Raw video and proprioception alone are insufficient for reliable chain recovery in EMT-QA; an explicit reading heuristic is required.
- The DRH can be used at inference with no coding agent and no model updates.
- The identical DRH text can replace the VLM with a lightweight programmatic classifier that matches its accuracy.
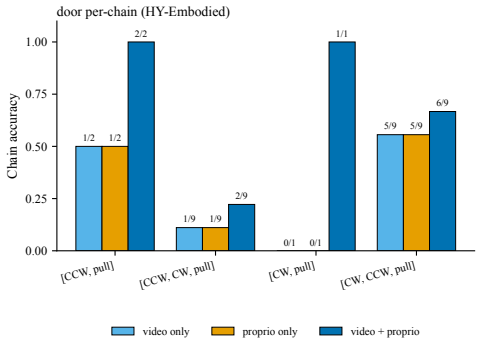
- The improvement holds across three simulator tasks and two real-robot tasks.
Where Pith is reading between the lines
- Many VLM failures on embodied trace data may stem from missing explicit reading instructions rather than from limits in visual or reasoning capacity.
- The distillation procedure could be applied to other trace-interpretation problems such as failure analysis in navigation or assembly logs.
- If the DRH generalizes across VLMs, it could be used to create consistent behavior even when swapping the underlying vision-language model.
Load-bearing premise
A per-task coding agent inspecting labeled training traces can reliably distill a one-line natural-language heuristic that generalizes to new traces of the same task without further adaptation or model changes.
What would settle it
Run the distillation on training traces for one of the reported tasks, then measure chain accuracy on held-out test traces both with and without the resulting DRH; if accuracy does not rise by at least 0.3 or if the DRH-derived programmatic classifier underperforms the prompted VLM, the central claim is falsified.
Figures


read the original abstract
Exploratory manipulation often turns an apparent failed attempt into the key evidence for what to do next. For example, a robot pulls a locked cabinet drawer, fails, and only succeeds after opening the lock. The failed pull reveals a latent precondition (the drawer is locked) that determines the minimal-success action chain (the fewest actions that complete the task), here [lock-open, drawer-pull]. Correctly reading this trace is therefore the prerequisite for recovering that chain. We formalize this setting as Exploratory Manipulation Trace QA (EMT-QA): given synchronized video and proprioception from an exploratory trace, predict the minimal-success action chain under the latent precondition revealed by the probe. However, even state-of-the-art VLMs and embodied multimodal LLMs misread this evidence: they do not reliably recover the chain from raw video, raw proprioception, or their combination. We introduce Closed-Loop Trace Distillation, a pipeline that uses a per-task coding agent to inspect labeled training traces and distill a one-line natural-language prompt over the trace, which we call the Distilled Reading Heuristic (DRH). At inference, no agent is invoked and no model weights are updated; a frozen VLM receives the raw trace plus the DRH as a prompt entry. Across three simulator and two real-robot tasks, the DRH improves chain accuracy by +0.38 to +0.47 over the best raw-modality baseline. The same DRH also serves as the sole specification for one-shot programmatic classifiers that match the prompted VLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes Exploratory Manipulation Trace QA (EMT-QA), where a robot's exploratory trace (video + proprioception) reveals a latent precondition that determines the minimal-success action chain. It claims that VLMs and multimodal LLMs fail on raw modalities, but Closed-Loop Trace Distillation uses a per-task coding agent to inspect labeled training traces and produce a one-line Distilled Reading Heuristic (DRH). At inference the frozen VLM receives the raw trace plus the DRH, yielding claimed chain-accuracy gains of +0.38 to +0.47 over the best raw-modality baseline across three simulator and two real-robot tasks; the same DRH is asserted to serve as the sole specification for one-shot programmatic classifiers that match the prompted VLM.
Significance. If the distillation step is shown to produce heuristics that genuinely generalize beyond the labeled training traces, the method supplies a lightweight, training-free way to improve VLM reasoning on embodied traces while also yielding directly executable programmatic classifiers. The dual-use property of the DRH is a concrete strength that increases interpretability and reduces reliance on the VLM at deployment time.
major comments (2)
- [Abstract] Abstract: the headline quantitative claim (+0.38 to +0.47 chain accuracy) is presented without error bars, statistical tests, data-split descriptions, number of training traces per task, or exclusion criteria, rendering the central empirical result impossible to evaluate for reliability.
- [Abstract] Abstract (distillation pipeline): the claim that a per-task coding agent can distill a single natural-language sentence that generalizes to unseen traces of the same task is load-bearing for both the accuracy gains and the programmatic-classifier equivalence, yet no count of training traces, agent prompt/model, or ablation against ground-truth re-statement is supplied.
minor comments (1)
- [Abstract] The expansion of the EMT-QA acronym appears only after its first use; an earlier parenthetical definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional details are needed for transparency and will revise the abstract accordingly while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline quantitative claim (+0.38 to +0.47 chain accuracy) is presented without error bars, statistical tests, data-split descriptions, number of training traces per task, or exclusion criteria, rendering the central empirical result impossible to evaluate for reliability.
Authors: We acknowledge the abstract omits these elements. In revision we will add error bars and statistical test descriptions to the reported gains, summarize the data splits and per-task training trace counts, and state exclusion criteria. These details already appear in the experimental sections; the abstract will be updated to include concise versions so the headline numbers can be evaluated directly. revision: yes
-
Referee: [Abstract] Abstract (distillation pipeline): the claim that a per-task coding agent can distill a single natural-language sentence that generalizes to unseen traces of the same task is load-bearing for both the accuracy gains and the programmatic-classifier equivalence, yet no count of training traces, agent prompt/model, or ablation against ground-truth re-statement is supplied.
Authors: We agree the abstract should supply these specifics. Revision will state the number of training traces per task, name the coding agent model and prompt template, and report an ablation of the distilled heuristic versus a ground-truth re-statement. The full pipeline description and ablation already exist in the methods; we will condense them into the abstract for completeness. revision: yes
Circularity Check
No significant circularity; method uses held-out evaluation
full rationale
The paper describes an empirical pipeline that distills a one-line DRH from labeled training traces via a coding agent, then applies the frozen DRH to a VLM on held-out traces. No equations, derivations, or self-referential definitions appear. Results are reported as accuracy gains on separate test data, with no reduction of outputs to inputs by construction. This matches standard train/test separation and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can reliably follow short natural-language heuristics added to prompts for interpreting manipulation traces
Reference graph
Works this paper leans on
-
[1]
Y . Wang, X. Zhang, R. Wu, Y . Li, Y . Shen, M. Wu, Z. He, Y . Wang, and H. Dong. Adamanip: Adaptive articulated object manipulation environments and policy learning. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/ forum?id=Luss2sa0vc. arXiv:2502.11124
-
[2]
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. SAPIEN: A simulated Part-Based interactive environment. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020. URLhttps://openaccess.thecvf.com/content_CVPR_2020/html/ Xiang_SAPIEN_A_SimulAted_P...
-
[3]
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Tulsiani. Where2Act: From pixels to actions for articulated 3D objects. InIEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021. URLhttps://doi.org/10.1109/ICCV48922.2021.00674. arXiv:2101.02692
-
[4]
H. Geng, H. Xu, C. Zhao, C. Xu, L. Yi, S. Huang, and H. Wang. GAPartNet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,
-
[5]
In: Conference on Computer Vision and Pattern Recognition (CVPR)
URLhttps://doi.org/10.1109/CVPR52729.2023.00684. arXiv:2211.05272
-
[6]
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Man- dlekar, and Y . Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2410.00371. arXiv:2410.00371
- [7]
-
[8]
Motion-o: Trajectory-Grounded Video Reasoning
B. Galoaa, S. Moezzi, X. Bai, and S. Ostadabbas. Motion-o: Trajectory-grounded video rea- soning.arXiv preprint arXiv:2603.18856, 2026. URLhttps://arxiv.org/abs/2603. 18856
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
P. Schroeder, O. Biza, T. Weng, H. Luo, and J. Glass. Rover: Recursive reasoning over videos with vision-language models for embodied tasks.arXiv preprint arXiv:2508.01943, 2025. URLhttps://arxiv.org/abs/2508.01943
- [10]
-
[11]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
-
[12]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
PMLR, 2023. URLhttps://proceedings.mlr.press/v229/zitkovich23a.html. arXiv:2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Fos- ter, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InConfer- ence on Robot Learning (CoRL), volume 270. PMLR, 2024. URLhttps://proceedings. mlr....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Van- houcke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model. InInternational Conference on Machine Learn- ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
https://doi.org/10.48550/arXiv.2311
P. Sermanet, T. Ding, J. Zhao, F. Xia, D. Dwibedi, K. Gopalakrishnan, C. W. Chan, G. Dulac- Arnold, S. Maddineni, N. J. Joshi, P. Florence, W. Han, R. Baruch, Y . Lu, S. Mirchandani, P. Xu, P. Sanketi, K. Hausman, I. Shafran, B. Ichter, and Y . Cao. Robovqa: Multimodal long- horizon reasoning for robotics.arXiv (Cornell University), 2023. doi:10.48550/arx...
-
[17]
E. Zhao, V . Raval, H. Zhang, J. Mao, Z. Shangguan, S. Nikolaidis, Y . Wang, and D. Seita. Manipbench: Benchmarking vision-language models for low-level robot manipulation. In Conference on Robot Learning (CoRL), volume 305. PMLR, 2025. URLhttps://arxiv. org/abs/2505.09698. arXiv:2505.09698
- [18]
- [19]
-
[20]
L. Fu, S. Salimpour, L. Militano, H. Edelman, J. P. Queralta, and G. Toffetti. Rosbag mcp server: Analyzing robot data with llms for agentic embodied ai applications.ArXiv.org, 2025. doi:10.48550/arxiv.2511.03497. URLhttps://doi.org/10.48550/arxiv.2511.03497
-
[21]
J. Liu, X. Zhao, X. Shang, and Z. Shen. Dive into claude code: The design space of today’s and future ai agent systems.arXiv preprint arXiv:2604.14228, 2026. URLhttps://arxiv. org/abs/2604.14228
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Syner- gizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X. arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Lan- guage agents with verbal reinforcement learning. InAdvances in Neural Information Process- ing Systems (NeurIPS), volume 36, 2023. URLhttp://papers.nips.cc/paper_files/ paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference. html. arXiv:2303.11366. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Self-Refine: Iterative Refinement with Self-Feedback
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. URLhttp://papers.nips.cc/paper_...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Nee- lakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. Mc- Candlish, A. Radford, I. Sutskever, and D....
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), vol- ume 35, 2022. URLhttp://papers.nips.cc/paper_files/paper/2022/ hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.h...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InIEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2023. URLhttps://doi.org/10.1109/ ICRA48891.2023.10160591. arXiv:2209.07753
-
[28]
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models. InIEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023. URL https://doi.org/10.1109/ICRA48891.2023.10161317. arXiv:2209.11302
-
[29]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3D value maps for robotic manipulation with language models. InConference on Robot Learn- ing (CoRL), volume 229. PMLR, 2023. URLhttps://proceedings.mlr.press/v229/ huang23b.html. arXiv:2307.05973
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
J. Chen, Y . Mu, Q. Yu, T. Wei, S. Wu, Z. Yuan, Z. Liang, C. Yang, K. Zhang, W. Shao, Y . Qiao, H. Xu, M. Ding, and P. Luo. Roboscript: Code generation for free-form manipulation tasks across real and simulation.arXiv preprint arXiv:2402.14623, 2024. URLhttps://doi.org/ 10.48550/arXiv.2402.14623
-
[31]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bohez, K. Bousmalis, A. Brohan, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, O. Chang, J. E. Chen, X. Chen, H.-T. L. Chi- ang, K. Choromanski, D. D’Ambrosio, S. Dasari, T. Davchev, C. Devin, N. D. Palo, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
T. R. X, X. Yu, Z. Liu, Z. Wang, H. Zhang, Y . Rao, F. Liu, Y . Zhang, R. Zhao, O. Wang, Y . Liang, H. Lin, M. Wang, Y . Dong, K. Cheng, B. Ni, R. Huang, H. Hu, Z. Zhang, Li- nus, and S. Yao. HY-Embodied-0.5: Embodied foundation models for real-world agents. CoRR, abs/2604.07430, 2026. doi:10.48550/ARXIV .2604.07430. URLhttps://doi.org/ 10.48550/arXiv.2604.07430
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[33]
Makoviychuk, L
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State. Isaac gym: High performance GPU based physics simulation for robot learning. In J. Vanschoren and S. Yeung, edi- tors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets...
2021
-
[34]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Pret- tenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Per- rot, and ´E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learn- ing Research, 12:2825–2830, 2011. URLhttps://dl.acm.org/doi/10.5555/1953048...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.