BlueFin: Benchmarking LLM Agents on Financial Spreadsheets
Pith reviewed 2026-06-28 21:33 UTC · model grok-4.3
The pith
A benchmark of 131 financial spreadsheet tasks shows frontier LLMs score below 50 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces BlueFin, a benchmark that tasks LLM agents with realistic finance-domain spreadsheet workbooks and shows through expert-validated rubrics that frontier models achieve less than 50 percent average scores, with pronounced weaknesses in dynamic correctness.
What carries the argument
BlueFin benchmark of 131 tasks with 3,225 granular rubric criteria, paired with an LM judge that achieves parity with expert consensus.
If this is right
- The open-source harness supplies a repeatable way to measure future agents on the same tasks.
- Documented weaknesses in dynamic correctness identify a concrete capability gap for targeted model improvement.
- The dataset of examples across three task categories can serve as a reference for training or fine-tuning spreadsheet agents.
- The characterization of model performance establishes a baseline against which progress in finance-domain agents can be tracked.
Where Pith is reading between the lines
- Persistent low scores would imply that current agent architectures need advances in state tracking before they can handle live financial workbooks reliably.
- The rubric structure could be adapted to create similar benchmarks for other data-heavy professional domains such as operations or accounting.
- High agreement between the LM judge and humans suggests the evaluation method itself could reduce reliance on manual review for future spreadsheet benchmarks.
- If models improve on these tasks, finance teams might integrate them first for routine manipulation steps rather than full synthesis.
Load-bearing premise
The 131 curated tasks and their rubrics accurately reflect the distribution and difficulty of real tasks performed by finance professionals.
What would settle it
A re-run of the strongest models on the full task set that produces average scores above 60 percent while independent finance experts confirm the outputs match real occupational standards would falsify the reported performance gap.
Figures


read the original abstract
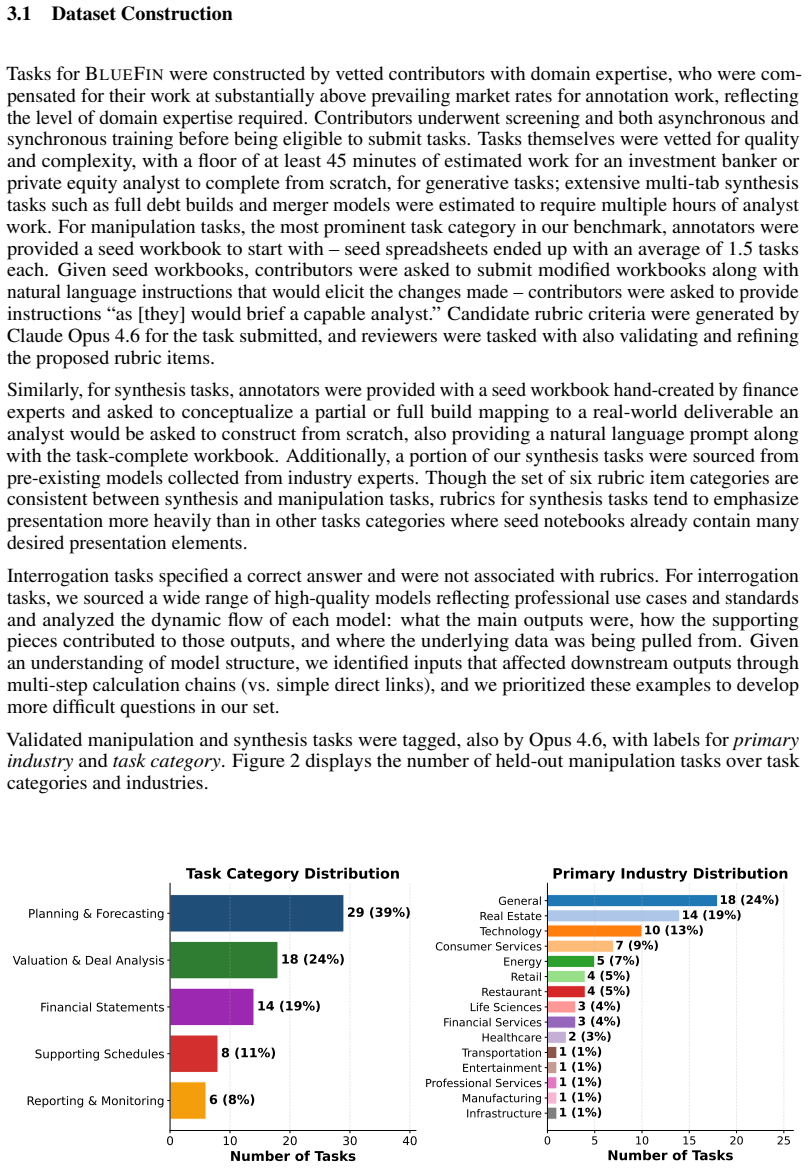
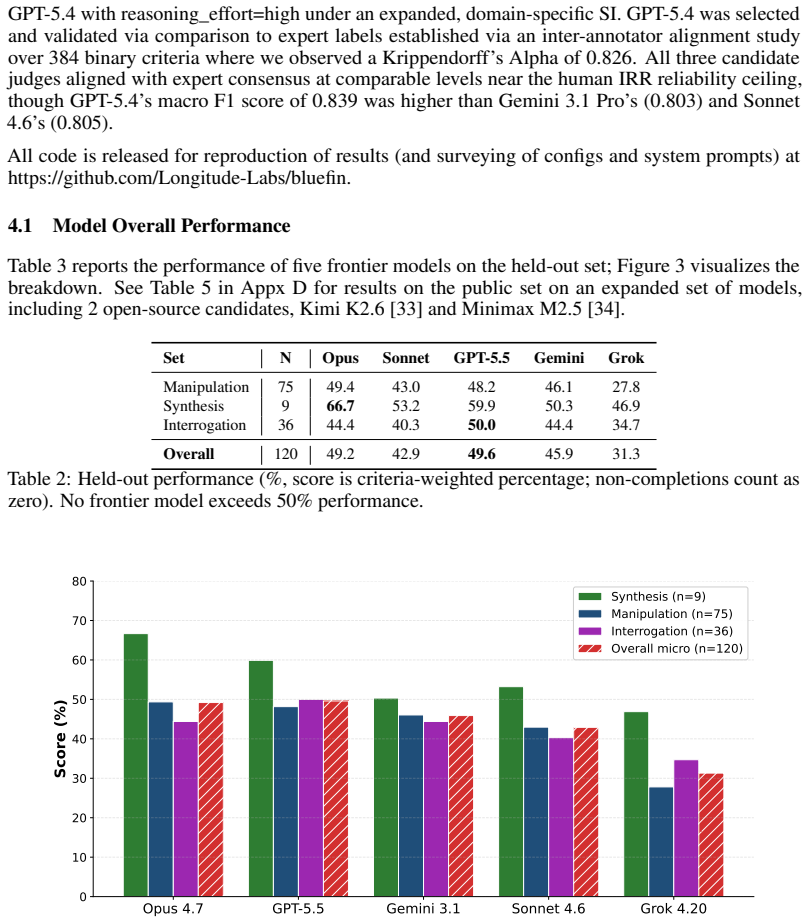
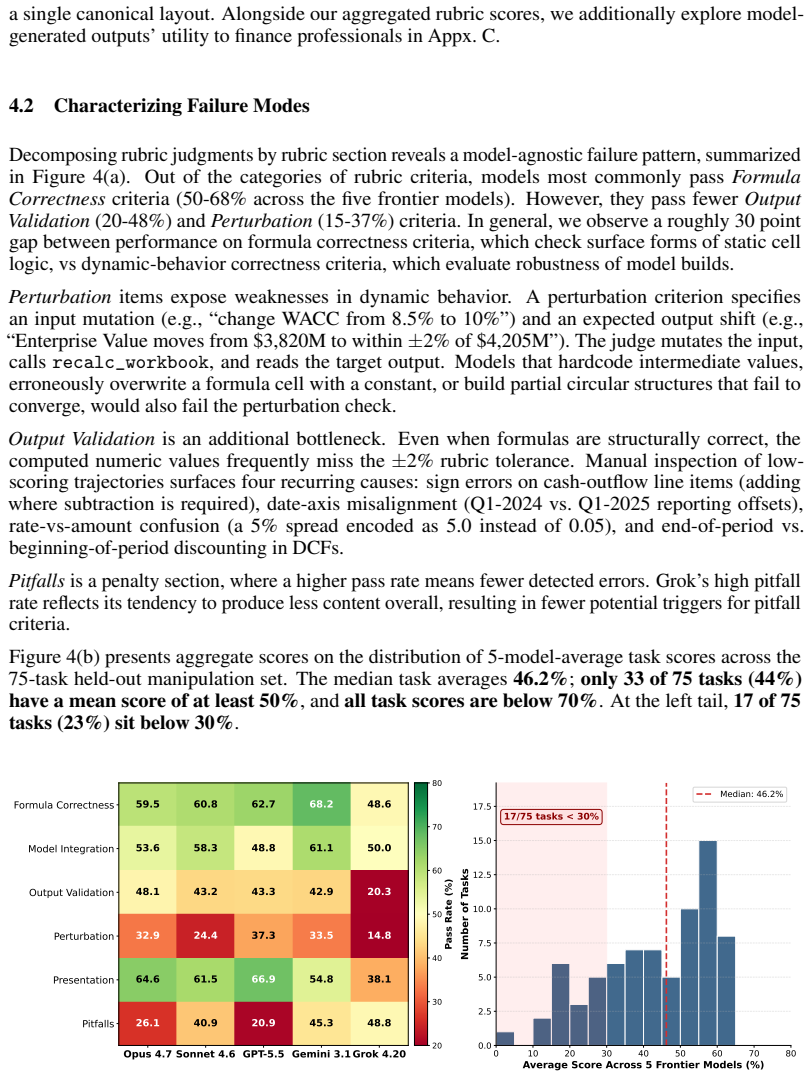
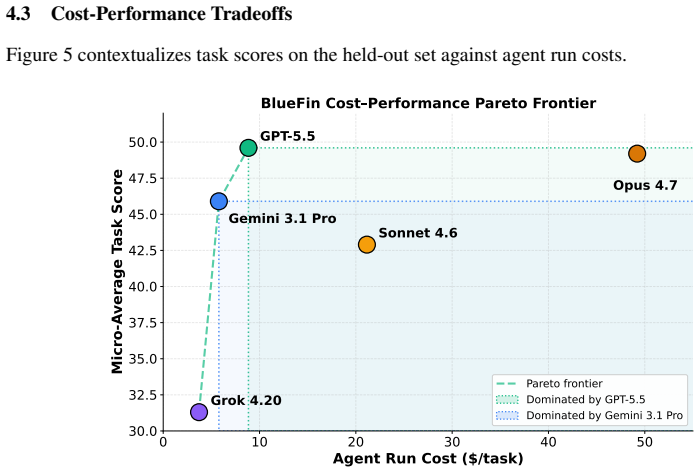
We present BlueFin, a benchmark that tasks large language model (LLM) agents with synthesis, manipulation, and comprehension tasks over spreadsheet workbooks in the professional finance domain. Though estimates of the global population of paying users of spreadsheet software range in the hundreds of millions -- an order of magnitude more than the estimated global population of professional developers -- comparatively fewer resources have been devoted to exploring and expanding LLM capabilities in the spreadsheet domain, with fewer still dedicated to mirroring real occupational tasks encountered by those in professional finance roles. In response, we curate a set of 131 challenging, complex tasks with real-world relevance in the domain, containing 3,225 granular rubric criteria; notably, our rubric criteria and LM judge evaluations are validated by a team of expert human annotators, resulting in high-quality, granular evaluations of complex tasks that are difficult to verify programmatically but can be reliably evaluated by an LM judge agent. Our judge achieves parity with expert consensus ($\alpha=0.826$) with a macro-F1 score of 0.839. Frontier LLMs demonstrate poor performance on the challenging benchmark, with the strongest LLMs achieving less than 50\% average scores across tasks -- models exhibit particular weaknesses in dynamic correctness. Our contributions include a dataset of examples across three categories of spreadsheet tasks, an open source harness and agentic evaluation framework, and a characterization of existing frontier models' performance on our benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BlueFin, a benchmark of 131 curated tasks (with 3,225 rubric criteria) for LLM agents performing synthesis, manipulation, and comprehension over financial spreadsheets. Tasks are claimed to have real-world relevance to professional finance roles; expert annotators validate the rubrics and LM judge (Krippendorff’s α=0.826, macro-F1=0.839). Frontier models are reported to score below 50% on average, with particular weaknesses on dynamic correctness. Contributions include the dataset, an open-source evaluation harness, and the performance characterization.
Significance. If the task set faithfully samples occupational finance spreadsheet work, the <50% result would document a substantial capability gap for a domain with hundreds of millions of users. The open-source harness and granular rubric approach are positive contributions that could support future agent development. The representativeness claim, however, is not quantitatively supported, limiting the strength of the headline performance conclusion.
major comments (2)
- [Abstract / benchmark construction] Abstract and benchmark-construction section: the central claim that frontier LLMs achieve <50% average scores (and are weak on dynamic correctness) is presented as evidence of a general capability gap, yet no quantitative evidence (e.g., job-shadowing data, frequency analysis of finance spreadsheets, or comparison to occupational task inventories) is supplied to show that the 131 tasks match the distribution and difficulty of real professional work. This selection process is load-bearing for the interpretation of the results.
- [Evaluation protocol] Evaluation methodology: dynamic correctness is highlighted as a particular weakness, but the manuscript does not detail how this criterion is operationalized across the 3,225 rubric items or how it differs from static correctness in the LM-judge protocol, making it difficult to assess whether the reported gap is robust or rubric-dependent.
minor comments (2)
- [Validation] The inter-annotator agreement figures (α=0.826, macro-F1=0.839) are reported without the full annotation protocol or breakdown by task category; adding these details would strengthen the validation claim.
- [Results] Table or figure presenting per-model scores should include confidence intervals or per-task variance to allow readers to judge the stability of the <50% aggregate.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below. While we can expand on the evaluation protocol, we cannot supply new quantitative data on task representativeness without additional empirical studies outside the current scope.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark-construction section: the central claim that frontier LLMs achieve <50% average scores (and are weak on dynamic correctness) is presented as evidence of a general capability gap, yet no quantitative evidence (e.g., job-shadowing data, frequency analysis of finance spreadsheets, or comparison to occupational task inventories) is supplied to show that the 131 tasks match the distribution and difficulty of real professional work. This selection process is load-bearing for the interpretation of the results.
Authors: The 131 tasks were developed through iterative curation by authors and external annotators with direct professional experience in financial analysis and modeling roles. Selection prioritized tasks involving multi-sheet dependencies, formula synthesis, and iterative updates that mirror documented occupational demands. We do not, however, possess or present quantitative supporting data such as job-shadowing statistics or alignment with formal occupational task inventories. We will revise the benchmark-construction section to describe the expert-driven selection process in greater detail and to explicitly note the absence of frequency-based validation as a limitation. revision: partial
-
Referee: [Evaluation protocol] Evaluation methodology: dynamic correctness is highlighted as a particular weakness, but the manuscript does not detail how this criterion is operationalized across the 3,225 rubric items or how it differs from static correctness in the LM-judge protocol, making it difficult to assess whether the reported gap is robust or rubric-dependent.
Authors: We agree that greater transparency is needed. Dynamic correctness evaluates whether an agent correctly propagates changes across dependent cells and formulas when the workbook state evolves over multiple turns (e.g., a formula that must update after an upstream cell is modified). Static correctness, by contrast, assesses only the final state against ground truth without requiring correct handling of intermediate state transitions. We will add a dedicated subsection in the evaluation protocol that (a) defines both criteria, (b) provides example rubric items for each, and (c) describes how the LM judge is prompted to distinguish them. This revision will be accompanied by supplementary material listing representative rubric excerpts. revision: yes
- Quantitative evidence (job-shadowing data, frequency analysis, or comparison to occupational task inventories) demonstrating that the 131 tasks match the distribution and difficulty of real professional finance spreadsheet work
Circularity Check
No circularity: benchmark is externally validated measurement
full rationale
The paper constructs 131 tasks and 3,225 rubric criteria, validates the LM judge against expert annotators (α=0.826, macro-F1=0.839), and reports direct empirical scores on frontier LLMs. No derivation chain exists that reduces a claimed result to a fitted parameter, self-definition, or self-citation load-bearing premise. The performance numbers are measurements on an independently curated task set rather than predictions forced by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks and rubrics reflect real occupational demands in professional finance.
Reference graph
Works this paper leans on
-
[1]
Bureau of Labor Statistics
U.S. Bureau of Labor Statistics. Occupational employment and wage statistics: National employment and wage data, may 2024. https://www.bls.gov/news.release/ocwage.t01.htm, 2025. Accessed May 2026. 10
2024
-
[2]
Powell, Barry Lawson, and Kenneth R
Stephen G. Powell, Barry Lawson, and Kenneth R. Baker. Impact of errors in operational spreadsheets,
-
[3]
URLhttps://arxiv.org/abs/0801.0715
-
[4]
Science381(6654), 187–192 (2023)
Shakked Noy and Whitney Zhang. Experimental evidence on the productivity effects of generative artificial intelligence.Science, 381(6654):187–192, 2023. doi: 10.1126/science.adh2586. URL https: //www.science.org/doi/abs/10.1126/science.adh2586
-
[5]
Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R
Fabrizio Dell’Acqua, Edward McFowland, Ethan Mollick, Hila Lifshitz, Katherine C. Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R. Lakhani. Navigating the jagged technological frontier: Field experimental evidence of the effects of artificial intelligence on knowledge worker pro- ductivity and quality.Organization Science, 37(2):403–...
-
[6]
Swe-bench: Can language models resolve real-world github issues? In B
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Repre- sentations, volume 2024, pages 54107–54157, 2024. URL https://...
2024
-
[7]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench verified, 2024. URL https: //openai.com/index/introducing-swe-bench-verified/
2024
-
[8]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
Pith/arXiv arXiv 2025
-
[9]
NL2Formula: Generating spreadsheet formulas from natural language queries
Wei Zhao, Zhitao Hou, Siyuan Wu, Yan Gao, Haoyu Dong, Yao Wan, Hongyu Zhang, Yulei Sui, and Haidong Zhang. NL2Formula: Generating spreadsheet formulas from natural language queries. In Yvette Graham and Matthew Purver, editors,Findings of the Association for Computational Linguistics: EACL 2024, pages 2377–2388, St. Julian’s, Malta, March 2024. Associatio...
2024
-
[10]
SheetCopi- lot: Bringing Software Productivity to the Next Level through Large Language Models
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and ZHAO-XIANG ZHANG. SheetCopi- lot: Bringing Software Productivity to the Next Level through Large Language Models. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 4952–4984. Curran Asso- ciates, Inc., 2023....
2023
-
[11]
TableLLM: Enabling tabular data manipulation by LLMs in real office usage scenarios
Xiaokang Zhang, Sijia Luo, Bohan Zhang, Zeyao Ma, Jing Zhang, Yang Li, Guanlin Li, Zijun Yao, Kangli Xu, Jinchang Zhou, Daniel Zhang-Li, Jifan Yu, Shu Zhao, Juanzi Li, and Jie Tang. TableLLM: Enabling tabular data manipulation by LLMs in real office usage scenarios. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Fi...
-
[12]
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao, Hangyu Mao, and Fuzheng Zhang. Sheetagent: Towards a generalist agent for spreadsheet reasoning and manipulation via large language models. InProceedings of the ACM on Web Conference 2025, WWW ’25, page 158–177, New York, NY , USA, 2025. Association for Computing Machinery. ISBN ...
-
[13]
Jan Ravnik, Matjaž Liˇcen, Felix Bührmann, Bithiah Yuan, Felix Stinson, and Tanvi Singh. Finsheet-bench: From simple lookups to complex reasoning, where llms break on financial spreadsheets, 2026. URL https://arxiv.org/abs/2603.07316
arXiv 2026
-
[14]
Spreadsheetarena: Decomposing preference in llm generation of spread- sheet workbooks, 2026
Srivatsa Kundurthy, Clara Na, Michael Handley, Zach Kirshner, Chen Bo Calvin Zhang, Manasi Sharma, Emma Strubell, and John Ling. Spreadsheetarena: Decomposing preference in llm generation of spread- sheet workbooks, 2026. URLhttps://arxiv.org/abs/2603.10002
arXiv 2026
-
[15]
Officebench: Benchmarking language agents across multiple applications for office automation, 2024
Zilong Wang, Yuedong Cui, Li Zhong, Zimin Zhang, Da Yin, Bill Yuchen Lin, and Jingbo Shang. Officebench: Benchmarking language agents across multiple applications for office automation, 2024. URLhttps://arxiv.org/abs/2407.19056. 11
arXiv 2024
-
[16]
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, Natalie S. Kim, Patrick Chao, Samuel Miserendino, Gildas Chabot, David Li, Michael Sharman, Alexandra Barr, Amelia Glaese, and Jerry Tworek. Gdpval: Evaluating ai model performance on real-worl...
Pith/arXiv arXiv 2025
-
[17]
Alphabench: Benchmark- ing large language models in formulaic alpha factor mining
Haochen Luo, Ho Tin Ko, Jiandong Chen, David Sun, Yuan Zhang, and Chen Liu. Alphabench: Benchmark- ing large language models in formulaic alpha factor mining. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=d97Q8r7ZKZ
2026
-
[18]
Officeqa pro: An enterprise benchmark for end-to-end grounded reasoning, 2026
Krista Opsahl-Ong, Arnav Singhvi, Jasmine Collins, Ivan Zhou, Cindy Wang, Ashutosh Baheti, Owen Oertell, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, Matei Zaharia, and Xing Chen. Officeqa pro: An enterprise benchmark for end-to-end grounded reasoning, 2026. URL https://arxiv. org/abs/2603.08655
arXiv 2026
-
[19]
BankerToolBench: Evaluating AI agents in end-to-end investment banking workflows, 2026
Handshake AI, Elaine Lau, Markus Dücker, Ronak Chaudhary, Hui Wen Goh, Rosemary Wei, Vaibhav Kumar, Saed Qunbar, Guram Gogia, Yi Liu, Scott Millslagle, Nasim Borazjanizadeh, Ulyana Tkachenko, Samuel Eshun Danquah, Collin Schweiker, Vijay Karumathil, Asrith Devalaraju, Varsha Sandadi, Haemi Nam, Punit Arani, Ray Epps, Abdullah Arif, Sahil Bhaiwala, Curtis ...
Pith/arXiv arXiv 2026
-
[20]
Bertie Vidgen, Austin Mann, Abby Fennelly, John Wright Stanly, Lucas Rothman, Marco Burstein, Julien Benchek, David Ostrofsky, Anirudh Ravichandran, Debnil Sur, Neel Venugopal, Alannah Hsia, Isaac Robinson, Calix Huang, Olivia Varones, Daniyal Khan, Michael Haines, Austin Bridges, Jesse Boyle, Koby Twist, Zach Richards, Chirag Mahapatra, Brendan Foody, an...
arXiv 2026
-
[21]
FAST Standard Organization, London, 2015
FAST Standard Organization.FAST Modeling Best Practice Handbook. FAST Standard Organization, London, 2015. Financial Modeling Standard
2015
-
[22]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[23]
The stack: 3 tb of permissively licensed source code, 2022
Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The stack: 3 tb of permissively licensed source code, 2022. URL https://arxiv.org/abs/ 2211.15533
arXiv 2022
-
[24]
Zhiruo Wang, Grace Cuenca, Shuyan Zhou, Frank F. Xu, and Graham Neubig. MCoNaLa: A benchmark for code generation from multiple natural languages. In Andreas Vlachos and Isabelle Augenstein, editors, Findings of the Association for Computational Linguistics: EACL 2023, pages 265–273, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics. ...
-
[25]
Li et al., ”Competition-Level Code Gen- eration with AlphaCode,”Science, vol
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Ec- cles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Mas- son d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, P...
-
[26]
Code llama: Open foundation models for code, 2024
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nico...
2024
-
[27]
Raymond R. Panko and Salvatore Aurigemma. Revising the panko-halverson taxonomy of spread- sheet errors.Decision Support Systems, 49(2):235–244, 2010. ISSN 0167-9236. doi: https://doi. org/10.1016/j.dss.2010.02.009. URL https://www.sciencedirect.com/science/article/pii/ S0167923610000461
-
[28]
Spreadsheetbench: Towards challenging real world spreadsheet manipulation
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. Spreadsheetbench: Towards challenging real world spreadsheet manipulation. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 94871–9490...
2024
-
[29]
MiMoTable: A multi-scale spreadsheet benchmark with meta operations for table reasoning
Zheng Li, Yang Du, Mao Zheng, and Mingyang Song. MiMoTable: A multi-scale spreadsheet benchmark with meta operations for table reasoning. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 2548–2560, Abu Dh...
2025
-
[30]
Hendryx, Brad Kenstler, and Bing Liu
Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton Wang, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Sumana Basu, Aishwarya Balwani, Denis Peskoff, Marcos Ayestaran, Sean M. Hendryx, Brad Kenstler, and Bing Liu. Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents, 2025. URLhttps://arxiv.org...
arXiv 2025
-
[31]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
-
[32]
URLhttps://arxiv.org/abs/2211.09110
-
[33]
Gaia: a benchmark for general ai assistants, 2023
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023. URLhttps://arxiv.org/abs/2311.12983
Pith/arXiv arXiv 2023
-
[34]
Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance, 2021
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance, 2021. URLhttps://arxiv.org/abs/2105.07624
arXiv 2021
-
[35]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
Pith/arXiv arXiv 2026
-
[36]
MiniMax-M2.5: Built for real-world productivity
MiniMax. MiniMax-M2.5: Built for real-world productivity. https://www.minimax.io/news/ minimax-m25, February 2026. Model weights: https://huggingface.co/MiniMaxAI/MiniMax-M2. 5
2026
-
[37]
Zora Zhiruo Wang, Sanidhya Vijayvargiya, Aspen Chen, Hanmo Zhang, Venu Arvind Arangarajan, Jett Chen, Valerie Chen, Diyi Yang, Daniel Fried, and Graham Neubig. How well does agent development reflect real-world work?, 2026. URLhttps://arxiv.org/abs/2603.01203. 14 A BLUEFINRubric Descriptions Synthesis and manipulation tasks in BLUEFINare evaluated with bi...
arXiv 2026
-
[38]
Submit Workbooks and Prompt
View task from the “Submit Workbooks and Prompt” category
-
[39]
would this output substantially help in my build process, or would it require significant rework before I could continue?
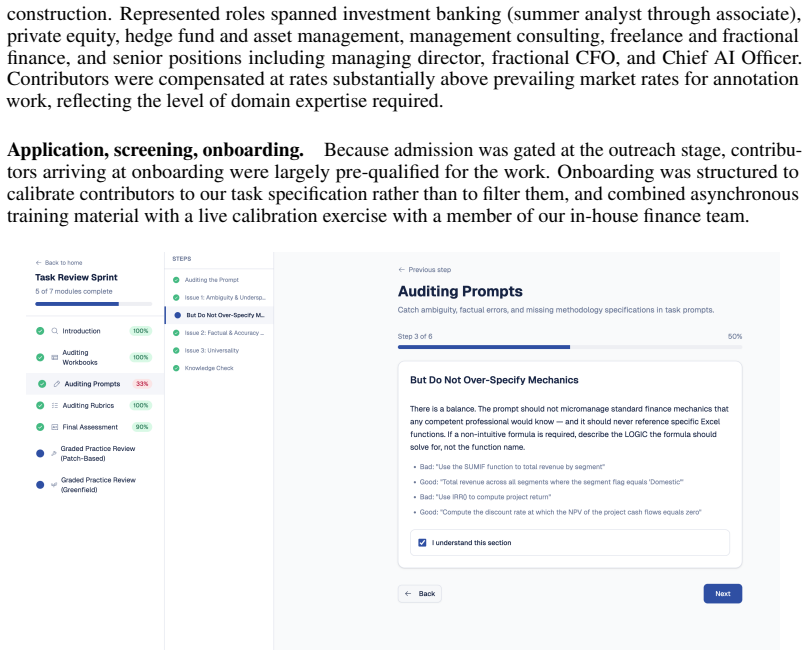
Figure 7: Excerpt from the annotator instructions provided during onboarding. The full document covered task creation, rubric design, quality review, and calibration procedures. dimensions, and each shift triggered retroactive rework on tasks that had already cleared earlier rounds of review. Some examples: • Prompt design.Early task prompts were overly p...
-
[40]
Read the current value of the target output cell
-
[41]
Modify the specified input cell to the test value
-
[42]
Call recalc_workbook to recompute all formulas
-
[43]
Read the target output cell again and verify it changed as expected
-
[44]
done" tool and pass your evaluations as the
Restore the original input value and recalc to leave the workbook unchanged. - If the output does not change after the input modification, the criterion is NOT MET (the model likely hardcoded the value). 19 For each criterion, respond with: - criterion_id: the exact ID string provided - met: true if the criterion’s condition is satisfied, false otherwise ...
-
[45]
open, exec, eval, compile, input, breakpoint, exit, quit, helpare replaced with stubs that raisePermissionError
Builtin allow-list.A curated set of safe builtins (types, iteration, math, print, common exceptions) is exposed. open, exec, eval, compile, input, breakpoint, exit, quit, helpare replaced with stubs that raisePermissionError
-
[46]
detailed
Import allow-list.A wrapper around __import__ permits only math, datetime, decimal, fractions, statistics, collections, itertools, functools, string, re, copy, json, and openpyxl.* submodules. Imports of os, subprocess, sys, socket, etc., raise ImportError. 3.Wall-clock timeout.A 30-secondSIGALRMkills runaway code. E.4 Provider adapters One adapter per pr...
-
[47]
If under cap, untouched
-
[48]
Otherwise, identify large array fields (values, formulas, preview); keep first 40% and last 20% of rows with an elision marker for the omitted middle
-
[49]
shared challenge with diverging mechanism
If still oversized, hard-truncate the JSON string with a marker. Truncation sets _truncated: true on the observation. The character cap follows the precedent set bymini-swe-agent’s 10K cap, relaxed for spreadsheet-shaped results. E.7 Trajectory log format One JSON-Lines file per run ({task_id}_{model}_{timestamp}.jsonl), flushed line-by-line. Entry types:...
2021
-
[50]
Building a monthly OpEx schedule from January 2024 through December 2028 by dividing each annualInputsvalue by 12
2024
-
[51]
Computing annual subtotals as the sum of the 12 monthly cells
-
[52]
other opex
Wiring the new tab back into the KPI Dashboard’s “other opex” placeholders and the Income Statement operating-expense block; and
-
[53]
Preserving dynamic flexibility under perturbation: if Office Lease Rental (Inputs row 68) changes, the corresponding Income Statement period must update without manual intervention. The task is structurally simple – no novel financial logic is required – but stresses a specific capability: locating the correct row in a moderately deep input schedule and p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.