Architecture-Sensitive Supervised Fine-Tuning for Screen-Conditioned Action Prediction: A PiSAR Benchmark
Pith reviewed 2026-06-29 07:36 UTC · model grok-4.3
The pith
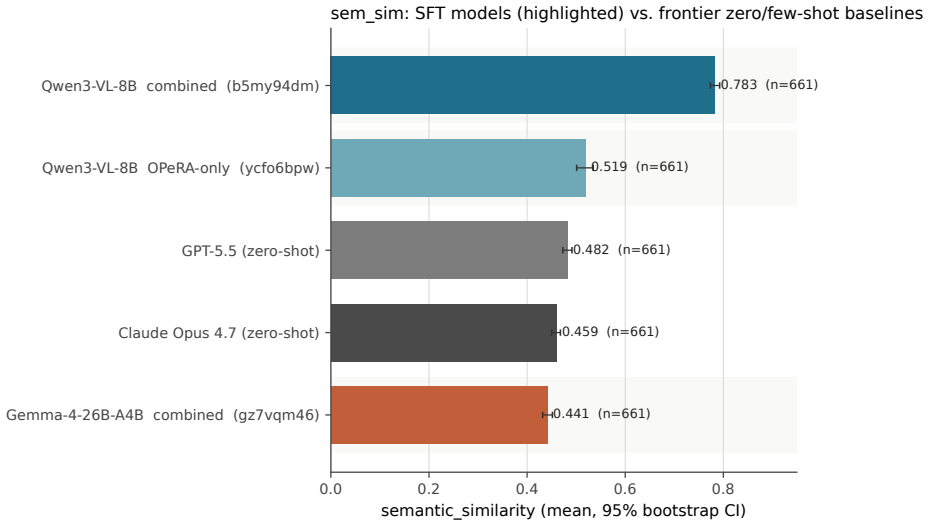
Fine-tuned Qwen3-VL-8B-Instruct reaches 0.783 sem_sim on screen action prediction, 0.30 above frontier zero-shot baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
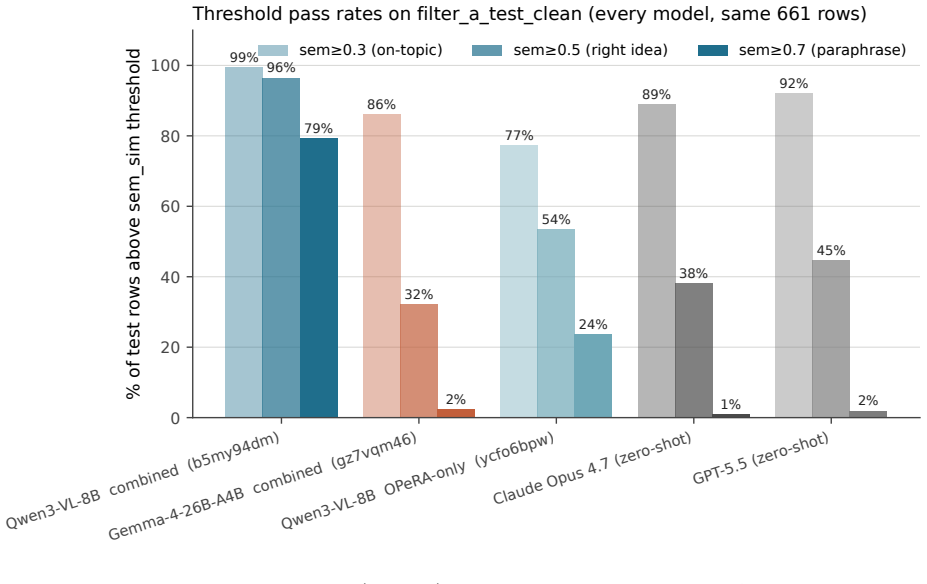
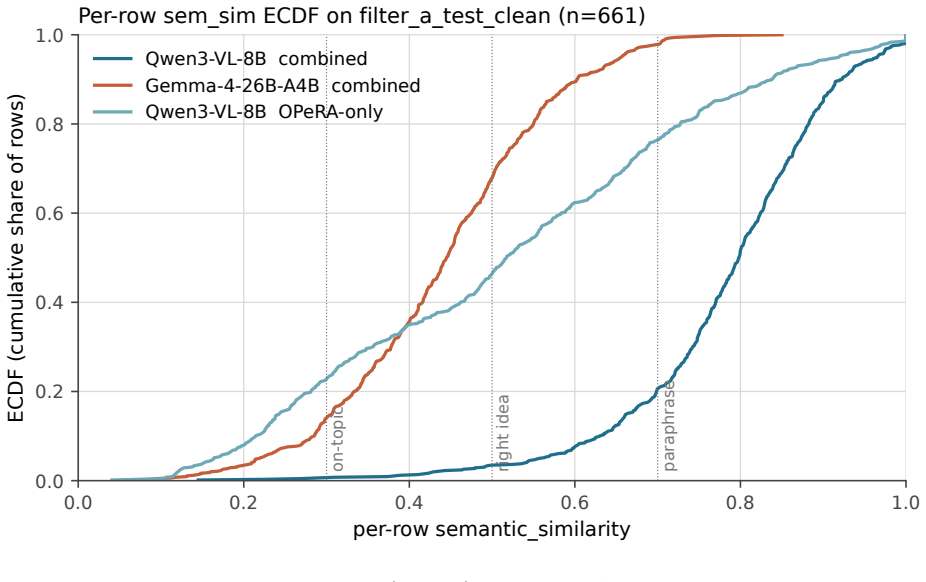
On the same 661-row test set from PiSAR, zero-shot Claude Opus 4.7 and GPT-5.5 achieve sem_sim scores of 0.459 and 0.482. Fine-tuning Qwen3-VL-8B-Instruct on the training data raises this to 0.783 with 79% of rows at or above 0.7, versus 1-2% for the baselines. The identical fine-tuning applied to Gemma-4-26B-A4B-IT produces only 0.441, remaining in the baseline range. The authors interpret this as evidence that fine-tuning effectiveness depends on the underlying model architecture.
What carries the argument
The PiSAR corpus of 12,929 screen-anchored behavioural rationales, scored by the sem_sim metric on a fixed held-out slice to compare fine-tuned and zero-shot models.
If this is right
- Fine-tuning Qwen3-VL-8B-Instruct produces a 0.30 absolute gain in semantic similarity and raises the share of high-quality predictions from 1-2% to 79%.
- The same fine-tuning recipe leaves Gemma-4-26B-A4B-IT at baseline performance, showing that model architecture affects how well a given training approach transfers.
- Reasoning-tuned high-parameter models resist displacement by standard fine-tuning and would likely require more data or a stronger method to improve.
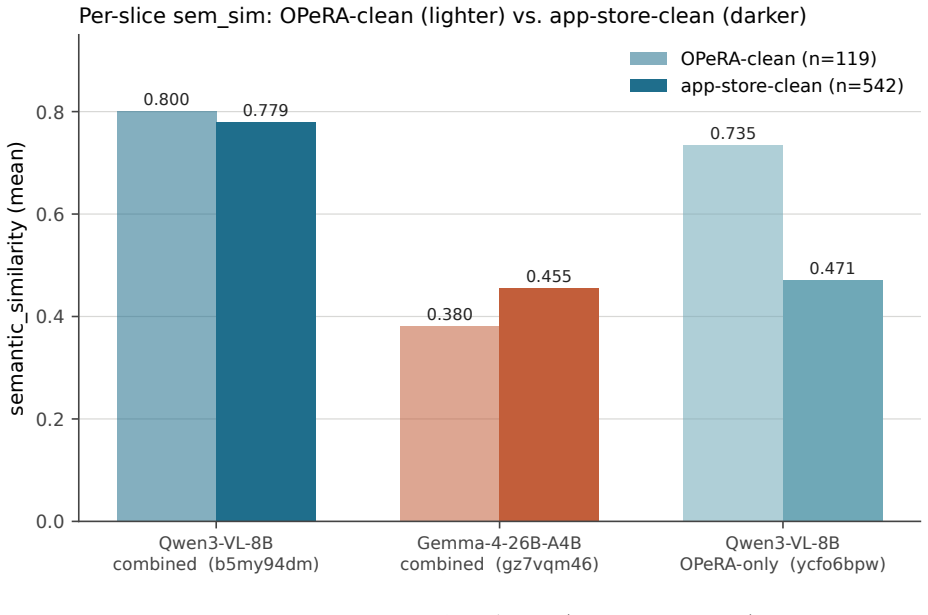
- Data drawn from app-store reviews, Pew demographics, and OPeRA shopper traces supports the observed gains in screen-conditioned action prediction.
Where Pith is reading between the lines
- The architecture sensitivity finding implies that practitioners should test multiple base models rather than assume a single fine-tuning recipe will work across families.
- If the curation sources introduce no hidden bias, similar gains may appear in other screen-interaction domains such as mobile UI agents.
- The mismatch between model scale and fine-tuning success points to a need for architecture-aware training schedules that the paper leaves unexplored.
Load-bearing premise
The 661-row held-out slice is a fair and representative test set, and the sem_sim metric accurately measures the quality of action prediction without bias from the data curation process.
What would settle it
Re-running the evaluation on a new held-out set drawn independently from different app interactions or replacing sem_sim with direct human ratings of predicted action quality to check whether the 0.30 gap persists.
Figures


read the original abstract
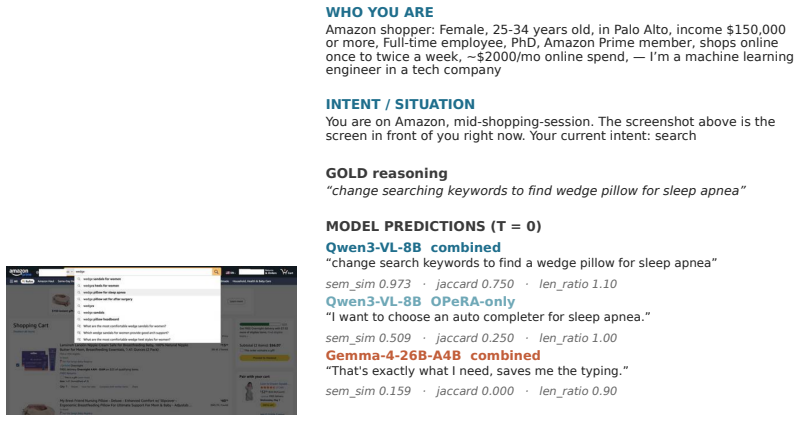
We benchmark three supervised fine-tuned models against frontier zero-shot baselines on a 661-row held-out slice of PiSAR (Persona, intent, Screen, Action, Rationale), a 12,929-tuple corpus of screen-anchored behavioural rationales curated from public app-store reviews, Pew American Trends Panel demographics, and the OPeRA shopper traces. Every model, frontier or fine-tuned, is evaluated on the same 661-row slice with the same scoring pipeline. Two findings. First, frontier zero-shot baselines (Claude Opus 4.7 and GPT-5.5) reach sem_sim 0.459 and 0.482 respectively; a fine-tuned Qwen3-VL-8B-Instruct reaches 0.783 and clears sem_sim >= 0.7 on 79% of rows, against 1-2% for either frontier baseline, a gap of 0.30 absolute on the same test set. Second, the same training data and recipe on Gemma-4-26B-A4B-IT scores only 0.441, in the same band as the frontier zero-shot baselines rather than the fine-tuned Qwen. We read this as a recipe-vs-model mismatch: the reasoning-tuned high-parameter model resists displacement and would likely need either more data or a stronger fine-tuning method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PiSAR benchmark consisting of a 12,929-tuple corpus curated from app-store reviews, Pew American Trends Panel demographics, and OPeRA shopper traces. It reports empirical results on a 661-row held-out slice where frontier zero-shot models (Claude Opus 4.7 and GPT-5.5) achieve sem_sim scores of 0.459 and 0.482 respectively, while a supervised fine-tuned Qwen3-VL-8B-Instruct reaches 0.783 (with 79% of rows >=0.7) and the same SFT recipe applied to Gemma-4-26B-A4B-IT yields only 0.441. The central claim is that these results demonstrate architecture-sensitive supervised fine-tuning for screen-conditioned action prediction, with the performance gap of ~0.30 absolute on identical test rows and scoring pipeline indicating a recipe-vs-model mismatch.
Significance. If the results hold after addressing evaluation concerns, the work provides concrete evidence that SFT can produce large gains on this task for certain model families while leaving others near zero-shot levels, underscoring the need for architecture-aware fine-tuning choices. Credit is due for evaluating every model on the exact same 661-row slice with the same scoring pipeline, which strengthens the direct comparison. The significance is limited by the absence of detailed validation for the sem_sim metric and held-out set representativeness.
major comments (2)
- [Evaluation / held-out slice] The 661-row held-out slice (abstract and evaluation description): the claim that the 0.30 absolute sem_sim gap demonstrates genuine improvement in action prediction quality is load-bearing for both the performance and architecture-sensitivity conclusions, yet the curation process (app-store reviews, Pew demographics, OPeRA traces) and lack of reported checks for stylistic artifacts or embedding overlap with sem_sim references leave open the possibility that gains reflect distribution matching rather than task capability. A concrete test (e.g., adversarial re-sampling or metric ablation) is needed to isolate this.
- [Results / architecture comparison] Architecture-sensitivity interpretation (abstract): the observation that Gemma-4-26B-A4B-IT remains at 0.441 after identical SFT while Qwen3-VL-8B-Instruct reaches 0.783 is presented as evidence of model-vs-recipe mismatch, but without reported ablations on data volume, learning rate schedule, or loss formulation per architecture, the attribution to inherent model properties rather than hyperparameter sensitivity is not yet supported.
minor comments (1)
- [Abstract / Methods] The abstract states sem_sim >=0.7 percentages but does not define the embedding model or reference corpus used for sem_sim; this notation should be clarified in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation / held-out slice] The 661-row held-out slice (abstract and evaluation description): the claim that the 0.30 absolute sem_sim gap demonstrates genuine improvement in action prediction quality is load-bearing for both the performance and architecture-sensitivity conclusions, yet the curation process (app-store reviews, Pew demographics, OPeRA traces) and lack of reported checks for stylistic artifacts or embedding overlap with sem_sim references leave open the possibility that gains reflect distribution matching rather than task capability. A concrete test (e.g., adversarial re-sampling or metric ablation) is needed to isolate this.
Authors: We agree that the absence of explicit checks for distribution matching or stylistic artifacts is a limitation. The held-out slice was drawn from the same multi-source curation pipeline as the training data to promote representativeness, but we did not report embedding overlap statistics or adversarial resampling. In revision we will add a quantitative analysis of embedding cosine similarities between the held-out set and training corpus plus a limitations paragraph acknowledging that distribution matching cannot be fully ruled out without such tests. A full adversarial re-sampling experiment lies outside the current experimental budget. revision: partial
-
Referee: [Results / architecture comparison] Architecture-sensitivity interpretation (abstract): the observation that Gemma-4-26B-A4B-IT remains at 0.441 after identical SFT while Qwen3-VL-8B-Instruct reaches 0.783 is presented as evidence of model-vs-recipe mismatch, but without reported ablations on data volume, learning rate schedule, or loss formulation per architecture, the attribution to inherent model properties rather than hyperparameter sensitivity is not yet supported.
Authors: The referee is correct that we did not conduct architecture-specific hyperparameter ablations. The reported results use a single standardized SFT recipe applied to both models precisely to illustrate sensitivity under matched conditions. We will revise the abstract and discussion sections to present the 0.30 gap as an observation under fixed training settings rather than conclusive evidence of irreducible model properties, and we will add an explicit statement that per-architecture optimization remains an open direction. revision: yes
Circularity Check
No circularity: empirical held-out evaluation on independent test slice
full rationale
The paper presents a standard machine-learning benchmark: a 12,929-tuple corpus is split, models are fine-tuned on the training portion, and all models (fine-tuned and zero-shot baselines) are scored with the same sem_sim metric on the identical 661-row held-out slice. No equations, fitted parameters, or derivations are claimed; the headline numbers (0.783 vs 0.459/0.482) are direct empirical measurements. None of the six enumerated circularity patterns apply—no self-definitional quantities, no fitted inputs relabeled as predictions, no load-bearing self-citations, and no ansatz or uniqueness theorems. The result is therefore self-contained against external benchmarks and receives the default non-circularity score.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generative agents: Interactive simulacra of human behavior,
doi:10.1145/3586183.3606763. Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie J. Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. Generative agent simulations of 1,000 people.arXiv preprint,
-
[2]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
doi:10.48550/arXiv.2411.10109. Marcel Binz and Eric Schulz. Using cognitive psychology to understand GPT-3.Proceedings of the National Academy of Sciences (PNAS), 120(6),
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.10109
-
[3]
doi:10.1073/pnas.2218523120. 12 Marcel Binz, Elif Akata, Matthias Bethge, Miguel Brand, Evelina Fedorenko, Jan-Philipp Fränken, Moshe Glickman, Karim Haggag, Caroline Hoffmann, and Eric Schulz. Centaur: A foundation model of human cognition.Nature,
-
[4]
Aida Namazova, Lorenzo Brondetta, Y
Preprint released October 2024 as arXiv:2410.20268. Aida Namazova, Lorenzo Brondetta, Y. Strittmatter, Matthew R. Nassar, and Sebastian Musslick. Not yet AlphaFold for the mind: Evaluating Centaur as a synthetic participant.arXiv preprint,
-
[5]
doi:10.48550/arXiv.2508.07887. Marcel Binz et al. Post-training makes large language models less human-like.arXiv preprint,
-
[6]
Post-training makes large language models less human-like
doi:10.48550/arXiv.2605.07632. Yao Lu, Yu-Chen Yao, Xingjian Gu, Yu-Hsuan Huang, et al. UXAgent: An LLM-Agent-Based usability testing framework for web design. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25), 2025a. doi:10.1145/3706599.3719729. Yao Lu, Yu-Hsuan Huang, Z. Han, Yu-Chen Yao, et al. Prompting is n...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07632
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
doi:10.48550/arXiv.2106.09685. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quan- tized LLMs. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685
-
[8]
QLoRA: Efficient Finetuning of Quantized LLMs
doi:10.48550/arXiv.2305.14314. Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Zhang, Juanzi Li, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. CogAgent: A visual language model for GUI agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.14314
-
[9]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su
doi:10.48550/arXiv.2312.08914. Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems,
-
[10]
Mind2Web: Towards a Generalist Agent for the Web
doi:10.48550/arXiv.2306.06070. FireworksAI. FireworksAI:Managedinferenceandsupervisedfine-tuningplatform. https://fireworks.ai/,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.06070
-
[11]
auto completer
We did not override Fireworks- managed-SFT defaults beyond what the UI exposes. 13 Eval-time inference settings:T = 0.0, top_p=1.0, top_k=40, max_tokens=200 for the two Qwen runs and 1,500 for the Gemma run (raised after we found the chain-of-thought template was exhausting the budget mid-thinking; see Section 4.2). Concurrency 6 against Fireworks’ OpenAI...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.