Hist2Style: Histogram-Guided Stylization with Bilateral Grids
Pith reviewed 2026-06-28 15:21 UTC · model grok-4.3
The pith
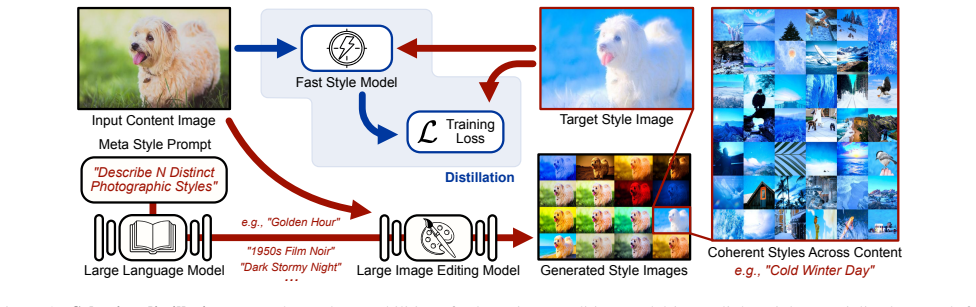
Hist2Style distills large editing models into a lightweight bilateral-grid network conditioned on style histograms to deliver real-time photorealistic stylization without hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hist2Style formulates stylization as locally affine transforms performed in bilateral space and conditions those transforms on a histogram-based embedding of the style target. Training a lightweight network on a large supervised corpus generated by language and vision-language models produces a model that executes edge-aware color and tone edits while preserving visual fidelity.
What carries the argument
The bilateral-grid formulation that applies locally affine transforms in bilateral space, conditioned on a histogram embedding of the style target.
If this is right
- Real-time processing becomes feasible for high-resolution images.
- Users can interactively adjust output color and tone by editing the target histogram.
- Content structure is preserved by the bilateral-grid constraints without additional regularization.
- Hallucinations are avoided because operations stay within locally affine color transforms.
Where Pith is reading between the lines
- The histogram interface could be adapted to control other spatially varying edits such as local contrast or exposure.
- Similar distillation into bilateral grids might speed up related tasks like video color grading if temporal consistency is added.
- The approach suggests that many global appearance edits can be reduced to histogram-guided local affine adjustments without full generative models.
Load-bearing premise
The locally affine bilateral-grid transforms distilled from the supervised corpus will generalize to arbitrary real-world images without introducing artifacts or fidelity loss.
What would settle it
Applying the trained network to real images outside the generated training distribution and observing either changes to scene structure or visible artifacts would falsify the generalization claim.
Figures






read the original abstract
Photorealistic style transfer aims to match the color and tone of an input image to that of a style target while preserving the content and details of the original scene. Although existing large image models can facilitate these kinds of appearance edits, their high computational demands, potential for hallucinations, and limited user control make them unsuitable for high-resolution, real-time workflows. We introduce Hist2Style, a bilateral-grid formulation for fast, edge-aware stylization that preserves visual fidelity by constraining operations to locally affine transforms in bilateral space. Our model distills a large image editing model into a lightweight network by training on a large supervised corpus generated with language and vision-language models, targeting spatially varying color edits. The network conditions on a histogram-based embedding of the style target to provide an interpretable interface for adjusting the output style by modifying the target color distribution. Overall, Hist2Style maintains content structure by construction, avoids hallucinations, and supports real-time, high-resolution photorealistic stylization with interactive user-controllable color and tone adjustments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hist2Style, a bilateral-grid formulation for photorealistic style transfer. It distills a large image editing model into a lightweight network trained on a supervised corpus generated by language and vision-language models, targeting spatially varying color edits. The network conditions on a histogram-based embedding of the style target to enable interpretable user adjustments to color and tone. The approach claims to maintain content structure by construction via locally affine transforms in bilateral space, avoid hallucinations, and support real-time, high-resolution stylization with interactive control.
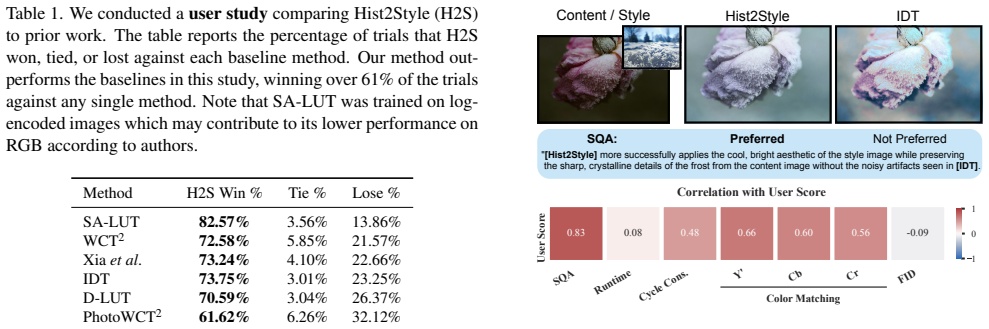
Significance. If the claims hold, the work would be significant for enabling efficient, controllable photorealistic stylization without the computational cost or hallucination risks of large models. The bilateral-grid approach for edge-aware, locally affine transforms is a strength for real-time high-resolution workflows, and the histogram conditioning provides a practical interface for user control. The distillation strategy from large models to a lightweight network could have broader applicability.
major comments (2)
- [Abstract] Abstract: The claim that content structure is 'maintained by construction' and hallucinations are 'avoided' rests on the locally affine transforms in bilateral space, but the abstract provides no equations, derivation, or analysis showing why these transforms remain artifact-free when input histograms and content deviate from the synthetic training corpus generated by LMs/VLMs. This is load-bearing for the central no-hallucination and generalization claims.
- [Method] The skeptic concern on generalization is valid here: nothing in the formulation as described guarantees that the predicted per-grid affine coefficients will not over-smooth or introduce ringing at boundaries unseen during distillation. The paper must provide either a theoretical argument or targeted experiments demonstrating robustness outside the training distribution.
minor comments (1)
- [Abstract] Abstract: The phrase 'targeting spatially varying color edits' is vague; specify how the histogram embedding enforces spatial variation versus global tone shifts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and commit to appropriate revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that content structure is 'maintained by construction' and hallucinations are 'avoided' rests on the locally affine transforms in bilateral space, but the abstract provides no equations, derivation, or analysis showing why these transforms remain artifact-free when input histograms and content deviate from the synthetic training corpus generated by LMs/VLMs. This is load-bearing for the central no-hallucination and generalization claims.
Authors: We agree the abstract would benefit from added context. The structure-preserving property follows from the bilateral grid being constructed directly from the content image's spatial and intensity coordinates; locally affine transforms are then applied within these content-adaptive cells, which by definition prevents cross-edge mixing or structural hallucination regardless of the specific coefficient values (the operation remains a per-region color/tone adjustment). We will revise the abstract to briefly note this property and reference the equations in Section 3. revision: yes
-
Referee: [Method] The skeptic concern on generalization is valid here: nothing in the formulation as described guarantees that the predicted per-grid affine coefficients will not over-smooth or introduce ringing at boundaries unseen during distillation. The paper must provide either a theoretical argument or targeted experiments demonstrating robustness outside the training distribution.
Authors: The concern is valid; while the bilateral formulation limits certain artifacts (e.g., no edge crossing), network-predicted coefficients could still produce over-smoothing or ringing on out-of-distribution inputs. We will add a short theoretical note on the bounded interpolation properties of the bilateral grid and include targeted experiments on challenging OOD cases (extreme histograms, unseen fine structures) to demonstrate robustness. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, derivations, or load-bearing steps that reduce to inputs by construction. The claim of preserving structure 'by construction' via locally affine bilateral-grid transforms is a direct statement of the method's design property rather than a self-referential reduction. Distillation from external LMs/VLMs is described as a training process without evidence of fitted parameters being renamed as predictions or self-citation chains. No self-definitional, fitted-input, or uniqueness-imported patterns are identifiable from the text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Locally affine transforms in bilateral space maintain content structure by construction
Reference graph
Works this paper leans on
-
[1]
Accessed: 2025- 11-13
Unsplash.https://unsplash.com. Accessed: 2025- 11-13
2025
-
[2]
Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild
Abubakar Abid, Ali Abdalla, Ali Abid, Dawood Khan, Ab- dulrahman Alfozan, and James Zou. Gradio: Hassle-free sharing and testing of ml models in the wild.arXiv preprint arXiv:1906.02569, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[3]
Fast high- dimensional filtering using the permutohedral lattice.Euro- graphics, 2010
Andrew Adams, Jongmin Baek, and Abe Davis. Fast high- dimensional filtering using the permutohedral lattice.Euro- graphics, 2010
2010
-
[4]
Adobe photoshop lightroom, 2007
Adobe Systems Incorporated. Adobe photoshop lightroom, 2007
2007
-
[5]
The fast bilateral solver
Jonathan T Barron and Ben Poole. The fast bilateral solver. ECCV, 2016
2016
-
[6]
Fast bilateral-space stereo for synthetic de- focus.CVPR, 2015
Jonathan T Barron, Andrew Adams, YiChang Shih, and Car- los Hern´andez. Fast bilateral-space stereo for synthetic de- focus.CVPR, 2015
2015
-
[7]
Experiment tracking with weights and bi- ases, 2020
Lukas Biewald. Experiment tracking with weights and bi- ases, 2020
2020
-
[8]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[9]
IQA-PyTorch: Pytorch toolbox for image quality assessment
Chaofeng Chen and Jiadi Mo. IQA-PyTorch: Pytorch toolbox for image quality assessment. [Online]. Avail- able:https : / / github . com / chaofengc / IQA - PyTorch, 2022
2022
-
[10]
Nlut: Neural-based 3d lookup tables for video photorealistic style transfer, 2023
Yaosen Chen, Han Yang, Yuexin Yang, Yuegen Liu, Wei Wang, Xuming Wen, and Chaoping Xie. Nlut: Neural-based 3d lookup tables for video photorealistic style transfer, 2023
2023
-
[11]
Photowct 2: Compact autoencoder for photorealistic style transfer resulting from blockwise training and skip connections of high-frequency residuals, 2021
Tai-Yin Chiu and Danna Gurari. Photowct 2: Compact autoencoder for photorealistic style transfer resulting from blockwise training and skip connections of high-frequency residuals, 2021
2021
-
[12]
Color psychology: Effects of perceiving color on psychological functioning in humans
Andrew Elliot and Markus Maier. Color psychology: Effects of perceiving color on psychological functioning in humans. Annual review of psychology, 65, 2013
2013
-
[13]
Histogan: Controlling colors of gan-generated and real images via color histograms
Afifi et al. Histogan: Controlling colors of gan-generated and real images via color histograms. InCVPR, 2021
2021
-
[14]
Toward generalized image quality assessment: Relaxing the perfect reference quality assumption, 2025
Chen et al. Toward generalized image quality assessment: Relaxing the perfect reference quality assumption, 2025
2025
-
[15]
Image quality assessment: From human to machine preference, 2025
Li et al. Image quality assessment: From human to machine preference, 2025
2025
-
[16]
PyTorch Lightning, 2019
William Falcon and The PyTorch Lightning team. PyTorch Lightning, 2019
2019
-
[17]
A Neural Algorithm of Artistic Style
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. A neural algorithm of artistic style.CoRR, abs/1508.06576, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Barron, Samuel W
Micha ¨el Gharbi, Jiawen Chen, Jonathan T. Barron, Samuel W. Hasinoff, and Fr ´edo Durand. Deep bilateral learning for real-time image enhancement.ACM Transac- tions on Graphics, 36(4):1–12, 2017
2017
-
[19]
Sa-lut: Spatial adaptive 4d look-up ta- ble for photorealistic style transfer, 2025
Zerui Gong, Zhonghua Wu, Qingyi Tao, Qinyue Li, and Chen Change Loy. Sa-lut: Spatial adaptive 4d look-up ta- ble for photorealistic style transfer, 2025
2025
-
[20]
Routledge, 2019
Charles Haine.Color Grading 101: getting started color grading for editors, cinematographers, directors, and aspir- ing colorists. Routledge, 2019
2019
-
[21]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InICCV, 2017
2017
-
[23]
Matplotlib: A 2d graphics environment
John D Hunter. Matplotlib: A 2d graphics environment. Computing in science & engineering, 9(03):90–95, 2007
2007
-
[24]
Neural Style Transfer: A Review
Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, and Mingli Song. Neural style transfer: A review.CoRR, abs/1705.04058, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Zhanghan Ke, Yuhao Liu, Lei Zhu, Nanxuan Zhao, and Ryn- son W.H. Lau. Neural preset for color style transfer. InCom- puter Vision and Pattern Recognition Conference (CVPR), 2023
2023
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
2025
-
[28]
D-LUT: Photorealistic Style Transfer via Diffusion Process
Mujing Li, Guanjie Wang, Xingguang Zhang, Qifeng Liao, and Chenxi Xiao. D-LUT: Photorealistic Style Transfer via Diffusion Process . In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 9206–9214, Los Alamitos, CA, USA, 2025. IEEE Computer Society
2025
-
[29]
Universal Style Transfer via Feature Transforms
Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. Universal style transfer via feature transforms.CoRR, abs/1705.08086, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
A Closed-form Solution to Photorealistic Image Stylization
Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, and Jan Kautz. A closed-form solution to photorealistic image stylization.CoRR, abs/1802.06474, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
A convnet for the 2020s.CoRR, abs/2201.03545, 2022
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s.CoRR, abs/2201.03545, 2022. 9
-
[32]
Fujun Luan, Sylvain Paris, Eli Shechtman, and Kavita Bala. Deep photo style transfer.arXiv preprint arXiv:1703.07511, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Null-text inversion for editing real images using guided diffusion models, 2022
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models, 2022
2022
-
[34]
pandas-dev/pandas: Pandas
The pandas development team. pandas-dev/pandas: Pandas. 2020
2020
-
[35]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InCVPR, 2022
2022
-
[36]
Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in Neural Information Processing Systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in Neural Information Processing Systems, 32, 2019
2019
-
[37]
Scikit-learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
Fabian Pedregosa, Ga ¨el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
2011
-
[38]
Computational optimal transport, 2020
Gabriel Peyr ´e and Marco Cuturi. Computational optimal transport, 2020
2020
-
[39]
P. F. Piti ´e and A. C. Kokaram. The linear monge- kantorovitch linear colour mapping for example-based colour transfer. InProceedings of the 4th IEE European Conference on Visual Media Production (CVMP), London, United Kingdom, 2007
2007
-
[40]
P. F. Piti ´e, A. C. Kokaram, and R. Dahyot. N-dimensional probability density function transfer and its application to colour transfer. InProceedings of the IEEE International Conference on Computer Vision (ICCV), Beijing, China, 2005
2005
-
[41]
P. F. Piti ´e, A. C. Kokaram, and R. Dahyot. Towards auto- mated colour grading. InProceedings of the 2nd IEE Euro- pean Conference on Visual Media Production (CVMP), Lon- don, United Kingdom, 2005
2005
-
[42]
P. F. Piti´e, A. C. Kokaram, and R. Dahyot. Automated colour grading using colour distribution transfer.Computer Vision and Image Understanding, 2007
2007
-
[43]
P. F. Piti ´e, A. C. Kokaram, and R. Dahyot. Enhancement of digital photographs using color transfer techniques. In Single-Sensor Imaging, pages 295–321. CRC Press, 2008
2008
-
[44]
Julien Porquet, Sitong Wang, and Lydia B. Chilton. Copying style, extracting value: Illustrators’ perception of AI style transfer and its impact on creative labor, 2025
2025
-
[45]
Reinhard, M
E. Reinhard, M. Ashikhmin, B. Gooch, and P. Shirley. Color transfer between images.IEEE Computer Graphics and Ap- plications, 21(5):34–41, 2001
2001
-
[46]
statsmodels: Econo- metric and statistical modeling with python
Skipper Seabold and Josef Perktold. statsmodels: Econo- metric and statistical modeling with python. In9th Python in Science Conference, 2010
2010
-
[47]
A survey of multimodal-guided image editing with text-to-image diffu- sion models, 2024
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, and Dacheng Tao. A survey of multimodal-guided image editing with text-to-image diffu- sion models, 2024
2024
-
[48]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[49]
Gem- ini: A family of highly capable multimodal models, 2025
Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gem- ini: A family of highly capable multimodal models, 2025
2025
-
[50]
Unsplash lite dataset photos
Unsplash. Unsplash lite dataset photos. GitHub repository
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.CoRR, abs/1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Image editing with diffusion models: A sur- vey, 2025
Jia Wang, Jie Hu, Xiaoqi Ma, Hanghang Ma, Xiaoming Wei, and Enhua Wu. Image editing with diffusion models: A sur- vey, 2025
2025
-
[53]
Bilateral guided radiance field processing, 2024
Yuehao Wang, Chaoyi Wang, Bingchen Gong, and Tianfan Xue. Bilateral guided radiance field processing, 2024
2024
-
[54]
Seaborn: statistical data visualization
Michael L Waskom. Seaborn: statistical data visualization. Journal of Open Source Software, 6(60):3021, 2021
2021
-
[55]
Dimitrova, and Shih-Fu Chang
Cheng-Yu Wei, N. Dimitrova, and Shih-Fu Chang. Color- mood analysis of films based on syntactic and psychological models. In2004 IEEE International Conference on Multi- media and Expo (ICME) (IEEE Cat. No.04TH8763), pages 831–834 V ol.2, 2004
2004
-
[56]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
2025
-
[57]
Xide Xia, Meng Zhang, Tianfan Xue, Zheng Sun, Hui Fang, Brian Kulis, and Jiawen Chen. Joint bilateral learning for real-time universal photorealistic style transfer.CoRR, abs/2004.10955, 2020
-
[58]
Photorealistic style transfer via wavelet transforms
Jaejun Yoo, Youngjung Uh, Sanghyuk Chun, Byeongkyu Kang, and Jung-Woo Ha. Photorealistic style transfer via wavelet transforms. InInternational Conference on Com- puter Vision (ICCV), 2019
2019
-
[59]
Style transfer: A decade survey, 2025
Tianshan Zhang and Hao Tang. Style transfer: A decade survey, 2025
2025
- [60]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.