LAMP: Lane-Aligned Motion Primitives for Feasible Trajectory Prediction
Pith reviewed 2026-06-26 05:18 UTC · model grok-4.3
The pith
LAMP anchors multimodal predictions to lane-aligned motion primitives learned by VQ-VAE to raise feasibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
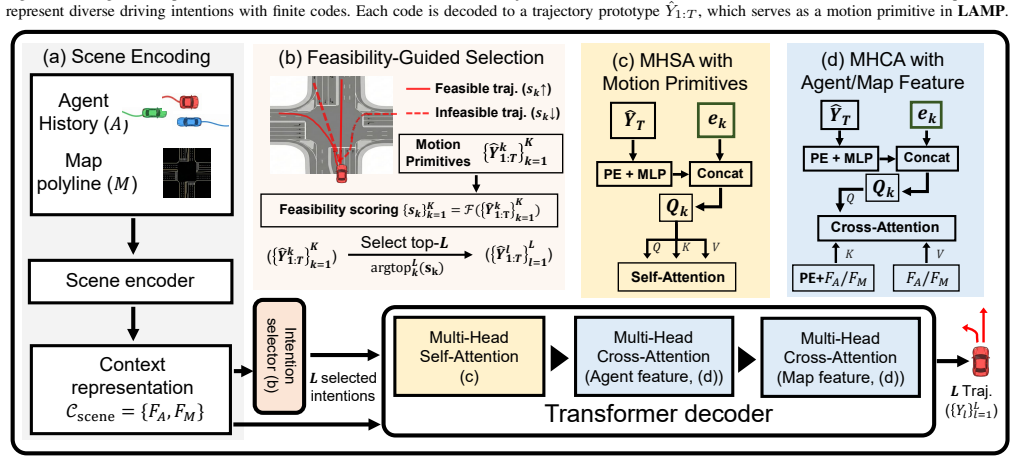
LAMP anchors multimodal prediction to structured motion primitives aligned with lane topology by using a VQ-VAE to learn discrete intention queries that capture spatiotemporal patterns beyond endpoints and by training a feasibility-aware intention selector with a lane-topology prior that filters unreachable queries, guiding the decoder to produce topology-consistent yet diverse predictions.
What carries the argument
Lane-aligned motion primitives as discrete codes from a VQ-VAE, filtered by a feasibility-aware intention selector that uses a lane-topology prior.
If this is right
- Predicted trajectories violate fewer physical and logical lane constraints.
- Prediction sets become more reliable inputs for downstream safety-critical planning.
- Diversity is preserved because the selector does not remove all low-probability but reachable modes.
- Accuracy on standard displacement metrics remains comparable to existing methods.
Where Pith is reading between the lines
- Planners might need fewer separate post-hoc feasibility filters when using these predictions.
- The same discrete primitive approach could transfer to other structured prediction domains with topology constraints.
- Long-horizon consistency might improve because early choices are already lane-constrained.
Load-bearing premise
The lane-topology prior correctly identifies unreachable intention queries without discarding behaviorally important modes.
What would settle it
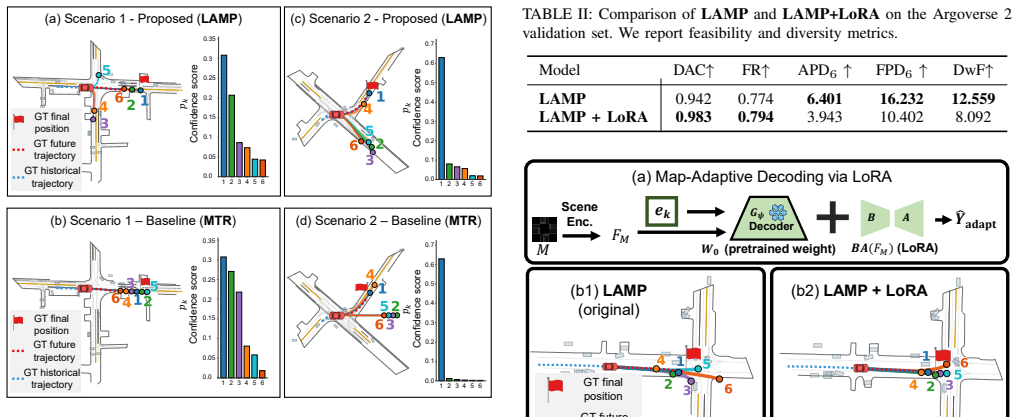
If feasibility and diversity metrics on Argoverse 2 show no gain over baselines while displacement error stays comparable, the performance advantage would not hold.
Figures


read the original abstract
Motion forecasting is essential for autonomous driving systems to enable safe decision-making and planning in complex driving scenarios. While existing predictors excel at minimizing standard displacement errors, they often overlook the adherence to lane topology of multimodal predictions, particularly for lower-probability modes. Consequently, predicted trajectories may violate physical and logical constraints, making the prediction set unreliable for safety-critical planning. In this paper, we propose LAMP (Lane-Aligned Motion Primitives), a topology-aware forecasting framework that anchors multimodal prediction to structured motion primitives aligned with lane topology. Specifically, we use a VQ-VAE to learn shape-aware motion primitives as discrete intention queries, capturing spatiotemporal patterns beyond endpoint-based intentions. We further introduce a feasibility-aware intention selector trained with a lane-topology prior for filtering unreachable intention queries, guiding the decoder to prioritize topology-consistent intentions while preserving behavioral diversity. Extensive experiments on the Argoverse 2 dataset demonstrate that LAMP achieves prediction accuracy comparable to state-of-the-art baselines while outperforming them in feasibility and diversity metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAMP, a topology-aware motion forecasting framework that learns shape-aware motion primitives via VQ-VAE as discrete intention queries and employs a feasibility-aware intention selector trained with a lane-topology prior to filter unreachable queries before decoding. It claims that this yields prediction accuracy comparable to state-of-the-art baselines while improving feasibility and diversity metrics on the Argoverse 2 dataset.
Significance. If the central claims hold after verification of the prior, the approach could offer a practical way to anchor multimodal predictions to lane structure without sacrificing coverage of relevant behaviors, which would be useful for safety-critical planning. The VQ-VAE component for capturing spatiotemporal patterns beyond endpoints is a potentially reusable idea if ablations confirm its contribution independent of the selector.
major comments (3)
- [Experiments] Experiments section: the headline claim of superior feasibility and diversity rests on the lane-topology prior correctly labeling only unreachable intentions; no analysis is provided of the fraction of Argoverse 2 ground-truth trajectories that the prior would classify as unreachable, which is required to rule out over-filtering of valid lane-change or cut-in modes.
- [Method] Method section on VQ-VAE and selector: the codebook size and selector threshold are listed as free parameters with no reported ablation or selection procedure; without these the reported gains cannot be reproduced or shown to be robust rather than tuned to the evaluation set.
- [Results] Results: quantitative tables, error bars, and per-metric breakdowns comparing LAMP to baselines on accuracy, feasibility, and diversity are referenced in the abstract but the provided manuscript text supplies none, preventing assessment of effect sizes or statistical significance.
minor comments (2)
- [Method] Notation for the discrete queries and the selector output probabilities should be defined explicitly in the method section to avoid ambiguity when describing the filtering step.
- [Abstract] The abstract states 'extensive experiments' but the manuscript would benefit from a short table summarizing the key hyperparameter choices (codebook size, threshold) even if full ablations are moved to the supplement.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments and the recommendation for major revision. We will address the concerns regarding the lane-topology prior analysis, hyperparameter ablations, and presentation of quantitative results in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim of superior feasibility and diversity rests on the lane-topology prior correctly labeling only unreachable intentions; no analysis is provided of the fraction of Argoverse 2 ground-truth trajectories that the prior would classify as unreachable, which is required to rule out over-filtering of valid lane-change or cut-in modes.
Authors: We agree that this analysis is necessary to validate the prior. In the revised version, we will add a new subsection or table reporting the percentage of ground-truth trajectories classified as unreachable by the lane-topology prior, with breakdowns by scenario types including lane changes and cut-ins. This will confirm that the prior does not excessively filter valid behaviors while improving feasibility. revision: yes
-
Referee: [Method] Method section on VQ-VAE and selector: the codebook size and selector threshold are listed as free parameters with no reported ablation or selection procedure; without these the reported gains cannot be reproduced or shown to be robust rather than tuned to the evaluation set.
Authors: We acknowledge the importance of reporting hyperparameter choices. We will include ablations on the codebook size (varying from 64 to 512) and selector threshold in the experiments section of the revision. The selection procedure, based on validation performance for feasibility and diversity without sacrificing accuracy, will also be detailed. revision: yes
-
Referee: [Results] Results: quantitative tables, error bars, and per-metric breakdowns comparing LAMP to baselines on accuracy, feasibility, and diversity are referenced in the abstract but the provided manuscript text supplies none, preventing assessment of effect sizes or statistical significance.
Authors: The manuscript text does reference the results, but we recognize that detailed tables may not have been sufficiently included or visible. We will ensure the revised manuscript prominently features Tables 1-3 with quantitative comparisons, including error bars (standard deviation over multiple runs) and per-metric breakdowns. Statistical significance tests (e.g., paired t-tests) will be added where appropriate. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper describes a VQ-VAE for discrete motion primitives followed by a feasibility-aware selector that incorporates an external lane-topology prior from map data. No equations, fitted parameters, or self-citations are quoted that reduce the reported feasibility or diversity metrics to the selector's training prior by construction. The prior is presented as an independent input rather than a self-defined quantity, and all metrics are evaluated against the Argoverse 2 ground truth without evidence of tautological re-labeling. This is the normal case of a non-circular architecture paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- VQ-VAE codebook size
axioms (1)
- domain assumption Lane topology provides a reliable prior for reachable intentions
invented entities (1)
-
Lane-aligned motion primitives
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Motion transformer with global intention localization and local movement refinement,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “Motion transformer with global intention localization and local movement refinement,”Advances in Neural Information Processing Systems, vol. 35, pp. 6531–6543, 2022
2022
-
[2]
VectorNet: Encoding HD maps and agent dynamics from vectorized representation,
J. Gao, C. Sun, H. Zhao,et al., “VectorNet: Encoding HD maps and agent dynamics from vectorized representation,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020, pp. 11525–11533
2020
-
[3]
Desire: Distant future prediction in dynamic scenes with interacting agents,
N. Lee, W. Choi, P. Vernaza,et al., “Desire: Distant future prediction in dynamic scenes with interacting agents,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 336– 345
2017
-
[4]
Social GAN: Socially accept- able trajectories with generative adversarial networks,
A. Gupta, J. Johnson, L. Fei-Fei,et al., “Social GAN: Socially accept- able trajectories with generative adversarial networks,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 2255–2264
2018
-
[5]
Trajec- tron++: Dynamically-feasible trajectory forecasting with heterogeneous data,
T. Salzmann, B. Ivanovic, P. Chakravarty, and M. Pavone, “Trajec- tron++: Dynamically-feasible trajectory forecasting with heterogeneous data,” inProceedings of the European Conference on Computer Vision, 2020, pp. 683–700
2020
-
[6]
ChauffeurNet: Learning to drive by imitating the best and synthesizing the worst,
M. Bansal, A. Krizhevsky, and A. Ogale, “ChauffeurNet: Learning to drive by imitating the best and synthesizing the worst,” inProceedings of the Robotics: Science and Systems, 2019
2019
-
[7]
Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction,
Y . Chai, B. Sapp, M. Bansal, and D. Anguelov, “Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction,” in Proceedings of the Conference on Robot Learning, 2020, pp. 86–99
2020
-
[8]
CoverNet: Multi- modal behavior prediction using trajectory set,
T. Phan-Minh, E. C. Grigore, F. A. Boulton,et al., “CoverNet: Multi- modal behavior prediction using trajectory set,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020, pp. 14074–14083
2020
-
[9]
TNT: Target-driven trajectory predic- tion,
H. Zhao, J. Gao, T. Lan,et al., “TNT: Target-driven trajectory predic- tion,” inProceedings of the Conference on Robot Learning, 2021, pp. 895–904
2021
-
[10]
DenseTNT: End-to-end trajectory prediction from dense goal sets,
J. Gu, C. Sun, and H. Zhao, “DenseTNT: End-to-end trajectory prediction from dense goal sets,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15303–15312
2021
-
[11]
MTR++: Multi-agent motion prediction with symmetric scene modeling and guided intention query- ing,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “MTR++: Multi-agent motion prediction with symmetric scene modeling and guided intention query- ing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3955–3971, 2024
2024
-
[12]
Neural discrete representation learning,
A. Van Den Oord and O. Vinyals, “Neural discrete representation learning,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[13]
Unitraj: A unified framework for scalable vehicle trajectory prediction,
L. Feng, M. Bahari, K. M. B. Amor,et al., “Unitraj: A unified framework for scalable vehicle trajectory prediction,” inProceedings of the European Conference on Computer Vision, 2024, pp. 106–123
2024
-
[14]
Argoverse 2: Next generation datasets for self-driving perception and forecasting,
B. Wilson, W. Qi, T. Agarwal,et al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,” inProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[15]
Latent variable sequential set transformers for joint multi-agent motion prediction,
R. Girgis, F. Golemo, F. Codevilla,et al., “Latent variable sequential set transformers for joint multi-agent motion prediction,” inProceedings of the International Conference on Learning Representations, 2022
2022
-
[16]
Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,
B. Varadarajan, A. Hefny, A. Srivastava,et al., “Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,” inProceedings of the International Conference on Robotics and Au- tomation, 2022, pp. 7814–7821
2022
-
[17]
Scene Transformer: A unified architecture for predicting future trajectories of multiple agents,
J. Ngiam, V . Vasudevan, B. Caine,et al., “Scene Transformer: A unified architecture for predicting future trajectories of multiple agents,” inProceedings of the International Conference on Learning Represen- tations, 2022
2022
-
[18]
Forecast-MAE: Self-supervised pre- training for motion forecasting with masked autoencoders,
J. Cheng, X. Mei, and M. Liu, “Forecast-MAE: Self-supervised pre- training for motion forecasting with masked autoencoders,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8679–8689
2023
-
[19]
Wayformer: Motion forecasting via simple & efficient attention networks,
N. Nayakanti, R. Al-Rfou, A. Zhou,et al., “Wayformer: Motion forecasting via simple & efficient attention networks,” inProceedings of the IEEE International Conference on Robotics and Automation, 2023, pp. 2980–2987
2023
-
[20]
Predicting long-term human behaviors in discrete representations via physics-guided diffusion,
Z. Zhang, A. Li, A. Lim, and M. Chen, “Predicting long-term human behaviors in discrete representations via physics-guided diffusion,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 11500–11507
2024
-
[21]
Trajectory forecasting through low-rank adaptation of discrete latent codes,
R. Benaglia, A. Porrello, P. Buzzega,et al., “Trajectory forecasting through low-rank adaptation of discrete latent codes,” inProceedings of the International Conference on Pattern Recognition, 2024, pp. 236– 251
2024
-
[22]
NSVQ: Noise substitution in vector quantization for machine learning,
M. H. Vali, and T. B ¨ackstr¨om, “NSVQ: Noise substitution in vector quantization for machine learning,”IEEE Access, vol. 10, pp. 13598– 13610, 2022
2022
-
[23]
Finite scalar quantization: VQ-V AE made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Finite scalar quantization: VQ-V AE made simple,” inProceedings of the International Conference on Learning Representations, 2024
2024
-
[24]
Implicit latent variable model for scene-consistent motion forecasting,
S. Casas, C. Gulino, S. Suo,et al., “Implicit latent variable model for scene-consistent motion forecasting,” inProceedings of the European Conference on Computer Vision, 2020, pp. 624–641
2020
-
[25]
PointNet: Deep learning on point sets for 3D classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 652–660
2017
-
[26]
Efficient motion prediction: A lightweight & accurate trajectory prediction model with fast training and inference speed,
A. Prutsch, H. Bischof, and H. Possegger, “Efficient motion prediction: A lightweight & accurate trajectory prediction model with fast training and inference speed,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 9411–9417
2024
-
[27]
CRITERIA: A new benchmarking paradigm for evaluating trajectory prediction models for autonomous driving,
C. Chen, M. Pourkeshavarz, and A. Rasouli, “CRITERIA: A new benchmarking paradigm for evaluating trajectory prediction models for autonomous driving,” inProceedings of the IEEE International Conference on Robotics and Automation, 2024, pp. 8265–8271
2024
-
[28]
Diverse and admissible trajectory forecasting through multimodal context understanding,
S. H. Park, G. Lee, J. Seo,et al., “Diverse and admissible trajectory forecasting through multimodal context understanding,” inProceedings of the European Conference on Computer Vision, 2020, pp. 282–298
2020
-
[29]
DLow: Diversifying latent flows for diverse human motion prediction,
Y . Yuan, and K. Kitani, “DLow: Diversifying latent flows for diverse human motion prediction,” inProceedings of the European Conference on Computer Vision, 2020, 346–364
2020
-
[30]
Likelihood- based diverse sampling for trajectory forecasting,
Y . J. Ma, J. P. Inala, D. Jayaraman, and O. Bastani, “Likelihood- based diverse sampling for trajectory forecasting,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13279–13288
2021
-
[31]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis,et al., “LoRA: Low-rank adaptation of large language models,” inProceedings of the International Conference on Learning Representations, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.