MATCH: Modulating Attention via In-Context Retrieval for Long-Context Transformers
Pith reviewed 2026-06-30 06:09 UTC · model grok-4.3
The pith
MATCH improves sparse attention performance on long-context tasks by dynamically retrieving and modulating in-context information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MATCH augments sparsified attention mechanisms with dynamically integrated in-context information through an efficient retrieval system, thereby improving the performance of sparse-attention models on tasks requiring long-range dependencies.
What carries the argument
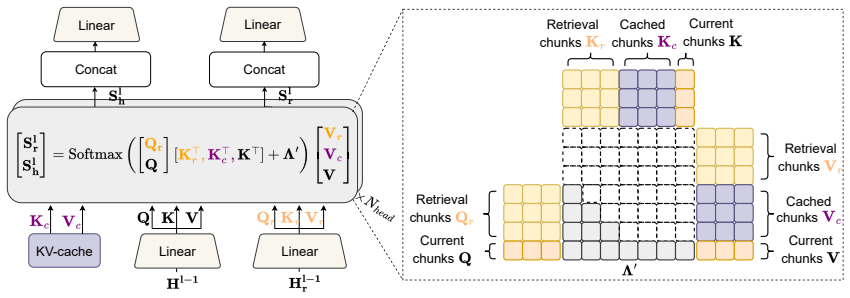
The MATCH framework, which modulates attention by retrieving and injecting relevant in-context information into a sparsified attention computation.
If this is right
- Sparse attention models recover accuracy on tasks that need distant context.
- The computational savings of sparse attention remain intact.
- MATCH works as a general add-on for multiple sparse attention designs.
- Gains appear on both controlled synthetic benchmarks and practical natural language problems.
Where Pith is reading between the lines
- The same retrieval modulation could be tested on other efficiency techniques such as linear or kernel attention.
- If retrieval cost stays low at extreme lengths, MATCH might support contexts far beyond current practical limits.
- Combining MATCH with external knowledge stores could extend its use from in-context to factual retrieval.
Load-bearing premise
An efficient retrieval system can be added to sparsified attention without new overhead or errors that cancel the claimed speed and accuracy benefits.
What would settle it
A direct measurement showing that the retrieval step adds more compute time than sparsity saves, or that accuracy on long-range recall tasks stays flat or drops, would disprove the central claim.
Figures


read the original abstract
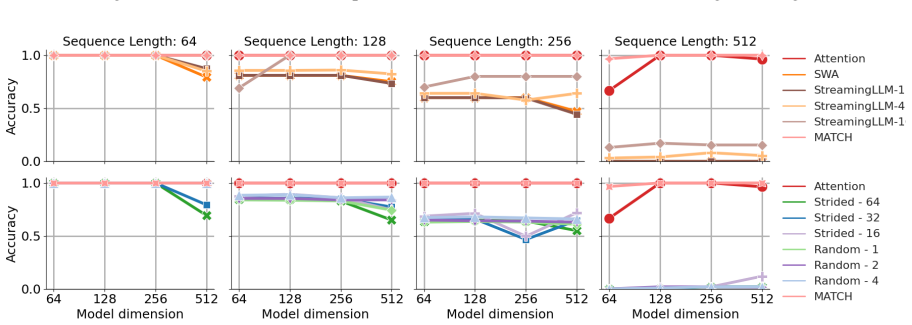
The quadratic computational cost of traditional attention mechanisms poses a major bottleneck to the scalability and practical deployment of large language models (LLMs), particularly in long-context scenarios. To improve efficiency, existing approaches often enforce rigid structural constraints such as local attention windows. However, these strategies typically lead to substantial performance degradation on tasks requiring precise long-range recall. In this work, we propose MATCH, a scalable and efficient framework that augments sparsified attention mechanisms with dynamically integrated in-context information through an efficient retrieval system. Empirical results show that MATCH significantly improves the performance of sparse-attention models on both synthetic and real-world natural-language tasks. These findings highlight the versatility of MATCH as a general approach for enhancing in-context retrieval capabilities while maintaining the efficiency benefits of sparse attention architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MATCH, a framework that augments sparsified attention mechanisms in long-context transformers with dynamically integrated in-context retrieval via an efficient retrieval system. It claims that this approach significantly improves performance of sparse-attention models on both synthetic and real-world natural-language tasks while preserving efficiency benefits.
Significance. If the empirical results hold with proper controls, MATCH would address a central tension in long-context modeling by improving recall without reintroducing quadratic costs, offering a general method for enhancing in-context capabilities in sparse architectures.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('MATCH significantly improves the performance of sparse-attention models') is asserted without any reported data, baselines, error bars, task definitions, dataset sizes, or implementation details on retrieval index construction, query cost, or attention modulation. This absence makes it impossible to evaluate whether the evidence supports the claim or whether hidden overheads offset the efficiency gains.
- [Abstract] Abstract (framework description): the claim of an 'efficient retrieval system' that is 'dynamically integrated' without prohibitive overhead or new failure modes is load-bearing for the efficiency-accuracy trade-off but is stated without any equations, pseudocode, complexity analysis, or ablation on retrieval latency versus attention savings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and propose revisions to strengthen the abstract while preserving its role as a concise summary.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('MATCH significantly improves the performance of sparse-attention models') is asserted without any reported data, baselines, error bars, task definitions, dataset sizes, or implementation details on retrieval index construction, query cost, or attention modulation. This absence makes it impossible to evaluate whether the evidence supports the claim or whether hidden overheads offset the efficiency gains.
Authors: We agree that the abstract, as a high-level summary, does not contain the quantitative details present in the full manuscript. The Experiments section reports specific performance gains (with baselines, error bars, task definitions, dataset sizes), and the Method section details retrieval index construction, query costs, and attention modulation. To address the concern, we will revise the abstract to incorporate representative empirical results and efficiency metrics. revision: yes
-
Referee: [Abstract] Abstract (framework description): the claim of an 'efficient retrieval system' that is 'dynamically integrated' without prohibitive overhead or new failure modes is load-bearing for the efficiency-accuracy trade-off but is stated without any equations, pseudocode, complexity analysis, or ablation on retrieval latency versus attention savings.
Authors: The full manuscript provides equations for attention modulation, pseudocode in the algorithm box, complexity analysis establishing linear scaling, and ablations comparing retrieval latency to attention savings in the Experiments and Analysis sections. We will revise the abstract to briefly reference these efficiency properties and analyses. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations
full rationale
The paper presents MATCH as an empirical framework that augments sparse attention with retrieval, validated on synthetic and real tasks. No equations, derivations, or load-bearing self-citations appear in the provided text. The central claim reduces to measured performance gains rather than any algebraic reduction to fitted inputs or prior self-citations. This is the expected non-finding for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
LM-Infinite: Zero-Shot Extreme Length Generalization for Large Language Models , booktitle =
Chi Han and Qifan Wang and Hao Peng and Wenhan Xiong and Yu Chen and Heng Ji and Sinong Wang , editor =. LM-Infinite: Zero-Shot Extreme Length Generalization for Large Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.NAACL-LONG.222 , timestamp =
-
[9]
Thirty-seventh Conference on Neural Information Processing Systems , year=
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Zoology: Measuring and Improving Recall in Efficient Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
The Twelfth International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
The Twelfth International Conference on Learning Representations,
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[14]
Random-Access Infinite Context Length for Transformers , booktitle =
Amirkeivan Mohtashami and Martin Jaggi , editor =. Random-Access Infinite Context Length for Transformers , booktitle =. 2023 , url =
2023
-
[15]
SparQ Attention: Bandwidth-Efficient
Luka Ribar and Ivan Chelombiev and Luke Hudlass. SparQ Attention: Bandwidth-Efficient. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[16]
Fast Attention Over Long Sequences With Dynamic Sparse Flash Attention , booktitle =
Matteo Pagliardini and Daniele Paliotta and Martin Jaggi and Fran. Fast Attention Over Long Sequences With Dynamic Sparse Flash Attention , booktitle =. 2023 , url =
2023
-
[17]
On the Expressive Flexibility of Self-Attention Matrices , booktitle =
Valerii Likhosherstov and Krzysztof Choromanski and Adrian Weller , editor =. On the Expressive Flexibility of Self-Attention Matrices , booktitle =. 2023 , url =. doi:10.1609/AAAI.V37I7.26055 , timestamp =
-
[18]
The Thirteenth International Conference on Learning Representations,
Xiangming Gu and Tianyu Pang and Chao Du and Qian Liu and Fengzhuo Zhang and Cunxiao Du and Ye Wang and Min Lin , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[19]
The Thirteenth International Conference on Learning Representations,
Hanlin Tang and Yang Lin and Jing Lin and Qingsen Han and Danning Ke and Shikuan Hong and Yiwu Yao and Gongyi Wang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[20]
Zhenyu Zhang and Ying Sheng and Tianyi Zhou and Tianlong Chen and Lianmin Zheng and Ruisi Cai and Zhao Song and Yuandong Tian and Christopher R. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[21]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =
Jingyang Yuan and Huazuo Gao and Damai Dai and Junyu Luo and Liang Zhao and Zhengyan Zhang and Zhenda Xie and Yuxing Wei and Lean Wang and Zhiping Xiao and Yuqing Wang and Chong Ruan and Ming Zhang and Wenfeng Liang and Wangding Zeng , editor =. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =. 2025 , url =
2025
-
[22]
MoBA: Mixture of Block Attention for Long-Context LLMs
Enzhe Lu and Zhejun Jiang and Jingyuan Liu and Yulun Du and Tao Jiang and Chao Hong and Shaowei Liu and Weiran He and Enming Yuan and Yuzhi Wang and Zhiqi Huang and Huan Yuan and Suting Xu and Xinran Xu and Guokun Lai and Yanru Chen and Huabin Zheng and Junjie Yan and Jianlin Su and Yuxin Wu and Neo Y. Zhang and Zhilin Yang and Xinyu Zhou and Mingxing Zha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13189 2025
-
[23]
Improving Language Models by Retrieving from Trillions of Tokens , booktitle =
Sebastian Borgeaud and Arthur Mensch and Jordan Hoffmann and Trevor Cai and Eliza Rutherford and Katie Millican and George van den Driessche and Jean. Improving Language Models by Retrieving from Trillions of Tokens , booktitle =. 2022 , url =
2022
-
[24]
Parallel distributed processing, 9th Edition , author =
-
[25]
Neural Computation 9, 1735–1780
Long Short-Term Memory , author =. Neural Comput. , volume = 9, number = 8, pages =. doi:10.1162/NECO.1997.9.8.1735 , url =
-
[26]
Learning Phrase Representations using
Kyunghyun Cho and Bart van Merrienboer and. Learning Phrase Representations using. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,. doi:10.3115/V1/D14-1179 , url =
-
[27]
3rd International Conference on Learning Representations,
Neural Machine Translation by Jointly Learning to Align and Translate , author =. 3rd International Conference on Learning Representations,
-
[28]
Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
Attention is All you Need , author =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[29]
Mandar Joshi and Eunsol Choi and Daniel S. Weld and Luke Zettlemoyer , year = 2017, booktitle =. TriviaQA:. doi:10.18653/V1/P17-1147 , url =
-
[31]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,
Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,. doi:10.18653/V1/P18-1027 , url =
-
[33]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author =. 2001.08361 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[34]
Patrick S. H. Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , url =
2020
-
[35]
Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , url =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , url =
2020
-
[36]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
How Much Knowledge Can You Pack Into the Parameters of a Language Model? , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,. doi:10.18653/V1/2020.EMNLP-MAIN.437 , url =
-
[37]
Proceedings of the 37th International Conference on Machine Learning,
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , author =. Proceedings of the 37th International Conference on Machine Learning,
-
[38]
In-context Learning and Induction Heads
In-context Learning and Induction Heads , author =. 2209.11895 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , url =
2022
-
[40]
The Tenth International Conference on Learning Representations,
Efficiently Modeling Long Sequences with Structured State Spaces , author =. The Tenth International Conference on Learning Representations,
-
[41]
The Tenth International Conference on Learning Representations,
Finetuned Language Models are Zero-Shot Learners , author =. The Tenth International Conference on Learning Representations,
-
[43]
2025 , eprint=
Do Robot Snakes Dream like Electric Sheep? Investigating the Effects of Architectural Inductive Biases on Hallucination , author=. 2025 , eprint=
2025
-
[44]
Findings of the Association for Computational Linguistics:
Evaluating Verifiability in Generative Search Engines , author =. Findings of the Association for Computational Linguistics:. doi:10.18653/V1/2023.FINDINGS-EMNLP.467 , url =
-
[45]
International Conference on Machine Learning,
Large Language Models Struggle to Learn Long-Tail Knowledge , author =. International Conference on Machine Learning,
-
[46]
International Conference on Machine Learning,
Large Language Models Can Be Easily Distracted by Irrelevant Context , author =. International Conference on Machine Learning,
-
[47]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
Enabling Large Language Models to Generate Text with Citations , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. doi:10.18653/V1/2023.EMNLP-MAIN.398 , url =
-
[48]
In: Rogers, A., Boyd- Graber, J., Okazaki, N
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. doi:10.18653/V1/2023.ACL-LONG.546 , url =
-
[49]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah I Abdin and Sam Ade Jacobs and Ammar Ahmad Awan and Jyoti Aneja and Ahmed Awadallah and Hany Awadalla and Nguyen Bach and Amit Bahree and Arash Bakhtiari and Harkirat S. Behl and Alon Benhaim and Misha Bilenko and Johan Bjorck and S. Phi-3 Technical Report:. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.14219 , eprinttype =. 2404.14219 , ti...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.14219 2024
-
[50]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author =. 2408.00118 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Qwen2.5 Technical Report , author =. 2412.15115 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Yi: Open Foundation Models by 01.AI
Yi: Open Foundation Models by 01.AI , author =. 2403.04652 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A Hybrid Transformer-Mamba Language Model , author =. 2403.19887 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism , author =. 2401.02954 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Mixtral of Experts , author =. 2401.04088 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Journal on Machine Learning Research , volume = 25, pages =
Scaling Instruction-Finetuned Language Models , author =. Journal on Machine Learning Research , volume = 25, pages =
-
[58]
First Conference on Language Modeling,
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. First Conference on Language Modeling,
-
[59]
Forty-first International Conference on Machine Learning,
Repeat After Me: Transformers are Better than State Space Models at Copying , author =. Forty-first International Conference on Machine Learning,
-
[60]
Forty-first International Conference on Machine Learning,
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality , author =. Forty-first International Conference on Machine Learning,
-
[61]
Can Mamba Learn How To Learn?
Jongho Park and Jaeseung Park and Zheyang Xiong and Nayoung Lee and Jaewoong Cho and Samet Oymak and Kangwook Lee and Dimitris Papailiopoulos , year = 2024, booktitle =. Can Mamba Learn How To Learn?
2024
-
[62]
Forty-first International Conference on Machine Learning,
Gated Linear Attention Transformers with Hardware-Efficient Training , author =. Forty-first International Conference on Machine Learning,
-
[63]
Forty-first International Conference on Machine Learning,
Mechanistic Design and Scaling of Hybrid Architectures , author =. Forty-first International Conference on Machine Learning,
-
[64]
Forty-first International Conference on Machine Learning,
In-Context Language Learning: Architectures and Algorithms , author =. Forty-first International Conference on Machine Learning,
-
[65]
The Twelfth International Conference on Learning Representations,
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author =. The Twelfth International Conference on Learning Representations,
-
[66]
The Twelfth International Conference on Learning Representations,
Zoology: Measuring and Improving Recall in Efficient Language Models , author =. The Twelfth International Conference on Learning Representations,
-
[67]
The Twelfth International Conference on Learning Representations,
Xi Victoria Lin and Xilun Chen and Mingda Chen and Weijia Shi and Maria Lomeli and Richard James and Pedro Rodriguez and Jacob Kahn and Gergely Szilvasy and Mike Lewis and Luke Zettlemoyer and Wen. The Twelfth International Conference on Learning Representations,
-
[68]
The Twelfth International Conference on Learning Representations,
Making Retrieval-Augmented Language Models Robust to Irrelevant Context , author =. The Twelfth International Conference on Learning Representations,
-
[69]
Fangyuan Xu and Weijia Shi and Eunsol Choi , year = 2024, booktitle =
2024
-
[70]
International Conference on Computational Linguistics,
How Well Can a Long Sequence Model Model Long Sequences? Comparing Architechtural Inductive Biases on Long-Context Abilities , author =. International Conference on Computational Linguistics,
-
[71]
The Thirteenth International Conference on Learning Representations , year=
Hymba: A Hybrid-head Architecture for Small Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[72]
Proceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization@ACL 2005, Ann Arbor, Michigan, USA, June 29, 2005 , pages =
Satanjeev Banerjee and Alon Lavie , editor =. Proceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization@ACL 2005, Ann Arbor, Michigan, USA, June 29, 2005 , pages =. 2005 , url =
2005
-
[73]
Luca Zancato and Arjun Seshadri and Yonatan Dukler and Aditya Golatkar and Yantao Shen and Benjamin Bowman and Matthew Trager and Alessandro Achille and Stefano Soatto , booktitle =. B'. 2024 , url=
2024
-
[74]
Gated Slot Attention for Efficient Linear-Time Sequence Modeling , author=. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, December 10-15, 2024, Vancouver, BC, Canada , year=
2024
-
[75]
L ong B ench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai and Xin Lv and Jiajie Zhang and Hongchang Lyu and Jiankai Tang and Zhidian Huang and Zhengxiao Du and Xiao Liu and Aohan Zeng and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , editor =. LongBench:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V...
-
[76]
FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism , author =
-
[77]
Efficient Classification of Long Documents via State-Space Models , booktitle =
Peng Lu and Suyuchen Wang and Mehdi Rezagholizadeh and Bang Liu and Ivan Kobyzev , editor =. Efficient Classification of Long Documents via State-Space Models , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.404 , timestamp =
-
[78]
ReGLA: Refining Gated Linear Attention , booktitle =
Peng Lu and Ivan Kobyzev and Mehdi Rezagholizadeh and Boxing Chen and Philippe Langlais , editor =. ReGLA: Refining Gated Linear Attention , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.147 , timestamp =
-
[79]
Accelerating Prefilling via Decoding-time Contribution Sparsity
TriangleMix: A Lossless and Efficient Attention Pattern for Long Context Prefilling , author=. arXiv preprint arXiv:2507.21526 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
-
[81]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[82]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2302.13971 , eprinttype =. 2302.13971 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[83]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al. The Llama 3 Herd of Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[84]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.