Formal Verification of Learned Multi-Agent Communication Policies via Decision Tree Distillation
Pith reviewed 2026-06-26 20:21 UTC · model grok-4.3
The pith
Neural multi-agent policies can be distilled into decision trees for formal verification, with safety properties transferring back to the originals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
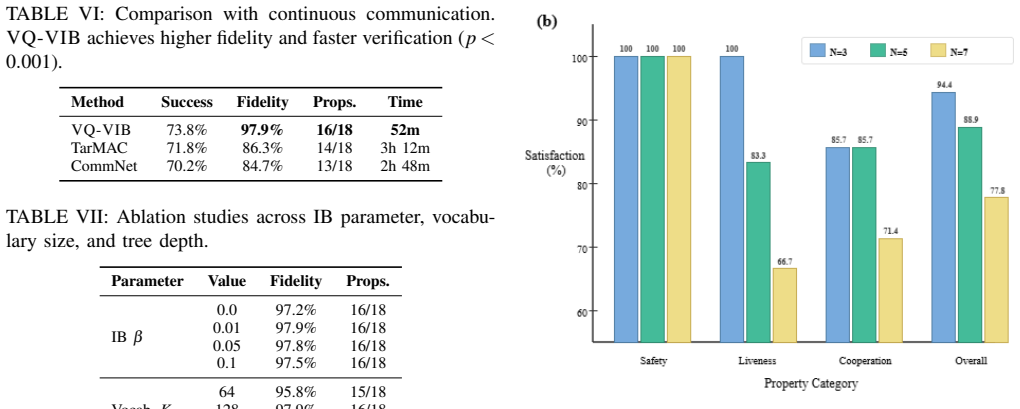
Distilling neural multi-agent communication policies into decision trees allows automated translation to PRISM and compositional verification of PCTL properties including safety thresholds; Monte Carlo runs confirm these properties transfer to the original networks with at most 0.6 percentage-point deviation, while discrete message encodings yield higher fidelity and faster verification than continuous ones.
What carries the argument
The four-stage pipeline of domain-specific feature extraction from observations, decision tree distillation, complete feature-to-state translation into PRISM, and compositional PCTL verification via pairwise decomposition with union-bound aggregation.
If this is right
- All five safety thresholds are met, including collision probability at 0.3 percent against a 1 percent limit.
- 18 temporal logic properties across safety, liveness, and cooperation are verified for 5-7 agent cases.
- Discrete VQ-VIB messages deliver 11.6 to 13.6 percentage-point fidelity gains and enable 3-4 times faster verification.
- Verified properties transfer to the original networks with at most 0.6 percentage-point deviation at 95 percent .
Where Pith is reading between the lines
- The same distillation-plus-verification steps could apply to other multi-agent robotic settings such as vehicle fleets.
- Formal bounds relating fidelity percentage to property preservation would strengthen the empirical transfer result.
- Pairwise compositional verification may extend to larger agent groups if the union-bound aggregation remains tight.
- The framework reduces reliance on exhaustive simulation by providing a certified abstraction layer.
Load-bearing premise
That 97.9 percent decision-tree fidelity is high enough to ensure all verified PCTL properties hold for the original neural policy.
What would settle it
A Monte Carlo simulation run on the original neural policy that violates a verified safety threshold while the corresponding decision tree satisfies it in PRISM.
Figures

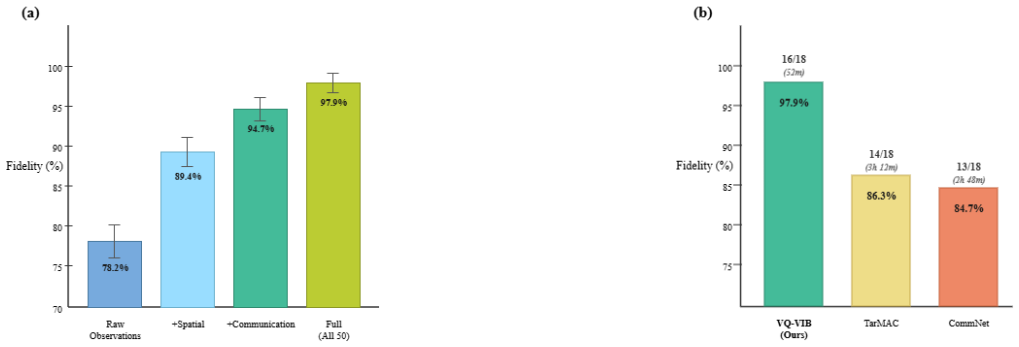
read the original abstract
Multi-agent reinforcement learning (MARL) enables agents to develop coordination strategies through emergent communication, but neural policies lack the formal safety guarantees required for safety-critical robotic deployment in drone swarms and autonomous vehicle fleets. We present the first end-to-end framework for safety verification of learned multi-agent communication policies through policy abstraction: neural policies are distilled into interpretable decision trees, then formally verified, with empirical validation confirming that verified safety properties transfer to original networks. Our four-stage pipeline consists of domain-specific feature extraction from agent observations, decision tree distillation achieving 97.9% +/- 1.2% fidelity to neural policies, automated translation to PRISM probabilistic model checker specifications with complete feature-to-state-variable correspondence, and compositional verification of Probabilistic Computation Tree Logic (PCTL) properties via pairwise decomposition with union-bound aggregation and empirical neighbor modeling. Evaluating Vector-Quantized Variational Information Bottleneck (VQ-VIB) policies for multi-drone coordination with 5-7 agents, we verify 18 temporal logic properties across safety, liveness, and cooperation, achieving 88.9% property satisfaction with all five safety thresholds satisfied (0.3% collision probability vs. 1% threshold). Monte Carlo validation of original neural policies confirms that verified safety properties transfer with <=0.6 percentage-point deviation (95% CI). Discrete VQ-VIB messages provide +11.6 to +13.6 percentage-point fidelity advantages over continuous methods, enabling 3-4x faster verification. Our framework provides empirically validated safety verification for distilled policy abstractions, serving as a practical bridge between deep MARL and formal safety workflows for multi-robot deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a four-stage end-to-end framework for safety verification of learned multi-agent communication policies in MARL: domain-specific feature extraction, decision-tree distillation of VQ-VIB neural policies (97.9% +/- 1.2% fidelity), automated translation to PRISM with feature-to-state mapping, and compositional PCTL verification via pairwise decomposition and union-bound aggregation. On 5-7 agent multi-drone coordination, 18 temporal logic properties (safety, liveness, cooperation) are verified with 88.9% satisfaction rate; all five safety thresholds are met (e.g., 0.3% collision prob vs. 1% threshold), and Monte Carlo checks on the original networks confirm transfer with <=0.6 pp deviation (95% CI). Discrete VQ-VIB messages yield fidelity and speed advantages over continuous baselines.
Significance. If the reported empirical transfer holds under the stated conditions, the framework supplies a concrete, practical bridge between deep MARL and formal verification tools for safety-critical multi-robot systems. The concrete metrics (fidelity, property satisfaction rates, transfer deviation), the use of an off-the-shelf model checker (PRISM), and the reported 3-4x verification speedup from discrete messages are strengths that could be directly usable by practitioners. The work also supplies falsifiable predictions via the Monte Carlo transfer checks.
major comments (2)
- [Evaluation / Results] Evaluation section: Monte Carlo validation of property transfer (reported as <=0.6 pp deviation) is described only for the five safety properties; no corresponding validation is reported for the liveness or cooperation properties among the 18 verified PCTL formulas. This is load-bearing for the central claim that 'verified safety properties transfer to original networks' when the framework is presented as covering all 18 properties.
- [Verification Pipeline] Verification pipeline (PRISM translation and compositional verification): the 97.9% +/- 1.2% per-step action fidelity is used to justify the DT abstraction, yet no simulation relation, Lipschitz bound, or propagation analysis is supplied showing how local action mismatches affect path probabilities in PCTL formulas (e.g., collision probability <=0.01) under the multi-agent transition structure and union-bound aggregation. The 0.3 pp empirical margin to the 1% threshold therefore lacks a proven robustness margin.
minor comments (2)
- [Abstract] Abstract: the phrase '88.9% property satisfaction' should be accompanied by the exact count (18) and a breakdown by category to avoid ambiguity.
- [Pipeline Description] The description of 'complete feature-to-state-variable correspondence' in the PRISM translation would benefit from an explicit statement of how continuous observation components are mapped or discretized.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below, agreeing that clarifications and additional discussion are warranted to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section: Monte Carlo validation of property transfer (reported as <=0.6 pp deviation) is described only for the five safety properties; no corresponding validation is reported for the liveness or cooperation properties among the 18 verified PCTL formulas. This is load-bearing for the central claim that 'verified safety properties transfer to original networks' when the framework is presented as covering all 18 properties.
Authors: We agree that the scope of the transfer claim requires clearer delineation. The manuscript's abstract and evaluation section explicitly limit the Monte Carlo transfer result to 'verified safety properties' because these are the properties with explicit numerical thresholds and direct relevance to safety-critical deployment. The 18 properties include liveness and cooperation, which were verified on the decision-tree abstraction but not subjected to the same transfer check. To address the concern, we will revise the text in Section 5 and the abstract to emphasize the scoped claim, and we will add Monte Carlo transfer results for two representative liveness properties (using the same 95% CI protocol) in the revised manuscript. revision: yes
-
Referee: [Verification Pipeline] Verification pipeline (PRISM translation and compositional verification): the 97.9% +/- 1.2% per-step action fidelity is used to justify the DT abstraction, yet no simulation relation, Lipschitz bound, or propagation analysis is supplied showing how local action mismatches affect path probabilities in PCTL formulas (e.g., collision probability <=0.01) under the multi-agent transition structure and union-bound aggregation. The 0.3 pp empirical margin to the 1% threshold therefore lacks a proven robustness margin.
Authors: This observation correctly identifies a theoretical gap. The current framework is empirical: it relies on the measured per-step fidelity together with direct Monte Carlo sampling on the original networks to demonstrate that the observed deviation remains small (<=0.6 pp) for the safety properties under test. No simulation relation or analytic propagation bound is provided, and developing one would require substantial additional theoretical machinery beyond the scope of this work. We will add an explicit limitations paragraph in the discussion section acknowledging the absence of such a bound and noting that the empirical margin supplies practical (but not formally proven) evidence under the evaluated conditions. revision: yes
Circularity Check
No circularity; verification pipeline uses independent model checking and empirical transfer checks
full rationale
The paper describes a four-stage empirical pipeline: feature extraction, DT distillation (with separate fidelity measurement), PRISM translation and compositional PCTL verification on the DT, followed by Monte Carlo validation on the original VQ-VIB networks. No equations or claims reduce the verified safety properties or transfer results to quantities fitted from the same data by construction; the 97.9% fidelity and <=0.6pp deviation are reported as measured outcomes rather than definitional. The framework does not invoke self-citations for load-bearing uniqueness theorems or smuggle ansatzes, and the central claims rest on external model checking and simulation rather than self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,”Advances in neural information processing systems, vol. 35, pp. 24611–24624, 2022
2022
-
[2]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[3]
Reluplex: An efficient smt solver for verifying deep neural networks,
G. Katz, C. Barrett, D. L. Dill, K. Julian, and M. J. Kochenderfer, “Reluplex: An efficient smt solver for verifying deep neural networks,” inInternational conference on computer aided verification, pp. 97– 117, Springer, 2017
2017
-
[4]
Learning safe control for multi-robot systems: Methods, verification, and open challenges,
K. Garg, S. Zhang, O. So, C. Dawson, and C. Fan, “Learning safe control for multi-robot systems: Methods, verification, and open challenges,”Annual Reviews in Control, vol. 57, p. 100948, 2024
2024
-
[5]
Verifiable reinforcement learning via policy extraction,
O. Bastani, Y . Pu, and A. Solar-Lezama, “Verifiable reinforcement learning via policy extraction,”Advances in neural information pro- cessing systems, vol. 31, 2018
2018
-
[6]
Maviper: Learning decision tree policies for interpretable multi-agent reinforcement learning,
S. Milani, Z. Zhang, N. Topin, Z. R. Shi, C. Kamhoua, E. E. Papalexakis, and F. Fang, “Maviper: Learning decision tree policies for interpretable multi-agent reinforcement learning,” inJoint Euro- pean conference on machine learning and knowledge discovery in databases, pp. 251–266, Springer, 2022
2022
-
[7]
Cool-mc: a comprehensive tool for reinforcement learning and model checking,
D. Gross, N. Jansen, S. Junges, and G. A. P ´erez, “Cool-mc: a comprehensive tool for reinforcement learning and model checking,” inInternational Symposium on Dependable Software Engineering: Theories, Tools, and Applications, pp. 41–49, Springer, 2022
2022
-
[8]
Safety-oriented pruning and interpretation of reinforcement learning policies,
D. Gross and H. Spieker, “Safety-oriented pruning and interpretation of reinforcement learning policies,”arXiv preprint arXiv:2409.10218, 2024
arXiv 2024
-
[9]
An abstract domain for certifying neural networks,
G. Singh, T. Gehr, M. P ¨uschel, and M. Vechev, “An abstract domain for certifying neural networks,”Proceedings of the ACM on Programming Languages, vol. 3, no. POPL, pp. 1–30, 2019
2019
-
[10]
Toward interpretable deep reinforcement learning with linear model u-trees,
G. Liu, O. Schulte, W. Zhu, and Q. Li, “Toward interpretable deep reinforcement learning with linear model u-trees,” inJoint Euro- pean Conference on Machine Learning and Knowledge Discovery in Databases, pp. 414–429, Springer, 2018
2018
-
[11]
Model-checkingω- regular properties of interval markov chains,
K. Chatterjee, K. Sen, and T. A. Henzinger, “Model-checkingω- regular properties of interval markov chains,” inInternational Confer- ence on Foundations of Software Science and Computational Struc- tures, pp. 302–317, Springer, 2008
2008
-
[12]
Safe reinforcement learning via shielding,
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, and U. Topcu, “Safe reinforcement learning via shielding,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[13]
Cautious reinforcement learning with logical constraints,
M. Hasanbeig, A. Abate, and D. Kroening, “Cautious reinforcement learning with logical constraints,”arXiv preprint arXiv:2002.12156, 2020
arXiv 2002
-
[14]
Safe reinforcement learning via formal methods: Toward safe control through proof and learning,
N. Fulton and A. Platzer, “Safe reinforcement learning via formal methods: Toward safe control through proof and learning,” inPro- ceedings of the AAAI Conference on Artificial Intelligence, vol. 32, 2018
2018
-
[15]
Compositional model checking,
E. M. Clarke, D. E. Long, and K. L. McMillan, “Compositional model checking,” 1989
1989
-
[16]
Assume- guarantee verification for probabilistic systems,
M. Kwiatkowska, G. Norman, D. Parker, and H. Qu, “Assume- guarantee verification for probabilistic systems,” inInternational Con- ference on Tools and Algorithms for the Construction and Analysis of Systems, pp. 23–37, Springer, 2010
2010
-
[17]
Prism-games: A model checker for stochastic multi-player games,
T. Chen, V . Forejt, M. Kwiatkowska, D. Parker, and A. Simaitis, “Prism-games: A model checker for stochastic multi-player games,” inInternational Conference on TOOLS and Algorithms for the Con- struction and Analysis of Systems, pp. 185–191, Springer, 2013
2013
-
[18]
Mcmas: an open-source model checker for the verification of multi-agent systems,
A. Lomuscio, H. Qu, and F. Raimondi, “Mcmas: an open-source model checker for the verification of multi-agent systems,”International Journal on Software Tools for Technology Transfer, vol. 19, no. 1, pp. 9–30, 2017
2017
-
[19]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Fergus,et al., “Learning multiagent communication with backpropagation,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[20]
Tarmac: Targeted multi-agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” inInterna- tional Conference on machine learning, pp. 1538–1546, PMLR, 2019
2019
-
[21]
A. Farooq and K. Iqbal, “Bandwidth-efficient multi-agent communi- cation through information bottleneck and vector quantization,”arXiv preprint arXiv:2602.02035, 2026
arXiv 2026
-
[22]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyals,et al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[23]
The information bottleneck method,
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”arXiv preprint physics/0004057, 2000
Pith/arXiv arXiv 2000
-
[24]
F. A. Oliehoek, C. Amato,et al.,A concise introduction to decentral- ized POMDPs, vol. 1. Springer, 2016
2016
-
[25]
Graph attention networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y . Bengio, et al., “Graph attention networks,” inInternational conference on learning representations, vol. 6, p. 2, Ithaca, 2018
2018
-
[26]
Classification and regression trees (crc, boca raton, fl),
L. Breiman, J. Friedman, C. Stone, and R. Olshen, “Classification and regression trees (crc, boca raton, fl),” 1984
1984
-
[27]
Prism 4.0: Verification of probabilistic real-time systems,
M. Kwiatkowska, G. Norman, and D. Parker, “Prism 4.0: Verification of probabilistic real-time systems,” inInternational conference on computer aided verification, pp. 585–591, Springer, 2011
2011
-
[28]
A logic for reasoning about time and reliability,
H. Hansson and B. Jonsson, “A logic for reasoning about time and reliability,”Formal aspects of computing, vol. 6, no. 5, pp. 512–535, 1994
1994
-
[29]
U. S. F. A. Administration,Pilots’ Role in Collision Avoidance. No. 48, US Department of Transportation, Federal Aviation Adminis- tration, 1983
1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.