VAMPS: Visual-Assisted Mathematical Problem Solving Benchmark
Pith reviewed 2026-06-28 09:36 UTC · model grok-4.3
The pith
Direct analytical solving outperforms tool-enabled visual solving on graph-assisted math problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
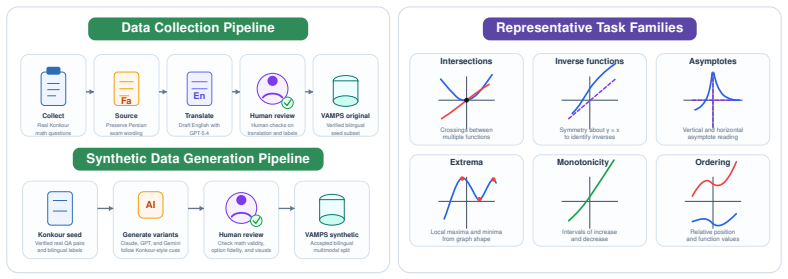
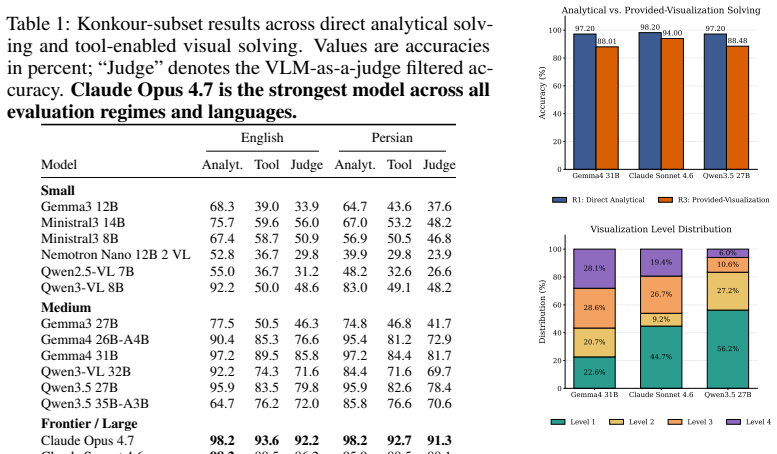
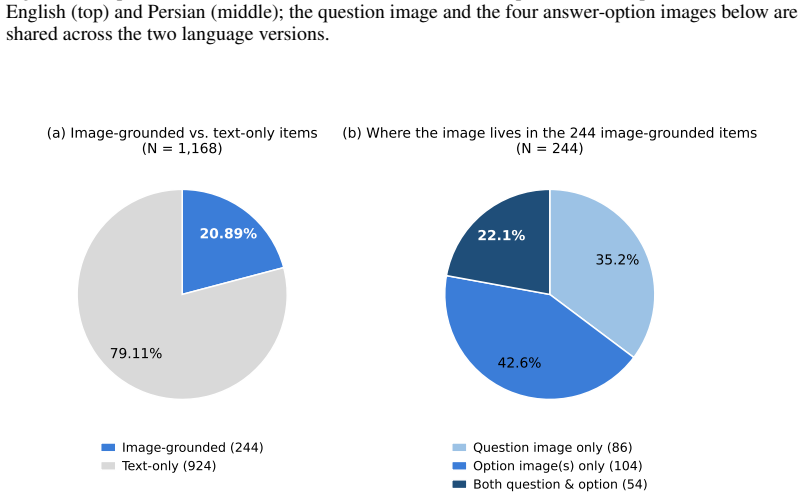
VAMPS is a benchmark for graph-assisted mathematics containing 1,168 bilingual multiple-choice questions where plotting provides a natural solution strategy. The central claim is that direct analytical solving outperforms tool-enabled visual solving across a diverse set of models, even on these plot-friendly problems.
What carries the argument
VAMPS benchmark, which compares direct analytical solving against tool-enabled construction and interpretation of graphs on problems selected for natural visual strategies.
Load-bearing premise
The problems and synthetic variants were selected such that plotting genuinely provides a natural and unbiased solution strategy without introducing artifacts that favor analytical over visual paths.
What would settle it
Finding any model or configuration where tool-enabled visual solving produces higher accuracy than direct analytical solving on the VAMPS questions would falsify the central result.
Figures













read the original abstract
Multimodal large language models are increasingly capable of complex reasoning, yet their performance often degrades when they must externalize a problem through a tool and then reason over the tool's output, specifically when they rely on visual aids. This gap is especially important because real engineering and scientific workflows often rely on visualization tools for analysis, validation, and decision-making. To study this discrepancy, we introduce VAMPS (Visual-Assisted Mathematical Problem Solving), a benchmark for graph-assisted mathematics. VAMPS contains 1,168 multimodal, bilingual multiple-choice question-answer pairs drawn from Iranian University Entrance Exam algebra and calculus problems and expanded with human-reviewed LLM-generated synthetic variants, all selected so that plotting provides a natural solution strategy by revealing intersections, extrema, asymptotes, etc. Designed for both benchmarking and diagnosis, VAMPS goes beyond prior multimodal benchmarks that primarily evaluate reasoning over fixed visual inputs by testing whether a model can benefit from constructing a useful graph and grounding its answer in the resulting visualization. Overall, we found that across a diverse set of models, direct analytical solving surprisingly outperforms tool-enabled visual solving, even on problems where plotting is a natural strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the VAMPS benchmark consisting of 1,168 multimodal bilingual multiple-choice questions drawn from Iranian University Entrance Exam algebra and calculus problems and expanded via human-reviewed LLM-generated synthetic variants. All items are selected so that plotting reveals intersections, extrema, or asymptotes as a natural solution strategy. The central empirical claim is that, across diverse models, direct analytical solving outperforms tool-enabled visual solving even on these problems.
Significance. If the result is robust to benchmark-construction artifacts, it would demonstrate a clear and practically relevant limitation in current MLLMs' ability to externalize reasoning through visualization tools, with direct implications for scientific workflows. The benchmark itself supplies a diagnostic resource beyond static-image multimodal tests. The paper supplies no machine-checked proofs or parameter-free derivations; its value is therefore entirely empirical and hinges on the validity of the problem-selection protocol.
major comments (2)
- [Benchmark construction / data collection] The headline result (analytical > tool-enabled visual) is load-bearing on the claim that every problem was chosen or constructed so that plotting is a genuinely natural, unbiased strategy. The manuscript describes human review of LLM-generated synthetic variants but provides no quantitative check (e.g., comparison of algebraic vs. visual solution difficulty, coefficient statistics, or inter-annotator agreement on visual utility) that would rule out systematic artifacts favoring clean algebraic solutions over noisy or ambiguous plots. This directly affects interpretability of the performance gap.
- [Experimental setup and results] The experimental results cannot be reproduced or assessed for statistical significance because the manuscript supplies no details on model prompting for tool use, the graph-generation method and parameters, the exact scoring protocol for multiple-choice answers, data splits, or any hypothesis tests on the reported performance differences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve transparency and reproducibility.
read point-by-point responses
-
Referee: The headline result (analytical > tool-enabled visual) is load-bearing on the claim that every problem was chosen or constructed so that plotting is a genuinely natural, unbiased strategy. The manuscript describes human review of LLM-generated synthetic variants but provides no quantitative check (e.g., comparison of algebraic vs. visual solution difficulty, coefficient statistics, or inter-annotator agreement on visual utility) that would rule out systematic artifacts favoring clean algebraic solutions over noisy or ambiguous plots. This directly affects interpretability of the performance gap.
Authors: Problems were drawn from Iranian University Entrance Exams where plotting intersections, extrema, and asymptotes is a standard, curriculum-endorsed strategy; synthetic variants underwent expert human review specifically to confirm that visual features remain unambiguous and solution-relevant. We agree that quantitative validation would further strengthen claims. The revision will add a dedicated subsection reporting inter-annotator agreement on visual utility (Cohen's kappa) and summary statistics comparing algebraic versus visual solution characteristics. revision: yes
-
Referee: The experimental results cannot be reproduced or assessed for statistical significance because the manuscript supplies no details on model prompting for tool use, the graph-generation method and parameters, the exact scoring protocol for multiple-choice answers, data splits, or any hypothesis tests on the reported performance differences.
Authors: We acknowledge the omission of implementation details. The revised manuscript will include full prompting templates for both analytical and tool-enabled conditions, graph-generation parameters (library, resolution, axis scaling), the exact multiple-choice scoring rule, any train/test splits, and statistical tests (e.g., McNemar's test) with p-values for reported differences. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces an empirical benchmark (VAMPS) consisting of exam problems and human-reviewed synthetic variants, then reports model performance comparisons between analytical and tool-enabled visual solving. No equations, parameters, or derivations are present; the central claim is a direct empirical observation across tested models. Problem selection and variant generation are described as external processes (Iranian exams + LLM synthesis with human review) without any self-referential fitting or prediction that reduces to the inputs by construction. No self-citation chains support load-bearing uniqueness claims or ansatzes. The work is self-contained as a measurement study and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plotting reveals intersections, extrema, and asymptotes that directly aid solution of the chosen algebra and calculus problems.
Reference graph
Works this paper leans on
-
[1]
Ai achieves silver-medal standard solving international mathematical olympiad problems
AlphaProof and AlphaGeometry Teams. Ai achieves silver-medal standard solving international mathematical olympiad problems. Google DeepMind blog, 2024. URL https://deepmind. google/blog/ai-solves-imo-problems-at-silver-medal-level/
2024
-
[2]
Introducing claude opus 4.7
Anthropic. Introducing claude opus 4.7. https://www.anthropic.com/news/ claude-opus-4-7, 2026. Accessed 2026-05-04
2026
-
[3]
Introducing Claude Sonnet 4.6
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, February 2026. Accessed: 2026-04-20
2026
-
[4]
Qwen3-VL technical report
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[5]
Qwen2.5-VL technical report
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report. F...
2025
-
[6]
Scientific workflow: A survey and research directions
Adam Barker and Jano van Hemert. Scientific workflow: A survey and research directions. In Roman Wyrzykowski, Jack Dongarra, Konrad Karczewski, and Jerzy Wasniewski, editors,Par- allel Processing and Applied Mathematics, pages 746–753, Berlin, Heidelberg, 2008. Springer Berlin Heidelberg. ISBN 978-3-540-68111-3
2008
-
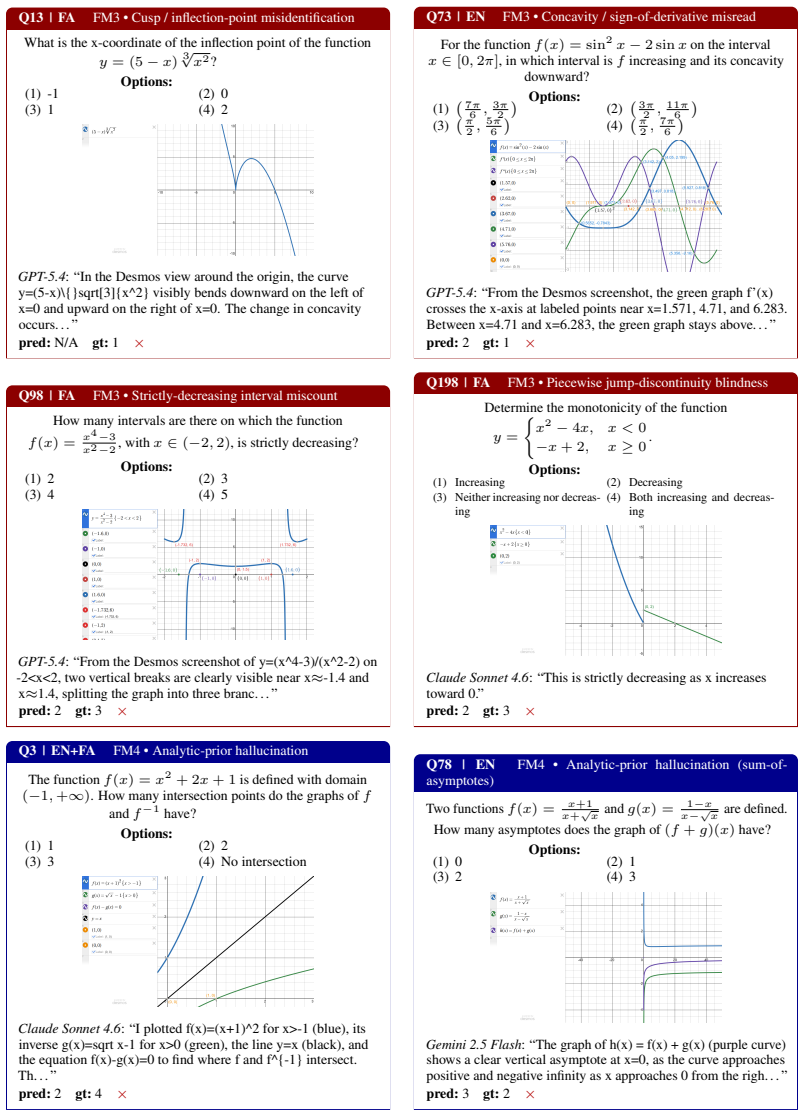
[7]
Callahan, Juliana Freire, Emanuele Santos, Carlos E
Steven P. Callahan, Juliana Freire, Emanuele Santos, Carlos E. Scheidegger, Cláudio T. Silva, and Huy T. V o. Vistrails: visualization meets data management. InProceedings of the 2006 ACM SIGMOD International Conference on Management of Data, SIGMOD ’06, page 745–747, New York, NY , USA, 2006. Association for Computing Machinery. ISBN 1595934340. doi: 10....
-
[8]
GeoQA: A geometric question answering benchmark towards multimodal numerical reasoning
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric Xing, and Liang Lin. GeoQA: A geometric question answering benchmark towards multimodal numerical reasoning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 513–523, Online, August
2021
-
[9]
doi: 10.18653/v1/2021.findings-acl.46
Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-acl.46. URL https://aclanthology.org/2021.findings-acl.46/
-
[10]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. UniGeo: Unifying geometry logical reasoning via reformulating mathematical expression. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3313–3323, Abu Dhabi, United A...
-
[11]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompt- ing: Disentangling computation from reasoning for numerical reasoning tasks.Transactions on Machine Learning Research, 2023
2023
-
[12]
Desmos Graphing Calculator
Desmos Studio. Desmos Graphing Calculator. https://www.desmos.com/calculator, n.d. Accessed: 2026-05-04
2026
-
[13]
Gerard, and Marcia C
Dermot Francis Donnelly-Hermosillo, Libby F. Gerard, and Marcia C. Linn. Impact of graph technologies in k-12 science and mathematics education.Computers & Education, 146:103748,
-
[14]
doi: https://doi.org/10.1016/j.compedu.2019.103748
ISSN 0360-1315. doi: https://doi.org/10.1016/j.compedu.2019.103748. URL https: //www.sciencedirect.com/science/article/pii/S036013151930301X
-
[15]
We’re expanding our gemini 2.5 family of models
Tulsee Doshi. We’re expanding our gemini 2.5 family of models. https://blog.google/products-and-platforms/products/gemini/ gemini-2-5-model-family-expands/ , 2025. Google blog post, accessed 2026-05- 04
2025
-
[16]
Gemma 4: Byte for byte, the most capable open mod- els
Clement Farabet and Olivier Lacombe. Gemma 4: Byte for byte, the most capable open mod- els. https://blog.google/innovation-and-ai/technology/developers-tools/ gemma-4/, 2026. Google DeepMind blog post, accessed 2026-05-04
2026
-
[17]
Refocus: Visual editing as a chain of thought for structured image understanding
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Richard Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=a7qFlPOTix
2025
-
[19]
URLhttps://arxiv.org/abs/2211.10435
-
[20]
Google DeepMind. Gemma 3. https://deepmind.google/models/gemma/gemma-3/, March 2025. Accessed: 2026-04-20
2025
-
[21]
ToRA: A tool-integrated reasoning agent for mathematical problem solving
Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. ToRA: A tool-integrated reasoning agent for mathematical problem solving. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=Ep0TtjVoap
2024
-
[22]
Can visual scratchpads with dia- grammatic abstractions augment LLM reasoning? InI Can’t Believe It’s Not Better Workshop: Failure Modes in the Age of Foundation Models, 2024
Joy Hsu, Gabriel Poesia, Jiajun Wu, and Noah Goodman. Can visual scratchpads with dia- grammatic abstractions augment LLM reasoning? InI Can’t Believe It’s Not Better Workshop: Failure Modes in the Age of Foundation Models, 2024. URL https://openreview.net/ forum?id=YlhKbQ0zF3
2024
-
[23]
Smith, and Ranjay Krishna
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=GNSMl1P5VR
2024
-
[24]
FigureQA: An annotated figure dataset for visual reasoning
Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Akos Kadar, Adam Trischler, and Yoshua Bengio. FigureQA: An annotated figure dataset for visual reasoning. October 2017
2017
-
[25]
2008.Visual Analytics: Definition, Pro- cess, and Challenges
Daniel Keim, Gennady Andrienko, Jean-Daniel Fekete, Carsten Görg, Jörn Kohlhammer, and Guy Melançon.Visual Analytics: Definition, Process, and Challenges, pages 154–175. Springer Berlin Heidelberg, Berlin, Heidelberg, 2008. ISBN 978-3-540-70956-5. doi: 10.1007/ 978-3-540-70956-5_7. URLhttps://doi.org/10.1007/978-3-540-70956-5_7
-
[26]
Gaea Leinhardt, Orit Zaslavsky, and Mary Kay Stein. Functions, graphs, and graphing: Tasks, learning, and teaching.Review of Educational Research, 60(1):1–64, 1990. ISSN 00346543, 19351046. URLhttp://www.jstor.org/stable/1170224
arXiv 1990
-
[27]
API-bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-bank: A comprehensive benchmark for tool-augmented LLMs. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on 11 Empirical Methods in Natural Language Processing, pages 3102–3116, Singapore, December
2023
-
[28]
Api-bank: A comprehensive benchmark for tool-augmented llms
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.187. URLhttps://aclanthology.org/2023.emnlp-main.187/
-
[29]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
2024
-
[30]
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg- zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025
Pith/arXiv arXiv 2025
-
[31]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. ToolSandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational L...
-
[32]
Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th I...
2021
-
[33]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=KUNzEQMWU7
2024
-
[34]
Towards robust mathematical reasoning
Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu Hoang Trinh, Quoc V Le, and Junehyuk Jung. Towards robust mathematical reasoning. In Christos Christodoulopoulos, T...
-
[35]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, May 2022. Association...
-
[36]
Multimedia learning
Richard E Mayer. Multimedia learning. InPsychology of learning and motivation, volume 41, pages 85–139. Elsevier, 2002
2002
-
[37]
Khapra, and Pratyush Kumar
Nitesh Methani, Pritha Ganguly, Mitesh M. Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots. InThe IEEE Winter Conference on Applications of Computer Vision (WACV), March 2020
2020
-
[38]
GAIA: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=fibxvahvs3. 12
2024
-
[39]
Introducing Mistral 3.https://mistral.ai/news/mistral-3, December 2025
Mistral AI. Introducing Mistral 3.https://mistral.ai/news/mistral-3, December 2025. Accessed: 2026-04-20
2025
-
[40]
NVIDIA nemotron nano V2 VL
Nvidia, Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Guo Chen, Karan Sapra, Zhiding Yu, Adi Renduchintala, Charles Wang, Peter Jin, Arushi Goel, Mike Ranzinger, Lukas V oegtle, Philipp Fischer, Timo Roman, Wei Ping, Boxin Wang, Zhuolin Yang, Nayeon...
2025
-
[41]
Hello GPT-4o
OpenAI. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/, May 2024. Ac- cessed: 2026-04-20
2024
-
[42]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-04-20
2026
-
[43]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=2GmDdhBdDk
2025
-
[44]
Jonathan Roberts, Kai Han, and Samuel Albanie. Grab: A challenging graph analysis benchmark for large multimodal models.arXiv preprint arXiv:2408.11817, 2024
arXiv 2024
-
[45]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=Yacmpz84TH
2023
-
[46]
Gemini 3.1 Pro: A Smarter Model for Your Most Com- plex Tasks
The Gemini Team. Gemini 3.1 Pro: A Smarter Model for Your Most Com- plex Tasks. https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/ , 2026. Google blog post, published 2026-02-19, ac- cessed 2026-05-04
2026
-
[47]
Alphageometry: An olympiad-level ai system for geome- try
Trieu Trinh and Thang Luong. Alphageometry: An olympiad-level ai system for geome- try. Google DeepMind blog, 2024. URL https://deepmind.google/discover/blog/ alphageometry-an-olympiad-level-ai-system-for-geometry/
2024
-
[48]
Robert van Liere, Jurriaan D. Mulder, and Jarke J. van Wijk. Computational steering.Future Generation Computer Systems, 12(5):441–450, 1997. ISSN 0167-739X. doi: https://doi. org/10.1016/S0167-739X(96)00029-5. URL https://www.sciencedirect.com/science/ article/pii/S0167739X96000295. HPCN96
-
[49]
MV-MATH: Evaluating multimodal math reasoning in multi-visual contexts
Peijie Wang, Zhong-Zhi Li, Fei Yin, Xin Yang, Dekang Ran, and Cheng-Lin Liu. MV-MATH: Evaluating multimodal math reasoning in multi-visual contexts. August 2025. 13
2025
-
[50]
Benchmarking multimodal mathematical reasoning with explicit visual dependency, 2026
Zhikai Wang, Jiashuo Sun, Wenqi Zhang, Zhiqiang Hu, Xin Li, Fan Wang, and Deli Zhao. Benchmarking multimodal mathematical reasoning with explicit visual dependency, 2026. URL https://openreview.net/forum?id=j3960MwHQn
2026
-
[51]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. October 2022
2022
-
[52]
{$\tau$}-bench: A benchmark for \underline{T}ool-\underline{A}gent-\underline{U}ser interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. {$\tau$}-bench: A benchmark for \underline{T}ool-\underline{A}gent-\underline{U}ser interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=roNSXZpUDN
2025
-
[53]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?arXiv preprint arXiv:2403.14624, 2024
Pith/arXiv arXiv 2024
-
[54]
#!$%#$&#!!
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Visualthinker: First ever r1-zero’s aha moment on just a 2b non-SFT model, 2026. URL https://openreview.net/forum?id=CaIoemPKp0. 14 A Code and Data Availability and Reproducibility The benchmark code accompanying this paper is publicly available at https://github.com/vam...
2026
-
[55]
desmos_plot
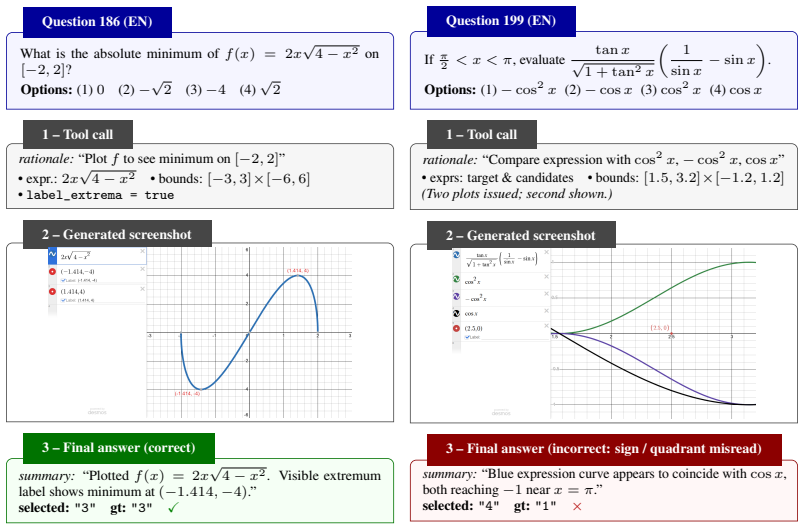
5 2. 253. 524. 5 Figure 5: Example of theR2: Tool-enabled Visual Solvingprotocol. The VLM performs an agentic interaction loop with Desmos by selecting expressions to plot, inspecting the returned screenshots, and requesting additional visual evidence when needed. In this example, the model plots the rational function, identifies the vertical and horizont...
-
[56]
Extract the option label the model selected (1, 2, 3, 4)
-
[57]
Rules (follow strictly):
Classify the ORIGINAL model output into exactly one category. Rules (follow strictly):
-
[58]
Use the model output to determine what the model selected
Do NOT solve or verify the question. Use the model output to determine what the model selected
-
[59]
Prefer an explicit option label stated by the model (use the FINAL label if multiple are mentioned)
-
[60]
If no option label is stated but the model gives an answer value/text, map it to the matching option using the provided model response only (no additional reasoning)
-
[61]
If you cannot determine a single option, use "N/A"
-
[62]
- visual_evidence_based: visual-cue-based solution is supported by screenshots or images with only light arithmetic on values directly visible from images or screenshots
category must be exactly one of: - solved_analytically: response mainly uses algebra/calculus/symbolic or heavy computation. - visual_evidence_based: visual-cue-based solution is supported by screenshots or images with only light arithmetic on values directly visible from images or screenshots. - no_definitive_answer: response does not provide a clear fin...
-
[63]
rationale must be brief and must quote the exact substring from the model output that supports the extracted selection and category (or explain why none exists)
-
[64]
selected_option
If the evidence is conflicting, incomplete, or ambiguous, do not infer; return "selected_option":"N/A" and choose "no_definitive_answer" unless the category is still clearly supported by the response. Output format: Return ONLY one compact JSON object with exactly these keys: "rationale":"<brief>","category":"<one-category>","selected_option":"<option-lab...
-
[65]
From the first screenshot, the zeros of cot(x)+tan(x)-4cos(2x)=0 were found near x≈0.2264 and x≈0.6155 (and their π-shifted counterparts). The four soluti
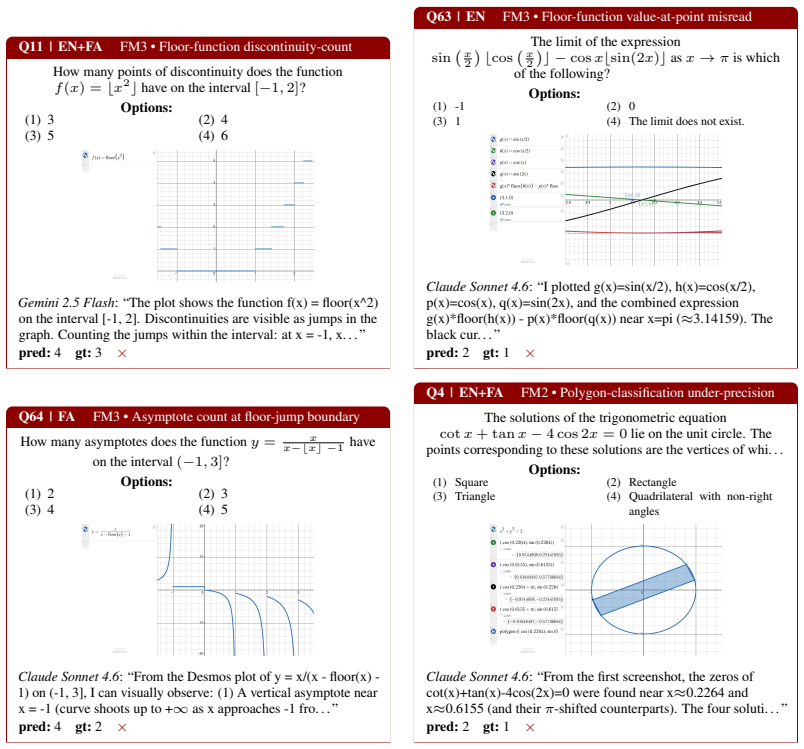
on (-1, 3], I can visually observe: (1) A vertical asymptote near x = -1 (curve shoots up to +∞as x approaches -1 fro. . . ” pred:4gt:2× Q4 | EN+FAFM2 • Polygon-classification under-precision The solutions of the trigonometric equation cotx+ tanx−4 cos 2x= 0lie on the unit circle. The points corresponding to these solutions are the vertices of whi. . . Op...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.