EARL: Towards a Unified Analysis-Guided Reinforcement Learning Framework for Egocentric Interaction Reasoning and Pixel Grounding
Pith reviewed 2026-06-30 21:27 UTC · model grok-4.3
The pith
EARL transfers coarse egocentric interaction semantics to fine-grained query answering and pixel grounding using a two-stage RL framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
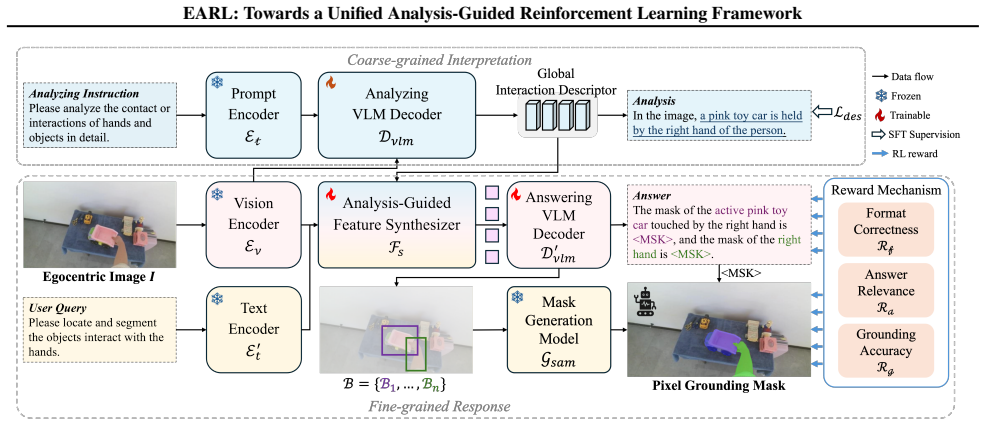
EARL adopts a two-stage parsing framework including coarse-grained interpretation and fine-grained response. The first stage holistically interprets egocentric interactions and generates a structured textual description. The second stage produces the textual answer and pixel-level mask in response to the user query. To bridge the two stages, a global interaction descriptor is extracted as a semantic prior and integrated via the Analysis-guided Feature Synthesizer for query-oriented reasoning. The response stage is trained with GRPO using a multi-faceted reward function to handle heterogeneous outputs including textual answers, bounding boxes, and grounding masks.
What carries the argument
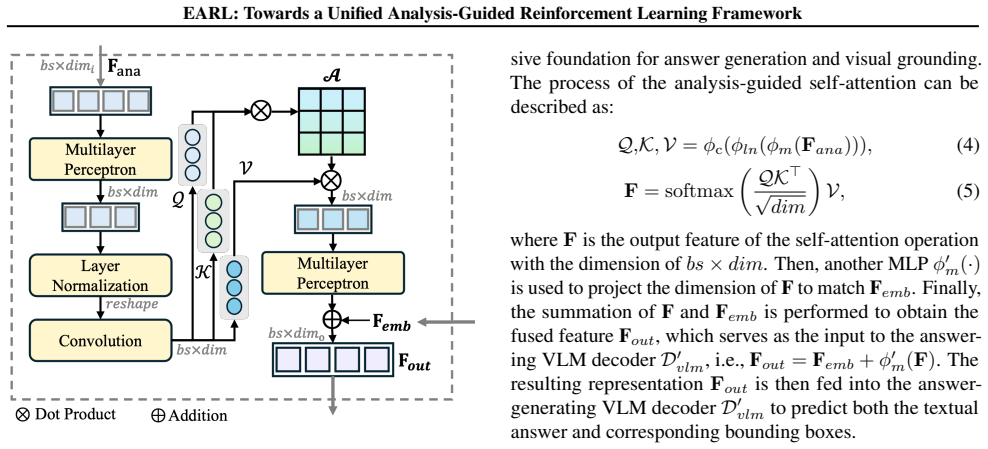
The Analysis-guided Feature Synthesizer (AFS) that integrates the global interaction descriptor extracted from the coarse stage as a semantic prior into the fine-grained response stage.
Load-bearing premise
The global interaction descriptor extracted from the coarse stage can be effectively integrated via the Analysis-guided Feature Synthesizer to improve query-oriented reasoning and grounding without introducing errors or losing important details.
What would settle it
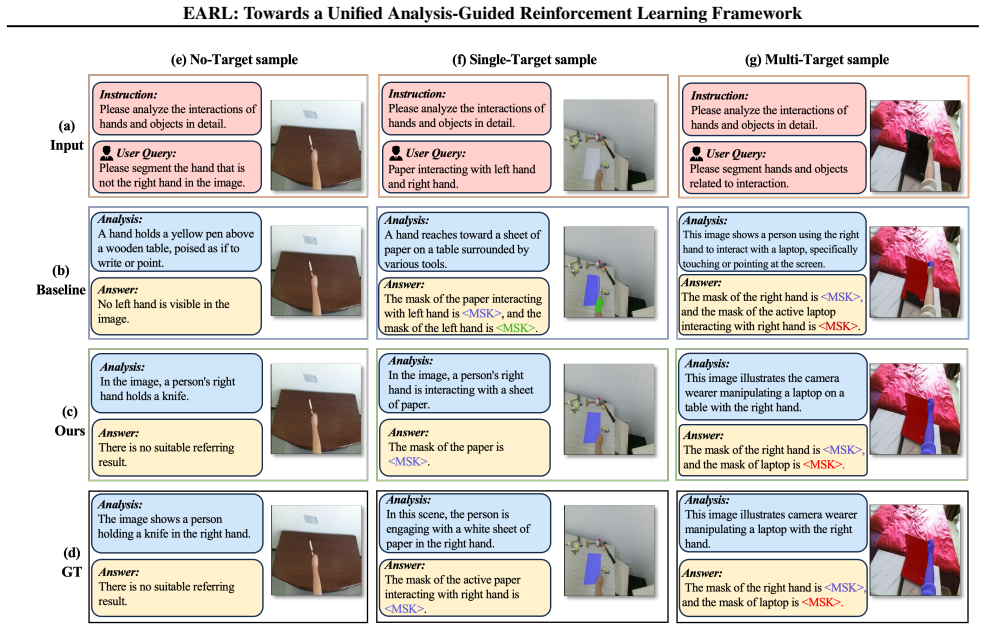
If ablating the AFS module or the coarse stage produces no drop in cIoU on Ego-IRGBench or no loss of transfer performance on EgoHOS OOD grounding, the central claim would be falsified.
Figures



read the original abstract
Understanding human--environment interactions from egocentric vision is essential for assistive robotics and embodied intelligent agents, yet existing multimodal large language models (MLLMs) still struggle with accurate interaction reasoning and fine-grained pixel grounding. To this end, this paper introduces EARL, an Egocentric Analysis-guided Reinforcement Learning framework that explicitly transfers coarse interaction semantics to query-oriented answering and grounding. Specifically, EARL adopts a two-stage parsing framework including coarse-grained interpretation and fine-grained response. The first stage holistically interprets egocentric interactions and generates a structured textual description. The second stage produces the textual answer and pixel-level mask in response to the user query. To bridge the two stages, we extract a global interaction descriptor as a semantic prior, which is integrated via a novel Analysis-guided Feature Synthesizer (AFS) for query-oriented reasoning. To optimize heterogeneous outputs, including textual answers, bounding boxes, and grounding masks, we design a multi-faceted reward function and train the response stage with GRPO. Experiments on Ego-IRGBench show that EARL achieves 65.48% cIoU for pixel grounding, outperforming previous RL-based methods by 8.37%, while OOD grounding results on EgoHOS indicate strong transferability to unseen egocentric grounding scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EARL, a two-stage egocentric analysis-guided RL framework. Stage 1 performs coarse-grained holistic interpretation of egocentric interactions to produce a structured textual description and a global interaction descriptor. Stage 2 uses an Analysis-guided Feature Synthesizer (AFS) to integrate this descriptor for query-oriented textual answering, bounding-box prediction, and pixel-level grounding, optimized via GRPO with a multi-faceted reward. On Ego-IRGBench it reports 65.48% cIoU for grounding (8.37% above prior RL methods) and strong OOD transfer on EgoHOS.
Significance. If the experimental claims are substantiated, the work offers a concrete mechanism for transferring coarse interaction semantics into fine-grained multimodal outputs via RL, which could benefit embodied agents and assistive robotics. The multi-faceted reward design for heterogeneous outputs (text, boxes, masks) and the explicit two-stage bridging via AFS are potentially reusable ideas.
major comments (3)
- [Experiments] Experiments section: the headline claims (65.48% cIoU, +8.37% over prior RL methods, OOD transfer on EgoHOS) rest on the AFS transferring the coarse-stage global descriptor without noise or detail loss, yet no ablation isolates AFS (keeping GRPO and other components fixed), no descriptor-fidelity metric is reported, and no failure-case analysis of the synthesizer is provided. This is load-bearing for the central performance claim.
- [Method] Method (AFS description): the integration of the global interaction descriptor is described at a high level but lacks quantitative validation that the synthesized features preserve fine visual cues needed for accurate masks; without such evidence the reported grounding gains cannot be attributed to the proposed bridge.
- [Abstract / Experiments] Abstract and Experiments: performance numbers are stated without reference to the precise baselines, number of runs, statistical significance tests, or potential confounding factors (e.g., differences in MLLM backbone or training data), preventing assessment of whether the 8.37% margin is robust.
minor comments (2)
- [Method] Notation for the global interaction descriptor and AFS output should be introduced with explicit symbols and dimensionality to aid reproducibility.
- [Method] The multi-faceted reward function components (textual, box, mask) should be listed with their relative weighting and exact formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We respond to each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claims (65.48% cIoU, +8.37% over prior RL methods, OOD transfer on EgoHOS) rest on the AFS transferring the coarse-stage global descriptor without noise or detail loss, yet no ablation isolates AFS (keeping GRPO and other components fixed), no descriptor-fidelity metric is reported, and no failure-case analysis of the synthesizer is provided. This is load-bearing for the central performance claim.
Authors: We agree that an explicit ablation isolating AFS (with GRPO and remaining components held fixed) is necessary to substantiate the headline claims. The revised manuscript will add this ablation, introduce a descriptor-fidelity metric (e.g., cosine similarity between original and synthesized global descriptors), and include a failure-case analysis of the AFS module to document cases where detail loss occurs. revision: yes
-
Referee: [Method] Method (AFS description): the integration of the global interaction descriptor is described at a high level but lacks quantitative validation that the synthesized features preserve fine visual cues needed for accurate masks; without such evidence the reported grounding gains cannot be attributed to the proposed bridge.
Authors: We acknowledge that the current AFS description is primarily qualitative. In revision we will add quantitative validation, including feature-similarity metrics between pre- and post-synthesis visual features and an analysis of mask accuracy attributable to the synthesized descriptor, to demonstrate preservation of fine visual cues. revision: yes
-
Referee: [Abstract / Experiments] Abstract and Experiments: performance numbers are stated without reference to the precise baselines, number of runs, statistical significance tests, or potential confounding factors (e.g., differences in MLLM backbone or training data), preventing assessment of whether the 8.37% margin is robust.
Authors: The experiments section identifies the prior RL methods used as baselines, yet we agree that additional detail is required for reproducibility and robustness assessment. The revision will explicitly enumerate the exact baselines, report the number of independent runs together with standard deviations, include statistical significance tests, and discuss potential confounding factors such as backbone or data differences. revision: yes
Circularity Check
No circularity: framework claims rest on empirical results and design choices, not self-referential definitions or fitted predictions.
full rationale
The paper presents EARL as a two-stage RL framework with an Analysis-guided Feature Synthesizer (AFS) bridging coarse interaction descriptors to fine-grained grounding outputs, trained via GRPO and a multi-faceted reward. No equations, derivations, or parameter-fitting steps are described that would reduce a claimed prediction or result back to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The reported metrics (65.48% cIoU, OOD transfer) are presented as experimental outcomes rather than analytically forced quantities. The central assumptions about AFS fidelity are empirical claims open to ablation or failure analysis, not circular by the enumerated patterns. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
J., and Yu, C
Bambach, S., Lee, S., Crandall, D. J., and Yu, C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. InProceedings of the IEEE/CVF international conference on computer vision, pp. 1949–1957,
1949
-
[3]
Chen, M., Chen, J., Fan, Z., Lee, Y ., Dang, Z., Wang, L., Cui, Y ., Chau, L.-P., and Wang, Y . Hvg-3d: Bridging real and simulation domains for 3d-conditional hand-object inter- action video synthesis.arXiv preprint arXiv:2604.03305,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Huang, J., Xu, Z., Zhou, J., Liu, T., Xiao, Y ., Ou, M., Ji, B., Li, X., and Yuan, K. SAM-R1: leveraging SAM for reward feedback in multimodal segmentation via rein- forcement learning.CoRR, abs/2505.22596,
-
[5]
10 EARL: Towards a Unified Analysis-Guided Reinforcement Learning Framework Li, J., Xu, H., Cheng, S., Wu, K., Yap, K.-H., Chau, L.-P., and Wang, Y . Building egocentric procedural ai assistant: Methods, benchmarks, and challenges.arXiv preprint arXiv:2511.13261, 2025a. Li, K., Guo, D., Chen, G., Fan, C., Xu, J., Wu, Z., Fan, H., and Wang, M. Prototypical...
-
[6]
Liu, Y ., Ma, Z., Pu, J., Qi, Z., Wu, Y ., Ying, S., and Chen, C. W. Unipixel: Unified object referring and segmenta- tion for pixel-level visual reasoning. InAdvances in Neu- ral Information Processing Systems (NeurIPS), 2025a. Liu, Y ., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., and Jia, J. Seg-zero: Reasoning-chain guided segmentation via cognitive ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
A., Veness, J., Bellemare, M
Mnih, V ., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidje- land, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning. nature, 518 (7540): 529–533, 2015.Cited on, 3(4),
2015
-
[8]
Egothinker: Unveiling egocentric reasoning with spatio-temporal cot.CoRR, abs/2510.23569,
Pei, B., Huang, Y ., Xu, J., He, Y ., Chen, G., Wu, F., Qiao, Y ., and Pang, J. Egothinker: Unveiling egocentric reasoning with spatio-temporal cot.CoRR, abs/2510.23569,
-
[10]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., Hu, R., Ryali, C., Ma, T., Khedr, H., R ¨adle, R., Rolland, C., Gustafson, L., et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024a. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Deep feature selection-and- fusion for RGB-D semantic segmentation
Su, Y ., Yuan, Y ., and Jiang, Z. Deep feature selection-and- fusion for RGB-D semantic segmentation. In2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, July 5-9, 2021, pp. 1–6. IEEE,
2021
-
[13]
Induced and reduced unbounded operator algebras
doi: 10.1109/ICME51207.2021.9428155. Su, Y ., Wang, Y ., and Chau, L.-P. Care-ego: Contact-aware relationship modeling for egocentric interactive hand- object segmentation.Expert Systems with Applications, pp. 129148, 2025a. Su, Y ., Wang, Y ., Hu, Q., Yang, C., and Chau, L. ANNEXE: unified analyzing, answering, and pixel grounding for egocentric interact...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icme51207.2021.9428155 2021
-
[14]
L., Papaioannou, I., Eshghi, A., Konstas, I., and Lemon, O
Suglia, A., Greco, C., Baker, K., Part, J. L., Papaioannou, I., Eshghi, A., Konstas, I., and Lemon, O. Alanavlm: A multimodal embodied ai foundation model for egocentric video understanding.arXiv preprint arXiv:2406.13807,
-
[15]
Wang, H., Yang, J., Yu, B., Zhan, Y ., Tao, D., and Ling, H. Distilling interaction knowledge for semi-supervised egocentric action recognition.Pattern Recognition, 157: 110927, 2025a. Wang, J., Tian, Z., Wang, X., Zhang, X., Huang, W., Wu, Z., and Jiang, Y . Simplear: Pushing the frontier of autore- gressive visual generation through pretraining, sft, an...
-
[16]
Wang, X., Wang, Y ., and Chau, L.-P. Eva02-at: Egocentric video-language understanding with spatial-temporal ro- tary positional embeddings and symmetric optimization. arXiv preprint arXiv:2506.14356, 2025c. 12 EARL: Towards a Unified Analysis-Guided Reinforcement Learning Framework Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y ., W...
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q., Men, R....
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.48550/ARXIV .2505.09388. Yang, Y ., Zhai, W., Wang, C., Yu, C., Cao, Y ., and Zha, Z.-J. Egochoir: Capturing 3d human-object interaction regions from egocentric views.Advances in Neural Information Processing Systems, 37:54529–54557,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[19]
arXiv preprint arXiv:2506.22624 (2025)
You, Z. and Wu, Z. Seg-r1: Segmentation can be sur- prisingly simple with reinforcement learning.CoRR, abs/2506.22624,
-
[20]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/ abs/2503.14476. Yu, Z., Huang, Y ., Furuta, R., Yagi, T., Goutsu, Y ., and Sato, Y . Fine-grained affordance annotation for egocen- tric hand-object interaction videos. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pp. 2155–2163,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Each egocentric RGB image is accompanied by a depth map and an interaction description detailing the specific interaction taking place
dataset. Each egocentric RGB image is accompanied by a depth map and an interaction description detailing the specific interaction taking place. Additionally, multiple interaction-related queries are annotated for each image, with each query paired with an answer and a corresponding pixel-level grounding mask. In total, the dataset contains over 1.6 milli...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.