DISC: Decoupling Instruction from State-Conditioned Control via Policy Generation
Pith reviewed 2026-05-21 04:55 UTC · model grok-4.3
The pith
A hypernetwork generates complete task-specific robot policies from language instructions alone, so the resulting controller has no direct access to language and must encode task awareness in its parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
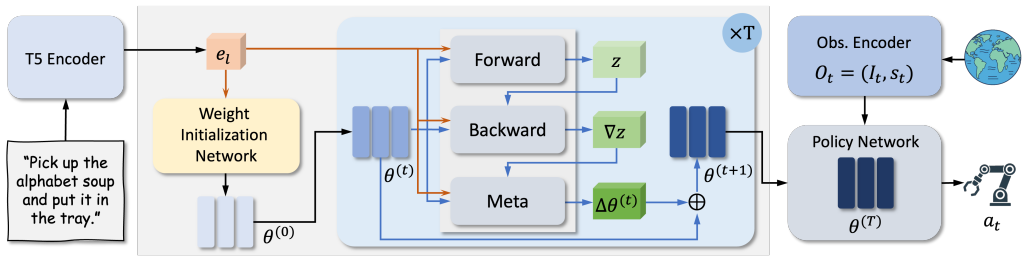
DISC replaces conditioning a shared policy on both language and observations with a hypernetwork that produces the full parameter set of a dedicated task-specific policy from the instruction alone. Because this generated policy never receives language input, its task-specific actions must derive from the parameters rather than from any observation-to-action mapping learned during training. A two-stage hypernetwork design incorporates the structure of gradient-based optimization as a feed-forward inductive bias to synthesize globally consistent high-dimensional weights without running actual optimization at inference time.
What carries the argument
A two-stage hypernetwork that maps an instruction to an initial set of policy parameters and then refines them through a feed-forward module whose structure mirrors gradient descent steps.
If this is right
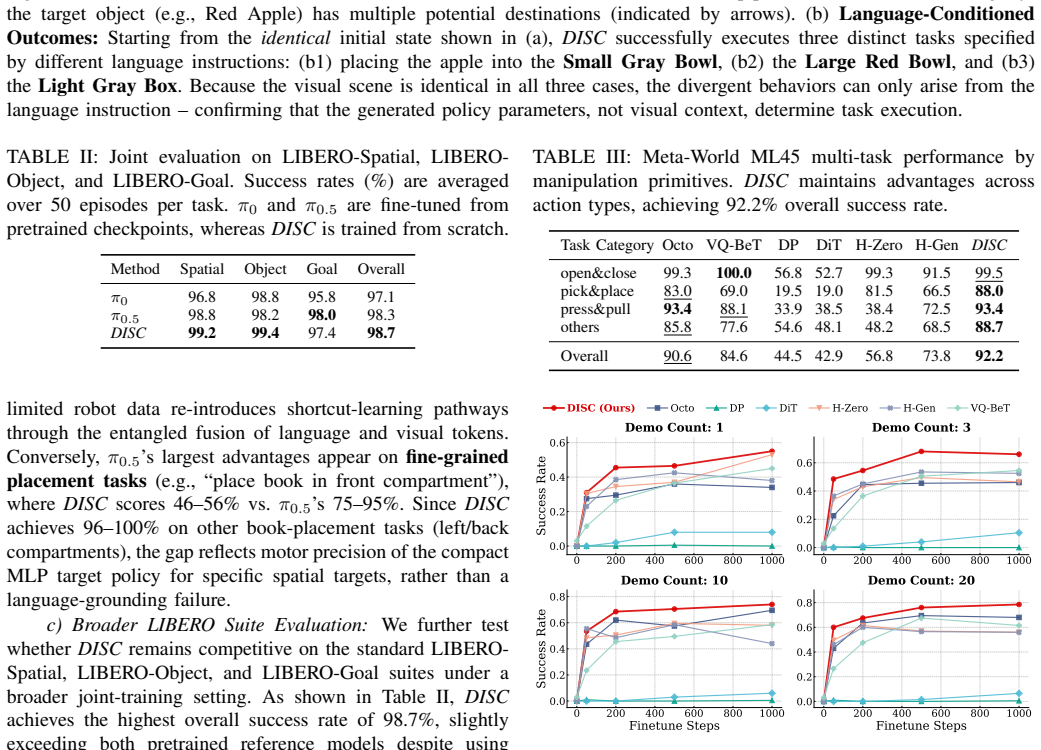
- Outperforms all language-conditioned baselines on LIBERO-90 and Meta-World, with larger margins on complex long-horizon tasks.
- Surpasses a large-scale pretrained policy model without using any external pretraining data.
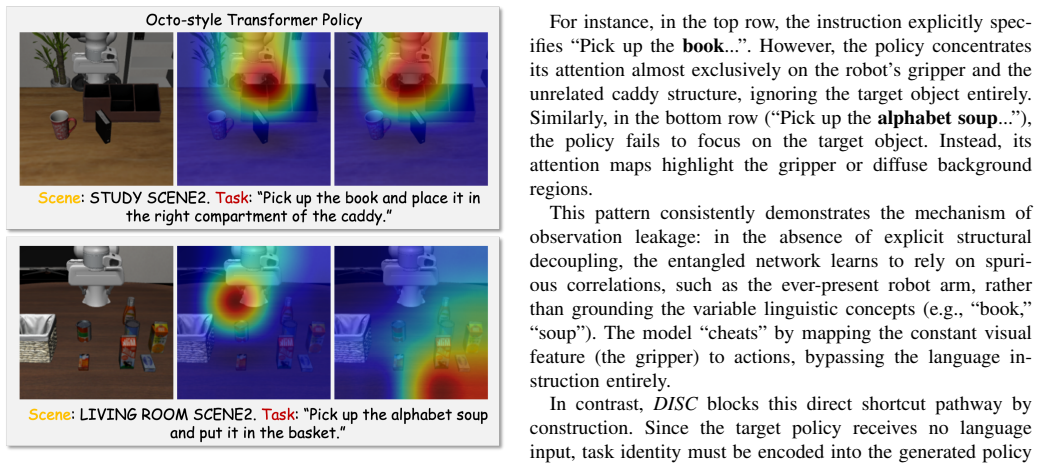
- Delivers substantially higher success on real-world tasks sharing identical visual contexts, confirming that generated parameters rather than visual shortcuts drive the behavior.
- Learns a semantically structured parameter manifold that supports few-shot adaptation from minimal demonstrations and robust performance under paraphrased instructions.
Where Pith is reading between the lines
- The learned parameter manifold could support interpolation between tasks to create policies for novel instruction combinations without additional training.
- The same generation approach might extend to other task specifications such as goal images or sketches.
- Separating parameter generation from execution could reduce interference in other sequential control settings where multiple objectives must be satisfied from the same observations.
Load-bearing premise
The hypernetwork can produce coherent, high-dimensional policy parameters that correctly solve the instructed task when the generated policy receives only visual observations.
What would settle it
On a real-world test where every instruction is paired with the identical visual scene, the generated policies for different instructions produce indistinguishable behaviors despite the change in language.
Figures




read the original abstract
Language-conditioned manipulation policies typically process instructions and observations through shared network parameters. This task-state entanglement provides a pathway for observation leakage -- networks learn scene-to-action shortcuts that bypass language grounding entirely. DISC eliminates this failure structurally. Rather than conditioning a universal policy on language, DISC uses a hypernetwork to generate the entire parameter set of a task-specific visuomotor policy from the instruction alone. The generated policy never directly accesses language; therefore, its task-awareness must come from the language. Consequently, observation leakage has no pathway to emerge. On the other hand, generating coherent high-dimensional policy weights is itself a challenging problem. We address it with a two-stage hypernetwork whose refinement stage embeds the structure of gradient-based optimization as a feed-forward inductive bias, producing globally consistent parameters without actual gradient computation. Trained entirely from scratch on standard data budgets, DISC outperforms all entangled baselines on LIBERO-90 and Meta-World, with advantages that widen on complex, long-horizon tasks -- and surpasses the large-scale pretrained $\pi_0$ despite using no external pretraining data. On a real-world benchmark where all tasks share identical visual context, DISC substantially outperforms entangled alternatives, directly confirming that language-generated policy parameters, not visual shortcuts, drive behavior. The hypernetwork further learns a semantically structured parameter manifold that enables few-shot adaptation from minimal demonstrations and robust generalization across paraphrased instructions. Our code is available at: {https://github.com/ReNginx/DISC}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DISC, a method for language-conditioned robotic manipulation that decouples instructions from state-conditioned control. Rather than using a shared network that processes both language and observations, DISC employs a hypernetwork to generate the full parameter set of a task-specific visuomotor policy from the instruction alone; the resulting policy receives only observations. A two-stage hypernetwork design is used, with a refinement stage that incorporates an inductive bias mimicking gradient-based optimization to produce coherent high-dimensional parameters. The paper claims this structural change eliminates observation leakage, and reports outperformance over entangled baselines on LIBERO-90, Meta-World, and a real-world benchmark with identical visual contexts across tasks, plus few-shot adaptation via a learned parameter manifold, all without external pretraining.
Significance. If the central claims hold, the work provides a structural alternative to data-driven or regularization-based approaches for avoiding shortcut learning in language-conditioned policies, which could improve reliability in long-horizon manipulation tasks. The real-world experiment with controlled visual context offers direct support for the decoupling hypothesis, and the reported outperformance of a large pretrained model (π0) without pretraining data is a notable empirical result. Reproducible code is provided, which aids verification. The significance hinges on whether the hypernetwork reliably generates globally consistent, task-solving parameters from instructions.
major comments (3)
- [§3] §3 (Method, two-stage hypernetwork description): The refinement stage is presented as embedding the structure of gradient-based optimization as a feed-forward inductive bias to generate globally consistent parameters. However, the manuscript does not provide explicit equations or a detailed derivation showing how the feed-forward layers map to optimization steps (e.g., no equivalent to an unrolled gradient update), making it unclear whether this produces coherent high-dimensional policy weights or merely local approximations that could fail to encode task behavior reliably.
- [Results section] Results section (LIBERO-90 and Meta-World evaluations): The abstract states outperformance with widening advantages on complex tasks, but the reported results lack error bars, ablation details on the refinement stage, and explicit data exclusion rules. This weakens verification that improvements arise from the structural decoupling rather than implementation specifics, directly affecting the load-bearing claim that language-generated parameters drive behavior.
- [Real-world benchmark section] Real-world benchmark section: While the identical-visual-context setup is a strong test for leakage, the quantitative results (e.g., success rates) are summarized without variance measures or statistical tests. This makes it difficult to assess the robustness of the claim that 'language-generated policy parameters, not visual shortcuts, drive behavior.'
minor comments (2)
- [Abstract] Abstract: The statement that 'observation leakage has no pathway to emerge' is absolute; consider qualifying it as 'substantially reduces pathways for leakage' given that empirical validation is still required.
- [Notation] Notation throughout: Ensure that symbols for generated policy parameters (e.g., θ) and hypernetwork outputs are defined consistently in the first use and used uniformly in equations and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify and strengthen the presentation of our work. We address each major comment below and have revised the manuscript accordingly to improve clarity, reproducibility, and statistical rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method, two-stage hypernetwork description): The refinement stage is presented as embedding the structure of gradient-based optimization as a feed-forward inductive bias to generate globally consistent parameters. However, the manuscript does not provide explicit equations or a detailed derivation showing how the feed-forward layers map to optimization steps (e.g., no equivalent to an unrolled gradient update), making it unclear whether this produces coherent high-dimensional policy weights or merely local approximations that could fail to encode task behavior reliably.
Authors: We agree that additional mathematical detail would strengthen the explanation of the refinement stage. In the revised manuscript, we have expanded §3 with explicit equations and a short derivation showing how the feed-forward refinement layers approximate a single step of gradient-based parameter optimization (including the mapping from layer operations to an implicit update rule). This makes the inductive bias more transparent while preserving the feed-forward nature of the architecture. revision: yes
-
Referee: [Results section] Results section (LIBERO-90 and Meta-World evaluations): The abstract states outperformance with widening advantages on complex tasks, but the reported results lack error bars, ablation details on the refinement stage, and explicit data exclusion rules. This weakens verification that improvements arise from the structural decoupling rather than implementation specifics, directly affecting the load-bearing claim that language-generated parameters drive behavior.
Authors: We acknowledge these omissions reduce verifiability. The revised results section now reports mean success rates with standard deviation error bars computed over 5 random seeds for all LIBERO-90 and Meta-World tables and figures. We have added a dedicated ablation table isolating the contribution of the refinement stage. We have also clarified in the experimental protocol that no tasks or episodes were excluded from the standard benchmark splits and that all reported numbers follow the official evaluation protocols without post-hoc filtering. revision: yes
-
Referee: [Real-world benchmark section] Real-world benchmark section: While the identical-visual-context setup is a strong test for leakage, the quantitative results (e.g., success rates) are summarized without variance measures or statistical tests. This makes it difficult to assess the robustness of the claim that 'language-generated policy parameters, not visual shortcuts, drive behavior.'
Authors: We agree that variance and significance testing would better support the real-world claims. In the revised real-world section we now include per-task success rates with standard deviations across 10 independent rollouts per task, together with a paired t-test (p < 0.05) comparing DISC against each entangled baseline. These additions directly quantify the robustness of the observed performance gap under identical visual contexts. revision: yes
Circularity Check
No circularity: architectural decoupling supported by empirical benchmarks
full rationale
The paper's core contribution is an architectural proposal: a hypernetwork generates the full parameter set of a task-specific visuomotor policy from the instruction alone, so the resulting policy receives only observations and never directly accesses language. This structural separation is presented as eliminating observation leakage by design, with the two-stage refinement stage described as embedding gradient-based optimization structure as a feed-forward bias. No equations or derivations are shown that reduce a claimed prediction or first-principles result to the inputs by construction. Performance claims rest on empirical comparisons against entangled baselines on LIBERO-90, Meta-World, and a real-world identical-visual-context benchmark, plus few-shot adaptation results. No load-bearing self-citations, fitted-input predictions, or ansatz smuggling appear in the provided text; the method is self-contained against external benchmarks and does not rely on tautological renaming or uniqueness theorems imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A hypernetwork can map language instructions to coherent high-dimensional visuomotor policy parameters
invented entities (1)
-
Two-stage hypernetwork with gradient-optimization-mimicking refinement stage
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DISC uses a hypernetwork to generate the entire parameter set of a task-specific visuomotor policy from the instruction alone... two-stage hypernetwork whose refinement stage embeds the structure of gradient-based optimization as a feed-forward inductive bias
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The generated policy never directly accesses language; therefore, its task-awareness must come from the language.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vision-language models struggle to align entities across modalities
I ˜nigo Alonso, Gorka Azkune, Ander Salaberria, Jeremy Barnes, and Oier Lopez de Lacalle. Vision-language models struggle to align entities across modalities. In Findings of the Association for Computational Linguis- tics: ACL 2025, pages 18846–18862, Vienna, Austria, July 2025. Association for Computational Linguistics. URL https://aclanthology.org/2025....
work page 2025
-
[2]
Hypernetworks in meta-reinforcement learning
Jacob Beck, Matthew Thomas Jackson, Risto Vuorio, and Shimon Whiteson. Hypernetworks in meta-reinforcement learning. InConference on Robot Learning, pages 1478–
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi 0 : A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[7]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Lin- guistics, pages 4171–4186. Association for Computa- tional Linguistics, 2019. URL https://aclan...
work page 2019
-
[8]
Model- agnostic meta-learning for fast adaptation of deep net- works
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model- agnostic meta-learning for fast adaptation of deep net- works. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
work page 2017
-
[9]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
Baku: An efficient transformer for multi-task policy learning
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. Baku: An efficient transformer for multi-task policy learning. Advances in Neural Information Processing Systems, 37: 141208–141239, 2024
work page 2024
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural infor- mation processing systems, 33:6840–6851, 2020
work page 2020
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[13]
Otter: A vision-language-action model with text-aware visual feature extraction
Huang Huang, Fangchen Liu, Letian Fu, Tingfan Wu, Mustafa Mukadam, Jitendra Malik, Ken Goldberg, and Pieter Abbeel. Otter: A vision-language-action model with text-aware feature extraction.arXiv preprint arXiv:2503.03734, 2025
-
[14]
Continual model-based reinforcement learning with hypernetworks
Yizhou Huang, Kevin Xie, Homanga Bharadhwaj, and Florian Shkurti. Continual model-based reinforcement learning with hypernetworks. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 799–805. IEEE, 2021
work page 2021
-
[15]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations.arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision- language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
work page 2026
-
[19]
Vision-Language Foundation Models as Effective Robot Imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, et al. Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
work page 2023
-
[21]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, Benoit Dumoulin, and Hanghang Tong. Seeing but not believing: Probing the disconnect between visual attention and answer correctness in VLMs.arXiv preprint arXiv:2510.17771, 2025
-
[23]
Visu- alizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visu- alizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
work page 2008
-
[24]
Text takes over: A study of modality bias in multimodal intent detection
Ankan Mullick, Saransh Sharma, Abhik Jana, and Pawan Goyal. Text takes over: A study of modality bias in multimodal intent detection. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24040–24070, Miami, Florida, USA, November 2025. Association for Computational Lin- guistics. URL https://aclanthology.org/2025...
work page 2025
-
[25]
Anupam Pani and Yanchao Yang. Gaze-vlm: Bridging gaze and vlms through attention regularization for ego- centric understanding.arXiv preprint arXiv:2510.21356, 2025
-
[26]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[27]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139, pages 8748–876...
work page 2021
-
[29]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[30]
Scott Reed, Konrad Zolna, Emilio Parisotto, Ser- gio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent.arXiv preprint arXiv:2205.06175, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Hypogen: Optimization-biased hypernetworks for generalizable policy generation
Hanxiang Ren, Li Sun, Xulong Wang, Pei Zhou, Zewen Wu, Siyan Dong, Difan Zou, Youyi Zheng, and Yanchao Yang. Hypogen: Optimization-biased hypernetworks for generalizable policy generation. InThe Thirteenth Inter- national Conference on Learning Representations, 2025
work page 2025
-
[32]
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal-conditioned imitation learning us- ing score-based diffusion policies.arXiv preprint arXiv:2304.02532, 2023
-
[33]
Moritz Reuss, Jyothish Pari, Pulkit Agrawal, and Rudolf Lioutikov. Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning.arXiv preprint arXiv:2412.12953, 2024
-
[34]
Hyper- networks for zero-shot transfer in reinforcement learning
Sahand Rezaei-Shoshtari, Charlotte Morissette, Fran- cois R Hogan, Gregory Dudek, and David Meger. Hyper- networks for zero-shot transfer in reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9579–9587, 2023
work page 2023
-
[35]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[36]
Meta-learning with memory-augmented neural networks
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. InInterna- tional conference on machine learning, pages 1842–
-
[37]
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloningkmodes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
work page 2022
-
[38]
Jake Snell, Kevin Swersky, and Richard Zemel. Prototyp- ical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[39]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [40]
-
[41]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[43]
Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
work page 2020
-
[44]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, et al. Dreamvla: a vision-language- action model dreamed with comprehensive world knowl- edge.arXiv preprint arXiv:2507.04447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Maxmi: A maximal mutual information criterion for manipulation concept discovery
Pei Zhou and Yanchao Yang. Maxmi: A maximal mutual information criterion for manipulation concept discovery. InEuropean Conference on Computer Vision, pages 88–
-
[47]
Autocgp: Closed-loop concept- guided policies from unlabeled demonstrations
Pei Zhou, Ruizhe Liu, Qian Luo, Fan Wang, Yibing Song, and Yanchao Yang. Autocgp: Closed-loop concept- guided policies from unlabeled demonstrations. InThe Thirteenth International Conference on Learning Repre- sentations, 2025
work page 2025
-
[48]
Pei Zhou, Wanting Yao, Qian Luo, Xunzhe Zhou, and Yanchao Yang. Hyper-goalnet: Goal-conditioned manip- ulation policy learning with hypernetworks.Advances in Neural Information Processing Systems, 38:83438– 83469, 2026
work page 2026
-
[49]
Rt-2: Vision-language- action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. APPENDIXA PROBLEMFORMULATIONDETAILS A. State and Action Spaces The state spaceS ⊆R H×...
work page 2023
-
[50]
For backward pass simulation,F Backward estimates Ja- cobians usingJ θi =CrossAttn(τ i−1,ω i,ω i)andJ hi = CrossAttn(ωi,τ i−1,τ i−1)for inter-layer dependencies. Chain rule computations are implemented via attention-based matrix multiplications:∂L/∂z i−1 =CrossAttn(∂L/∂z i, Jhi , Jhi), ensuring modality consistency by using upstream gradients as queries w...
work page 2050
-
[51]
The robot successfully grasps the correct target object specified in the instruction
-
[52]
The object is transported to and released inside the correct target container. We evaluate each method over 30 trials per task, totaling30× 9 = 270evaluation episodes per method. APPENDIXK EXTENDEDQUALITATIVEANALYSIS To provide concrete evidence for our claims regarding the limitations of task-state entanglement, we conduct qualitative analyses on a repre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.