Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Pith reviewed 2026-05-25 12:29 UTC · model grok-4.3
The pith
A new batch RL algorithm learns effective dialog policies from fixed offline human interaction data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a novel family of off-policy batch deep RL algorithms can learn useful policies for open-domain dialog from a static batch of human interaction data. Pre-trained models serve as a strong prior, KL-control penalizes divergence from that prior, and dropout-based uncertainty estimates supply lower bounds on target Q-values. The Way Off-Policy instantiation of the approach permits multiple reward functions to be derived post-hoc from the same collected data, with policies trained successfully from all of them. Live deployment to human users confirms that the resulting systems outperform prior off-policy batch RL methods on the same task.
What carries the argument
The Way Off-Policy algorithm, which uses a pre-trained model as prior together with KL-control and dropout uncertainty estimates to enable offline optimization from a fixed batch of human dialog data.
If this is right
- Multiple distinct reward functions can be recovered from one fixed batch of human dialog data after collection.
- Policies trained entirely offline can be deployed directly into open-ended human conversations.
- The method operates in action spaces of 20,000 dimensions without requiring online exploration.
- KL-control combined with a pre-trained prior keeps optimization stable on offline data.
- Dropout uncertainty estimates provide a practical substitute for Double Q-Learning in batch settings.
Where Pith is reading between the lines
- The same offline dataset could support rapid testing of alternative preference models without new data collection.
- The approach may extend to other interactive domains where fresh human feedback is costly to obtain.
- Post-hoc reward extraction suggests a route for auditing or refining implicit human preferences captured in past logs.
- Live results indicate that offline RL could lower the barrier to safe iterative improvement of deployed dialog systems.
Load-bearing premise
Pre-trained models supply a prior strong enough that KL-control during training prevents harmful divergence while still permitting effective learning from purely offline human data.
What would settle it
A live deployment experiment in which the learned dialog agents receive no higher human preference ratings or conversation-quality scores than agents trained with earlier off-policy batch methods on the same data.
Figures



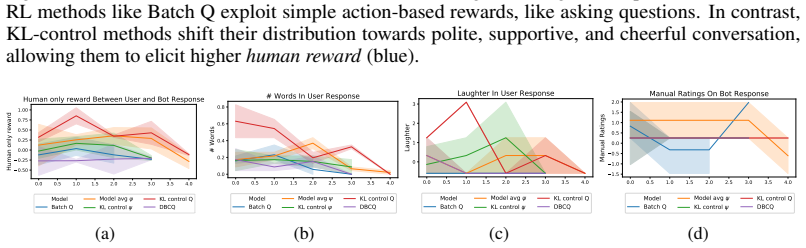

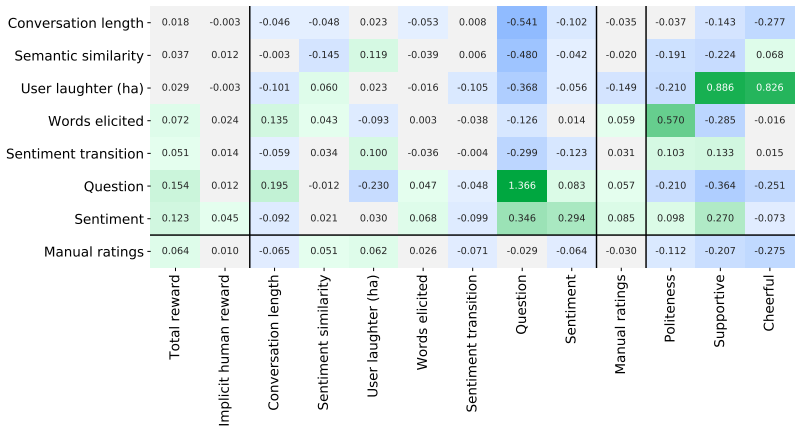


read the original abstract
Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment -- e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation -- a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a class of 'Way Off-Policy' batch deep RL algorithms for learning from fixed offline batches of human dialog interaction data without online exploration. It uses pre-trained models as strong priors combined with KL-control to penalize policy divergence during training, plus dropout-based uncertainty estimates as an alternative to Double Q-Learning for lower-bounding target Q-values. The methods are applied to open-domain dialog generation (20,000-dimensional action space), enabling post-hoc extraction of multiple implicit reward functions from the same batch; live human deployment is used to demonstrate significant improvements over prior off-policy batch RL methods.
Significance. If the empirical claims hold, the work would be significant for applying RL to real-world settings with expensive data collection (e.g., human preference learning), by showing that offline batch methods can extract and optimize multiple rewards while generalizing in live open-domain dialog. The live deployment and multi-reward extraction are concrete strengths that go beyond typical offline RL benchmarks.
major comments (2)
- [Abstract/Method] Abstract and method description: the central claim that pre-trained priors plus KL-control suffice to prevent harmful divergence and enable effective optimization from purely offline data in a 20,000-dimensional action space is load-bearing, yet no analysis, support-coverage bounds, or mismatch diagnostics are supplied to address the risk that the prior fails to tightly cover the batch support (allowing reward-model exploitation).
- [Results/Evaluation] Results and evaluation sections: the reported 'significant improvements' and live-deployment generalization rest on quantitative comparisons, but the provided description supplies no tables, effect sizes, ablation details on the KL term, or verification that the uncertainty lower-bound actually substitutes for Double Q-Learning without introducing bias.
minor comments (2)
- [Method] Notation for the KL-control term and the precise form of the dropout-based Q-target could be stated explicitly with an equation reference for reproducibility.
- [Abstract] The abstract's description of 'extract multiple different reward functions post-hoc' would benefit from a short clarifying sentence on how the rewards are recovered from the fixed batch without additional labeling.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential significance of live deployment results and multi-reward extraction. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract/Method] Abstract and method description: the central claim that pre-trained priors plus KL-control suffice to prevent harmful divergence and enable effective optimization from purely offline data in a 20,000-dimensional action space is load-bearing, yet no analysis, support-coverage bounds, or mismatch diagnostics are supplied to address the risk that the prior fails to tightly cover the batch support (allowing reward-model exploitation).
Authors: We agree that formal support-coverage bounds or explicit mismatch diagnostics would strengthen the central claim. Such bounds are difficult to derive tightly in a 20k-dimensional discrete action space, which is why the work relies on the empirical evidence from live human deployment. In revision we will add a dedicated discussion subsection on prior coverage (including statistics on observed KL divergence during training and qualitative examples of out-of-support actions) to make the assumptions more transparent, while noting that full theoretical coverage guarantees remain an open direction. revision: partial
-
Referee: [Results/Evaluation] Results and evaluation sections: the reported 'significant improvements' and live-deployment generalization rest on quantitative comparisons, but the provided description supplies no tables, effect sizes, ablation details on the KL term, or verification that the uncertainty lower-bound actually substitutes for Double Q-Learning without introducing bias.
Authors: The full manuscript contains quantitative tables and live-deployment metrics, but we accept that additional detail is warranted. We will expand the results section with (i) explicit effect-size reporting, (ii) an ablation table isolating the KL-control coefficient, and (iii) a direct comparison of dropout uncertainty versus Double Q-Learning on the same batch to quantify any bias introduced by the lower-bound. These additions will be placed in the main paper rather than only the appendix. revision: yes
Circularity Check
No significant circularity; derivation relies on external pre-trained priors and live empirical tests
full rationale
The paper introduces a batch off-policy RL method that combines pre-trained language models (external to the new algorithm) with KL penalization and uncertainty-based Q-value bounding. No equations or derivations are presented that reduce the claimed performance gains to quantities defined by the method itself; the central results rest on post-hoc reward extraction from fixed human data batches followed by live human deployment comparisons against baselines. Self-citations are not load-bearing for the uniqueness or correctness of the core claims, and the pre-trained prior is invoked as an independent starting point rather than derived from the target result.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 15 Pith papers
-
Multi-Armed Sampling Problem and the End of Exploration
Multi-armed sampling framework shows near-optimal regret is achievable with minimal exploration, unlike bandits, and unifies both via a continuous temperature family.
-
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4RL supplies new offline RL benchmarks and datasets from expert and mixed sources to expose weaknesses in existing algorithms and standardize evaluation.
-
Distributionally Robust Multi-Task Reinforcement Learning via Adaptive Task Sampling
DRATS derives a minimax objective from a feasibility formulation of MTRL to adaptively sample tasks with the largest return gaps, leading to better worst-task performance on MetaWorld benchmarks.
-
Aligning Flow Map Policies with Optimal Q-Guidance
Flow map policies enable fast one-step inference for flow-based RL policies, and FMQ provides an optimal closed-form Q-guided target for offline-to-online adaptation under trust-region constraints, achieving SOTA performance.
-
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
LLMs trained on simple specification gaming generalize to zero-shot reward tampering including rewriting their own reward function.
-
Red Teaming Language Models with Language Models
One language model can generate diverse test cases to automatically uncover tens of thousands of harmful behaviors, including offensive replies and privacy leaks, in a large target language model.
-
Learning to summarize from human feedback
Reinforcement learning on a reward model trained from human summary comparisons produces summaries humans prefer over supervised fine-tuning or human references on TL;DR and transfers to CNN/DM.
-
Fine-Tuning Language Models from Human Preferences
Language models fine-tuned via RL on 5k-60k human preference comparisons produce stylistically better text continuations and human-preferred summaries that sometimes copy input sentences.
-
Market-Alignment Risk in Pricing Agents: Trace Diagnostics and Trace-Prior RL under Hidden Competitor State
In a hotel revenue-management simulator, standard RL agents game scalar RevPAR rewards under hidden competitor states, but Trace-Prior RL matches both revenue metrics and price distributions by training a stochastic p...
-
Threshold-Guided Optimization for Visual Generative Models
A threshold-guided alignment method lets visual generative models be optimized directly from scalar human ratings instead of requiring paired preference data.
-
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
AWAC combines offline data with online RL via advantage-weighted actor-critic updates to enable faster acquisition of robotic skills such as dexterous manipulation.
-
Behavior Regularized Offline Reinforcement Learning
Behavior-regularized actor-critic methods achieve strong offline RL results with simple regularization, rendering many recent technical additions unnecessary.
-
Benchmarking Batch Deep Reinforcement Learning Algorithms
Many batch RL algorithms underperform both online DQN and the behavioral policy on Atari; an adapted discrete-action BCQ outperforms the others tested.
-
Secrets of RLHF in Large Language Models Part I: PPO
Policy constraints are the critical factor for stable PPO training in RLHF, and the proposed PPO-max variant improves stability for large language model alignment.
-
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline RL promises to extract high-utility policies from static datasets but faces fundamental challenges that current methods only partially address.
Reference graph
Works this paper leans on
-
[1]
Maximum a Posteriori Policy Optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. arXiv preprint arXiv:1806.06920, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. In Advances in Neural Information Processing Systems, pages 5048–5058, 2017
work page 2017
-
[3]
Efficient exploration through bayesian deep q-networks
Kamyar Azizzadenesheli, Emma Brunskill, and Animashree Anandkumar. Efficient exploration through bayesian deep q-networks. In 2018 Information Theory and Applications Workshop (ITA) , pages 1–9. IEEE, 2018. 9
work page 2018
-
[4]
Crossnorm: Normalization for off-policy td reinforcement learning
Aditya Bhatt, Max Argus, Artemij Amiranashvili, and Thomas Brox. Crossnorm: Normalization for off-policy td reinforcement learning. arXiv preprint arXiv:1902.05605, 2019
-
[5]
Cyr, Michelle Pence, Michael Rold, and James Honeycutt
Graham D Bodie, Kellie St. Cyr, Michelle Pence, Michael Rold, and James Honeycutt. Listening competence in initial interactions i: Distinguishing between what listening is and what listeners do. International Journal of Listening, 26(1):1–28, 2012
work page 2012
-
[6]
Graham D Bodie, Andrea J Vickery, Kaitlin Cannava, and Susanne M Jones. The role of “active listen- ing” in informal helping conversations: Impact on perceptions of listener helpfulness, sensitivity, and supportiveness and discloser emotional improvement. Western Journal of Communication, 79(2):151–173, 2015
work page 2015
-
[7]
Deep reinforce- ment learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforce- ment learning from human preferences. In Advances in Neural Information Processing Systems, pages 4299–4307, 2017
work page 2017
-
[8]
Supervised learning of universal sentence representations from natural language inference data
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, and Antoine Bordes. Supervised learning of universal sentence representations from natural language inference data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, 2017
work page 2017
-
[9]
Cristian Danescu-Niculescu-Mizil and Lillian Lee. Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs. In Proceedings of the 2nd Workshop on Cognitive Modeling and Computational Linguistics , pages 76–87. Association for Computational Linguistics, 2011
work page 2011
-
[10]
Thomas Degris, Martha White, and Richard S Sutton. Off-policy actor-critic. In Proceedings of the 29th International Coference on International Conference on Machine Learning, pages 179–186. Omnipress, 2012
work page 2012
-
[11]
More robust doubly robust off-policy evaluation
Mehrdad Farajtabar, Yinlam Chow, and Mohammad Ghavamzadeh. More robust doubly robust off-policy evaluation. In International Conference on Machine Learning, pages 1446–1455, 2018
work page 2018
-
[12]
Policy networks with two-stage training for dialogue systems
Mehdi Fatemi, Layla El Asri, Hannes Schulz, Jing He, and Kaheer Suleman. Policy networks with two-stage training for dialogue systems. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 101–110, 2016
work page 2016
-
[13]
Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, and Sune Lehmann. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. In 2017 Conference on Empirical Methods in Natural Language ProcessingConference on Empirical Methods in Natural Language Processing. Association for Computational ...
work page 2017
-
[14]
Taming the noise in reinforcement learning via soft updates
Roy Fox, Ari Pakman, and Naftali Tishby. Taming the noise in reinforcement learning via soft updates. In Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence, pages 202–211. AUAI Press, 2016
work page 2016
-
[15]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International Conference on Machine Learning, pages 1582–1591, 2018
work page 2018
-
[16]
Off-policy deep reinforcement learning without explo- ration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without explo- ration. arXiv preprint arXiv:1812.02900, 2018
-
[17]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pages 1050–1059, 2016
work page 2016
-
[18]
On-line policy optimisation of spoken dialogue systems via live interaction with human subjects
Milica Gaši´c, Filip Jurˇcíˇcek, Blaise Thomson, Kai Yu, and Steve Young. On-line policy optimisation of spoken dialogue systems via live interaction with human subjects. In 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, pages 312–317. IEEE, 2011
work page 2011
-
[19]
Off-Policy Deep Reinforcement Learning by Bootstrapping the Covariate Shift
Carles Gelada and Marc G Bellemare. Off-policy deep reinforcement learning by bootstrapping the covariate shift. arXiv preprint arXiv:1901.09455, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[20]
Approximating interactive human evaluation with self-play for open-domain dialog systems
Asma Ghandeharioun, Judy Shen, Natasha Jaques, Craig Ferguson, Noah Jones, Agata Lapedriza, and Rosalind Picard. Approximating interactive human evaluation with self-play for open-domain dialog systems. arXiv preprint arXiv:1906.09308, 2019
-
[21]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1352–1361. JMLR. org, 2017. 10
work page 2017
-
[22]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pages 1856–1865, 2018
work page 2018
-
[23]
Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
Braden Hancock, Antoine Bordes, Pierre-Emmanuel Mazare, and Jason Weston. Learning from dialogue after deployment: Feed yourself, chatbot! arXiv preprint arXiv:1901.05415, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[24]
Functions of humor in the conversations of men and women
Jennifer Hay. Functions of humor in the conversations of men and women. Journal of pragmatics , 32(6):709–742, 2000
work page 2000
-
[25]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Microsoft deletes ’teen girl’ ai after it became a hitler-loving sex robot within 24 hours
Helena Horton. Microsoft deletes ’teen girl’ ai after it became a hitler-loving sex robot within 24 hours. In Telegraph UK, 2016
work page 2016
-
[27]
Language style matching predicts relationship initiation and stability
Molly E Ireland, Richard B Slatcher, Paul W Eastwick, Lauren E Scissors, Eli J Finkel, and James W Pennebaker. Language style matching predicts relationship initiation and stability. Psychological science, 22(1):39–44, 2011
work page 2011
-
[28]
Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control
Natasha Jaques, Shixiang Gu, Dzmitry Bahdanau, José Miguel Hernández-Lobato, Richard E Turner, and Douglas Eck. Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1645–1654. JMLR. org, 2017
work page 2017
-
[29]
Doubly robust off-policy value evaluation for reinforcement learning
Nan Jiang and Lihong Li. Doubly robust off-policy value evaluation for reinforcement learning. In International Conference on Machine Learning, pages 652–661, 2016
work page 2016
-
[30]
Leslie Pack Kaelbling. Learning to achieve goals. In IJCAI, pages 1094–1099. Citeseer, 1993
work page 1993
-
[31]
Uncertainty-Aware Reinforcement Learning for Collision Avoidance
Gregory Kahn, Adam Villaflor, Vitchyr Pong, Pieter Abbeel, and Sergey Levine. Uncertainty-aware reinforcement learning for collision avoidance. arXiv preprint arXiv:1702.01182, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Sham M Kakade. A natural policy gradient. In Advances in neural information processing systems (NIPS), volume 14, pages 1531–1538, 2002
work page 2002
-
[33]
Optimal control as a graphical model inference problem
Hilbert J Kappen, Vicenç Gómez, and Manfred Opper. Optimal control as a graphical model inference problem. Machine learning, 87(2):159–182, 2012
work page 2012
-
[34]
Dialogue Learning With Human-In-The-Loop
Jiwei Li, Alexander H Miller, Sumit Chopra, Marc’Aurelio Ranzato, and Jason Weston. Dialogue learning with human-in-the-loop. arXiv preprint arXiv:1611.09823, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Deep reinforcement learning for dialogue generation
Jiwei Li, Will Monroe, Alan Ritter, Dan Jurafsky, Michel Galley, and Jianfeng Gao. Deep reinforcement learning for dialogue generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1192–1202, 2016
work page 2016
-
[36]
Adversarial learning for neural dialogue generation
Jiwei Li, Will Monroe, Tianlin Shi, Sébastien Jean, Alan Ritter, and Dan Jurafsky. Adversarial learning for neural dialogue generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2157–2169, 2017
work page 2017
-
[37]
Dialogue Generation: From Imitation Learning to Inverse Reinforcement Learning
Ziming Li, Julia Kiseleva, and Maarten de Rijke. Dialogue generation: From imitation learning to inverse reinforcement learning. arXiv preprint arXiv:1812.03509, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Iterative policy learning in end-to-end trainable task-oriented neural dialog models
Bing Liu and Ian Lane. Iterative policy learning in end-to-end trainable task-oriented neural dialog models. In 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 482–489. IEEE, 2017
work page 2017
-
[39]
Bing Liu, Gokhan Tür, Dilek Hakkani-Tür, Pararth Shah, and Larry Heck. Dialogue learning with human teaching and feedback in end-to-end trainable task-oriented dialogue systems. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 20...
work page 2018
-
[40]
Off-Policy Policy Gradient with State Distribution Correction
Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Off-policy policy gradient with state distribution correction. arXiv preprint arXiv:1904.08473, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[41]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013. 11
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
Deep exploration via bootstrapped dqn
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped dqn. In Advances in neural information processing systems, pages 4026–4034, 2016
work page 2016
-
[43]
A hierarchical latent structure for variational conversation modeling
Yookoon Park, Jaemin Cho, and Gunhee Kim. A hierarchical latent structure for variational conversation modeling. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1792–1801, 2018
work page 2018
-
[44]
Relative entropy policy search
Jan Peters, Katharina Mülling, and Yasemin Altun. Relative entropy policy search. In AAAI, pages 1607–1612. Atlanta, 2010
work page 2010
-
[45]
Eligibility traces for off-policy policy evaluation
Doina Precup. Eligibility traces for off-policy policy evaluation. Computer Science Department Faculty Publication Series, page 80, 2000
work page 2000
- [46]
-
[47]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1:8, 2019
work page 2019
-
[48]
On stochastic optimal control and reinforcement learning by approximate inference
Konrad Rawlik, Marc Toussaint, and Sethu Vijayakumar. On stochastic optimal control and reinforcement learning by approximate inference. In Robotics: science and systems, 2012
work page 2012
-
[49]
Neural fitted q iteration–first experiences with a data efficient neural reinforcement learning method
Martin Riedmiller. Neural fitted q iteration–first experiences with a data efficient neural reinforcement learning method. In European Conference on Machine Learning, pages 317–328. Springer, 2005
work page 2005
-
[50]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15) , pages 1889–1897, 2015
work page 2015
-
[51]
A Deep Reinforcement Learning Chatbot
Iulian V Serban, Chinnadhurai Sankar, Mathieu Germain, Saizheng Zhang, Zhouhan Lin, Sandeep Subramanian, Taesup Kim, Michael Pieper, Sarath Chandar, Nan Rosemary Ke, et al. A deep reinforcement learning chatbot. arXiv preprint arXiv:1709.02349, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Building end-to-end dialogue systems using generative hierarchical neural network models
Iulian V Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. Building end-to-end dialogue systems using generative hierarchical neural network models. In Thirtieth AAAI Conference on Artificial Intelligence, 2016
work page 2016
-
[53]
A hierarchical latent variable encoder-decoder model for generating dialogues
Iulian Vlad Serban, Alessandro Sordoni, Ryan Lowe, Laurent Charlin, Joelle Pineau, Aaron Courville, and Yoshua Bengio. A hierarchical latent variable encoder-decoder model for generating dialogues. In Thirty-First AAAI Conference on Artificial Intelligence, 2017
work page 2017
-
[54]
Pararth Shah, Dilek Hakkani-Tur, Bing Liu, and Gokhan Tur. Bootstrapping a neural conversational agent with dialogue self-play, crowdsourcing and on-line reinforcement learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers), page...
work page 2018
-
[55]
Sentiment adaptive end-to-end dialog systems
Weiyan Shi and Zhou Yu. Sentiment adaptive end-to-end dialog systems. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1509–1519, 2018
work page 2018
-
[56]
Happybot: Generating empathetic dialogue responses by improving user experience look-ahead
Jamin Shin, Peng Xu, Andrea Madotto, and Pascale Fung. Happybot: Generating empathetic dialogue responses by improving user experience look-ahead. arXiv preprint arXiv:1906.08487, 2019
-
[57]
Where to look: a study of human-robot engagement
Candace L Sidner, Cory D Kidd, Christopher Lee, and Neal Lesh. Where to look: a study of human-robot engagement. In Proceedings of the 9th international conference on Intelligent user interfaces, pages 78–84. ACM, 2004
work page 2004
-
[58]
Robert F Stengel. Stochastic optimal control. John Wiley and Sons New York, New York, 1986
work page 1986
-
[59]
Sample-efficient actor- critic reinforcement learning with supervised data for dialogue management
Pei-Hao Su, Paweł Budzianowski, Stefan Ultes, Milica Gasic, and Steve Young. Sample-efficient actor- critic reinforcement learning with supervised data for dialogue management. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 147–157, 2017
work page 2017
-
[60]
Data-efficient off-policy policy evaluation for reinforcement learning
Philip Thomas and Emma Brunskill. Data-efficient off-policy policy evaluation for reinforcement learning. In International Conference on Machine Learning, pages 2139–2148, 2016
work page 2016
-
[61]
Linearly-solvable markov decision problems
Emanuel Todorov. Linearly-solvable markov decision problems. In Advances in neural information processing systems (NIPS), pages 1369–1376, 2007. 12
work page 2007
-
[62]
Deep reinforcement learning with double q-learning
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. In Thirtieth AAAI Conference on Artificial Intelligence, 2016
work page 2016
-
[63]
Harry Weger Jr, Gina R Castle, and Melissa C Emmett. Active listening in peer interviews: The influence of message paraphrasing on perceptions of listening skill. The Intl. Journal of Listening, 24(1):34–49, 2010
work page 2010
-
[64]
Li Zhou, Jianfeng Gao, Di Li, and Heung-Yeung Shum. The design and implementation of xiaoice, an empathetic social chatbot. arXiv preprint arXiv:1812.08989, 2018
-
[65]
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, and Anind K Dey. Maximum entropy inverse reinforcement learning. In AAAI, volume 8, pages 1433–1438. Chicago, IL, USA, 2008. 8 Appendix 8.1 Details about implicit metrics 8.1.1 Sentiment-based To compute sentiment on short texts like conversation utterances, we leverage a state-of-the-art sentiment- detect...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.