GS-QA: A Benchmark for Geospatial Question Answering
Pith reviewed 2026-05-22 02:29 UTC · model grok-4.3
The pith
GS-QA benchmark shows LLM systems handle simple spatial questions but lose accuracy on complex predicates, numeric outputs, and multi-source cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing GS-QA with its 28 templates, directional and towards predicates, numeric and aggregate output types, and explicit multi-source questions, the authors show that existing LLM pipelines achieve usable results only on the simplest spatial predicates returning entity names; accuracy drops markedly once questions demand complex spatial reasoning, numeric computation, or fusion of data from distinct sources such as maps and encyclopedic text.
What carries the argument
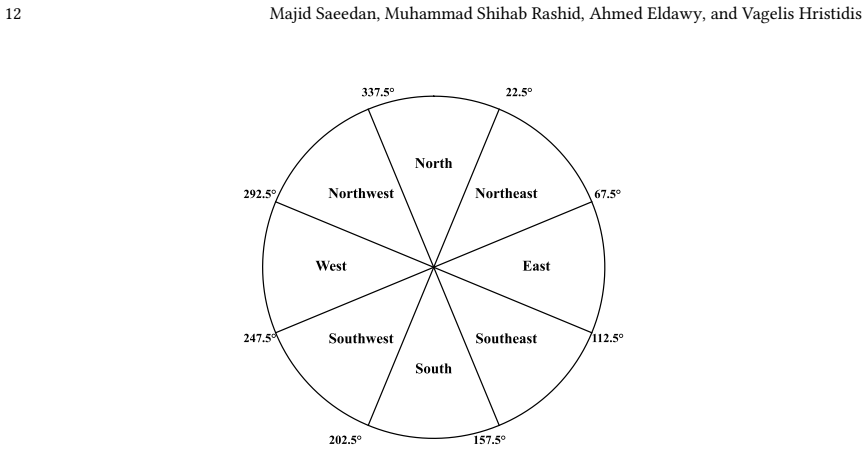
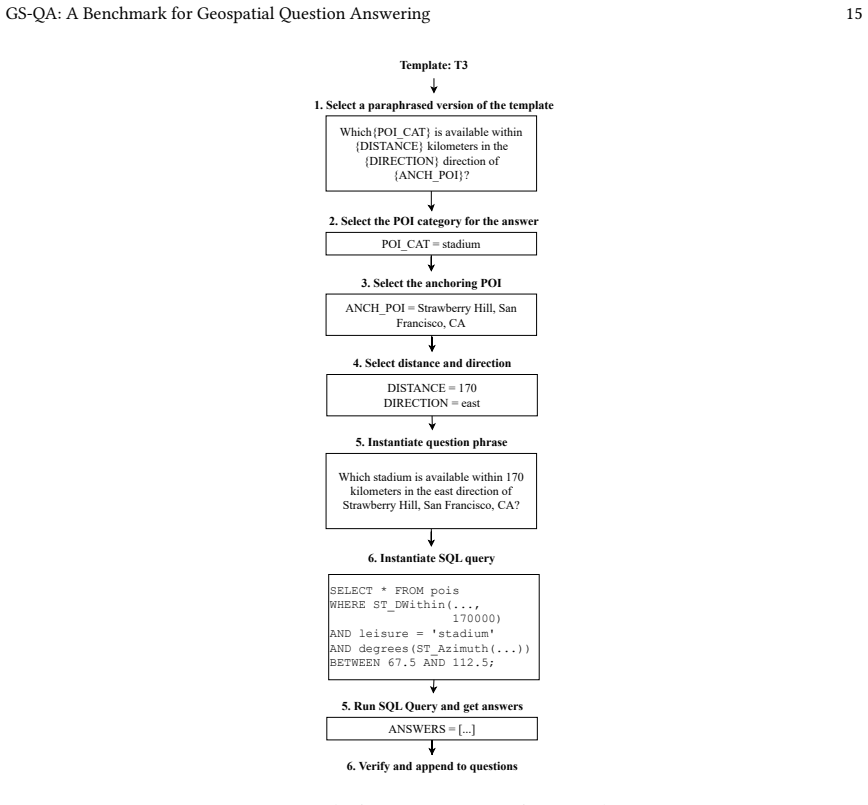
The GS-QA benchmark itself, defined by 28 question templates that produce 2,800 pairs spanning spatial predicates (including directional and towards filtering), multiple answer formats, and cross-source reasoning over OSM and Wikipedia.
If this is right
- Future QA systems need stronger native support for numeric geospatial calculations such as distances and aggregated lengths.
- Multi-source reasoning must be improved so models reliably combine spatial database facts with external textual data.
- Evaluation protocols should routinely include geospatial error measures such as distance and angular deviation in addition to standard text metrics.
- New model architectures or hybrid text-to-SQL plus retrieval approaches are needed to close the observed performance gap on complex cases.
Where Pith is reading between the lines
- Location-based consumer applications could adopt the benchmark to stress-test their query handlers before deployment.
- Adding temporal or user-contributed layers to future versions of the benchmark would expose additional failure modes in dynamic settings.
- Specialized spatial indexing or graph-based retrieval layers might complement LLMs to reduce errors on numeric and aggregate outputs.
Load-bearing premise
The 28 templates and the chosen OpenStreetMap plus Wikipedia sources are representative enough of the range of real geospatial questions people actually ask.
What would settle it
A new method that achieves consistently high accuracy across every template, including the complex-predicate, numeric-output, and multi-source subsets, would directly contradict the claim that geospatial QA remains a hard open problem.
Figures



read the original abstract
Recent advances in Large Language Models (LLMs) have led to dramatic improvements in question answering (QA). To address the challenge of evaluating QA systems, standardized benchmarks have been introduced. This work focuses on the problem of geospatial QA, where a large collection of geospatial data is available in the form of a spatial database or other forms. Existing work on geospatial QA benchmarks has various limitations, including a small number of questions, limited spatial predicates, narrow output types, and no multi-source reasoning. We present GS-QA, an extensible geospatial QA benchmark with 2,800 question-answer pairs across 28 templates on top of OpenStreetMap and Wikipedia data, covering a wide range of spatial objects, predicates (including directional and towards filtering), and answer types (entity names, locations, distances, directions, counts, and aggregated areas/lengths). A key feature of GS-QA is that some questions require combining information from multiple sources, e.g., geospatial information from OSM and factual information from Wikipedia. GS-QA includes a comprehensive evaluation methodology that combines text-based QA measures with geospatial-specific measures such as distance error and angular error. We implemented nine LLM-based geospatial QA baselines using three LLMs (GPT-4o, Claude Sonnet 4.6, and Ministral-3) with combinations of direct prompting, retrieval-augmented generation, and text-to-SQL. Our results show that existing solutions perform reasonably well on simple spatial predicates with entity name outputs, but accuracy degrades significantly for questions involving complex spatial predicates, numeric output types, and multi-source reasoning, demonstrating that geospatial QA remains a challenging open problem warranting further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GS-QA, an extensible geospatial QA benchmark consisting of 2,800 question-answer pairs generated from 28 templates over OpenStreetMap and Wikipedia data. It covers diverse spatial objects, predicates (including directional and towards filtering), and output types (entity names, locations, distances, directions, counts, aggregated areas/lengths), with some questions requiring multi-source reasoning. Nine LLM-based baselines are evaluated using GPT-4o, Claude Sonnet 4.6, and Ministral-3 with direct prompting, RAG, and text-to-SQL, showing reasonable performance on simple spatial predicates with entity name outputs but significant accuracy degradation on complex predicates, numeric outputs, and multi-source reasoning.
Significance. If the benchmark is representative, this work provides a valuable larger-scale evaluation framework that addresses limitations in prior geospatial QA benchmarks (small size, limited predicates and outputs, no multi-source). The combination of text-based QA metrics with geospatial-specific measures such as distance error and angular error is a strength for domain-appropriate assessment. The empirical results on LLM baselines highlight concrete challenges that could guide future model improvements or hybrid geospatial systems.
major comments (2)
- The central claim—that existing solutions degrade on complex predicates, numeric outputs, and multi-source reasoning, proving geospatial QA an open problem—depends on the 28 templates and OSM/Wikipedia sources being a representative proxy for real-world questions. No external validation (e.g., comparison to query logs or user studies) is provided to confirm that the hand-crafted templates capture linguistic variation, rare spatial relations, or authentic user phrasing; this is load-bearing for interpreting the degradation results as inherent task difficulty rather than template artifacts.
- Details on the exact question generation process, data filtering rules, and full metric definitions are insufficient. This limits verification of the reported accuracy drops and reproducibility of the benchmark construction and evaluation.
minor comments (2)
- Clarify the exact model name 'Claude Sonnet 4.6' (likely a version or typo) in the abstract and evaluation sections.
- Consider reporting the distribution of the 2,800 pairs across the 28 templates and any per-template performance breakdowns to better illustrate coverage and where degradation occurs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the two major comments point by point below, agreeing that both points identify areas where the manuscript can be strengthened through added detail and discussion. We plan to incorporate these changes in the revised version.
read point-by-point responses
-
Referee: The central claim—that existing solutions degrade on complex predicates, numeric outputs, and multi-source reasoning, proving geospatial QA an open problem—depends on the 28 templates and OSM/Wikipedia sources being a representative proxy for real-world questions. No external validation (e.g., comparison to query logs or user studies) is provided to confirm that the hand-crafted templates capture linguistic variation, rare spatial relations, or authentic user phrasing; this is load-bearing for interpreting the degradation results as inherent task difficulty rather than template artifacts.
Authors: We agree that external validation against real-world query logs or user studies would strengthen the claim of representativeness. Our templates were systematically derived from spatial predicate taxonomies in prior GIS and geospatial QA literature (e.g., directional, topological, and metric relations) and common OSM query patterns, but we did not conduct such validation. In the revision we will add a new subsection on template design rationale with explicit mappings to established spatial relation classifications, plus a dedicated limitations paragraph acknowledging the risk of template artifacts and calling for future user studies or log-based validation. revision: yes
-
Referee: Details on the exact question generation process, data filtering rules, and full metric definitions are insufficient. This limits verification of the reported accuracy drops and reproducibility of the benchmark construction and evaluation.
Authors: We concur that insufficient procedural detail hinders reproducibility. The current manuscript provides high-level descriptions but omits step-by-step generation logic, precise filtering thresholds (e.g., entity density, geographic scope), and complete metric formulas. We will expand the Methods section with algorithmic pseudocode for template instantiation and data filtering, explicit definitions of all metrics (including distance error as Euclidean deviation and angular error as bearing difference), and release the full generation scripts and dataset upon acceptance. revision: yes
Circularity Check
No circularity: empirical benchmark construction with independent evaluation results
full rationale
This is an empirical benchmark paper that constructs GS-QA from 28 hand-crafted templates over OSM and Wikipedia data and then directly measures LLM performance on the resulting 2,800 question-answer pairs. No mathematical derivations, equations, fitted parameters, or predictive models appear in the abstract or described methodology. The reported accuracy degradation on complex predicates, numeric outputs, and multi-source questions is a direct empirical observation on the benchmark rather than a quantity that reduces to any input by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked to justify the central claim; the benchmark and its evaluation stand as self-contained artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OpenStreetMap and Wikipedia provide reliable geospatial entities, spatial relations, and factual information suitable for benchmark construction.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present GS-QA, an extensible geospatial QA benchmark with 2,800 question-answer pairs across 28 templates on top of OpenStreetMap and Wikipedia data, covering a wide range of spatial objects, predicates (including directional and towards filtering), and answer types (entity names, locations, distances, directions, counts, and aggregated areas/lengths).
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that existing solutions perform reasonably well on simple spatial predicates with entity name outputs, but accuracy degrades significantly for questions involving complex spatial predicates, numeric output types, and multi-source reasoning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2024. GPT-4o System Card. https://openai.com/index/gpt-4o-system-card/
work page 2024
-
[2]
Nominatim: Open source geocoding with OpenStreetMap data
2024. Nominatim: Open source geocoding with OpenStreetMap data. https://nominatim.org/
work page 2024
-
[3]
2025. chroma-core/chroma. https://github.com/chroma-core/chroma original-date: 2022-10-05T17:58:44Z
work page 2025
-
[4]
Anthropic. 2026. Claude Sonnet 4.6. https://www.anthropic.com/claude/sonnet. Accessed: 2026-04-14. Manuscript submitted to ACM GS-QA: A Benchmark for Geospatial Question Answering 27
work page 2026
-
[5]
Sören Auer, Dante A. C. Barone, Cassiano Bartz, Eduardo G. Cortes, Mohamad Yaser Jaradeh, Oliver Karras, Manolis Koubarakis, Dmitry Mouromtsev, Dmitrii Pliukhin, Daniil Radyush, Ivan Shilin, Markus Stocker, and Eleni Tsalapati. 2023. The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge.Scientific Reports13, 1 (May 2023), 7240. https:/...
-
[6]
Placeholder Author. 2022. Giki: A Dataset for Geographic Question Answering. InProceedings of
work page 2022
-
[7]
Beydokhti, Matt Duckham, and Amy L
Mohammad K. Beydokhti, Matt Duckham, and Amy L. Griffin. 2021. GeoAnQu: A Dataset for Answering Geographic Analytical Questions. Transactions in GIS(2021)
work page 2021
-
[8]
Beydokhti, Yanan Tao, Matt Duckham, and Amy L
Mohammad K. Beydokhti, Yanan Tao, Matt Duckham, and Amy L. Griffin. 2024. Integrating Large Language Models and Qualitative Spatial Reasoning. InBig Data. CRC Press, 316–333
work page 2024
-
[9]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al. 2020. Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems33 (2020), 1877–1901
work page 2020
-
[10]
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric Xing, and Liang Lin. 2021. GeoQA: A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association for Computationa...
-
[11]
Wei Chen, Eric Fosler-Lussier, Ningchuan Xiao, Satyajeet Raje, Rajiv Ramnath, and Daniel Sui. 2013. A Synergistic Framework for Geographic Question Answering. In2013 IEEE Seventh International Conference on Semantic Computing. IEEE, Irvine, CA, USA, 94–99. https://doi.org/10.1109/ICSC.2013.25
-
[12]
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. 2023. TheoremQA: A Theorem-driven Question Answering Dataset. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 78...
-
[13]
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. 2018. QuAC : Question Answering in Context.CoRRabs/1808.07036 (2018). arXiv:1808.07036 http://arxiv.org/abs/1808.07036
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Cohn and Jose Hernandez-Orallo
Anthony G. Cohn and Jose Hernandez-Orallo. 2023. Dialectical Language Model Evaluation: An Initial Appraisal of the Commonsense Spatial Reasoning Abilities of LLMs.arXiv preprint arXiv:2304.11164(2023)
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of NAACL-HLT. 4171–4186
work page 2019
-
[16]
Alishiba Dsouza, Nicolas Tempelmeier, Ran Yu, Simon Gottschalk, and Elena Demidova. 2021. WorldKG: A World-Scale Geographic Knowledge Graph. InProceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM). ACM, 4475–4484. https: //doi.org/10.1145/3459637.3482023
-
[17]
Yu Feng, Linfang Ding, and Guohui Xiao. 2023. GeoQAMap – Geographic Question Answering with Maps Leveraging LLM and Open Knowledge Base. In12th International Conference on Geographic Information Science (GIScience 2023) (Leibniz International Proceedings in Informatics (LIPIcs), Vol. 277). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 28:1–28:7. http...
-
[18]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (Jan. 2024), 1132–1145. https://doi.org/10.14778/3641204.3641221
-
[19]
geofabrik 2024. Geofabrik Download Server. https://download.geofabrik.de/
work page 2024
-
[20]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2024. A Survey on LLM-as-a-Judge.arXiv preprint arXiv:2411.15594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding.Proceedings of the International Conference on Learning Representations (ICLR)(2021)
work page 2021
-
[22]
Chi Ho, Bill Yuchen Lin, Xiang Ren Chen, and Xiang Ren. 2020. Constructing Multi-hop Knowledge Paths for Complex Question Answering over Knowledge Bases. InProceedings of the 28th International Conference on Computational Linguistics (COLING). 6302–6318. https://aclanthology.org/ 2020.coling-main.554/
work page 2020
-
[23]
Yuhan Ji, Song Gao, Ying Nie, Ivan Majic, and Krzysztof Janowicz. 2025. Foundation Models for Geospatial Reasoning: Assessing the Capabilities of Large Language Models in Understanding Geometries and Topological Spatial Relations.International Journal of Geographical Information Science 39 (2025), 1–38. https://doi.org/10.1080/13658816.2025.2511227
-
[24]
Nikolaos Karalis, Georgios Mandilaras, and Manolis Koubarakis. 2019. Extending the YAGO2 knowledge graph with precise geospatial knowledge. InThe Semantic Web–ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, October 26–30, 2019, Proceedings, Part II 18. Springer, 181–197
work page 2019
-
[25]
Griffin, Yaguang Tao, Ross Purves, and Maria Vasardani
Mohammad Kazemi Beydokhti, Matt Duckham, Amy L. Griffin, Yaguang Tao, Ross Purves, and Maria Vasardani. 2024. Probabilistic qualitative spatial reasoning with applications to GeoQA.International Journal of Geographical Information Science(Dec. 2024), 1–30. https://doi.org/10.1080/ 13658816.2024.2434613
-
[26]
Sergios-Anestis Kefalidis, Dharmen Punjani, Eleni Tsalapati, Konstantinos Plas, Mariangela Pollali, Michail Mitsios, Myrto Tsokanaridou, Manolis Koubarakis, and Pierre Maret. 2023. Benchmarking Geospatial Question Answering Engines Using the Dataset GeoQuestions1089. InThe Semantic Web – ISWC 2023 (Lecture Notes in Computer Science, Vol. 14266). Springer,...
-
[27]
Sergios-Anestis Kefalidis, Dharmen Punjani, Eleni Tsalapati, Konstantinos Plas, Maria-Aggeliki Pollali, Pierre Maret, and Manolis Koubarakis
-
[28]
The question answering system geoqa2 and a new benchmark for its evaluation,
The question answering system GeoQA2 and a new benchmark for its evaluation.International Journal of Applied Earth Observation and Geoinformation134 (Nov. 2024), 104203. https://doi.org/10.1016/j.jag.2024.104203 Manuscript submitted to ACM 28 Majid Saeedan, Muhammad Shihab Rashid, Ahmed Eldawy, and Vagelis Hristidis
-
[29]
Kinetica. 2024. SQL-GPT: Natural Language to SQL for Real-Time Analytics. https://www.kinetica.com/features/sqlgpt/. Accessed: 2026-02-21
work page 2024
-
[30]
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. 2023. BioASQ-QA: A manually curated corpus for Biomedical Question Answering.Scientific Data10, 1 (March 2023), 170. https://doi.org/10.1038/s41597-023-02068-4
-
[31]
Md Tahmid Rahman Laskar, Sawsan Alqahtani, M Saiful Bari, Mizanur Rahman, Mohammad Abdullah Matin Khan, Haidar Khan, Israt Jahan, Amran Bhuiyan, Chee Wei Tan, Md Rizwan Parvez, Enamul Hoque, Shafiq Joty, and Jimmy Huang. 2024. A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations. InProce...
-
[32]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems(Van...
work page 2020
-
[33]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready?Proceedings of the VLDB Endowment17, 11 (2024), 3318–3331
work page 2024
-
[34]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2024. From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge.arXiv preprint arXiv:2411.16594(2024)
-
[35]
Haonan Li, Ehsan Hamzei, Ivan Majic, Hua Hua, Jochen Renz, Martin Tomko, Maria Vasardani, Stephan Winter, and Timothy Baldwin. 2021. Neural factoid geospatial question answering.Journal of Spatial Information Science23 (Dec. 2021), 65–90. https://doi.org/10.5311/JOSIS.2021.23.159
-
[36]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[37]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Ma Chenhao, Guoliang Li, Kevin Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs.Advances in Neural Information Processin...
work page 2023
-
[38]
Jianing Li, Xi Nan, Ming Lu, Li Du, and Shanghang Zhang. 2024. Proximity QA: Unleashing the Power of Multi-Modal Large Language Models for Spatial Proximity Analysis. https://doi.org/10.48550/arXiv.2401.17862 arXiv:2401.17862 [cs]
- [39]
-
[40]
Zhenlong Li and Huan Ning. 2023. Autonomous GIS: The Next-Generation AI-Powered GIS.International Journal of Digital Earth16, 2 (2023), 4668–4686. https://doi.org/10.1080/17538947.2023.2278895
-
[41]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[42]
Let’s Verify Step by Step.arXiv preprint arXiv:2305.20050(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. Visual spatial reasoning.Transactions of the Association for Computational Linguistics11 (2023), 635–651
work page 2023
-
[44]
Majid Saeedan, Muhammad Shihab Rashid, Ahmed Eldawy, and Vagelis Hristidis. 2025. GS-QA. https://github.com/MajidSas/GS-QA
work page 2025
-
[45]
Thomas Mandl, Fredric Gey, Giorgio Maria Di Nunzio, Nicola Ferro, and Ray R. Larson. 2008. GeoCLEF 2007: The CLEF 2007 Cross-Language Geographic Information Retrieval Track Overview. InWorking Notes of CLEF
work page 2008
- [46]
-
[47]
Mistral AI. 2025. Introducing Mistral 3. https://mistral.ai/news/mistral-3. Accessed: 2026-04-14
work page 2025
-
[48]
Ollama. 2024. nomic-embed-text Model Library. https://ollama.com/library/nomic-embed-text. Accessed: 2026-04-14
work page 2024
-
[49]
Ollama. 2025. ministral-3 Model Library. https://ollama.com/library/ministral-3:14b. Accessed: 2026-04-14
work page 2025
-
[50]
Ollama. 2025. qwen3.5:9b Model Library. https://ollama.com/library/qwen3.5:9b. Accessed: 2026-04-14
work page 2025
-
[51]
Map features - OpenStreetMap Wiki
osm 2024. Map features - OpenStreetMap Wiki. https://wiki.openstreetmap.org/wiki/Map_features
work page 2024
-
[52]
D. Punjani, K. Singh, A. Both, M. Koubarakis, I. Angelidis, K. Bereta, T. Beris, D. Bilidas, T. Ioannidis, N. Karalis, C. Lange, D. Pantazi, C. Papaloukas, and G. Stamoulis. 2018. Template-Based Question Answering over Linked Geospatial Data. InProceedings of the 12th Workshop on Geographic Information Retrieval. ACM, Seattle WA USA, 1–10. https://doi.org...
- [53]
-
[54]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
work page 2020
-
[55]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. InFirst Conference on Language Modeling. https://openreview.net/forum?id=Ti67584b98 Manuscript submitted to ACM GS-QA: A Benchmark for Geospatial Question Answering 29
work page 2024
-
[56]
Juan Sequeda, Dean Allemang, and Bryon Jacob. 2024. A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases. InProceedings of the 7th Joint Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA)(Santiago, AA, Chile)(GRADES-NDA ’2...
-
[57]
Samriddhi Singla, Yaming Zhang, and Ahmed Eldawy. 2022. OSMX: spark-based geospatial data extractor from OpenStreetMap. InProceedings of the 30th International Conference on Advances in Geographic Information Systems. ACM, Seattle Washington, 1–4. https://doi.org/10.1145/3557915.3560954
-
[58]
Alon Talmor and Jonathan Berant. 2018. The Web as a Knowledge-base for Answering Complex Questions. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). 641–651. https: //aclanthology.org/N18-1059/
work page 2018
-
[59]
Harsh Trivedi, Matt Gardner, Wen-tau Yih, Tom Kwiatkowski, and Oyvind Tafjord. 2022. Musique: Multi-hop questions via single-hop question composition.Transactions of the Association for Computational Linguistics (TACL)10 (2022), 648–662. https://aclanthology.org/2022.tacl-1.34/
work page 2022
-
[60]
Haoyu Wang, Lei Guo, Yu Liang, Lin Liu, and Jian Huang. 2025. GPT-Based Text-to-SQL for Spatial Databases.ISPRS International Journal of Geo-Information14, 8 (2025), 288. https://doi.org/10.3390/ijgi14080288
-
[61]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP). https://arxiv.org/abs/1809.09600
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
Chao Yu, Yiming Yao, Xiang Zhang, Guofeng Zhu, Yuxuan Guo, Xinyu Shao, and Ryosuke Shibasaki. 2025. Monkuu: A LLM-Powered Natural Language Interface for Geospatial Databases with Dynamic Schema Mapping.International Journal of Geographical Information Science(2025), 1–22. https://doi.org/10.1080/13658816.2025.2533322
- [63]
-
[64]
John M. Zelle and Raymond J. Mooney. 1996. Learning to Parse Database Queries Using Inductive Logic Programming. InProceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI). 1050–1055
work page 1996
-
[65]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. In International Conference on Learning Representations. https://openreview.net/forum?id=SkeHuCVFDr
work page 2020
- [66]
-
[67]
Wayne Xin Zhao, Jing Liu, Ruiyang Ren, and Ji-Rong Wen. 2024. Dense Text Retrieval Based on Pretrained Language Models: A Survey.ACM Trans. Inf. Syst.42, 4, Article 89 (Feb. 2024), 60 pages. https://doi.org/10.1145/3637870
-
[68]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, Vol. 36
work page 2023
-
[69]
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning.CoRRabs/1709.00103 (2017). Manuscript submitted to ACM
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.