SDR: Set-Distance Rewards for Radiology Report Generation
Pith reviewed 2026-06-28 19:16 UTC · model grok-4.3
The pith
Set-to-set distances between sentence embeddings provide continuous rewards that improve chest X-ray report generation over exact-match methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
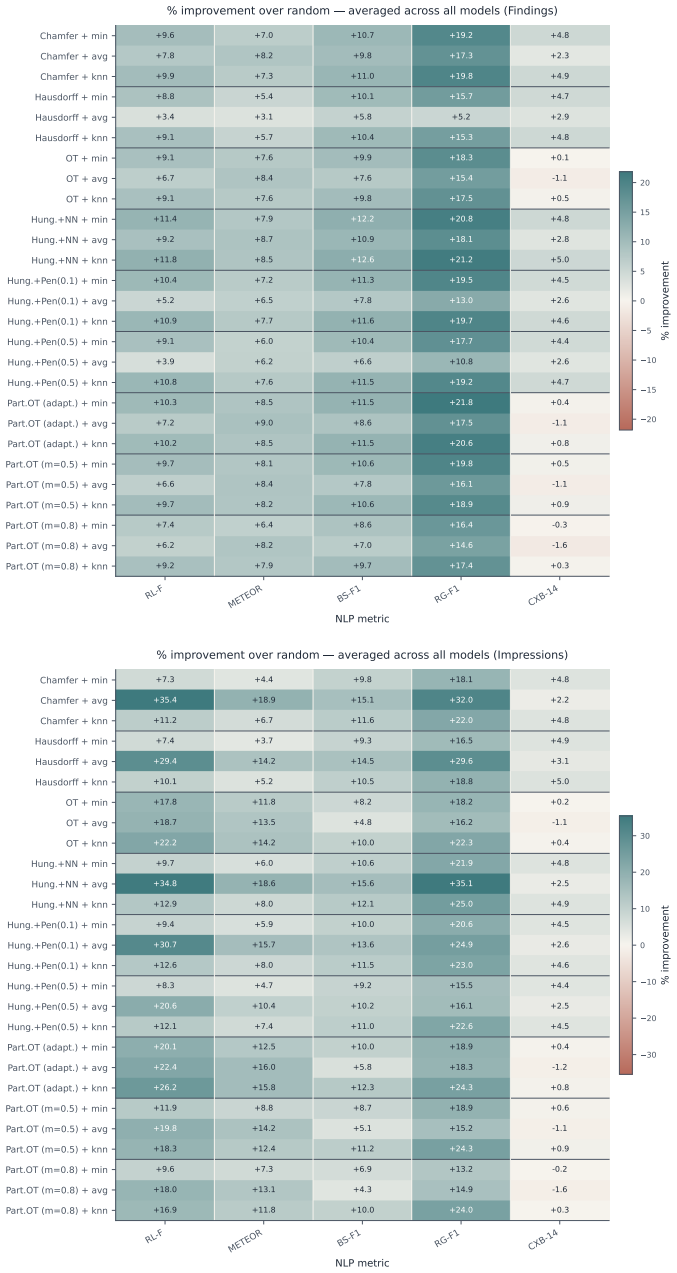
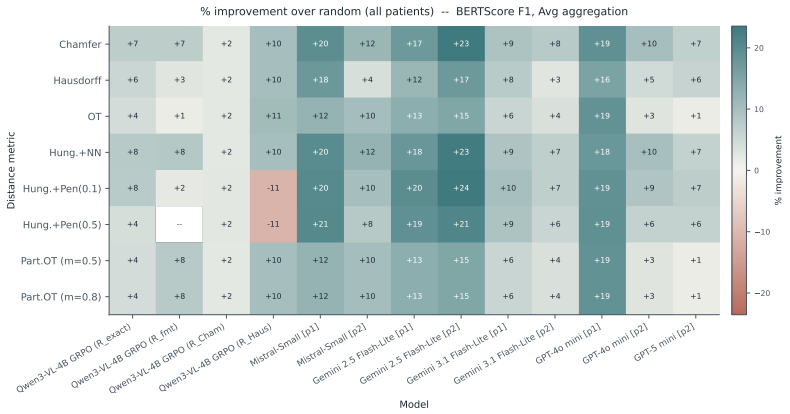
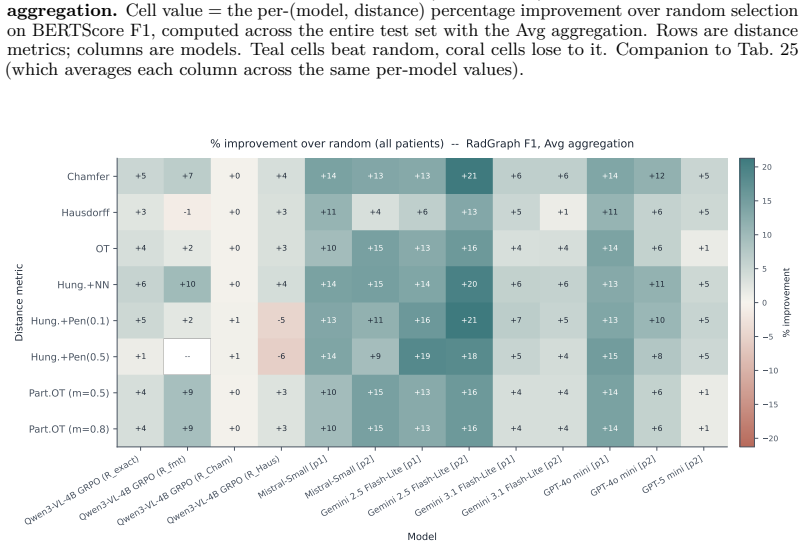
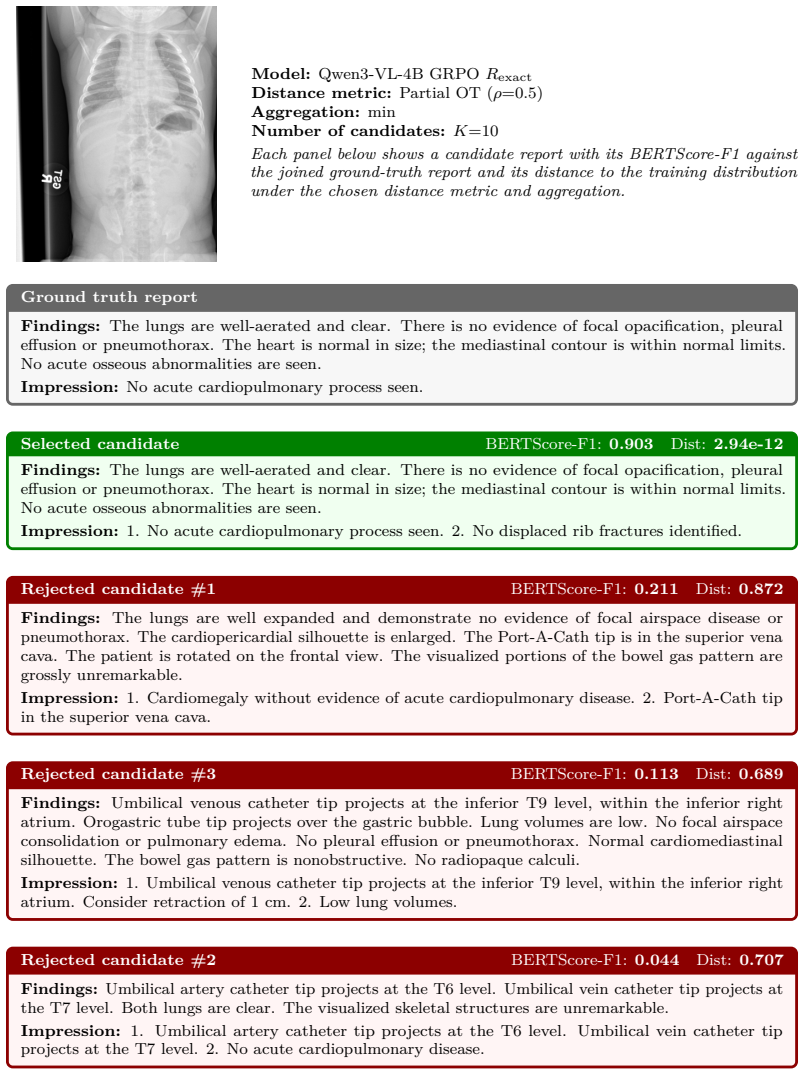
Post-training with set-to-set distance rewards via GRPO outperforms supervised fine-tuning and exact-match GRPO on BERTScore, RadGraph F1, and CheXbert F1 by average relative improvements of 6.80 percent, 7.82 percent, and 4.45 percent respectively; the identical distances also enable best-of-N selection that improves BERTScore by 16.4 percent on average and allow pruning that cuts generated tokens by more than 50 percent while preserving quality.
What carries the argument
Set-to-set distances computed on unordered collections of sentence embeddings produced by a frozen sentence transformer, used as the reward signal inside GRPO.
If this is right
- The reward signal works without retraining the embedding model and transfers across different base vision-language models.
- The same distances improve candidate selection at test time for both the trained models and closed-source LLMs.
- Mid-generation pruning guided by the distance signal reduces compute while matching the quality of full best-of-N sampling.
- Report generation can be viewed as matching unordered sets of findings rather than producing a single correct sequence.
Where Pith is reading between the lines
- The approach may extend to other generation tasks whose outputs are best described as collections of independent facts rather than ordered narratives.
- Alternative embedding models or distance functions could be swapped in to test whether the current choice is optimal.
- Because the reward is computed from a frozen model, the method decouples reward design from policy optimization and could be reused across related medical reporting tasks.
Load-bearing premise
That distances between sets of sentence embeddings from a frozen transformer serve as a valid and superior proxy for clinical report quality independent of the embedding model or distance function.
What would settle it
A side-by-side human radiologist evaluation or clinical error audit in which reports produced under set-distance rewards show no improvement or worse performance than those from exact-match rewards.
Figures



read the original abstract
Reinforcement learning with verifiable rewards has rapidly advanced reasoning in vision--language models. However, for chest X-ray report generation, the standard rewards (i.e. exact-match accuracy and step-level processes) are incompatible because the reports consist of unordered and orthogonal findings, rather than a causal reasoning chain. We address this gap with a set-based view: each report is split into sentences and embedded by a frozen sentence transformer, yielding unordered embedding sets. We propose the use of set-to-set distances between generated and reference embeddings as continuous, permutation-invariant rewards. Across two datasets and three vision--language models (Qwen3-VL-2B/4B, Gemma3-4B), post-training with set-to-set distance based rewards via GRPO consistently outperforms supervised fine-tuning and exact-match GRPO on all headline metrics (BERTScore, RadGraph F1 and CheXbert F1 by average \%6.80, \%7.82 and \%4.45 relative improvements respectively). The same set distances also enable test-time best-of-$N$ selection: scoring candidates by their distance to training-report embeddings outperforms random selection on our trained models as well as three closed-source LLMs (Mistral-Small, Gemini-2.5 Flash-Lite, GPT-4o-mini) with on average \%16.4 relative improvement on BERTScore. Used as a streaming signal, they support a more efficient form of test-time scaling: pruning low-scoring candidates mid-generation reduces generated tokens by over 50\% while preserving the Findings quality of full best-of-$N$ selection. Together these results establish set-distance rewards as a unified signal for both post-training and test-time scaling in chest X-ray report generation. Our code is publicly \href{https://anonymous.4open.science/r/Set-Distance-Rewards-CXR-BFDA}{available}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces set-distance rewards (SDR) for chest X-ray report generation: reports are split into sentences, embedded via a frozen sentence transformer, and set-to-set distances between generated and reference embedding sets serve as continuous, permutation-invariant rewards for GRPO post-training. The central claim is that this approach outperforms supervised fine-tuning and exact-match GRPO on BERTScore, RadGraph F1, and CheXbert F1 (average relative gains 6.80%, 7.82%, 4.45%) across two datasets and three VLMs (Qwen3-VL-2B/4B, Gemma3-4B); the same distances further enable test-time best-of-N selection and mid-generation pruning, with code released publicly.
Significance. If the results hold after addressing validation gaps, the work supplies a unified, practical reward signal suited to the unordered structure of radiology findings, extending RL and test-time scaling techniques to this domain. Public code availability is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the headline claim of consistent outperformance on RadGraph F1 and CheXbert F1 rests on the untested assumption that set-to-set distances on frozen sentence-transformer embeddings correlate with clinical extractors or expert judgment; no correlation analysis, ablation on embedding model, or distance function (e.g., which set metric) is referenced, leaving open whether gains reflect embedding proximity rather than report quality.
- [Abstract] Abstract: potential circularity exists because BERTScore is itself embedding-based while the reward optimizes embedding-set proximity; the comparison to exact-match GRPO does not isolate whether reported gains derive from reward density or from clinical fidelity of the proxy.
minor comments (2)
- [Abstract] Abstract: statistical significance, confidence intervals, or variance across runs are not mentioned for the reported relative improvements.
- [Abstract] Abstract: the description of the set-distance computation and its invariance properties could be expanded for clarity even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: the headline claim of consistent outperformance on RadGraph F1 and CheXbert F1 rests on the untested assumption that set-to-set distances on frozen sentence-transformer embeddings correlate with clinical extractors or expert judgment; no correlation analysis, ablation on embedding model, or distance function (e.g., which set metric) is referenced, leaving open whether gains reflect embedding proximity rather than report quality.
Authors: We agree that an explicit correlation analysis between the set-to-set distances and the clinical metrics would strengthen the presentation. The consistent gains on RadGraph F1 and CheXbert F1 (which rely on entity/relation extraction rather than embeddings) provide empirical support that the rewards improve clinical quality. In revision we will add a correlation analysis, an ablation on the sentence embedding model, and clarification of the specific set metric used in Section 3. revision: yes
-
Referee: potential circularity exists because BERTScore is itself embedding-based while the reward optimizes embedding-set proximity; the comparison to exact-match GRPO does not isolate whether reported gains derive from reward density or from clinical fidelity of the proxy.
Authors: We disagree that the overall evaluation is circular. While BERTScore is embedding-based, the headline results also report RadGraph F1 and CheXbert F1, which are not. The fact that SDR-GRPO outperforms exact-match GRPO on these independent clinical metrics indicates that the gains arise from the clinical alignment of the set-distance signal rather than reward density alone. We will revise the abstract and add explicit discussion to highlight this distinction. revision: partial
Circularity Check
No circularity: rewards defined externally via frozen embeddings, gains are measured outcomes
full rationale
The paper defines set-to-set distances on embeddings from a frozen external sentence transformer as the reward signal for GRPO. These distances are independent of the evaluation metrics (BERTScore, RadGraph F1, CheXbert F1), which are reported as post-training outcomes rather than inputs or fitted targets. No equations reduce the claimed improvements to the reward definition by construction, no parameters are fitted to subsets and relabeled as predictions, and the provided text contains no self-citations or uniqueness theorems from prior author work. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sentence embeddings from a frozen pre-trained transformer reflect semantic equivalence of medical findings sufficiently for set-distance comparison
Reference graph
Works this paper leans on
-
[1]
Towards a holistic framework for multimodal llm in 3d brain ct radiology report generation.Nature Communications, 16(1):2258, 2025
Cheng-Yi Li, Kao-Jung Chang, Cheng-Fu Yang, Hsin-Yu Wu, Wenting Chen, Hritik Bansal, Ling Chen, Yi-Ping Yang, Yu-Chun Chen, Shih-Pin Chen, et al. Towards a holistic framework for multimodal llm in 3d brain ct radiology report generation.Nature Communications, 16(1):2258, 2025
2025
-
[2]
Guangyi Liu, Yinghong Liao, Fuyu Wang, Bin Zhang, Lu Zhang, Xiaodan Liang, Xiang Wan, Shaolin Li, Zhen Li, Shuixing Zhang, et al. Medical-vlbert: Medical visual language bert for covid-19 ct report generation with alternate learning.IEEE transactions on neural networks and learning systems, 32(9):3786–3797, 2021
2021
-
[3]
Ct2rep: Automated radiology report generation for 3d medical imaging
Ibrahim Ethem Hamamci, Sezgin Er, and Bjoern Menze. Ct2rep: Automated radiology report generation for 3d medical imaging. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 476–486. Springer, 2024
2024
-
[4]
Clinically accurate chest x-ray report generation
Guanxiong Liu, Tzu-Ming Harry Hsu, Matthew McDermott, Willie Boag, Wei-Hung Weng, Peter Szolovits, and Marzyeh Ghassemi. Clinically accurate chest x-ray report generation. InMachine learning for healthcare conference, pages 249–269. PMLR, 2019
2019
-
[5]
Dynamic graph enhanced contrastive learning for chest x-ray report generation
Mingjie Li, Bingqian Lin, Zicong Chen, Haokun Lin, Xiaodan Liang, and Xiaojun Chang. Dynamic graph enhanced contrastive learning for chest x-ray report generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3334–3343, 2023
2023
-
[6]
Retrieval-based chest x-ray report generation using a pre-trained contrastive language- image model
Mark Endo, Rayan Krishnan, Viswesh Krishna, Andrew Y Ng, and Pranav Rajpurkar. Retrieval-based chest x-ray report generation using a pre-trained contrastive language- image model. InMachine learning for health, pages 209–219. PMLR, 2021
2021
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, and Brian Ichter. Chain of code: Reasoning with a language model-augmented code emulator.arXiv preprint arXiv:2312.04474, 2023
-
[10]
Juncheng Wu, Wenlong Deng, Xingxuan Li, Sheng Liu, Taomian Mi, Yifan Peng, Ziyang Xu, Yi Liu, Hyunjin Cho, Chang-In Choi, et al. Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs.arXiv preprint arXiv:2504.00993, 2025
-
[11]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, and Lu Wang. Process reward models that think. arXiv preprint arXiv:2504.16828, 2025
-
[14]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025. 11
2025
-
[15]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601, 2024
2024
-
[16]
Multi-modal understanding and generation for medical images and text via vision-language pre-training.IEEE Journal of Biomedical and Health Informatics, 26(12):6070–6080, 2022
Jong Hak Moon, Hyungyung Lee, Woncheol Shin, Young-Hak Kim, and Edward Choi. Multi-modal understanding and generation for medical images and text via vision-language pre-training.IEEE Journal of Biomedical and Health Informatics, 26(12):6070–6080, 2022
2022
-
[17]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-flamingo: a multimodal medical few-shot learner. InMachine learning for health (ML4H), pages 353–367. PMLR, 2023
2023
-
[18]
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Transactions on Medical Imaging, 2026
Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Yuheng Li, Konstantinos Psounis, and Xiaofeng Yang. Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Transactions on Medical Imaging, 2026
2026
-
[19]
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 337–347. Springer, 2025
2025
-
[20]
R- prm: Reasoning-driven process reward modeling
Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, and Shujian Huang. R- prm: Reasoning-driven process reward modeling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13449–13462, 2025
2025
-
[21]
Entropy-regularized process reward model
Hanning Zhang, Pengcheng Wang, Shizhe Diao, Yong Lin, Rui Pan, Hanze Dong, Dylan Zhang, Pavlo Molchanov, and Tong Zhang. Entropy-regularized process reward model. arXiv preprint arXiv:2412.11006, 2024
-
[22]
Lang Cao, Renhong Chen, Yingtian Zou, Chao Peng, Huacong Xu, Yuxian Wang, Wu Ning, Qian Chen, Mofan Peng, Zijie Chen, et al. More bang for the buck: Process reward modeling with entropy-driven uncertainty.arXiv preprint arXiv:2503.22233, 2025
-
[23]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019
2019
-
[24]
MIMIC- CXR Database.PhysioNet, July 2024
Alistair Johnson, Tom Pollard, Roger Mark, Seth Berkowitz, and Steven Horng. MIMIC- CXR Database.PhysioNet, July 2024. Version 2.1.0
2024
-
[25]
Xiaoman Zhang, Julián N Acosta, Josh Miller, Ouwen Huang, and Pranav Rajpurkar. Rexgradient-160k: A large-scale publicly available dataset of chest radiographs with free-text reports.arXiv preprint arXiv:2505.00228, 2025
-
[26]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024. 12 A Set-to-set distance metrics All metrics defined below operate on two finite, non-empty ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.