MimirRAG: A Multi-Agent RAG Framework for Financial Data Retrieval with Metadata Integration
Pith reviewed 2026-06-30 12:24 UTC · model grok-4.3
The pith
A multi-agent RAG system with metadata integration and table-aware chunking reaches 89.3 percent accuracy on FinanceBench financial questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
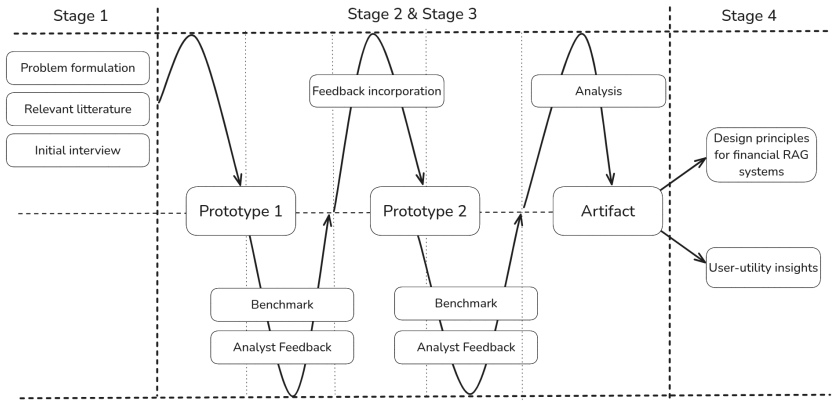
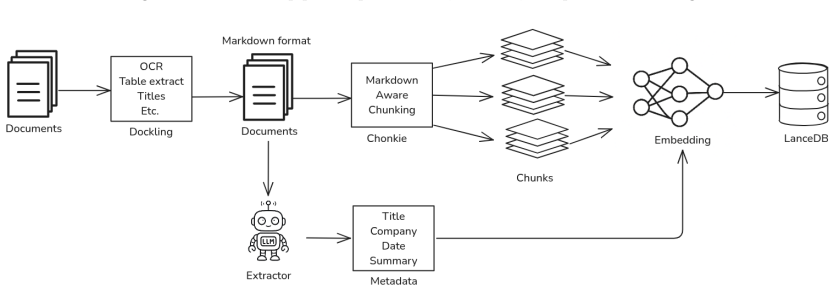
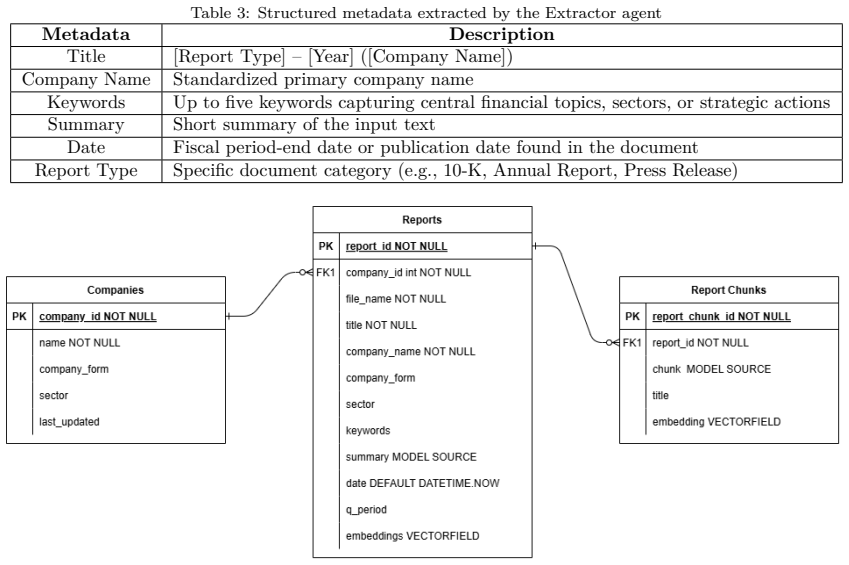
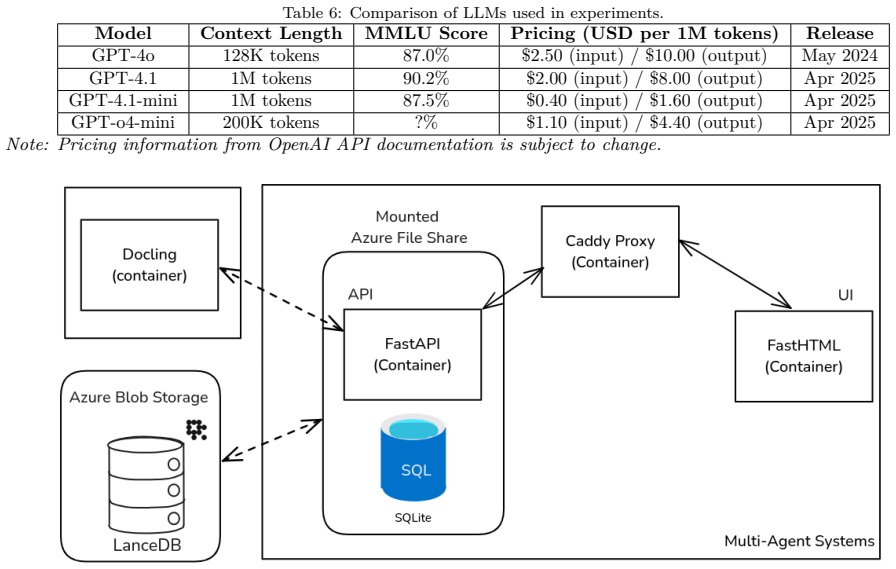
MimirRAG features a modular pipeline that performs structure-preserving parsing of PDF filings, table-aware chunking, metadata extraction, agent-based retrieval with query planning and hybrid search, validation, and context-aware generation with numerical reasoning support. The system reached 89.3 percent accuracy on FinanceBench, outperforming the original benchmark baselines. An ablation study identified metadata integration, table-aware chunking, and an agentic workflow as the three key technical enablers. Qualitative review with four financial analysts added that successful use also requires calibrated trust, comprehensive data integration, and user personalization.
What carries the argument
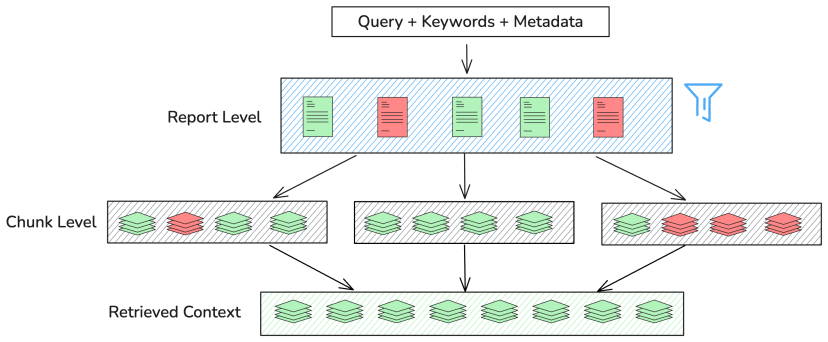
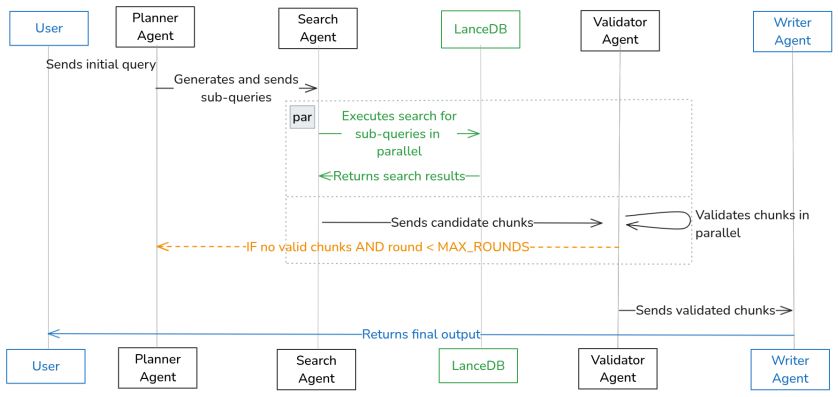
The multi-agent retrieval workflow that plans queries, performs hybrid search, and fuses results with metadata extracted during parsing of financial documents.
If this is right
- Metadata attached to document sections improves retrieval precision when filings mix text and tables.
- Table-aware chunking preserves numerical relationships that standard splitting methods break.
- Agent-based query planning handles questions that span multiple sections of a filing more effectively than single-pass retrieval.
- Validation steps before generation reduce unsupported numerical claims in financial answers.
- Human-centric elements such as personalization become necessary for practical deployment alongside the technical pipeline.
Where Pith is reading between the lines
- The same combination of metadata and agent planning could transfer to other regulated document domains that require evidence grounding.
- Adding explicit validation layers may lower hallucination rates in any high-stakes retrieval setting.
- Over time the modular design could support incremental updates when new filings arrive without full retraining.
- Testing on live market events would show whether the current accuracy holds when questions involve time-sensitive data not present in static benchmarks.
Load-bearing premise
That results on the FinanceBench dataset together with feedback from four financial analysts are enough to show the approach works in real financial analysis tasks.
What would settle it
A new test set of financial questions drawn from recent filings outside FinanceBench on which MimirRAG accuracy falls to or below standard RAG baselines.
Figures





read the original abstract
Retrieval-augmented generation (RAG) systems offer a promising approach to reduce hallucinations and improve answer accuracy in large language models (LLMs), a requirement for reliable, financial analysis where answers must be grounded in verifiable evidence from filings rather than generated from model priors. However, designing RAG systems that extract meaningful insights from mixed financial documents and integrate into analyst workflows remains challenging. This paper introduces MimirRAG (Metadata-Integrated Multi-Agent Information Retrieval), a multi-agent RAG system developed iteratively to address these challenges. MimirRAG features a modular pipeline encompassing structure-preserving parsing of PDF filings, table-aware chunking, metadata extraction, agent-based retrieval with query planning and hybrid search, validation, and context-aware generation with numerical reasoning support. Our ablation study identifies three key technical enablers for effective financial RAG: metadata integration, table-aware chunking, and an agentic workflow. MimirRAG was evaluated quantitatively using FinanceBench and qualitatively through expert validation with four financial analysts. The system achieved 89.3% accuracy on FinanceBench, outperforming the original benchmark baselines. Expert feedback highlighted that successful deployment also requires calibrated trust, comprehensive data integration, and user personalization. We conclude that combining multi-agent RAG architecture with human-centric design principles can improve the extraction of meaningful insights in financial analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MimirRAG, a multi-agent RAG system for financial document retrieval featuring structure-preserving PDF parsing, table-aware chunking, metadata extraction, agent-based retrieval with query planning and hybrid search, validation, and context-aware generation. It reports 89.3% accuracy on FinanceBench (outperforming original baselines), identifies metadata integration, table-aware chunking, and agentic workflow as key enablers via ablation, and includes qualitative expert validation with four financial analysts.
Significance. If the performance and ablation claims are substantiated with more rigorous controls and testing, the work could provide practical value for domain-specific RAG systems in finance by highlighting the role of metadata and multi-agent workflows in handling mixed text/table documents. The modular pipeline offers a concrete implementation example, though the current evaluation limits broader claims of superiority or generalization.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: The central claim of 89.3% accuracy on FinanceBench is reported without error bars, details on data splits or train/test methodology, baseline implementation specifics, or statistical significance testing on the performance improvement; this directly affects the ability to assess whether the system outperforms baselines in a robust manner.
- [Ablation study] Ablation study: The identification of the three technical enablers (metadata integration, table-aware chunking, agentic workflow) lacks quantitative isolation of their individual effects, controls for confounding variables such as prompt variations or model choice, and explicit comparison metrics, making the attribution of performance gains load-bearing but under-supported.
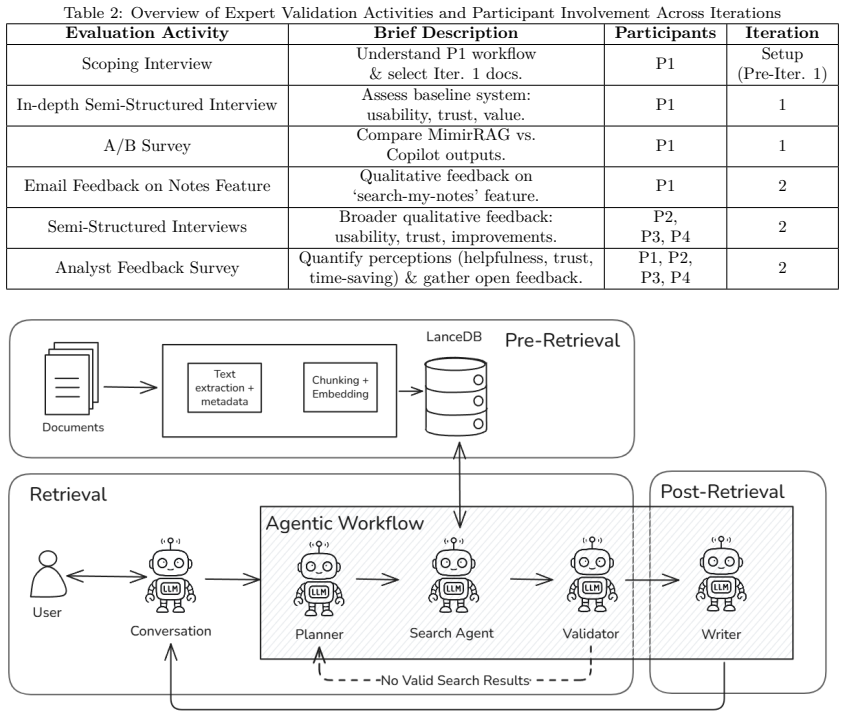
- [Expert validation] Expert validation: Reliance on feedback from only four financial analysts without quantitative metrics, sampling details, or controls for workflow variability provides insufficient evidence for claims of real-world effectiveness and generalization beyond the FinanceBench distribution.
minor comments (1)
- [Abstract] The abstract refers to 'original benchmark baselines' without naming them or providing citations, which reduces clarity on the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving the rigor of our evaluation and analysis. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The central claim of 89.3% accuracy on FinanceBench is reported without error bars, details on data splits or train/test methodology, baseline implementation specifics, or statistical significance testing on the performance improvement; this directly affects the ability to assess whether the system outperforms baselines in a robust manner.
Authors: We agree that the current reporting lacks sufficient statistical detail. In the revised manuscript we will add error bars from multiple runs with varied seeds, clarify that FinanceBench is a fixed benchmark (no custom train/test split; we evaluate on the provided test set), provide exact baseline implementation details including models and prompts, and report statistical significance tests (e.g., paired t-tests) for the observed improvements. These changes will appear in the Evaluation section and be referenced in the abstract. revision: yes
-
Referee: [Ablation study] Ablation study: The identification of the three technical enablers (metadata integration, table-aware chunking, agentic workflow) lacks quantitative isolation of their individual effects, controls for confounding variables such as prompt variations or model choice, and explicit comparison metrics, making the attribution of performance gains load-bearing but under-supported.
Authors: We will strengthen the ablation study by presenting incremental component additions with a dedicated metrics table, fixing prompts across variants to control for prompt effects, and explicitly noting that the same LLM backbone was used throughout to control for model choice. While exhaustive isolation of every possible confounder would require additional experiments beyond the current scope, these revisions will provide clearer quantitative attribution for the three enablers. revision: partial
-
Referee: [Expert validation] Expert validation: Reliance on feedback from only four financial analysts without quantitative metrics, sampling details, or controls for workflow variability provides insufficient evidence for claims of real-world effectiveness and generalization beyond the FinanceBench distribution.
Authors: We accept that the expert validation is limited in scale and detail. The revision will expand the section to describe analyst selection criteria, the interview protocol, and any quantitative elements present in the feedback. We will also add an explicit limitations paragraph noting the small sample size and positioning the validation as supplementary qualitative insight rather than primary evidence of generalization. revision: yes
Circularity Check
No circularity: empirical system evaluation on external benchmark
full rationale
The paper describes construction and evaluation of a multi-agent RAG pipeline for financial documents. Its central results are accuracy numbers obtained by running the system on the external FinanceBench benchmark and qualitative feedback from four analysts. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Ablation studies are standard removal experiments whose outcomes are measured against the same external benchmark rather than being forced by construction. The work is therefore self-contained against external data and does not reduce any claimed result to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
S. Ray, B. Srinivasan, Reducing hallucinations in large language models with custom intervention using amazon bedrock agents, amazon Web Services Blog, published November 26, 2024 (2024). URLhttps://aws.amazon.com/blogs/machine-l earning/reducing-hallucinations-in-large-l anguage-models-with-custom-intervention-usi ng-amazon-bedrock-agents/
2024
-
[3]
Sarmah, D
B. Sarmah, D. Mehta, S. Pasquali, T. Zhu, Towards reducing hallucination in extracting information from financialreportsusinglargelanguagemodels, in: Pro- ceedings of the Third International Conference on AI- ML Systems, 2023, pp. 1–5
2023
-
[4]
Impink, M
J. Impink, M. Paananen, A. Renders, Regulation- induced disclosures: evidence of information over- load?, Abacus 58 (3) (2022) 432–478
2022
-
[5]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al., Retrieval-augmented gen- eration for knowledge-intensive nlp tasks, Advances in neural information processing systems 33 (2020) 9459–9474
2020
-
[6]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, H. Wang, H. Wang, Retrieval- augmented generation for large language models: A survey, arXiv preprint arXiv:2312.10997 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
I. Iaroshev, R. Pillai, L. Vaglietti, T. Hanne, Evaluat- ing retrieval-augmented generation models for finan- cial report question and answering., Applied Sciences (2076-3417) 14 (20) (2024).doi:10.3390/app14209 318. URLhttps://doi.org/10.3390/app14209318
- [8]
- [9]
-
[10]
FinanceBench: A New Benchmark for Financial Question Answering
P. Islam, A. Kannappan, D. Kiela, R. Qian, N. Scher- rer, B. Vidgen, Financebench: A new benchmark for financial question answering, arXiv preprint arXiv:2311.11944 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
- [12]
- [13]
-
[14]
Rafiq, How ragie outperformed the financebench test,https://www.ragie.ai/blog/ragie-outperf ormed-financebench, blog post (Oct 2024)
M. Rafiq, How ragie outperformed the financebench test,https://www.ragie.ai/blog/ragie-outperf ormed-financebench, blog post (Oct 2024)
2024
-
[15]
Rafiq, How ragie outperformed the financebench test — part 2,https://www.ragie.ai/blog/how-r agie-outperformed-the-financebench-test-par t-2, blog post, Part 2 (Nov 2024)
M. Rafiq, How ragie outperformed the financebench test — part 2,https://www.ragie.ai/blog/how-r agie-outperformed-the-financebench-test-par t-2, blog post, Part 2 (Nov 2024)
2024
-
[16]
AI, Financebench performance of mafin 2.5,http s://github.com/VectifyAI/Mafin2.5-FinanceBe nch, gitHub repository (2025)
V. AI, Financebench performance of mafin 2.5,http s://github.com/VectifyAI/Mafin2.5-FinanceBe nch, gitHub repository (2025)
2025
-
[17]
FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
D. Araci, Finbert: Financial sentiment analysis with pre-trained language models, arXiv preprint arXiv:1908.10063 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[18]
S. Wu, O. Irsoy, S. Lu, V. Dabravolski, M. Dredze, S. Gehrmann, P. Kambadur, D. Rosenberg, G. Mann, Bloomberggpt: A large language model for finance (2023).arXiv:2303.17564. URLhttps://arxiv.org/abs/2303.17564
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [19]
- [20]
- [21]
-
[22]
Sarmah, D
B. Sarmah, D. Mehta, B. Hall, R. Rao, S. Patel, S. Pasquali, Hybridrag: Integrating knowledge graphs and vector retrieval augmented generation for effi- cient information extraction, in: Proceedings of the 5th ACM International Conference on AI in Finance, 2024, pp. 608–616
2024
- [23]
- [24]
- [25]
-
[26]
Taghvaei, A
F. Taghvaei, A. Elahi, Combining financial data and news articles for stock price movement prediction us- ing large language models, 2024 IEEE International Conference on Big Data (BigData) (2024) 4875–4883. URLhttps://api.semanticscholar.org/Corpus Id:273812246
2024
-
[27]
A.Singh, A.Ehtesham, S.Kumar, T.T.Khoei, Agen- ticretrieval-augmentedgeneration: Asurveyonagen- tic rag, arXiv preprint arXiv:2501.09136 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
-
[29]
Poliakov, N
M. Poliakov, N. Shvai, Multi-meta-rag: Improving rag for multi-hop queries using database filtering with llm-extracted metadata, in: International Confer- ence on Information and Communication Technolo- gies in Education, Research, and Industrial Applica- tions, Springer, 2024, pp. 334–342
2024
-
[30]
Saunders, P
M. Saunders, P. Lewis, A. Thornhill, Research Meth- ods for Business Students, 9th Edition, Pearson Edu- cation, 2023
2023
-
[31]
M. K. Sein, O. Henfridsson, S. Purao, M. Rossi, R. Lindgren, Action design research, MIS quarterly (2011) 37–56
2011
- [32]
-
[33]
Pfitzmann, C
B. Pfitzmann, C. Auer, M. Dolfi, A. S. Nassar, P. Staar, Doclaynet: A large human-annotated dataset for document-layout segmentation, in: Pro- ceedings of the 28th ACM SIGKDD conference on knowledgediscoveryanddatamining, 2022, pp.3743– 3751
2022
-
[34]
Nassar, N
A. Nassar, N. Livathinos, M. Lysak, P. Staar, Table- former: Table structure understanding with trans- formers, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2022, pp. 4614–4623
2022
-
[35]
L. Merrick, D. Xu, G. Nuti, D. Campos, Arctic- embed: Scalable, efficient, and accurate text embed- ding models, arXiv preprint arXiv:2405.05374 (2024)
- [36]
-
[37]
ToolGen: Unified Tool Retrieval and Calling via Generation
K. Enevoldsen, et al., Mmteb: Massive multilin- gual text embedding benchmark, arXiv preprint arXiv:2502.13595 (2025).doi:10.48550/arXiv.2 502.13595. URLhttps://arxiv.org/abs/2502.13595
- [38]
-
[39]
L. E. Erdogan, N. Lee, S. Kim, S. Moon, H. Fu- ruta, G. Anumanchipalli, K. Keutzer, A. Gholami, Plan-and-act: Improving planning of agents for long-horizon tasks, arXiv preprint arXiv:2503.09572 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
L. Wang, W. Xu, Y. Lan, Z. Hu, Y. Lan, R. K.- W. Lee, E.-P. Lim, Plan-and-solve prompting: Im- proving zero-shot chain-of-thought reasoning by large language models, in: A. Rogers, J. Boyd-Graber, N. Okazaki (Eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), Association for Computatio...
-
[41]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K.Narasimhan, Y.Cao, React: Synergizingreasoning and acting in language models, in: International Con- ference on Learning Representations (ICLR), 2023
2023
-
[42]
Colvin, et al., Pydantic (Apr
S. Colvin, et al., Pydantic (Apr. 2025).doi:10.528 1/zenodo.15174950
2025
- [43]
-
[44]
URLhttps://www.anthropic.com/engineering/ building-effective-agents
Anthropic, Building effective ai agents (Dec 2024). URLhttps://www.anthropic.com/engineering/ building-effective-agents
2024
-
[45]
Zhang, How we build effective agents, YouTube, presented at the AI Engineer Summit 2025, New York
B. Zhang, How we build effective agents, YouTube, presented at the AI Engineer Summit 2025, New York. [Accessed: May 14, 2025] (2025). URLhttps://www.youtube.com/watch?v=051042 _2p5E
2025
- [46]
-
[47]
J. D. Lee, K. A. See, Trust in automation: Designing for appropriate reliance, Human factors 46 (1) (2004) 50–80
2004
-
[48]
Shneiderman, Human-centered artificial intelli- gence: Reliable, safe & trustworthy, International Journal of Human–Computer Interaction 36 (6) (2020) 495–504
B. Shneiderman, Human-centered artificial intelli- gence: Reliable, safe & trustworthy, International Journal of Human–Computer Interaction 36 (6) (2020) 495–504
2020
-
[49]
European Parliament, EU AI Act: first regulation on artificial intelligence (2025). URLhttps://www.europarl.europa.eu/topics/ en/article/20230601STO93804/eu-ai-act-first -regulation-on-artificial-intelligence
- [50]
-
[51]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, I. Stoica, Judging llm-as-a-judge with mt-bench and chatbot arena, ArXiv abs/2306.05685 (2023). URLhttps://arxiv.org/pdf/2306.05685.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
J. Gu, X.Jiang, Z. Shi, H. Tan, X.Zhai, C. Xu, W. Li, Y. Shen, S. Ma, H. Liu, et al., A survey on llm-as-a- judge, arXiv preprint arXiv:2411.15594 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [53]
-
[54]
J. Ye, Y. Wang, Y. Huang, D. Chen, Q. Zhang, N. Moniz, T. Gao, W. Geyer, C. Huang, P.-Y. Chen, N. V. Chawla, X. Zhang, Justice or prejudice? quantifying biases in llm-as-a-judge, arXiv preprint arXiv:2410.02736 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, et al., Dspy: Compiling declarative language model calls into self-improving pipelines, arXiv preprint arXiv:2310.03714 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
URLhttps://www.anthropic.com/engineering/ claude-think-tool 28
Anthropic, The “think” tool: Enabling claude to stop and think (Mar 2025). URLhttps://www.anthropic.com/engineering/ claude-think-tool 28
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.