Simple vs complex temporal recurrences for video saliency prediction
Pith reviewed 2026-05-25 10:33 UTC · model grok-4.3
The pith
A simple exponential moving average matches a ConvLSTM for adding temporal information to video saliency models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
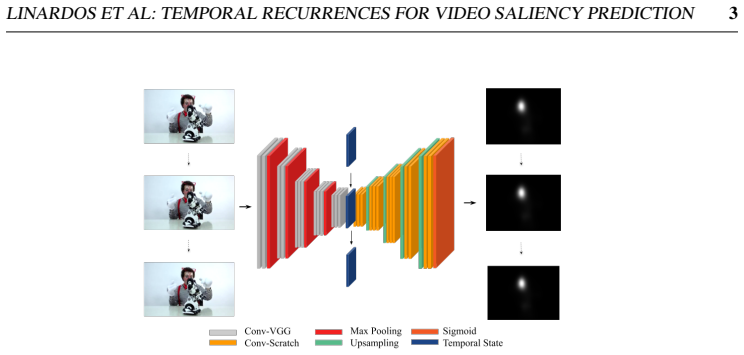
The authors demonstrate that modifying a static saliency network with either a ConvLSTM or an exponential moving average of an internal convolutional state, after pre-training on SALICON and fine-tuning on DHF1K, produces state-of-the-art video saliency predictions with both approaches yielding similar saliency maps.
What carries the argument
Exponential moving average of convolutional states, used as a simple temporal integrator in place of ConvLSTM.
Load-bearing premise
That pre-training on SALICON followed by fine-tuning on DHF1K produces a fair comparison between the two temporal modifications without differences in training or evaluation confounding the results.
What would settle it
A controlled experiment in which one modification clearly outperforms the other on DHF1K saliency metrics when both are trained and tested under identical conditions.
Figures




read the original abstract
This paper investigates modifying an existing neural network architecture for static saliency prediction using two types of recurrences that integrate information from the temporal domain. The first modification is the addition of a ConvLSTM within the architecture, while the second is a conceptually simple exponential moving average of an internal convolutional state. We use weights pre-trained on the SALICON dataset and fine-tune our model on DHF1K. Our results show that both modifications achieve state-of-the-art results and produce similar saliency maps. Source code is available at https://git.io/fjPiB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper modifies a static saliency prediction network with two temporal recurrences: a ConvLSTM and an exponential moving average (EMA) of an internal convolutional state. Weights are pre-trained on SALICON and fine-tuned on DHF1K; both variants are reported to reach state-of-the-art performance while producing similar saliency maps.
Significance. If the performance parity holds under controlled conditions, the result would indicate that a simple EMA suffices for temporal integration in video saliency, potentially allowing simpler and more efficient models than those using ConvLSTM. The release of source code aids reproducibility.
major comments (2)
- [Abstract / Methods] The central claim that both the ConvLSTM and EMA modifications achieve SOTA results and similar saliency maps rests on the assumption that the two variants received identical fine-tuning protocols on DHF1K. The abstract states only that weights were pre-trained on SALICON and fine-tuned on DHF1K; no section confirms that optimizer schedule, learning rate, epoch count, data augmentation, or early-stopping criteria were shared rather than tuned separately for each variant. This is load-bearing because unequal optimization effort could produce the observed similarity without the recurrences being equivalent.
- [Abstract / Results] No quantitative metrics, baseline comparisons, error bars, or dataset statistics are supplied in the abstract to support the SOTA assertion. The central claim cannot be evaluated for evidential support without these details in the results section or tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below in detail.
read point-by-point responses
-
Referee: [Abstract / Methods] The central claim that both the ConvLSTM and EMA modifications achieve SOTA results and similar saliency maps rests on the assumption that the two variants received identical fine-tuning protocols on DHF1K. The abstract states only that weights were pre-trained on SALICON and fine-tuned on DHF1K; no section confirms that optimizer schedule, learning rate, epoch count, data augmentation, or early-stopping criteria were shared rather than tuned separately for each variant. This is load-bearing because unequal optimization effort could produce the observed similarity without the recurrences being equivalent.
Authors: We thank the referee for highlighting this important point regarding experimental controls. Both the ConvLSTM and EMA variants were fine-tuned using an identical protocol: the same Adam optimizer, initial learning rate of 1e-4 with the same decay schedule, maximum of 20 epochs, early stopping on validation performance, and identical data augmentations. This procedure is described once in the methods and applied uniformly to both models without separate hyperparameter tuning. To make this explicit and remove any ambiguity, we will add a clarifying sentence in the methods section. revision: yes
-
Referee: [Abstract / Results] No quantitative metrics, baseline comparisons, error bars, or dataset statistics are supplied in the abstract to support the SOTA assertion. The central claim cannot be evaluated for evidential support without these details in the results section or tables.
Authors: The abstract serves as a high-level overview and does not include detailed numbers, per standard practice. Quantitative support for the SOTA claim, including AUC, NSS, CC, and SIM metrics with comparisons to baselines, is provided in Section 4 and Table 2, along with error bars from multiple runs. DHF1K dataset statistics appear in Section 3.1. We maintain that the evidential details are present in the results section and tables as required for evaluation. revision: no
Circularity Check
No circularity detected; empirical comparison relies on external datasets and standard training
full rationale
The paper describes an empirical study that modifies a static saliency network with either ConvLSTM or exponential moving average recurrence, pre-trains on SALICON, fine-tunes on DHF1K, and reports that both variants reach SOTA with similar maps. No derivation chain, first-principles prediction, or mathematical result is claimed. The central statements are experimental outcomes evaluated on held-out data; they do not reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The protocol uses publicly available external benchmarks and does not contain any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We wrap a convolutional layer with a temporal exponential moving average (EMA) operation... Et = αSt + (1 − α)Et−1
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The first modification is the addition of a ConvLSTM within the architecture
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
BIAS: A Biologically Inspired Algorithm for Video Saliency Detection
BIAS is a biologically inspired video saliency model that integrates static and motion features via retina-like detection and multi-Gaussian fitting, outperforming baselines on DHF1K and anticipating traffic accidents...
-
DiffAttn: Diffusion-Based Drivers' Visual Attention Prediction with LLM-Enhanced Semantic Reasoning
DiffAttn formulates driver visual attention prediction as a conditional diffusion-denoising task with Swin Transformer encoding, multi-scale fusion, and LLM semantic reasoning, achieving SoTA results on four datasets.
Reference graph
Works this paper leans on
-
[1]
Spatio-temporal saliency networks for dynamic saliency prediction
Cagdas Bak, Aysun Kocak, Erkut Erdem, and Aykut Erdem. Spatio-temporal saliency networks for dynamic saliency prediction. IEEE Transactions on Multimedia, 2017
work page 2017
-
[2]
Recurrent mixture density network for spatiotemporal visual attention
Loris Bazzani, Hugo Larochelle, and Lorenzo Torresani. Recurrent mixture density network for spatiotemporal visual attention. In International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[3]
Zoya Bylinskii, Tilke Judd, Aude Oliva, Antonio Torralba, and Frédo Durand. What do different evaluation metrics tell us about saliency models? IEEE transactions on pattern analysis and machine intelligence, 41(3):740–757, 2019
work page 2019
-
[4]
Long-term recurrent convo- lutional networks for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Sub- hashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convo- lutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015
work page 2015
-
[5]
Understanding the difficulty of training deep feed- forward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feed- forward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256, 2010
work page 2010
-
[6]
Going from image to video saliency: Augmenting image salience with dynamic attentional push
Siavash Gorji and James J Clark. Going from image to video saliency: Augmenting image salience with dynamic attentional push. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7501–7511, 2018
work page 2018
-
[7]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning LINARDOS ET AL: TEMPORAL RECURRENCES FOR VIDEO SALIENCY PREDICTION 11 for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[8]
Improving neural networks by preventing co-adaptation of feature detectors
Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[9]
Predicting Video Saliency with Object-to-Motion CNN and Two-layer Convolutional LSTM
Lai Jiang, Mai Xu, and Zulin Wang. Predicting video saliency with object-to-motion cnn and two-layer convolutional lstm. arXiv preprint arXiv:1709.06316, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
M. Jiang, S. Huang, J. Duan, and Q. Zhao. Salicon: Saliency in context. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1072–1080, June 2015. doi: 10.1109/CVPR.2015.7298710
-
[11]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
Marcin Marszałek, Ivan Laptev, and Cordelia Schmid. Actions in context. In CVPR 2009-IEEE Conference on Computer Vision & Pattern Recognition, pages 2929–2936. IEEE Computer Society, 2009
work page 2009
-
[13]
Actions in the eye: Dynamic gaze datasets and learnt saliency models for visual recognition
Stefan Mathe and Cristian Sminchisescu. Actions in the eye: Dynamic gaze datasets and learnt saliency models for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 37(7):1408–1424, 2015
work page 2015
-
[14]
Temporal Activity Detection in Untrimmed Videos with Recurrent Neural Networks
Alberto Montes, Amaia Salvador, Santiago Pascual, and Xavier Giro-i Nieto. Temporal activity detection in untrimmed videos with recurrent neural networks. arXiv preprint arXiv:1608.08128, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Shallow and deep convolutional networks for saliency prediction
Junting Pan, Elisa Sayrol, Xavier Giro-i Nieto, Kevin McGuinness, and Noel E O’Connor. Shallow and deep convolutional networks for saliency prediction. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 598–606, 2016
work page 2016
-
[16]
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
Junting Pan, Cristian Canton Ferrer, Kevin McGuinness, Noel E O’Connor, Jordi Torres, Elisa Sayrol, and Xavier Giro-i Nieto. Salgan: Visual saliency prediction with generative adversarial networks. arXiv preprint arXiv:1701.01081, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Some methods of speeding up the convergence of iteration methods
Boris T Polyak. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964
work page 1964
-
[18]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large- scale image recognition. arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Two-stream convolutional networks for action recognition in videos
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems, pages 568–576, 2014
work page 2014
-
[20]
Action recognition in realistic sports videos
Khurram Soomro and Amir R Zamir. Action recognition in realistic sports videos. In Computer vision in sports, pages 181–208. Springer, 2014. 12 LINARDOS ET AL: TEMPORAL RECURRENCES FOR VIDEO SALIENCY PREDICTION
work page 2014
-
[21]
On the impor- tance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George E Dahl, and Geoffrey E Hinton. On the impor- tance of initialization and momentum in deep learning. ICML (3), 28(1139-1147):5, 2013
work page 2013
-
[22]
Learning spatiotemporal features with 3d convolutional networks
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015
work page 2015
-
[23]
Deep visual attention prediction.IEEE Transactions on Image Processing, 27(5):2368–2378, 2018
Wenguan Wang and Jianbing Shen. Deep visual attention prediction.IEEE Transactions on Image Processing, 27(5):2368–2378, 2018
work page 2018
-
[24]
Revisiting video saliency: A large-scale benchmark and a new model
Wenguan Wang, Jianbing Shen, Fang Guo, Ming-Ming Cheng, and Ali Borji. Revisiting video saliency: A large-scale benchmark and a new model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4894–4903, 2018
work page 2018
-
[25]
Convolutional lstm network: A machine learning approach for precipitation nowcasting
SHI Xingjian, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang- chun Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Advances in neural information processing systems , pages 802–810, 2015
work page 2015
-
[26]
Youtube-vos: Sequence-to-sequence video object segmentation
Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. Youtube-vos: Sequence-to-sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 585–601, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.