Measuring Judgment Quality in Natural-Language Explanations: Evidence from Forecasting Tournaments
Pith reviewed 2026-07-01 01:16 UTC · model grok-4.3
The pith
LLM-scored Explanation Quality Markers predict forecast accuracy from written rationales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
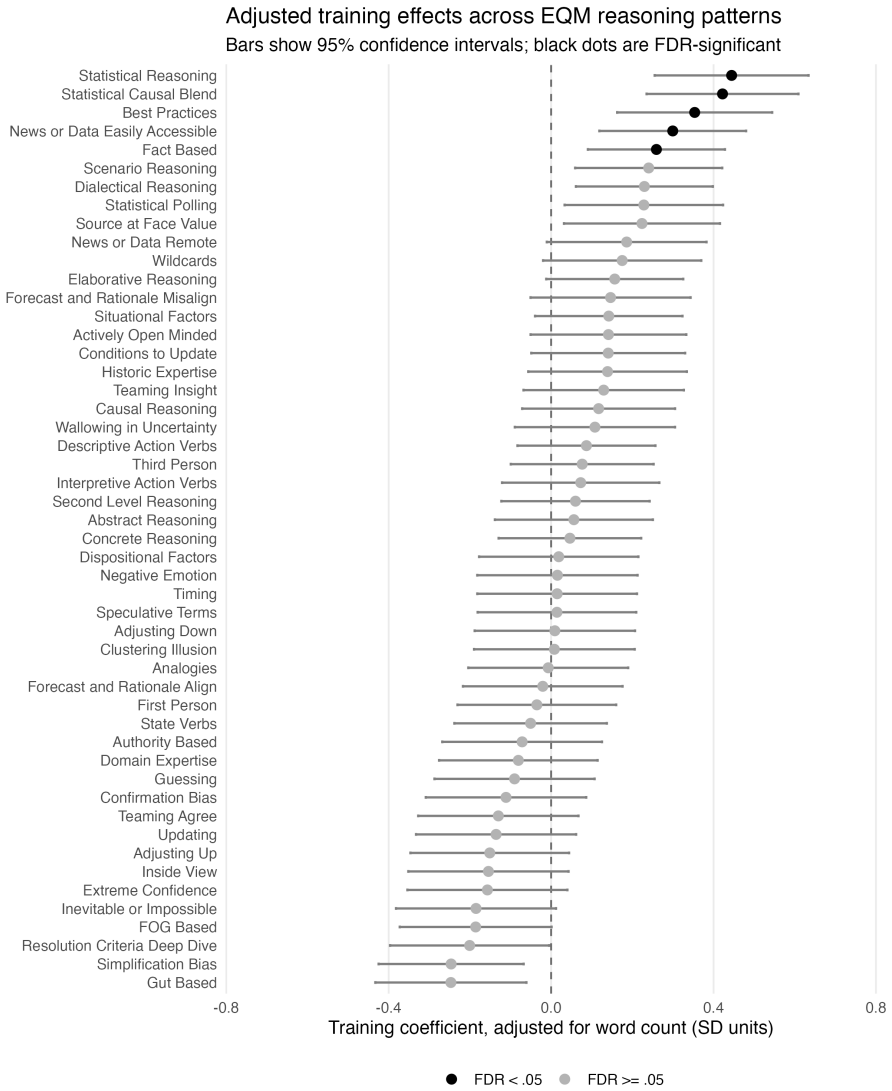
Explanation Quality Markers (EQMs) are sixty theory-guided reasoning patterns scored by LLMs that extract judgment-relevant information from written explanations, and in a pre-registered study of more than 55,000 forecast-rationale pairs these markers predict accuracy at both forecast and forecaster levels while outperforming pre-LLM methods.
What carries the argument
Explanation Quality Markers (EQMs), sixty theory-guided reasoning patterns in explanations that are scored automatically by large language models to measure judgment quality.
Load-bearing premise
LLM scoring of the sixty patterns yields reliable, low-noise measurements of reasoning quality.
What would settle it
A direct comparison where human coders score the same patterns on a subset of rationales and the human scores fail to predict accuracy while LLM scores do, or vice versa.
Figures

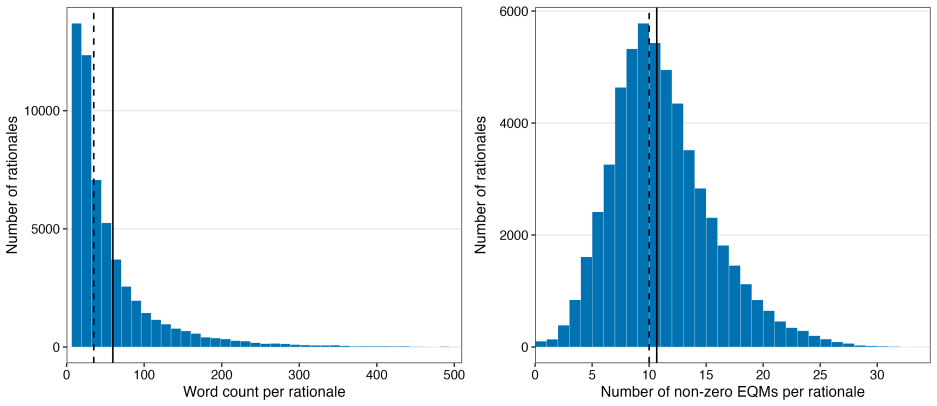
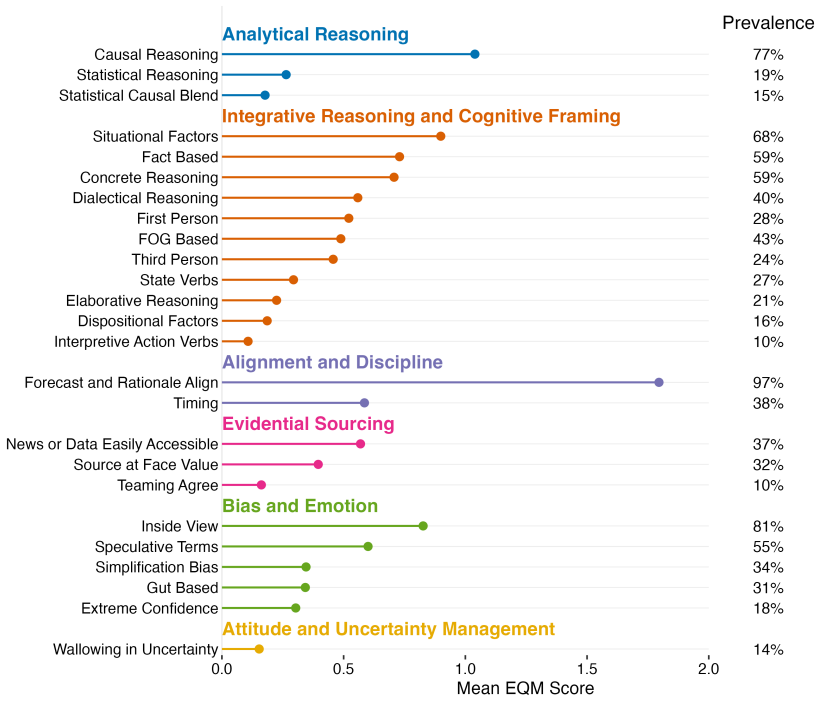
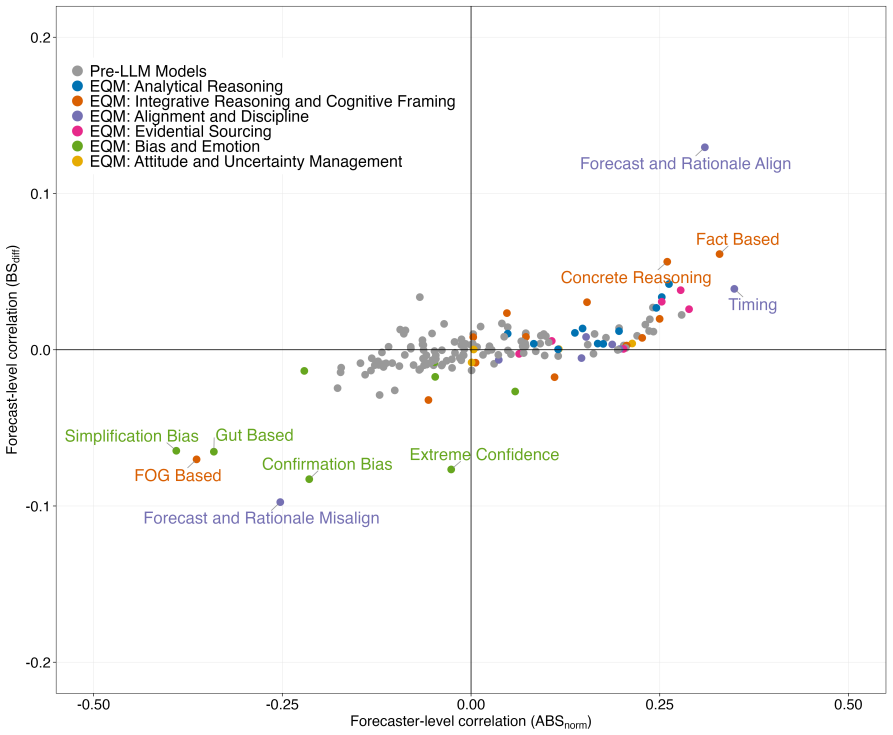
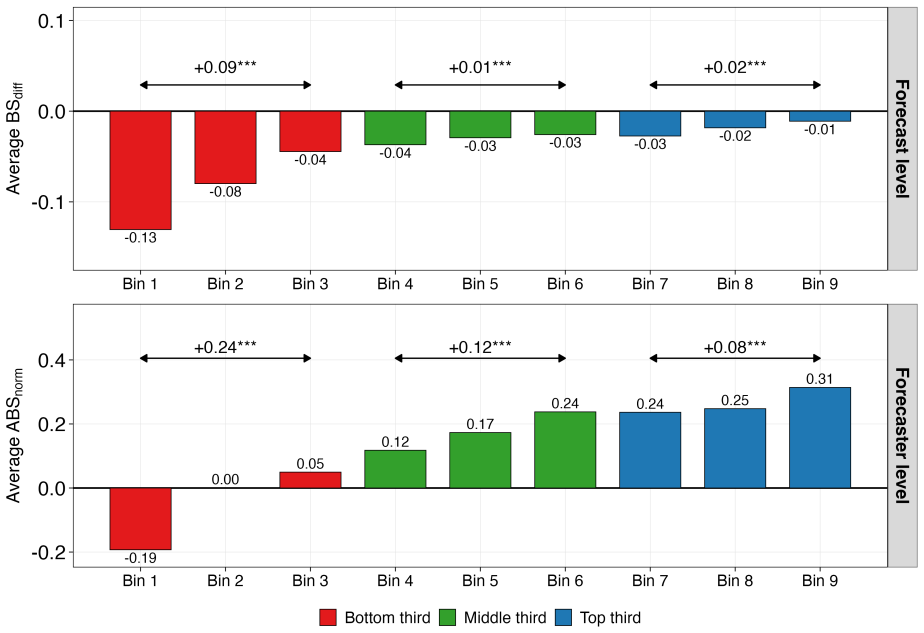
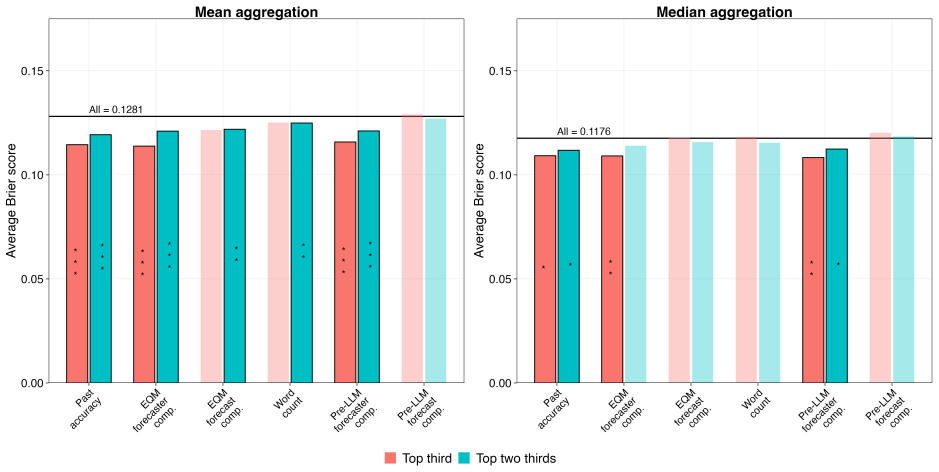
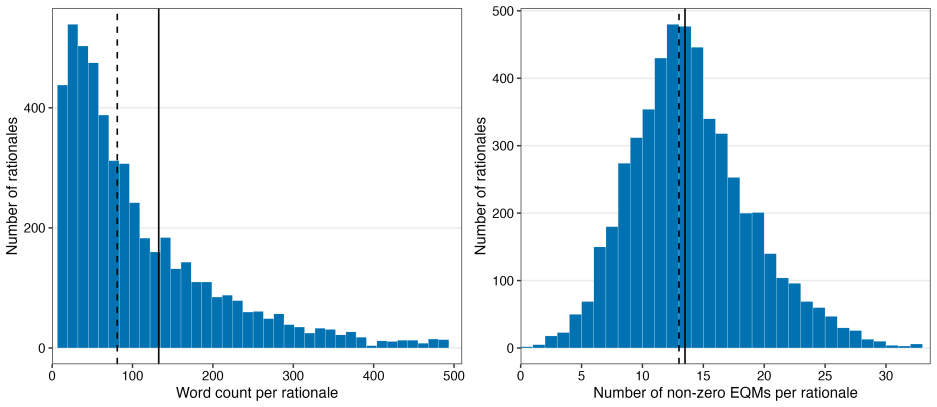
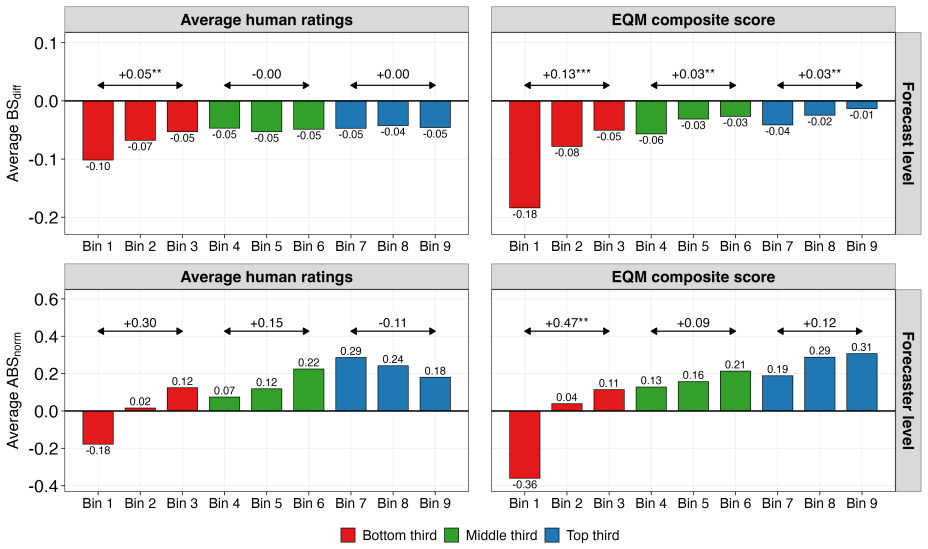


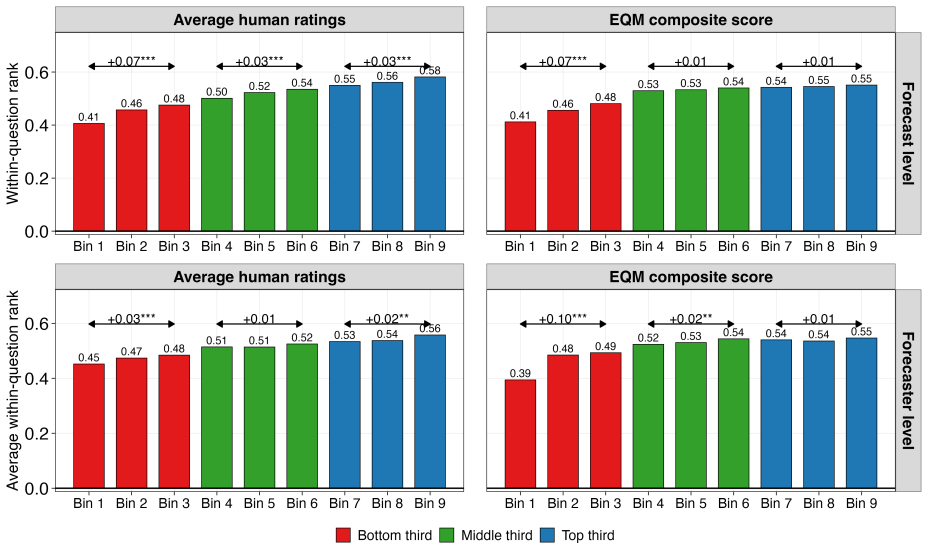






read the original abstract
Decision-makers routinely rely on expert judgments accompanied by written explanations, yet explanation quality is difficult to measure at scale. Forecasting tournaments offer a natural testing ground: probabilistic judgments are paired with natural-language rationales and scored against realized outcomes. We introduce Explanation Quality Markers (EQMs), a set of sixty theory-guided reasoning patterns scored by large language models (LLMs). In a pre-registered analysis of over 55,000 forecast-rationale pairs from a multiyear forecasting tournament, EQMs predict accuracy at both the forecast and forecaster levels, consistently outperforming pre-LLM text-analysis methods. More than 90% of statistically significant pattern-level EQM-accuracy correlations match our directional hypotheses. The signal is asymmetric: EQMs identify likely underperformers more reliably than they distinguish the very best forecasters. Benchmarked against traditional indicators of forecasting skill, EQMs are the strongest predictor at the forecast level and competitive at the forecaster level, though weaker than prior accuracy. Human ratings of rationale quality are less consistently correlated with accuracy and place disproportionate weight on rationale length. Results transfer to an independent forecasting study. EQMs provide a scalable, interpretable method for extracting judgment-relevant information from written explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Explanation Quality Markers (EQMs), a set of sixty theory-guided reasoning patterns scored by LLMs, and reports a pre-registered analysis of over 55,000 forecast-rationale pairs from multiyear forecasting tournaments showing that EQM scores predict accuracy at both the forecast and forecaster levels, consistently outperforming pre-LLM text-analysis methods, with more than 90% of statistically significant pattern-level correlations matching directional hypotheses. The signal is asymmetric (stronger for identifying underperformers), EQMs are the strongest predictor at the forecast level when benchmarked against traditional skill indicators, human ratings of rationale quality correlate less consistently with accuracy and emphasize length, and results transfer to an independent study.
Significance. If the LLM-based measurements prove reliable, the work supplies a scalable, interpretable approach for extracting judgment-relevant information from natural-language explanations, with potential applications in AI-supported decision systems and expert evaluation. The pre-registration, directional hypotheses, large sample size, and transfer result are methodological strengths that anchor the empirical claims.
major comments (2)
- [Abstract] Abstract: The headline results rest on LLM-assigned scores for the 60 EQMs constituting reliable, low-noise measures of reasoning quality. The abstract states only that LLMs score the patterns and provides no human-coder agreement statistics, inter-model consistency checks, or prompt-robustness results. This is load-bearing for the central claim because correlations with forecast accuracy (and the 90% directional match rate) could arise from LLM artifacts such as length or fluency biases rather than the intended constructs.
- [Abstract] Abstract and results sections: The paper reports that human ratings of rationale quality are less consistently correlated with accuracy than EQMs and place disproportionate weight on length, yet it does not describe whether these human ratings were used to validate the LLM scoring procedure or to calibrate the EQM prompts. Without such linkage, the superiority claim over human ratings does not directly address measurement validity of the LLM step.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of measurement validity for the LLM-scored EQMs. We address the two major comments below, providing additional context from the manuscript while agreeing to strengthen the abstract where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline results rest on LLM-assigned scores for the 60 EQMs constituting reliable, low-noise measures of reasoning quality. The abstract states only that LLMs score the patterns and provides no human-coder agreement statistics, inter-model consistency checks, or prompt-robustness results. This is load-bearing for the central claim because correlations with forecast accuracy (and the 90% directional match rate) could arise from LLM artifacts such as length or fluency biases rather than the intended constructs.
Authors: The manuscript's Methods and Appendix sections detail the theory-guided prompt design for each EQM, report inter-model consistency across GPT-4 and Claude-3 (with agreement rates above 0.75 for most markers), and include robustness checks varying prompt phrasing and temperature. We also include length as a covariate in all regressions to address fluency biases. The 90% directional hypothesis match rate further reduces the plausibility of artifact-driven results, as systematic length or fluency biases would not align with pre-registered predictions derived from judgment research. We will revise the abstract to briefly note inter-model consistency and length controls. revision: partial
-
Referee: [Abstract] Abstract and results sections: The paper reports that human ratings of rationale quality are less consistently correlated with accuracy than EQMs and place disproportionate weight on length, yet it does not describe whether these human ratings were used to validate the LLM scoring procedure or to calibrate the EQM prompts. Without such linkage, the superiority claim over human ratings does not directly address measurement validity of the LLM step.
Authors: Human ratings were collected as a separate benchmark to contrast with EQMs, not as a validation target or calibration source. EQM validity rests on their theory-derived definitions and direct prediction of objective forecast accuracy (the ground truth), plus the pre-registered directional hypothesis tests. Using human ratings for calibration would have risked circularity, as the paper shows humans overweight length and correlate less with accuracy. The LLM step is instead validated by outcome correlations and cross-model stability rather than alignment with potentially flawed human judgments. revision: no
Circularity Check
No significant circularity; empirical correlations are externally anchored
full rationale
The paper reports pre-registered empirical correlations between LLM-scored EQMs and realized forecast accuracy across 55,000+ pairs, with directional hypotheses serving as an external benchmark and no equations or fitted parameters that reduce the accuracy measure to a quantity defined from the same data. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the central results remain falsifiable against held-out outcomes and independent studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to score the presence of theory-guided reasoning patterns in natural language with sufficient consistency for downstream correlation analysis.
invented entities (1)
-
Explanation Quality Markers (EQMs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , doi =
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei , booktitle =. 2024 , doi =
2024
-
[2]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =
X-eval: Generalizable multi-aspect text evaluation via augmented instruction tuning with auxiliary evaluation aspects , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[3]
Computational Linguistics , volume =
Can large language models transform computational social science? , author =. Computational Linguistics , volume =. 2024 , doi =
2024
-
[4]
Proceedings of the National Academy of Sciences , volume =
Gilardi, Fabrizio and Alizadeh, Meysam and Kubli, Ma. Proceedings of the National Academy of Sciences , volume =. 2023 , publisher =
2023
-
[5]
Advances in neural information processing systems , volume =
Judging llm-as-a-judge with mt-bench and chatbot arena , author =. Advances in neural information processing systems , volume =
-
[6]
, journal =
Halterman, Andrew and Keith, Katherine A. , journal =. Codebook. 2026 , publisher =
2026
-
[7]
Can You Trust
Schroeder, Kayla and Wood-Doughty, Zach , journal =. Can You Trust
-
[8]
Journal of Computational Social Science , volume =
Prompt selection matters: enhancing text annotations for social sciences with large language models , author =. Journal of Computational Social Science , volume =. 2025 , publisher =
2025
-
[9]
Proceedings of the International AAAI Conference on Web and Social Media , volume =
What's in a Prompt?: A Large-Scale Experiment to Assess the Impact of Prompt Design on the Compliance and Accuracy of LLM-Generated Text Annotations , author =. Proceedings of the International AAAI Conference on Web and Social Media , volume =. 2025 , doi =
2025
-
[10]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Large language models are not fair evaluators , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[11]
Workshop on Challenges in Deployable Generative AI at the 40th International Conference on Machine Learning (
Calibrating Language Models via Augmented Prompt Ensembles , author =. Workshop on Challenges in Deployable Generative AI at the 40th International Conference on Machine Learning (. 2023 , address =
2023
-
[12]
Deterministic
Non-Determinism of “Deterministic” LLM System Settings in Hosted Environments , author =. Proceedings of the 5th Workshop on Evaluation and Comparison of NLP Systems , pages =. 2025 , doi =
2025
-
[13]
Statistical Power Analysis for the Behavioral Sciences , author =
-
[14]
Operations Research , volume =
Evaluating Quantile Assessments , author =. Operations Research , volume =. 2009 , doi =
2009
-
[15]
Biometrics , volume =
The Measurement of Observer Agreement for Categorical Data , author =. Biometrics , volume =. 1977 , doi =
1977
-
[16]
Biochemia Medica , volume =
Interrater Reliability: The Kappa Statistic , author =. Biochemia Medica , volume =. 2012 , doi =
2012
-
[17]
and Van Bavel, Jay J
Rathje, Steve and Mirea, Dan-Mircea and Sucholutsky, Ilia and Marjieh, Raja and Robertson, Claire E. and Van Bavel, Jay J. , journal =. 2024 , doi =
2024
-
[18]
Duckworth, Angela , title =
-
[19]
and Ashokkumar, Ashwini and Seraj, Sarah and Pennebaker, James W
Boyd, Ryan L. and Ashokkumar, Ashwini and Seraj, Sarah and Pennebaker, James W. , institution =. The Development and Psychometric Properties of
-
[20]
International Journal of Forecasting , volume=
What do forecasting rationales reveal about thinking patterns of top geopolitical forecasters? , author=. International Journal of Forecasting , volume=. 2022 , publisher=
2022
-
[21]
Judgment and Decision Making , volume=
Coherence of probability judgments from uncertain evidence: Does ACH help? , author=. Judgment and Decision Making , volume=. 2020 , publisher=
2020
-
[22]
International Journal of Forecasting , volume =
Effective Forecasting and Judgmental Adjustments: An Empirical Evaluation and Strategies for Improvement in Supply-Chain Planning , author =. International Journal of Forecasting , volume =. 2009 , doi =
2009
-
[23]
Journal of Personality and Social Psychology , volume =
Two Ways to Be Complex and Why They Matter: Implications for Attitude Strength and Lying , author =. Journal of Personality and Social Psychology , volume =. 2008 , doi =
2008
-
[24]
2013 , note =
Calculation for the Test of the Difference Between Two Dependent Correlations With One Variable in Common , author =. 2013 , note =
2013
-
[25]
Psychological Bulletin , volume =
Tests for Comparing Elements of a Correlation Matrix , author =. Psychological Bulletin , volume =. 1980 , doi =
1980
-
[26]
Superforecasting: The Art and Science of Prediction , author =
-
[27]
Behavior Research Methods , volume =
Shadows of Wisdom: Classifying Meta-Cognitive and Morally Grounded Narrative Content via Large Language Models , author =. Behavior Research Methods , volume =. 2024 , doi =
2024
-
[28]
2024 , note =
The Forecasting Proficiency Test: A General Use Assessment of Forecasting Ability , author =. 2024 , note =
2024
-
[29]
Organizational Behavior and Human Decision Processes , volume =
Small Steps to Accuracy: Incremental Belief Updaters Are Better Forecasters , author =. Organizational Behavior and Human Decision Processes , volume =. 2020 , doi =
2020
-
[30]
Monthly Weather Review , volume =
Verification of Forecasts Expressed in Terms of Probability , author =. Monthly Weather Review , volume =. 1950 , doi =
1950
-
[31]
Judgment and Decision Making , volume =
Accountability and Adaptive Performance Under Uncertainty: A Long-Term View , author =. Judgment and Decision Making , volume =. 2017 , doi =
2017
-
[32]
Judgment and Decision Making , volume =
Developing Expert Political Judgment: The Impact of Training and Practice on Judgmental Accuracy in Geopolitical Forecasting Tournaments , author =. Judgment and Decision Making , volume =. 2016 , doi =
2016
-
[33]
Political Psychology , volume =
Automated Integrative Complexity , author =. Political Psychology , volume =. 2014 , doi =
2014
-
[34]
Econometrica , volume =
Kahneman, Daniel and Tversky, Amos , title =. Econometrica , volume =. 1979 , doi =
1979
-
[35]
Thinking, Fast and Slow , author =
-
[36]
and Budescu, David V
Kelly, Megan O. and Budescu, David V. and Dhami, Mandeep and Mandel, David R. , title =. Judgment and Decision Making , volume =. 2025 , doi =
2025
-
[37]
and Irwin, Daniel and Dhami, Mandeep K
Mandel, David R. and Irwin, Daniel and Dhami, Mandeep K. and Budescu, David V. , title =. Journal of Behavioral Decision Making , volume =. 2023 , doi =
2023
-
[38]
Psychological Science , volume =
Psychological Strategies for Winning a Geopolitical Forecasting Tournament , author =. Psychological Science , volume =. 2014 , doi =
2014
-
[39]
, author=
The psychology of intelligence analysis: drivers of prediction accuracy in world politics. , author=. Journal of experimental psychology: applied , volume=. 2015 , publisher=
2015
-
[40]
Perspectives on Psychological Science , volume =
Identifying and Cultivating Superforecasters as a Method of Improving Probabilistic Predictions , author =. Perspectives on Psychological Science , volume =. 2015 , doi =
2015
-
[41]
Judgment and Decision Making , volume =
How Generalizable Is Good Judgment? A Multi-Task, Multi-Benchmark Study , author =. Judgment and Decision Making , volume =. 2017 , doi =
2017
-
[42]
Management Science , volume =
Confidence Calibration in a Multiyear Geopolitical Forecasting Competition , author =. Management Science , volume =. 2017 , doi =
2017
-
[43]
and Boyd, Ryan L
Pennebaker, James W. and Boyd, Ryan L. and Jordan, Kayla and Blackburn, Kate , institution =. The Development and Psychometric Properties of
-
[44]
International Journal of Forecasting , volume =
Combining Multiple Probability Predictions Using a Simple Logit Model , author =. International Journal of Forecasting , volume =. 2014 , doi =
2014
-
[45]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , editor =
Assessing Objective Recommendation Quality through Political Forecasting , author =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , editor =. 2017 , month = sep, doi =
2017
-
[46]
Current Directions in Psychological Science , volume =
Forecasting Tournaments: Tools for Increasing Transparency and Improving the Quality of Debate , author =. Current Directions in Psychological Science , volume =. 2014 , doi =
2014
-
[47]
Expert Political Judgment: How Good Is It? How Can We Know? , author =
-
[48]
Science , volume =
Judgment Under Uncertainty: Heuristics and Biases , author =. Science , volume =. 1974 , doi =
1974
-
[49]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , editor =
Measuring Forecasting Skill from Text , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , editor =. 2020 , month = jul, doi =
2020
-
[50]
Journal of Experimental Psychology: Human Perception and Performance , volume =
Knowing with Certainty: The Appropriateness of Extreme Confidence , author =. Journal of Experimental Psychology: Human Perception and Performance , volume =. 1977 , doi =
1977
-
[51]
Behavioral and Brain Sciences , volume =
Individual Differences in Reasoning: Implications for the Rationality Debate? , author =. Behavioral and Brain Sciences , volume =. 2000 , doi =
2000
-
[52]
Review of General Psychology , volume =
Confirmation Bias: A Ubiquitous Phenomenon in Many Guises , author =. Review of General Psychology , volume =. 1998 , doi =
1998
-
[53]
Psychological Review , volume =
On the Psychology of Prediction , author =. Psychological Review , volume =. 1973 , doi =
1973
-
[54]
International Journal of Forecasting , volume =
Fast and Frugal Forecasting , author =. International Journal of Forecasting , volume =. 2009 , doi =
2009
-
[55]
Psychological Review , volume =
Construal-Level Theory of Psychological Distance , author =. Psychological Review , volume =. 2010 , doi =
2010
-
[56]
Thinking and Deciding , author =
-
[57]
The Journal of Politics , volume =
What Makes Foreign Policy Teams Tick: Explaining Variation in Group Performance at Geopolitical Forecasting , author =. The Journal of Politics , volume =. 2019 , doi =
2019
-
[58]
Judgment and Decision Making , volume =
Forecasting Forecaster Accuracy: Contributions of Past Performance and Individual Differences , author =. Judgment and Decision Making , volume =. 2021 , doi =
2021
-
[59]
, title =
Morrison, Donald G. , title =. Journal of the American Statistical Association , volume =. 1972 , doi =
1972
-
[60]
, title =
Murphy, Allan H. , title =. Journal of Applied Meteorology , volume =. 1973 , doi =
1973
-
[62]
, title =
Stanovich, Keith E. , title =. Thinking & Reasoning , volume =. 2018 , doi =
2018
-
[63]
Journal of the American Statistical Association , volume=
Strictly Proper Scoring Rules, Prediction, and Estimation , author=. Journal of the American Statistical Association , volume=. 2007 , doi=
2007
-
[64]
Tetlock and Siegfried Streufert , title =
Peter Suedfeld and Philip E. Tetlock and Siegfried Streufert , title =. Motivation and Personality: Handbook of Thematic Content Analysis , editor =. 1992 , publisher =
1992
-
[65]
Journal of Conflict Resolution , volume =
Peter Suedfeld and Philip Tetlock , title =. Journal of Conflict Resolution , volume =. 1977 , month = mar, doi =
1977
-
[66]
Baker-Brown and E
G. Baker-Brown and E. J. Ballard and S. Bluck and B. de Vries and P. Suedfeld and P. E. Tetlock , title =. Motivation and Personality: Handbook of Thematic Content Analysis , editor =. 1992 , publisher =
1992
-
[68]
2009 , publisher=
The Elements of Statistical Learning: Data Mining, Inference, and Prediction , author=. 2009 , publisher=
2009
-
[69]
Barker, Jessica and Karger, Ezra and Himmelstein, Mark and Budescu, David and Benjamin, Daniel M. , title =. 2025 , month = mar, day =. doi:10.17605/OSF.IO/FM7VJ , url =
-
[70]
2026 , month = apr, day =
Introducing. 2026 , month = apr, day =
2026
-
[71]
Prompt selection matters: enhancing text annotations for social sciences with large language models
Louis Abraham, Charles Arnal, and Antoine Marie. Prompt selection matters: enhancing text annotations for social sciences with large language models. Journal of Computational Social Science, 8 0 (3): 0 73, 2025. doi:10.1007/s42001-025-00388-6
-
[72]
Introducing Claude Opus 4.7 , April 2026
Anthropic . Introducing Claude Opus 4.7 , April 2026. URL https://www.anthropic.com/news/claude-opus-4-7. Accessed 2026-05-05. API pricing: \ 5/\ 25 per million input/output tokens; 50\
2026
-
[73]
Pavel Atanasov, Jens Witkowski, Lyle Ungar, Barbara Mellers, and Philip E. Tetlock. Small steps to accuracy: Incremental belief updaters are better forecasters. Organizational Behavior and Human Decision Processes, 160: 0 19--35, 2020. doi:10.1016/j.obhdp.2020.02.001
-
[74]
u re, Zhe Wu, Lixinyu Xu, and Breck Baldwin. Non-determinism of “deterministic
Berk At l, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan T \"u re, Zhe Wu, Lixinyu Xu, and Breck Baldwin. Non-determinism of “deterministic” llm system settings in hosted environments. In Proceedings of the 5th Workshop on Evaluation and Comparison of NLP Systems, pag...
-
[75]
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, and Libby Hemphill. What's in a prompt?: A large-scale experiment to assess the impact of prompt design on the compliance and accuracy of llm-generated text annotations. In Proceedings of the International AAAI Conference on Web and Social Media, volume 19, pages 122--145, 2025. doi:10.1609/i...
-
[76]
G. Baker-Brown, E. J. Ballard, S. Bluck, B. de Vries, P. Suedfeld, and P. E. Tetlock. The conceptual/integrative complexity scoring manual. In Charles P. Smith, editor, Motivation and Personality: Handbook of Thematic Content Analysis, pages 401--418. Cambridge University Press, Cambridge, 1992. doi:10.1017/CBO9780511527937.029
-
[77]
Benjamin
Jessica Barker, Ezra Karger, Mark Himmelstein, David Budescu, and Daniel M. Benjamin. Team D ynamics: An experiment testing how group size and information sharing affect forecasting accuracy, March 2025. URL https://osf.io/fm7vj
2025
-
[78]
Thinking and Deciding
Jonathan Baron. Thinking and Deciding. Cambridge University Press, 4 edition, 2008
2008
-
[79]
Boyd, Ashwini Ashokkumar, Sarah Seraj, and James W
Ryan L. Boyd, Ashwini Ashokkumar, Sarah Seraj, and James W. Pennebaker. The development and psychometric properties of LIWC -22. Technical report, University of Texas at Austin, Austin, TX, 2022
2022
-
[80]
Glenn W. Brier. Verification of forecasts expressed in terms of probability. Monthly Weather Review, 78 0 (1): 0 1--3, 1950. doi:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2
-
[81]
Welton Chang, Eva Chen, Barbara Mellers, and Philip Tetlock. Developing expert political judgment: The impact of training and practice on judgmental accuracy in geopolitical forecasting tournaments. Judgment and Decision Making, 11 0 (5): 0 509--526, 2016. doi:10.1017/s1930297500004599
-
[82]
Welton Chang, Pavel Atanasov, Shefali Patil, Barbara A. Mellers, and Philip E. Tetlock. Accountability and adaptive performance under uncertainty: A long-term view. Judgment and Decision Making, 12 0 (6): 0 610--626, 2017. doi:10.1017/s1930297500006732
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.